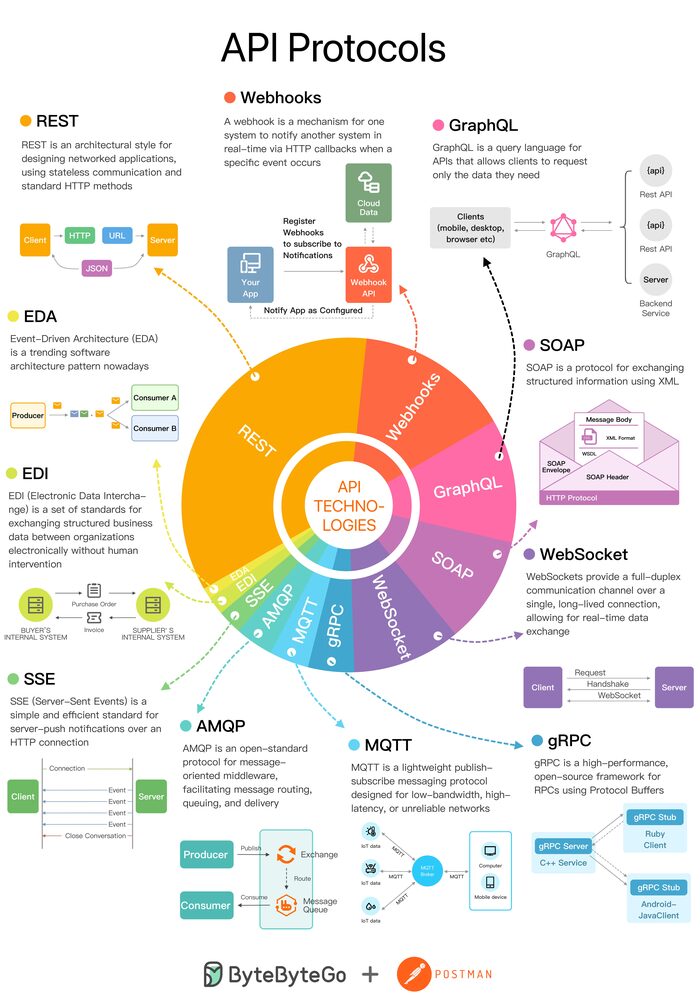
Развивающийся ландшафт протоколов API
Обзор шести самых популярных протоколов API
REST
Webhooks
GraphQL
SOAP
WebSocket
gRPC
источник https://t.me/itmozg/9692
Показать полностью
1
Обзор шести самых популярных протоколов API
REST
Webhooks
GraphQL
SOAP
WebSocket
gRPC
источник https://t.me/itmozg/9692
Сбер: теперь можно платить в магазинах улыбкой без карты и телефона!
Моя улыбка:
источник https://t.me/itumor/11544

Порою возникают ситуации, когда необходимо использовать в скрипте Python IP-адрес используемый активной сетевой картой, которая смотрит в Интернет, узнать MAC-адрес этой карты и имя сетевого соединения. К сожалению, функций из коробки пока что не наблюдается. Есть сторонние модули, которые позволяют узнать MAC-адрес, например getmac, но в качестве параметров в них нужно также передавать или IP-адрес, или имя соединения. Но, что, если их нужно определять программно и вводить вручную не вариант?
Я нашел для себя решение, которое работает, но требует тестирования на большом количестве систем. Хотя, думаю, что на большинстве ОС семейства Windows или Linux оно будет работать.

В данном решении не требуется устанавливать сторонние библиотеки. Необходимо лишь импортировать в скрип те, что нужны для его работы. Выполним их импорт:

Уже очень давно, около 15 лет назад на Stack Overflow был дан ответ по поводу получения «основного», имеющего маршрут по умолчанию, IP-адреса. Как описывает его автор скрипта, он работает под всеми основными ОС: Windows, Linux, OSX. Вот ссылка на данный пост.
Несмотря на то, что скрипту уже довольно много лет, он работает до сих пор. Потому, вместо изобретения велосипеда я использую его, за неимением лучшего. Тем более что он ни разу не давал сбоев. Вот сам скрипт:
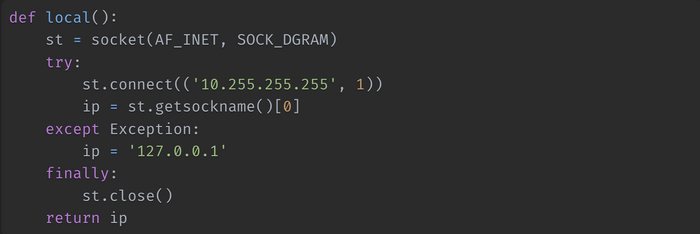
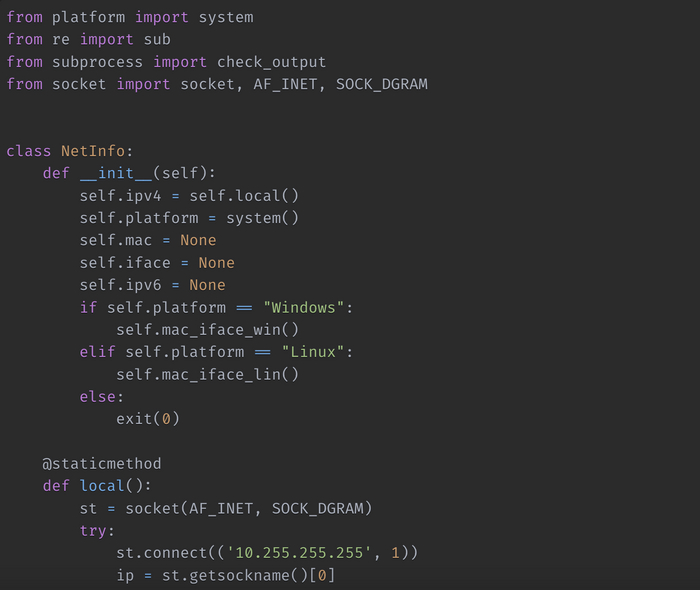
Теперь, когда мы определились с тем, каким способом будем получать IP-адрес, приступим к написанию скрипта для получения IPv6-, MAC- адресов, а также имени сетевого интерфейса.
Создадим класс NetInfo,который при инициализации будет получать необходимые данные в зависимости от операционной системы. Здесь мы определяем платформу с помощью модуля system библиотеки platform и в зависимости от этого запускаем тот или иной скрипт.
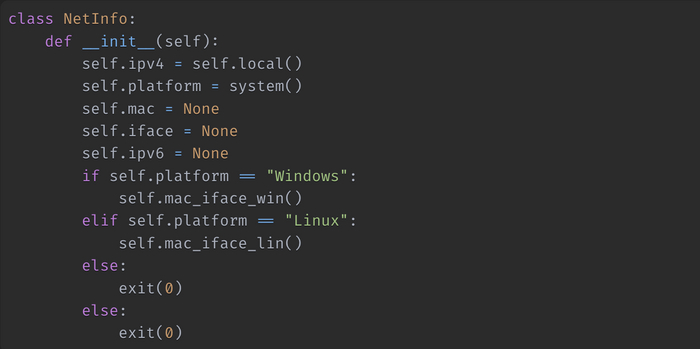
Двигаемся дальше. Создадим функцию для получения локального IP-адерса и объявим ее статическим методом, так как в ней не используются переменные класса.
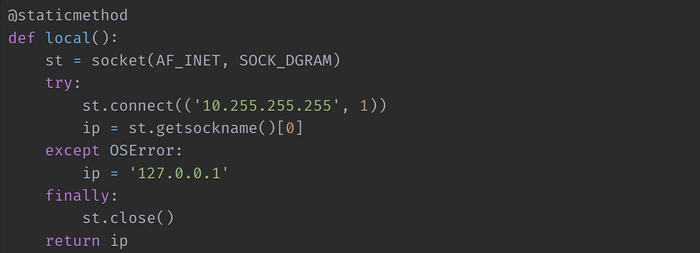
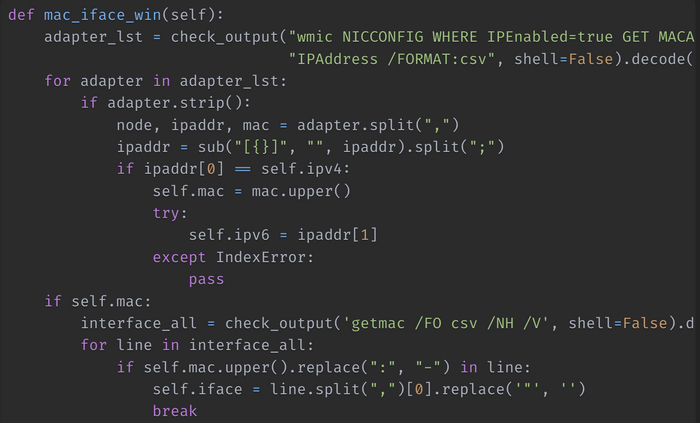
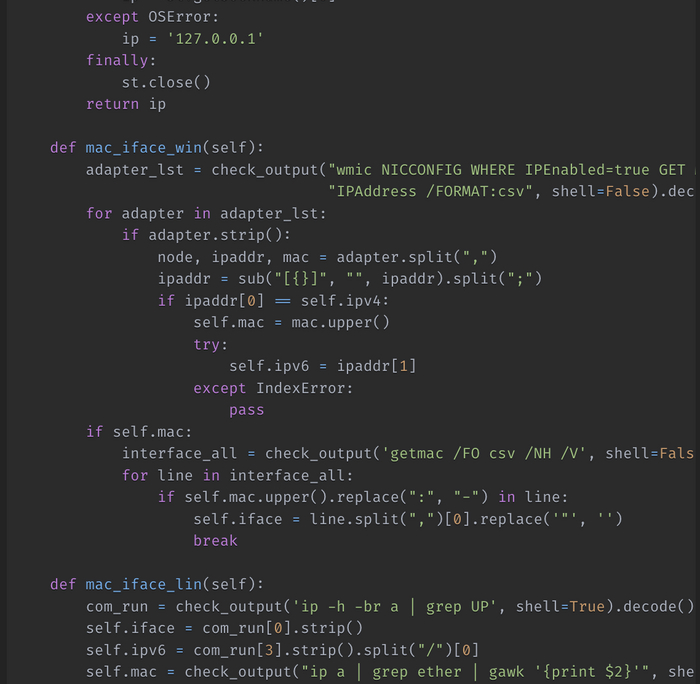
Напишем функцию mac_iface_win(self) в которой выполним получение нужных нам параметров. Для этого мы будем использовать возможности командной строки Windows, с частности инструмент командной стоки wmic. В частности будем использовать псевдоним NICCONFIG, который используется для управления сетевыми адаптерами. Отфильтруем только активные сетевые адаптеры. А их может быть в системе несколько, включая виртуальные: IPEnabled=true . После этого получим MAC – и IP – адреса используя GET MACAddress, IPAddress /FORMAT:csv, с указанием вывода полученных значений в формате csv для того, чтобы нам было проще их распарсить.
Вот полный вид данной команды:
wmic NICCONFIG WHERE IPEnabled=true GET MACAddress, IPAddress /FORMAT:csv
После того, как мы получим список активных сетевых адаптеров, поитерируемся по нему в цикле и проверим, есть ли в данном списке адаптер, IP-адрес которого равен полученному ранее локальному адресу. Если есть, забираем MAC-адрес, а также IPv6 адрес, если он не отключен в системе.
После того, как мы получим необходимые данные, выполним команду getmac /FO csv /NH /V с помощью которой получим список сетевых интерфейсов. Также в цикле проитерируемся по нему и будем проверять, есть ли уже полученный MAC-адрес в строке с параметрами интерфейса. Если есть, забираем название сетевого интерфейса.
Если в предыдущей функции мы получили данные для сетевого интерфейса в ОС Windows, то следует также написать аналогичную функцию и для Linux. Поэтому создадим функцию mac_iface_lin(self). В ней кода будет поменьше, так как в командах Linux содержится больше информации в одном месте и ее легче распарсить. Команда, которую мы будем использовать выглядит следующим образом:
ip -h -br a | grep UP
Здесь мы получим название сетевого интерфейса и IPv6-адрес. В Linux данный адрес можно получить, даже если он отключен в настройках адаптера.
После этого выполним похожую команду, но уже отфильтруем из ее вывода MAC-адрес:
ip a | grep ether | gawk '{print $2}'
Осталось только свести написанный код, если вы этого еще не сделали воедино.

Итак, продолжим. Полный код скрипта выглядит следующим образом:
Теперь необходимо протестировать его в операционных системах. В данном случае у меня доступны две системы: Windows 10 и Linux Mint.
Создадим в данном скрипте вызов нашего класса и выведем в терминал полученные параметры:

Для начала, запустим в ОС Windows:

А теперь то же самое в Linux Mint:

Как видим, скрипт справляется со своей работой. Для чего он может пригодиться? Ну, например, для автоматической установки активного сетевого интерфейса по умолчанию в Scapy при прослушивании пакетов с активного сетевого интерфейса. Но о Scapy поговорим немного позже.
Спасибо за внимание. Надеюсь, данная информация будет вам полезна
Почти все браузеры, основанные на chromium, хранят закладки похожим образом. Меняются только директории, в которые эти браузеры установлены. Исключением является только Mozilla Firefox. При этом закладки хранятся в открытом виде, так что, любой желающий может получить к ним доступ. Не сказать, чтобы это была супер секретная информация. Но все же, стоило бы продумать этот момент. В данной статье мы рассмотрим код, который в автоматизированном режиме получает все закладки из распространенных браузеров с помощью Python.

Поиск установленных браузеров
Создадим файл browser_check.py. В нем, напишем код, который будет производить поиск браузеров по пути указанному в одном из словарей.
Импортируем необходимые библиотеки для работы скрипта и определим список, в который будем помещать словари с найденными браузерами:

Следующим шагом будет создание двух словарей, в которые поместим пути к распространенным браузерам на операционных системах Windows и Linux, так как поиск браузеров будет производиться по путям, которые специфичны для каждой из операционных систем.
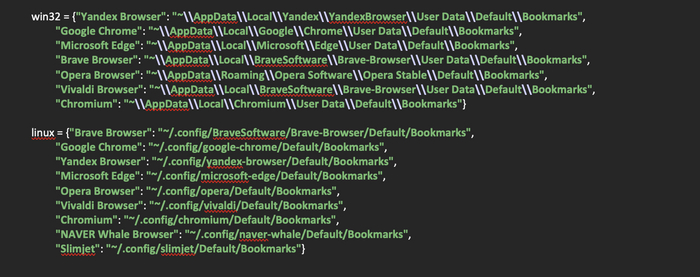
Создадим функцию browser_find(platform: dict) -> None, которая на входе будет получать словарь с путями к закладкам браузеров и проверять их существование. Если путь существует, в объявленный ранее список browser будет добавляться словарь с названием браузера и путем к его закладкам.

Следует обратить внимание на тот факт, что пути к закладкам браузеров указаны при установке их в директории по умолчанию. Если же пользователь поменял расположение директории с браузером, то он найден не будет.
Двигаемся далее и создадим функцию main, в которой будем определять платформу, на которой запущен скрипт. В принципе, если у вас MacOS, то нужно добавить еще один словарь с путями и условие, в котором определяется ваша система. Но, в данном случае детектируются только две операционные системы: Windows и Linux.
В зависимости от того, какая из систем установлена на компьютере с запущенным скриптом, забираем нужный словарь с путями к закладкам и передаем его в функцию browser_find, которую напишем в отдельном файле.
После этого проверяем, есть ли что-то в списке с браузерами. Если список пуст, выводим сообщение для пользователя, что браузеры не найдены. Если же список не пуст, итерируемся по нему в цикле, забираем словари и получаем название браузера, которое содержится в переменной key и путь к закладкам, содержащийся в переменной value.

Передаем полученное значение в функцию по парсингу json. На самом деле, файл с закладками, это json-файл с достаточно большой структурой вложенности.
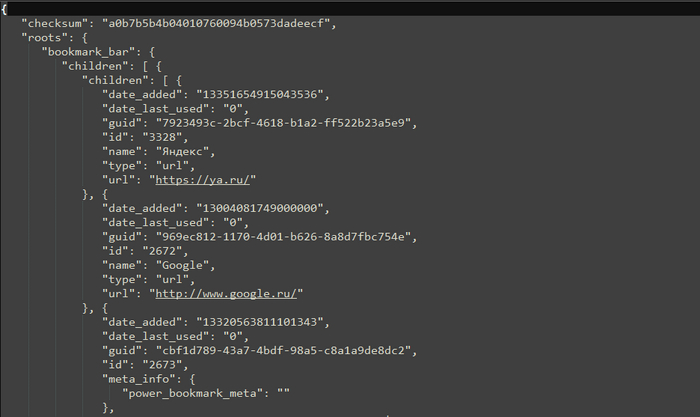
Часть структуры файла закладок
В зависимости от того, что вернет функция парсинга, а возвращает она или список со словарями, в которых содержаться полученные значения или False, двигаемся дальше. Если мы получаем список, то открываем файл с названием браузера на запись. Обратите внимание на то, что в данном случае файл открыт в режиме дозаписи, о чем свидетельствует параметр «a». Затем итерируемся по полученному списку, забираем из словарейОбратите внимание на ветку «roots», в которой и находятся все закладки. Так как закладки в браузере, это не просто последовательный набор названий и ссылок, то их группировка происходит по директориям создаваемым пользователем. Данные директории имеют название «children» и имеют тип «folder». Также, к примеру, на Панели закладок могут быть как директории с закладками, так и просто закладки для быстрого доступа. Тип закладок без папок «url».
Создадим файл bookmarks_find.py и приступим к написанию кода. Для начала импортируем библиотеки, которые понадобятся в данном скрипте.
import json
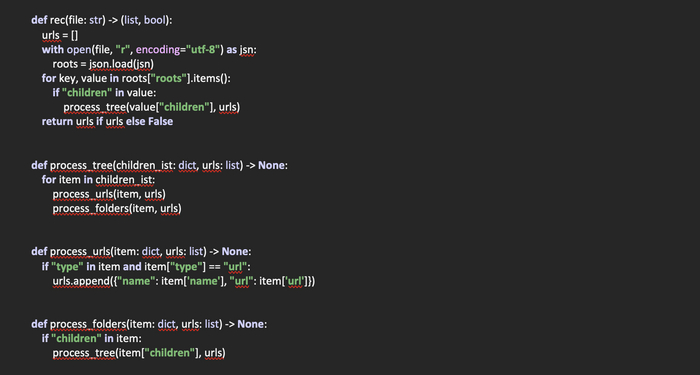
Создадим функцию rec(file: str) -> (list, bool), в которую передается путь к закладкам браузера. Возвращает же данная функция список со словарями, в которых содержится имя и url закладки. В случае же, если закладки найти не удалось, возвращается False.
Объявляем список urls, в который будем помещать найденные закладки в виде словарей. Откроем файл с закладками для чтения, поместим его содержимое в переменную roots.
Так как значение данной переменной будет являться словарем, проитерируемся по нему в цикле, указав ветку «roots» в качестве стартовой. Получим ключ и значение и проверим, есть ли в нем название «children». Если да, передаем полученную ветку в функцию process_tree, которую мы создадим чуть позже для обработки. Также передаем в эту функцию список urls. По сути, при передаче списка, если вспомнить его свойства, мы передаем указатель на оригинальный список, так как его копирования в данном случае не происходит. А значит, при его изменении в других функциях измениться и оригинальный словарь.

После того, как завершим итерацию по файлу, проверяем, пуст или нет список. Если список не пуст, возвращаем его из функции. Если пуст - возвращаем False.
Теперь создадим функцию process_tree(children_ist: dict, urls: list) -> None, которая получает на входе словарь из полученной директории и указатель на список, в котором будут храниться найденные ссылки в виде словарей.

Здесь все просто. Данная функция как переходник, в котором мы итерируемся по полученному словарю и передаем полученные значения в следующие функции для обработки.
Создадим функцию process_urls(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список. У данной функции предназначение – выявить ссылки в переданном словаре. Для этого проверяем, есть ли в переданном словаре ключ «type» и является ли его значение «url». Если да, забираем название ссылки и саму ссылку и добавляем в виде словаря в список urls.

И еще одна функция, которая будет необходима для проверки, не является ли полученный словарь директорией со ссылками «children». Создадим функцию process_folders(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список.
Здесь все тоже просто, проверяем, есть или нет «children» в переданном словаре. Если есть, передаем его рекурсивно в функцию process_tree для дальнейшей обработки.

Полный код скрипта:
import json
На этом вроде бы все. Основные скрипты и функции написаны, осталось только проверить, как это будет работать.
Открываем терминал и запускаем скрипт:
Если у вас Windows:
python browser_check.py
Если Linux:
python3 browser_check.py
В процессе работы скрипт выведет несколько сообщений: о том, сколько было найдено браузеров, для какого из браузеров найдены закладки и для какого количества из найденных закладки сохранены.
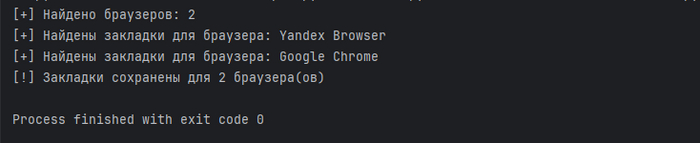
Сообщения в терминале
Если скрипт найдет браузеры в системе, в директории скрипта будут созданы файлы с названиями найденных браузеров, в которых содержатся закладки.
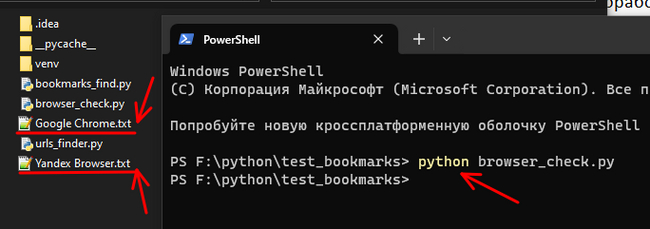
Файлы с найденными закладками
Как видно на скриншоте, у меня установлено два браузера. Давайте откроем один из файлов и посмотрим на часть его содержимого.
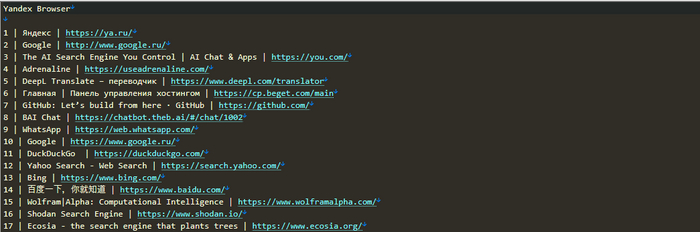
Содержимое файла с найденными закладками
Как видим, закладки найдены. За годы работы в данном браузере их накопилось чуть более 3000. Конечно же, показывать все я не буду, потому, только самое начало, для того, чтобы убедиться, что скрипт работает.
Скрипт работает как на Windows, так и на Linux. Вот скрин с работой скрипта в Fedora Workstation, в которой браузеры установлены по умолчанию, с помощью пакетов.
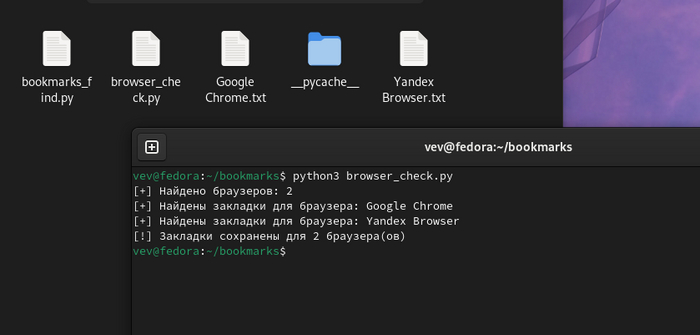
Работа скрипта в Fedora Workstation
Подведем итоги:
В данной статье мы научились рекурсивно парсить файл json, узнали, каким способом можно определить операционную систему, установленную на компьютере, а также сохранять данные из json в текстовый файл.
В перспективе, применений данному скрипту можно найти достаточно много. Все зависит только от вашей фантазии.
А на этом все. Спасибо за внимание.
git init - Инициализировать новый Git-репозиторий.
git clone - Клонировать удаленный репозиторий на вашу локальную машину.
git status - Проверить текущее состояние рабочей директории.
git add - Постановка изменений для следующей фиксации.
git commit - Записать внесенные изменения и создать снимок.
git push - загрузить локальные изменения в удаленный репозиторий.
git pull - Получение и объединение изменений из удаленного репозитория.
git branch - список, создание или удаление веток.
git checkout / git switch - переключение между ветками или коммитами.
git merge - Интеграция изменений из одной ветки в другую.
git diff - просмотр различий между рабочим каталогом и областью хранения.
git log - отображение хронологического списка коммитов.
источник https://t.me/itmozg/9679
Вводные:
- занимаюсь программированием(обычно держу 2 операционки на компе Linux/Windows). Linux нужна под конкретные задачи в работе, Windows WSL2 cейчас вроде покрывает потребности в лёгких задачах,но при установке чего-то специфического начинаются танцы с бубном и легче на Linux перейти.
- работал на MacOs недолго.
- занимаюсь также по второй работе и как хобби графикой(от GIMP/до продуктов Adobe)
Проблема:
Хочу взять ноут, посмотрел рынок и обнаружил, что мак почему-то уже не кажется таким оверпрайс в своих категориях. Те кто пользуются MacOs, есть-ли заметные минусы в работе с ней сейчас ? Вроде на Iphone не работает NCF и нет доступа к скачиванию каких-то приложений. Есть ли подобные проблемы у Мака ? Хороший ли экран у моделей(тот что был на стационарном маке мне не особо зашёл, но и не самый худший)?
Ну и другие советы, если у кого будут, с радостью почитаю в том числе за рынок ноутов(может за интересные модели по типу MateBook. Давно изучаю тему с маками и хочу попробовать, спрашиваю у друзей(возможности взять на время,из-за расстояния,к сожалению нет) и проблема в том, что конкретный ответ: чем лучше будет мак такого-же ноута по цене так и не получил.
На приведенной ниже диаграмме показана схема работы поисковой системы.
▶️ Шаг 1 - Краулинг
Веб-краулеры сканируют интернет в поисках веб-страниц. Они переходят по ссылкам URL с одной страницы на другую и сохраняют URL в хранилище URL. Краулеры ищут новый контент, включая веб-страницы, изображения, видео и файлы.
▶️ Шаг 2 - Индексирование
После того как веб-страница просмотрена, поисковая система анализирует ее и индексирует содержимое, найденное на странице, в базе данных. Содержимое анализируется и классифицируется. Например, оцениваются ключевые слова, качество сайта, свежесть контента и многие другие факторы, чтобы понять, о чем эта страница.
▶️ Шаг 3 - Ранжирование
Поисковые системы используют сложные алгоритмы для определения порядка результатов поиска. Эти алгоритмы учитывают различные факторы, включая ключевые слова, релевантность страниц, качество контента, вовлеченность пользователей, скорость загрузки страниц и многие другие. Некоторые поисковые системы также персонализируют результаты, основываясь на истории поиска пользователя, его местоположении, устройстве и других личных факторах.
▶️ Шаг 4 - Запрос
Когда пользователь выполняет поиск, поисковая система просматривает свой индекс, чтобы предоставить наиболее релевантные результаты.
источник https://t.me/itmozg/9667
Вы когда-нибудь задумывались, какой минимум необходим для загрузки Windows? Что ж, смотрите дальше! Этот образ Windows имеет размер менее 100 МБ(!), но, очевидно, он невероятно ограничен, то есть работает только командная строка и некоторые очень простые пакетные файлы. Но это все равно Windows!
Это стало возможным благодаря Nytrona, которому пришла в голову эта невероятная идея!
Энтузиаст с ником NTDEV создал невероятную вариацию операционной системы Windows 11, которая занимает всего 100 Мб. Для сравнения, полный официальный дистрибутив потянет на 64 Гб. В предельно урезанном виде ОС не пригодна для полезной работы, но сохраняет все свои базовые свойства.
источник https://t.me/mir_teh/1427
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.