Прикладной Python: S1E2, парсим Пикабу
По плану сегодня должен был выйти пост про работу с `input()`. Но пришла более интересная идея, поэтому input пришлось отодвинуть на несколько дней.
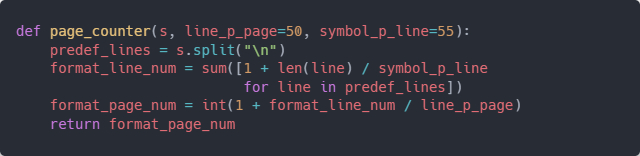
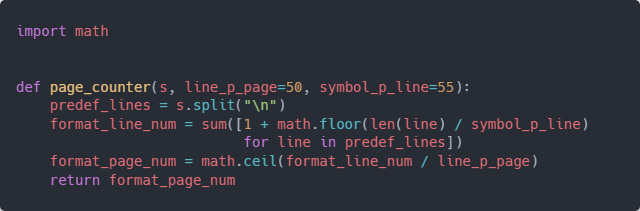
Видели прошлый пост? Он собрал много комментариев, и перед тем, как отвечать, я решил их систематизировать, чтобы понять общую тенденцию. Для этого я спарсил комменты с Пикабу и упаковал их в табличку Excel. Естественно, всё это делалось с помощью кода, а не руками. Так что сейчас мы с вами пошагово разберём, как можно перетянуть данные с веб-страницы на Пикабу в Excel с помощью небольшого кусочка кода.
На берегу предупреждаю, что материал не совсем новичкового уровня. Вложенные структуры данных, классы, внешние пакеты из PyPI - всё это будет использоваться. Также необходимы хотя бы базовые знания HTML и навыки работы с DevTools в Google Chrome.
Важное замечание
Любой ресурс, на котором есть уникальный контент, не слишком радостно относится к тому, что с него будут в автоматическом режиме тянуть данные. Особенно если речь идёт о массовом парсинге страниц, который может дать приличную нагрузку на сервер.
В этом посте я покажу, как аккуратно взять данные с 1 конкретной странички. Администрация дала на это добро. Повторять за мной или нет - решать вам. Но если будете парсить, то не злоупотребляйте и не ломитесь бесконтрольно на все страницы подряд, скачивая тысячами запросов контент "на чёрный день".
Selenium
Пикабу отбривает запросы, которые отправляются программно с помощью requests. Сначала я пробовал поиграться с User-Agent и прочими заголовками, но это не дало результата. Поэтому решил использовать Selenium, чтобы сымитировать "настоящего" пользователя, который заходит на сайт с помощью браузера.
Первое, что нужно сделать для использования Selenium - это скачать драйвер для взаимодействия с браузером. Инструкция здесь. Внимательно всё прочитайте и выберите подходящий для вашего браузера драйвер. Подход "просто ткну на первую ссылку" здесь может не сработать. Я пользуюсь браузером Chrome, поэтому дальше в тексте буду писать названия, сочетания клавиш и прочие моменты именно для него.
После того, как вы скачали драйвер, его нужно поместить туда, где система сможет его обнаружить. Если знакомы с тем, что такое PATH - отлично, вы знаете, что делать. Если нет, то закиньте скачанный файл вида `chromedriver.exe` в `C:\Windows\system32`.
Подготовка
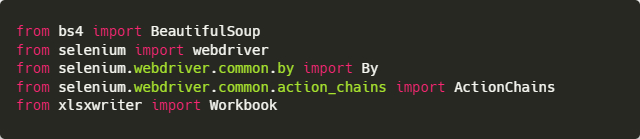
Устанавливаем необходимые пакеты из PyPI с помощью командной строки.
python -m pip install bs4 selenium xlsxwriter
Импортируем их.
https://www.codepile.net/pile/a1K5daAp
Создаём всё необходимое для работы Selenium и загружаем страницу.

https://www.codepile.net/pile/6YzeZO2y
Запустите этот код. Откроется браузер, и в нём загрузится указанный пост. У тех, кто пользуется Chrome, прямо под адресной строкой будет небольшая плашка "Браузером Chrome управляет автоматизированное тестовое ПО".

Открываем комментарии
На веб-странице, которая загрузилась в браузере, комментарии изначально отсутствуют. Для того, чтобы они подгрузились, нужно кликнуть по кнопке "Показать все комментарии".
Нажимаем F12, открываем вкладку "Elements" и находим в списке элементов нужную кнопку. Это тег `<button>` с классом `comments__more-button`.

Находим её с помощью `driver.find_element()` и нажимаем с помощью ранее созданного экземпляра `ActionChains`.

Извлекаем комментарии
Возвращаемся на вкладку "Elements" в Chrome и находим там контейнер, в котором хранятся все комментарии.

Извлекаем содержимое этого контейнера и собираем из него удобную структуру данных с помощью BeautifulSoup.

Извлекаем из каждого комментария текст и информацию об авторе. Интересны только первые комментарии, поэтому рекурсивно погружаться внутрь ветки не будем.

Теперь у нас есть список словарей, в котором хранится юзернейм, ссылка на пользователя и текст его комментария.
Записываем данные в Excel
Для этого воспользуемся библиотекой XlsxWriter.

Причёсываем код
Получилась довольно длинная простыня кода, поэтому её стоит структурировать и разбить на отдельные части. Чрезмерным абстрагированием заниматься не будем, просто разделим уже имеющуюся логику, чтобы с ней было проще работать. Выкладывать весь код целиком в виде изображения не буду, т.к. он довольно объёмный. Вот ссылка: https://www.codepile.net/pile/Vg37pvgb
Временные затраты
На написание парсера ушло около 20 минут, и ещё часа 3 ушло на подготовку поста :)
Сколько времени собирались бы эти данные вручную - сказать сложно. Но главное, что теперь для обновления данных достаточно просто запустить скрипт, а при ручном сборе пришлось бы каждый раз заново пробегаться по всем комментариям.
Если хочется попробовать, то напишите свой парсер какого-нибудь сайта, а затем поделитесь результатами в комментариях. Будет интересно посмотреть)