«Отпусти (Я хочу забыть тебя)» - кавер-версия, созданная искусственным интеллектом, в исполнении Анны Asti и Люси Чеботиной. Разыграйте знакомых, включите им эти треки. Может, нам на самом деле предложить этот хит вашим кумирам?
Пару недель назад я захотел сделать кавер с одним определённым голосом на какую-нибудь популярную песню. tl;dr всё получилось и ниже вы узнаете, как повторить такой результат:
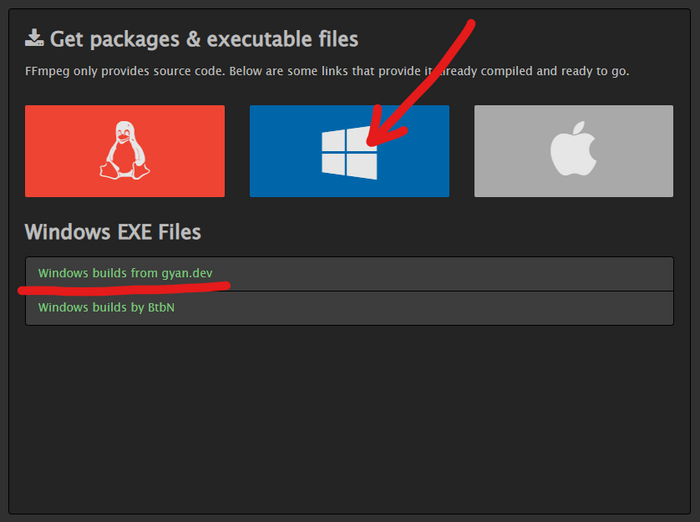
Быстрое гугление выдаёт несколько онлайновых сервисов, в которых либо можно выбрать из списка уже обученных моделей, либо это дорого, долго и вне моего контроля над генерацией.
платно
Если допустить немного пердолинга, то есть инструмент для локальной установки с простым веб-интерфейсом и кнопкой "Generate".
Но для полноценной работы ему требуются обученные голосовые модели в формате RVC (об этом ниже), функционала обучения в нём нет.
Ещё немного поисков выдают вариации такого колаба.
Для обучения нужно оплатить подписку Colab Pro, иначе процесс будет прибит сервером с ошибкой "недопустимая инструкция для бесплатного аккаунта".
Этого уже достаточно для создания каверов со своими голосовыми моделями. Первые каверы я делал именно так. Если хотите улучшить качество генерации или оптимизировать сам процесс, то переходите к следующему пункту.
Как это работает
Realistic Voice Cloning (реалистичное копирование голоса) или RVC работает по вполне понимаемому алгоритму.
При обучении:
дорожка с голосом, который нужно скопировать, нарезается на короткие отрезки
эти отрезки сортируются по высоте тона, тембру и эмоциям или настроению (используется нейросетевой инструмент оценки эмоциональности)
результат собирается в базу данных и индексируется
При копировании голоса:
заменяемая звуковая дорожка тоже нарезается на короткие отрезки
эти куски анализируются и подбирается наиболее подходящий аналог из базы данных (модели) обученного голоса
подобранному кусочку меняется высота тона, скорость воспроизведения и, если точного аналога не найдено, накладывается "акцент" для создания похожего звука
результат сшивается в цельную звуковую дорожку
Конечно "под капотом" всё устроено значительно сложнее, но принцип понятен.
Если умеете пользоваться гитом и командной строкой, то можете сразу перейти к пункту про обучение модели. Ниже будет подробная инструкция по установке.
Требования к железу:
компьютер с Windows или Linux
дискретная видеокарта с 8 ГБ памяти или больше (поддерживаются NVIDIA, AMD и Intel)
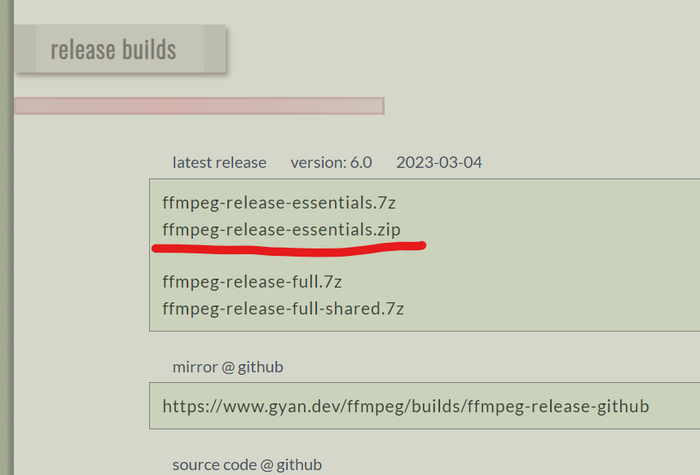
И распаковываем в любую папку. В моём случае C:\ffmpeg и файл ffmpeg.exe находится по адресу C:\ffmpeg\bin\ffmpeg.exe
Почти готово, нужно только добавить путь к ffmpeg в переменную path.
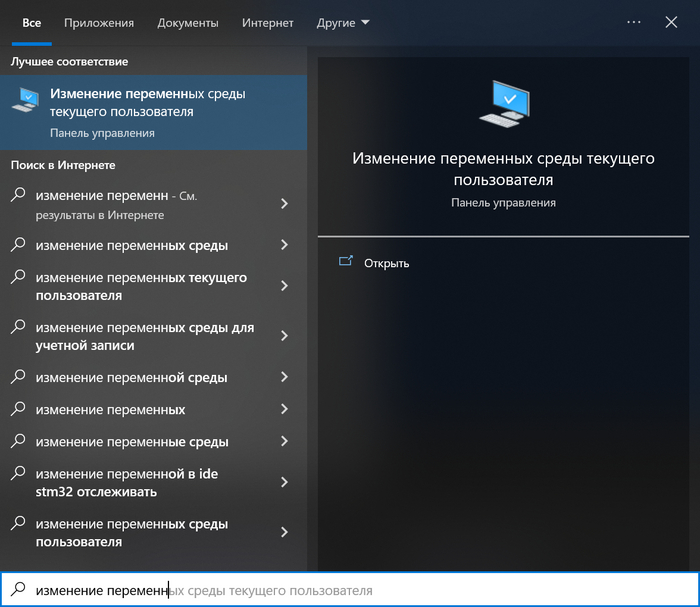
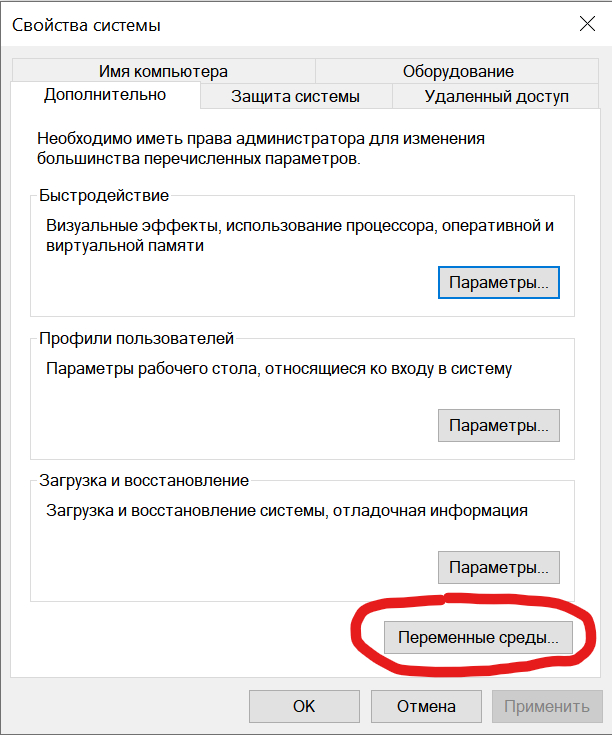
Нажимаем Win и начинаем вводить "изменение переменных среды":
выбираем этот пункт
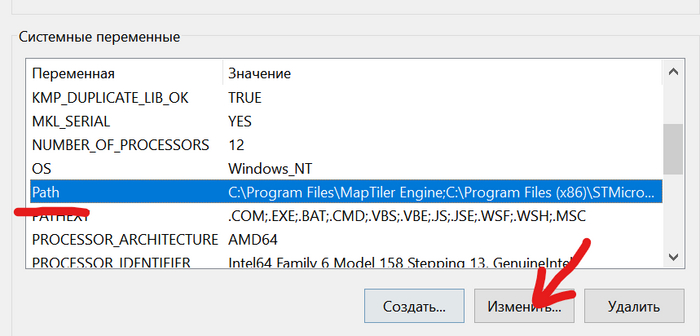
В системных переменных выбираем Path и нажимаем "Изменить..."
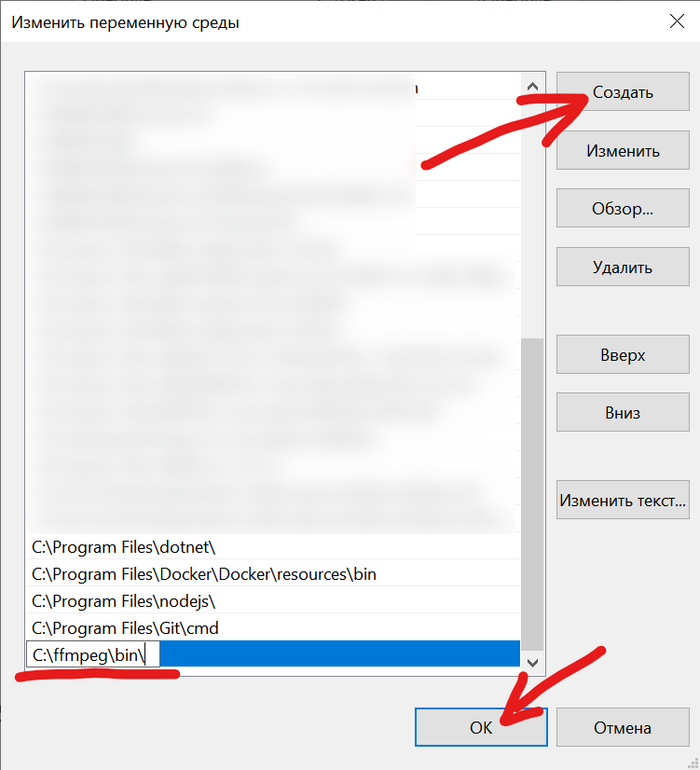
Создаём новую переменную с путём до файла ffmpeg.exe
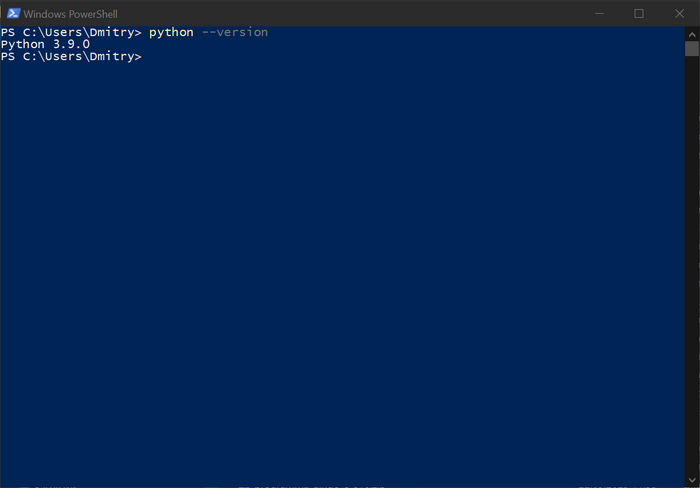
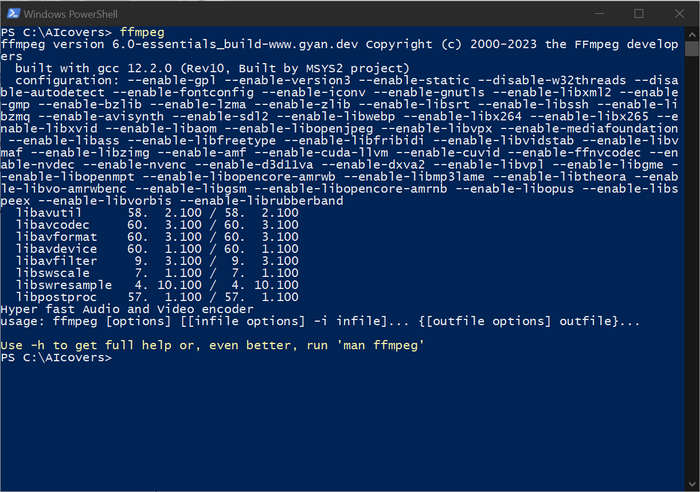
Опять открываем командную строку и проверяем правильность установки:
ffmpeg
Непосредственно установка
Создайте на диске папку, где будет размещаться софт для обучения модели. У меня это C:\AIcovers (обойдитесь без пробелов в именах папок, это упростит работу в будущем).
Откройте командную строку и перейдите в только что созданную папку.
cd C:\AIcovers
Клонируем этот репозиторий в папку train командой:
Осталось скачать предобученные модели для обработки звука. В основном репозитории нет скрипта для автоматического скачивания этих файлов, поэтому я набросал нечто корявое, но рабочее и отправил PR в основной репозиторий. После мержа курсивный текст будет неактуален.
Скачайте и сохраните у себя файл download_models.py в папке train/tools, куда мы клонировали репозиторий. Затем выполните команду:
И у нас автоматически должно открыться окно браузера с интерфейсом
Если видите это — поздравляю, вы всё сделали правильно. Читайте дальше, чтобы понять, как этим пользоваться.
Обучаем голосовую модель
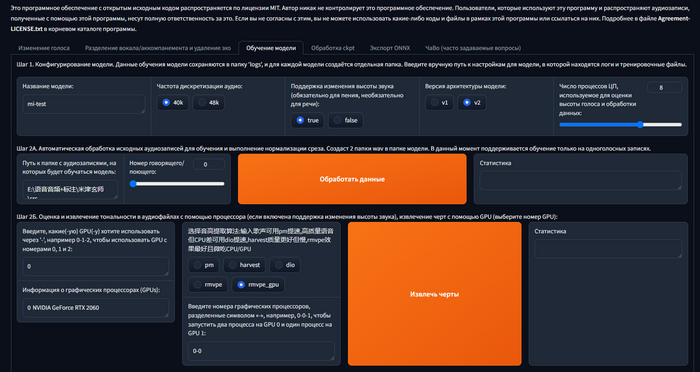
В интерфейсе переходим на вкладку "Обучение модели":
Нужно подготовить данные для обучения модели.
Задайте название для модели голоса в соответствующем поле.
Создайте на диске папку и положите в неё один или несколько файлов с записью голоса. Это должны быть аудиофайлы почти в любом формате. Точно поддерживаются wav, mp3 и m4a.
Голос должен быть максимально очищен от шумов и фоновой музыки. Не должно быть посторонних звуков, которые человек не может издавать ртом.
Для редактирования звука можно воспользоваться бесплатным редактором Audacity.
Введите адрес к папке с аудиозаписями в это поле:
Если в пути к этой папке есть пробелы, то добавьте кавычки.
Нажмите кнопку "Обработать данные" и дождитесь сообщения "end preprocess" в поле справа от кнопки.
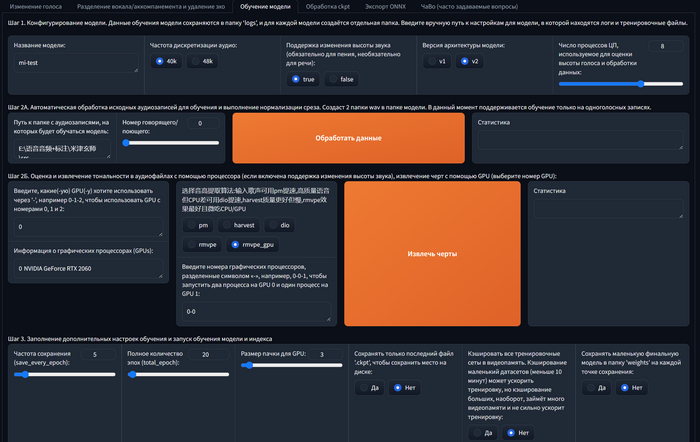
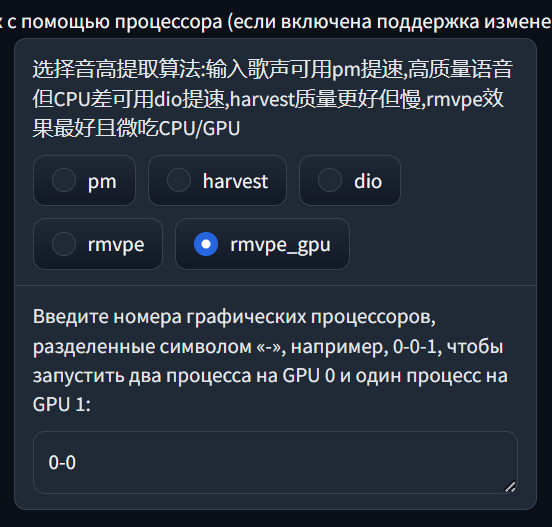
Следующая операция выполняется немного дольше. Сперва выберите алгоритм обработки данных (извлечения черт):
Лучшее качество дают rmvpe и rmvpe_gpu. Они по-разному нагружают видеокарту и центральный процессор. Я так и не понял, какой лучше, поэтому выбираю второй.
Нажмите кнопку "Извлечь черты" и дождитесь сообщения "all-feature-done" в поле справа от кнопки.
• 20-30 для исходника низкого качества с высоким уровнем шума, большее число не улучшит качества обучения
• ~200 для датасета высокого качества, с низким уровнем фонового шума и достаточной продолжительностью (10 минут и более)
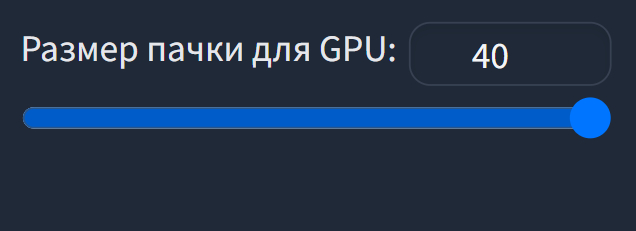
Этот параметр влияет на использование видеопамяти:
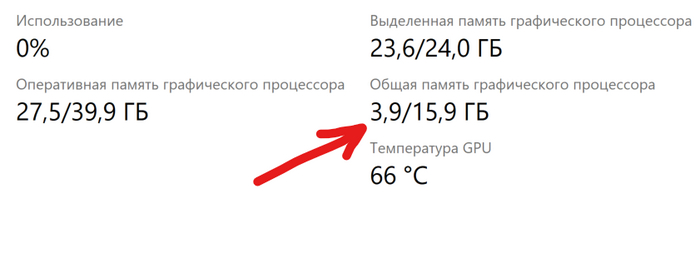
Рекомендаций по оптимальному значению не дам, подбирайте экспериментально для каждого датасета, чтобы расход видеопамяти не вылезал за общий её объём, иначе будет использована системная ОЗУ (та самая DDR на материнской плате) и вместо ускорения обучения вы получите замедление.
использовано 3.9 ГБ более медленной системной памяти
Нажимайте кнопку "Обучить модель" и ждите окончания процесса. Как и в предыдущих этапах в правом поле будет отображаться результат. В консоли можете следить за ходом процесса.
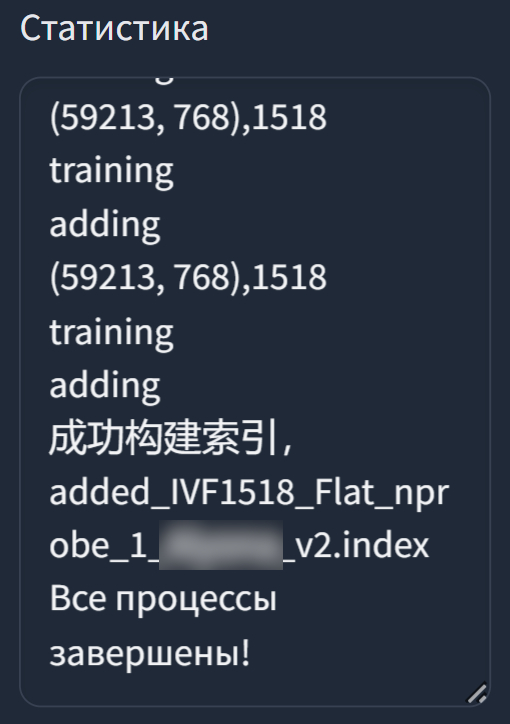
Дожидаемся окончания обучения и нажимаем кнопку "Обучить индекс черт" и ждём ещё немного.
Заходим в папку с нажим скриптом и по пути assets\weights находим файл *имя-модели*.pth (в моём случае my-voice.pth) и копируем его в отдельную папку.
Теперь по пути logs\*имя-модели* (в моём случае logs\my-voice) находим файл с именем формата added_IVFxxx_Flat_nprobe_1_*имя-модели*_v2.index (у меня это added_IVF2050_Flat_nprobe_1_my-voice_v2.index) и копируем его в папку к файлу .pth из предыдущего пункта.
Запакуйте оба файла в архив zip с любым именем. Можно использовать встроенный инструмент Windows из контекстного меню Отправить > Сжатая zip-папка.
Поздравляю, этот архив и есть нужная голосовая модель в формате RVC.
В этом места закончился лимит на картинки. Все иллюстрации можете посмотреть в статье на телеграфе.
Замена голоса в треках
Предыдущий инструмент, который мы использовали для тренировки модели, вполне подходит для генерации новых треков, но удобство использования у него на очень низком уровне. Обещаю внести свой вклад в исправление этого недостатка. А пока установим намного более дружелюбный инструмент.
В консоли после запуска будет ссылка, по которой открывается веб-интерфейс.
Для задания другого сетевого порта добавьте параметр --listen-port *номер порта*, а для доступности интерфейса с других компьютеров в локальной сети добавьте параметр --listen.
Для доступности из интернета можно добавить параметр --share.
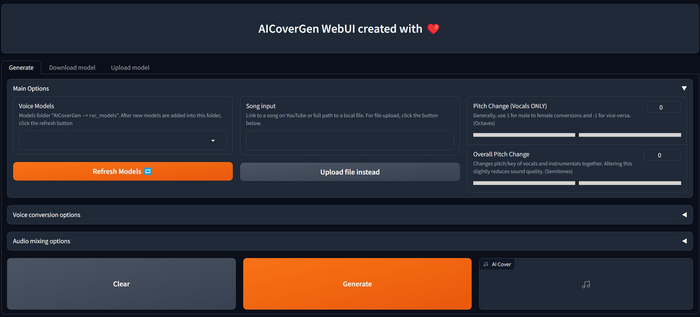
Использование
Откроем интерфейс и перейдём на вкладку "Upload model", чтобы добавить обученную на предыдущем этапе модель голоса.
Выберите файл для загрузки, задайте имя модели в поле "Model name" и нажмите кнопку "Upload model".
Если всё правильно, то в поле "Output message" вы увидите сообщение "model successfully uploaded!".
Теперь переходите на вкладку "Generate" и нажимайте кнопку "Refresh models". В списке "Voice models" появится загруженная вами модель. Выберите её.
В поле "Song input" можно либо вставить ссылку на ролик на YouTube, либо загрузить файл, выбрать вариант "Upload file instead". Рекомендую начать эксперименты с песни Джонни Кэша, у неё хорошо отделяется вокал и достаточно разборчивый голос для замены.
Нажимайте кнопку "Generate" и ждите результата. Подбирайте параметры, пока не получится что-то хорошее. Делитесь получившимися шедеврами.
Если будут вопросы, то можете задать их мне в телеграме.
Подписывайтесь на канал, ставьте лайки, жмите на колокольчик и всё такое. Всех люблю и обнимаю.
Все материалы в данной статье взяты из открытых источников.
Искусственный интеллект сегодня активно применяется в самых разных областях, включая музыкальное творчество. Благодаря прогрессу в области машинного обучения появилась возможность генерировать музыкальные произведения при помощи нейросетей. В этой статье мы рассмотрим, как создать собственную музыку с использованием инструмента Audiocraft - открытой нейросетевой платформы для генерации аудио от компании Meta*.
Официальная страница проекта в GitHub.
Поговорим о том, что представляет собой Audiocraft, какие задачи можно решать с его помощью и какую музыку получится сгенерировать. Рассмотрим процесс установки этого инструмента и на примерах покажем, как им пользоваться для создания собственных аудиодорожек в разных жанрах - от поп и рок-музыки до электроники и даже шумов природы.
Установка
Чтобы начать пользоваться нейросетью, вам понадобится проделать несколько шагов. Но перед этим, стоит также упомянуть, что вам обязательно потребуется видеокарта от Nvidia.
Рекомендуемое количество видеопамяти составляет 16 гигабайт, но в реальности нейросеть прекрасно себя показывает и на видеокартах сменьшим объемом. Например, на моей 3060 TI с ее 8 гигами, все замечательно работает.
Читайте ниженаписанное внимательно и постарайтесь не ошибиться. Я буду показывать процесс установки для операционной системы Windows.
Начнем.
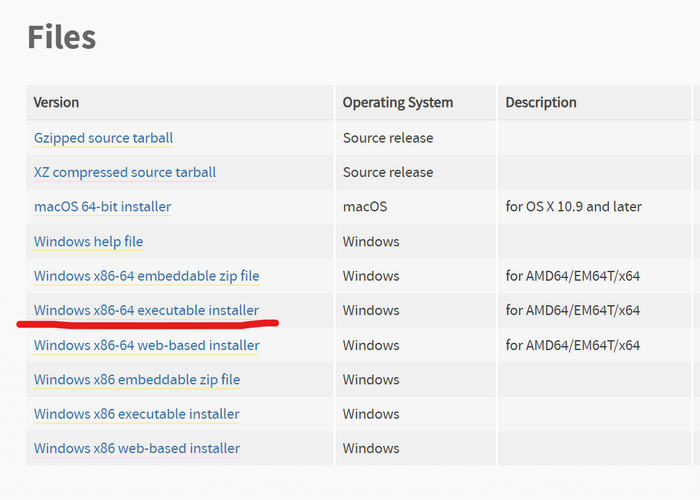
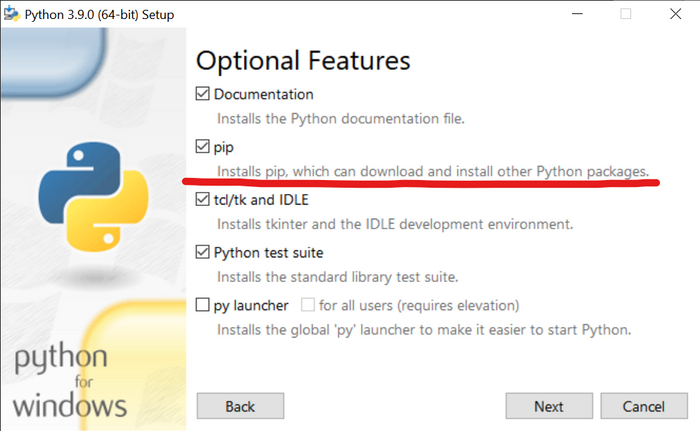
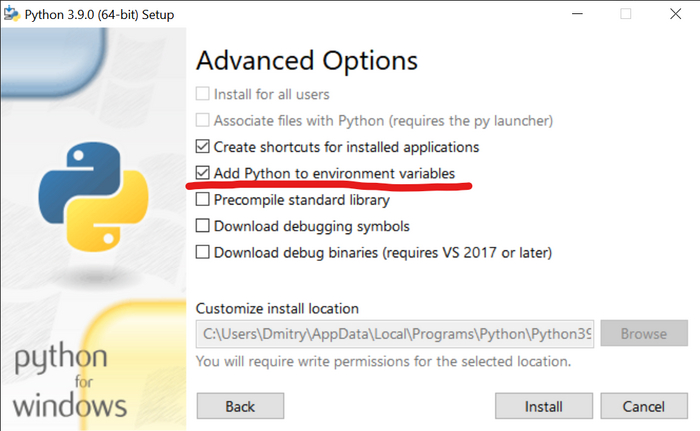
1) Скачайте и установите Git. 2) Скачайте и установите Python. 3) Скачайте и установите PyTorch. Чтобы это сделать, вам понадобится открыть командную строку от имени администратора и прописать там следующие команды:
Важно делать все по порядку. Категорически не следует наслаивать одну установку на другую. Дождитесь установки одной программы и только затем начинайте установку следующей.
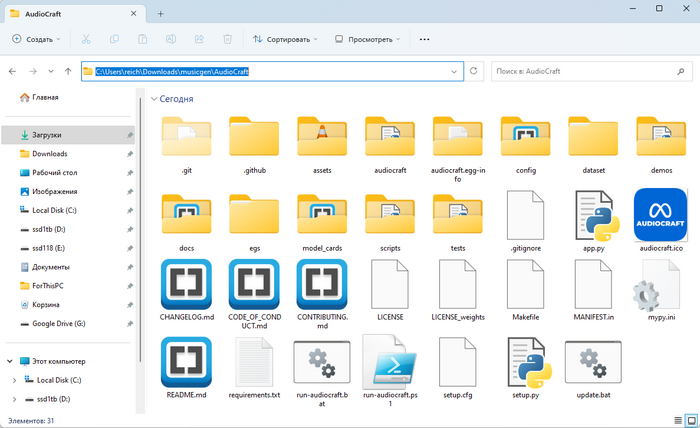
4) Далее вам следует создать отдельную папку на вашем компьютере. Назовите ее как-нибудь, обязательно на английском языке. Я назвал папку "musicgen".
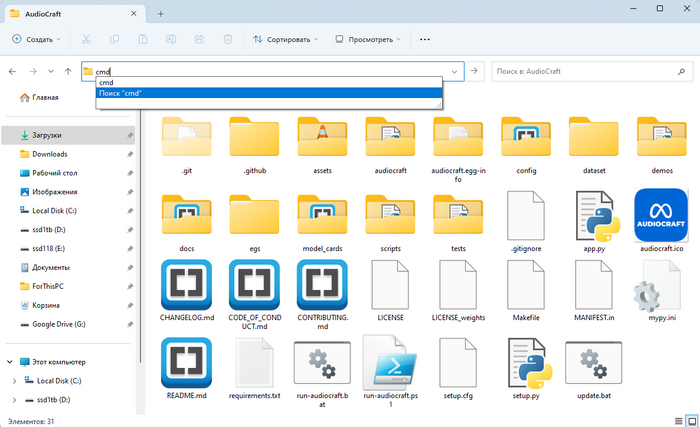
5) Откройте папку и кликните по верхней строке проводника. Пропишите там "cmd" и нажмите Enter.
6) Откроется командная строка. В ней вам необходимо прописать следующую команду:
Начнется процесс установки репозитория в созданную вами папку.
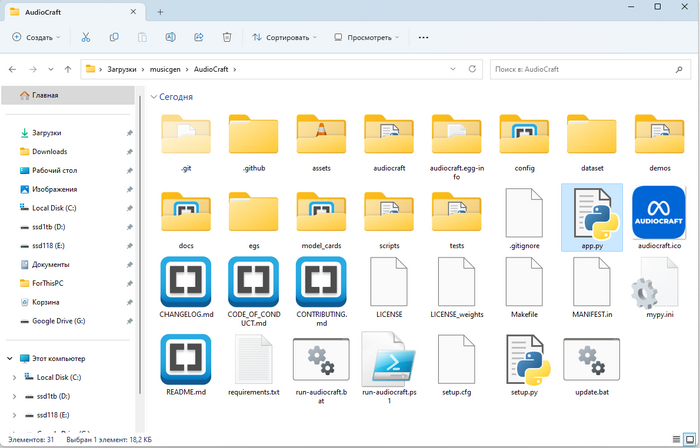
7) Когда процесс завершится, перейдите в скачанную только что папку AudioCraft и, по аналогии с созданной вами ранее папкой, откройте командную строку с помощью верхней строки проводника.
8) В открывшемся окне командной строки пропишите следующее:
pip install -e .
9) После установки этих компонентов вы можете попробовать прописать в этом же окне следующую команду:
Если на этом моменте никакой ошибки в командной строке не появится, то можете смело открывать IP-адрес, который высветится в ней же. Он будет начинаться с цифр 127. Просто кликните по нему левой кнопкой мыши, держа при этом CTRL.
Поздравляю! Вы установили AudioCraft на свой ПК и уже можете приступать к генерации треков.
Решение ошибки "[Errno 2] No such file or directory"
К сожалению, без проблем при установке может не обойтись. Неизвестно, почему, но многие люди сталкиваются с данной ошибкой при установке нейросети. С ней столкнулся и я.
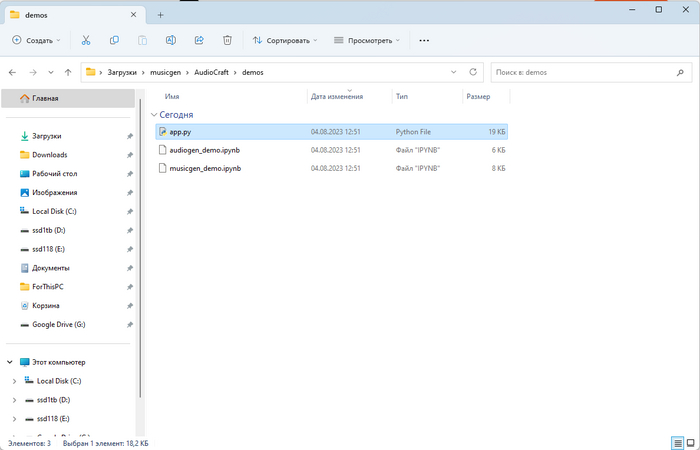
Появляется она при вводе команды "python app.py" (9 пункт моей инструкции) и гласит, что файл "app.py" найти не удалось. Сейчас покажу, как это исправить и все таки запустить нейросеть.
Решение, на самом деле, очень простое. Вам достаточно лишь зайти в папку "demos", которая находится в корневой папке нейросети AudioCraft (ее вы скачивали изначально). Здесь вы найдете файл с расширением .py и именно его вам нужно переименовать в "app.py", после чего скопировать и вставить в корень папки AudioCraft.
Затем попросту запускаете cmd, аналогично тому, как вы это делали в 7 пункте моей инструкции и прописываете команду "python app.py". Нейросеть должна начать работать.
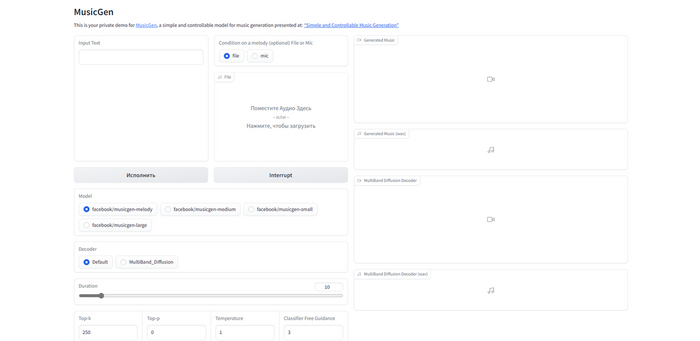
Как использовать AudioCraft?
И вот вы успешно установили и запустили нейросеть. Но что же она из себя представляет и как ей правильно пользоваться? На самом деле, ничего особенно трудного здесь нет.
Вводите ваш запрос в поле Input Text, после чего выбираете модель, с помощью которой хотите сгенерировать музыку. Для большинства компьютеров подойдет модель musicgen-melody. После этого выбираете длительность композиции. Оптимальным вариантом будет 10-30секунд для средне бюджетных ПК. Если хотите, можете попробовать создать более длинные треки, однако учитывайте, что и ресурсов ваш компьютер потратит гораздо больше, да и время генерации увеличится в разы.
Интерфейс Audiocraft.
После всех проделанных манипуляций, нажимайте кнопку "Generate" и ждите, пока трек будет готов. Полученную композицию можно скачать на ваш ПК и распространять кому и как угодно.
Официальный сайт.
Что касается остальных настроек, которые есть в интерфейсе нейросети, то тут могу порекомендовать вам ознакомиться с документацией, которая доступна по этой ссылке.
Чтобы не вызывать праведный гнев любителей русского рока в лучшем его проявлении (я тоже таковым являюсь), сделал голосовой кавер на товарища ATL. Вместо него теперь читает Ромка из визуальной новеллы Tiny Bunny.
Помимо голоса, попробовал создать небольшую визуализацию той истории, что происходит в тексте песни.
Для тех, кто хочет понять, как это всё происходит, оставляю ссылку на свой канал в телеграм. В закреплённых сообщениях есть ссылки на все нужные руководства, и что не менее важно, голосовые модели.
А помните. что были такие... Я про группу Многоточие. Решил смахнуть пыль с Легенд прогнать в формате нейромэшапа. Дальше двинусь в сторону иной бессмертной классики.
Для иллюстраций (обложки и арта внутри) использовал сервис PIXAI, работающий на базе моделей Stable Diffusion.
P.S.: Благодаря orcabomber появилась пара крутых идей. Всегда буду благодарен новым, даже самым безумным, для воплощения.