

Всё в порядке
Только сегодня дошли руки посмотреть, как там Яндекс браузер переводит видео налету. Ну что же, в ролик о задержании копами пьяной девушки, пытавшейся скрыться от них, переводчик внёс, так сказать, изюминку.
Только сегодня дошли руки посмотреть, как там Яндекс браузер переводит видео налету. Ну что же, в ролик о задержании копами пьяной девушки, пытавшейся скрыться от них, переводчик внёс, так сказать, изюминку.




Что будет, если пропустить через переводчик Яндекса текст, написанный сразу на двух языках? Например, вот это :)
Рождественский хорал In Dulci Jubilo (ссылка на видео), написанный на английском и латыни. Латинскую фразу «Trahe me post te» («Увлеки меня за собой») нейросеть перевела вот так :)
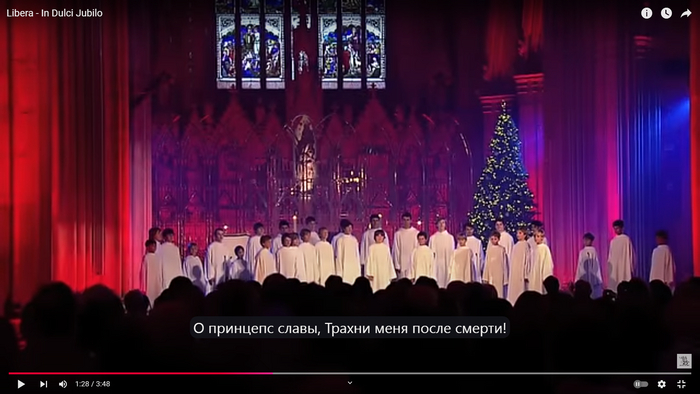
Поют в церкви мальчики в белых сутанах
Телеграм - https://t.me/roflemem/3994
Преданные последователи бегут, когда невероятно высокая башня «тазия» рушится во время процессии Мухаррам.
Башня «тазия» высотой 55 футов накренилась и рухнула во время процессии в Мухаррам.
Инцидент произошел недалеко от Бхопала в Индии 2 октября.
Тазия является изображением гробницы имама Хусейна, внука пророка Мухаммеда.
Во время Мухаррама мусульмане выносят башни тазия в процессии, чтобы оплакать мученическую смерть имама Хусейна и 72 других людей в битве при Кербеле.
Процессия в Бхопале была катастрофой с самого начала.
Башня тазия была слишком высокой и качалась под собственным весом.
Организаторы, которые пытались удержать его в вертикальном положении, балансируя с разных сторон с помощью длинных канатов, поняли, что борются с безнадежным делом.
Преданные, которые тащили тазию по узким улочкам, подняли тревогу, когда она начала наклоняться. Чувствуя, что он вот-вот упадет, они побежали в поисках безопасности.
Их опасения оправдались, когда возвышающееся сооружение рухнуло на здание и разбилось на куски.
Сайед Джаффер Хуссейн из шиитской организации «Фронт защиты Вакфа» в Хайдарабаде сказал, что никто не пострадал, поскольку здание приняло на себя основной удар падения.
Он сказал, что сооружение было построено не очень хорошо. «Из-за дождей у организаторов осталось очень мало времени для работы над этим», — добавил он.
Джаффер сказал, что в Хайдарабаде и многих других местах высота тазии составляла в среднем шесть или семь футов.
Но в некоторых частях Индии разные регионы соревнуются за строительство самых высоких тазий в году, иногда поднимая их высоту даже до 100 футов.
На днях я наткнулась на статью, в которой обсуждалось, как стремительно машинный перевод завоевывает мир, и задумалась вот о чем. Кто-то утверждает, что скоро профессия переводчика станет пережитком прошлого, кто-то, напротив, приводит примеры нелепых ошибок автоматических систем. Конечно, мы все хоть раз сталкивались с казусами машинного перевода: когда привычное слово вдруг обретает совершенно новый смысл, или когда предложение превращается в набор странных фраз, лишенных логики.
Однако за кулисами этих неудач скрываются невероятные достижения в области технологий. Машинный перевод, который мы знаем сегодня, — это результат многолетней работы тысяч специалистов. Вопрос не в том, сможет ли машина заменить человека, а в том, как она учится понимать человеческий язык и превращать его в другой — иногда с идеальной точностью, а иногда с неожиданными ошибками. Давайте разберемся, как создаются и обучаются эти сложные системы, которые стремятся стать "универсальными переводчиками" нашего времени.
Машинные модели нуждаются в больших объемах данных, чтобы понимать закономерности языка и правильно переводить текст. На этапе сбора данных критически важны параллельные корпуса — тексты, переведенные на несколько языков. Один из таких корпусов — Europarl-ST, который содержит тексты заседаний Европарламента, переведенные на несколько языков. Его отличительной чертой является высокое качество и формальный стиль, характерный для официальных дискуссий.
Другой известный корпус — OpenSubtitles, который собран на основе субтитров к фильмам и сериалам. Этот корпус включает диалоги в более разговорной и неформальной манере, что делает его полезным для работы с живым языком.
Также существуют наборы данных, такие как FLORES и NTrex, специально разработанные для оценки качества перевода. Эти корпуса используются для тестирования машинных переводов и выявления их сильных и слабых сторон в различных языковых парах и стилях.
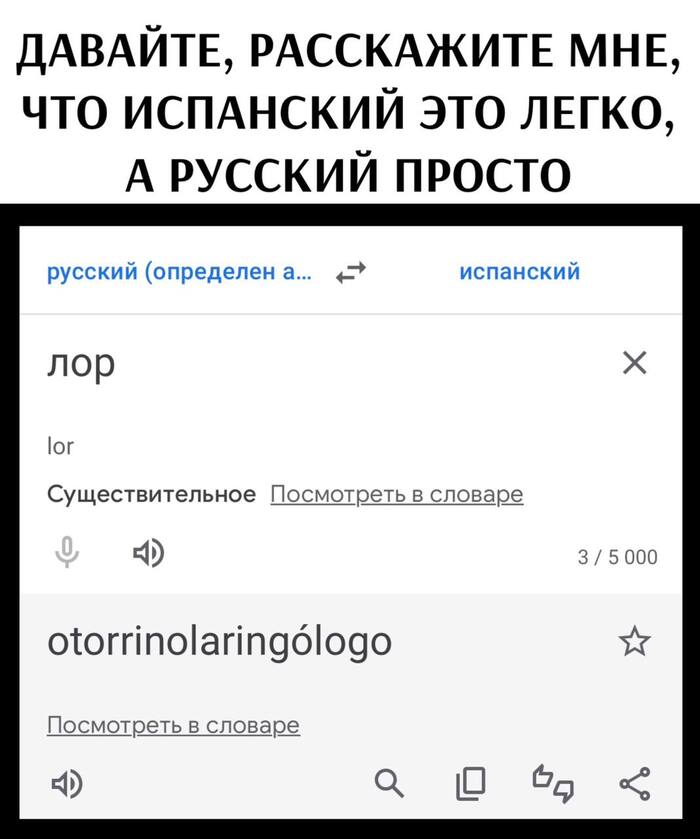
Для наиболее распространенных языковых пар, таких как английский и испанский, существует множество доступных параллельных текстов, но для редких языков (например, суахили или исландского) данные найти значительно сложнее.
Проблемы на этапе сбора данных:
Шум в данных: субтитры или тексты в социальных сетях могут содержать ошибки, неточности или непоследовательность перевода.
Нехватка данных для редких языков: для многих малораспространенных языков просто нет достаточного количества параллельных данных. В таких случаях используются методы обогащения данных (data augmentation) или перевод через промежуточный язык (pivot language).
Неполные или неточные выравнивания: параллельные корпуса могут содержать ошибки в выравнивании предложений, где одно предложение на одном языке не соответствует другому по смыслу или длине. Это может вводить модель в заблуждение, затрудняя корректное обучение.
Неоднородность доменов: корпуса данных могут включать тексты из разных доменов (например, технические, медицинские, художественные), и если модель обучается на данных из смешанных областей, это может снижать качество перевода для специфических тем. Специализированные модели требуют более узконаправленных данных для повышения точности в конкретных доменах.
Устаревшие данные: языки постоянно развиваются, и некоторые корпуса могут содержать устаревшие термины или фразы, что приводит к созданию переводов, не соответствующих современному языковому контексту. Это особенно заметно в быстрых изменениях, таких как сленг или технические термины.
После того как данные собраны, их необходимо тщательно обработать. Модели машинного перевода должны работать с «чистыми» текстами, чтобы минимизировать ошибки, вызванные шумом в данных. Этот этап включает несколько шагов:
Удаление дубликатов: нередко одни и те же предложения встречаются в разных корпусах. Чтобы модель не «переучилась» на повторяющихся данных, такие дубликаты необходимо удалить.
Фильтрация шума: некоторые корпуса могут содержать неправильно выровненные переводы или смешение языков. Такие тексты исключаются из корпуса.
Токенизация: процесс разделения текста на более мелкие части — слова или символы. Для языков, характеризующихся сложной морфологией (например, финского), могут использоваться методы токенизации подслов (subword tokenization), такие как Byte Pair Encoding (BPE) или SentencePiece. Эти методы позволяют эффективно работать с редкими словами, разрезая их на более мелкие компоненты, что улучшает перевод.
В начале эпохи нейронного машинного перевода использовались рекуррентные нейронные сети (RNN) и их более сложные версии, такие как LSTM (сети долгой краткосрочной памяти) и GRU (управляемый рекуррентный блок). Однако они оказались недостаточно эффективными для длинных предложений и сложных языковых конструкций.
Ситуация изменилась с появлением Transformer — архитектуры, которая опирается на механизм внимания (attention), который позволяет модели учитывать все слова в предложении одновременно, а не поочередно, как это делали RNN.
Преимущества архитектуры Transformer:
Параллелизм: модель может обрабатывать все слова в предложении одновременно, что значительно ускоряет обучение и инференс.
Например, если предложение звучит как «Кот бежит по траве», модель сразу видит и «кот», и «бежит», и «трава», а не по очереди.
Многоголовый механизм внимания: позволяет модели учитывать различные аспекты предложения (грамматика, контекст, значение отдельных слов) одновременно, что повышает качество перевода.
Допустим, вы рассказываете историю про кота, и для того чтобы понять, о чем идет речь, нужно помнить, что кот «бежит», а «по траве» — это место, где он бежит. Transformer одновременно обращает внимание и на действие (бежит), и на объект (кот), и на место (по траве), что помогает делать более точные переводы.
Глубокая архитектура: множество слоев энкодера и декодера позволяют модели лучше понимать сложные языковые зависимости.
Это похоже на многоуровневый процесс понимания. Сначала вы видите отдельные слова, затем начинаете замечать связи между ними, а на самых глубоких уровнях понимаете, почему кот бежит и к чему это ведет. Transformer использует множество слоев, которые помогают ему шаг за шагом разбираться не только в отдельных словах, но и в сложных взаимосвязях между ними.
Модели обучаются с использованием больших объемов данных и мощных вычислительных ресурсов. Этот процесс требует настройки гиперпараметров и использования алгоритмов оптимизации. Рассмотрим ключевые шаги обучения:
Функция потерь
Для обучения моделей обычно используется функция потерь кросс-энтропии. Она измеряет, насколько предсказанный перевод отличается от эталонного.
Представьте, что вы переводите предложение с одного языка на другой, а затем проверяете, насколько Ваш перевод совпадает с правильным вариантом. Модель делает нечто похожее. Это как если бы вы каждый раз получали оценку за свой перевод, и чем ближе она к 100%, тем лучше результат.
Алгоритмы оптимизации
Наиболее популярный алгоритм для обучения нейросетей — Adam, который сочетает преимущества метода стохастического градиентного спуска (SGD) и адаптивной оптимизации.
Когда вы учитесь, вы не запоминаете всю информацию сразу. вы допускаете ошибки, исправляете их и постепенно лучше понимаете материал. Алгоритм Adam работает аналогично. Он помогает модели учиться на своих ошибках и постепенно улучшать переводы, корректируя их с каждым шагом.
Регуляризация
Чтобы избежать переобучения, используются техники регуляризации, такие как Dropout, который «выключает» случайные нейроны на каждом этапе обучения, что делает модель более устойчивой к шуму в данных.
Скажем, вы учитесь кататься на велосипеде. Если ездить только по идеально ровной дороге, то любой крупный камень на пути может сбить с толку. Чтобы быть готовым к любым условиям, необходимо тренироваться в различных ситуациях. Регуляризация помогает модели не "привыкать" к слишком идеальным данным.
Обучение может занимать недели или даже месяцы, в зависимости от объема данных и вычислительных ресурсов.
После обучения модель необходимо оценить. Для этого применяются автоматические метрики, которые позволяют быстро и объективно сравнивать результаты разных моделей.
Основные автоматические метрики:
BLEU (Bilingual Evaluation Understudy): сравнивает машинный перевод с эталонным, подсчитывая совпадения слов и фраз.
Представьте, что вам нужно перевести фразу «Я люблю играть в футбол». Машинный перевод предлагает: «Мне нравится играть в футбол». BLEU проверяет, сколько слов совпадает между машинным и эталонным (человеческим) переводом. В данном случае слова «играть» и «в футбол» совпадают, поэтому BLEU оценит перевод как достаточно хороший, но не идеальный, поскольку слово «нравится» отличается от «люблю».
TER (Translation Edit Rate): измеряет количество правок, которые необходимо внести в машинный перевод, чтобы сделать его идентичным человеческому.
Машина перевела фразу «Я иду в школу» как «Я бегу в школу». TER подсчитает, что необходимо заменить слово «бегу» на «иду», чтобы сделать перевод правильным. Чем меньше правок потребуется, тем лучше оценка перевода.
COMET: современная метрика, которая учитывает контекст и смысл, что делает ее более надежной по сравнению с BLEU.
Если машинный перевод фразы «Она счастлива» будет «Ей радостно», COMET сможет понять, что, хотя слова разные, смысл сохраняется, и оценит перевод как хороший. BLEU мог бы снизить оценку из-за несовпадения слов, но COMET учитывает значение фраз и контекст, что делает его более надёжным.
Однако автоматические метрики не всегда точно отражают качество перевода. Для важных проектов, таких как литературный или юридический перевод, необходимо проводить ручную оценку качества, привлекая профессиональных переводчиков. Они оценивают не только точность, но и плавность, стиль и соответствие контексту.
Тем не менее, и в этом направлении уже заметны определенные достижения. Некоторые системы машинного перевода, например, Lingvanex, предлагают пост-обработку перевода с помощью LLM (больших языковых моделей), настроенных конкретно под ваш текст, его стиль и целевую аудиторию. Такой подход позволяет сократить время и затраты на редактирование перевода вручную.
После завершения основного этапа обучения модель может быть адаптирована для конкретных задач или доменов. Например, модель, обученная на общих данных, может демонстрировать недостаточную точность в технических, юридических или медицинских текстах. Для улучшения качества перевода в этих областях применяется дообучение (fine-tuning).
Медицинский перевод становится более точным благодаря дообучению моделей на специализированных текстах, содержащих медицинскую терминологию. Это помогает корректно переводить диагнозы, рецепты и медицинские статьи. В случае юридических переводов требуется максимально точное соответствие терминологии, поэтому модели дообучаются на юридических документах, чтобы избежать ошибок в трактовке законов и договоров. Переводы для IT также нуждаются в тщательной обработке: большое количество технических терминов требует правильной интерпретации в соответствующем контексте, и модели дообучаются на текстах с технической тематикой для повышения качества перевода.
Теперь, когда вы знаете, как обучаются модели для машинного перевода, следующий раз, когда вы увидите ошибку в переводе, вместо того чтобы лишь посмеяться, подумайте: что могло пойти не так? Ведь каждый перевод — это результат тысяч часов обучения и обработки колоссальных объемов данных. Представьте, что вы — модель перевода: сколько книг, фильмов и разговоров вам нужно перевести, чтобы стать настоящим экспертом в любом языке?
Машинный перевод — это не просто технологии. Это попытка научить компьютер думать как человек, понимать эмоции, контексты и намерения. И хотя до полного понимания еще далеко, одно ясно точно: каждый из нас может внести свой вклад в развитие этого процесса — просто используя машинный перевод, анализируя его результаты и помогая системе учиться на своих ошибках.








