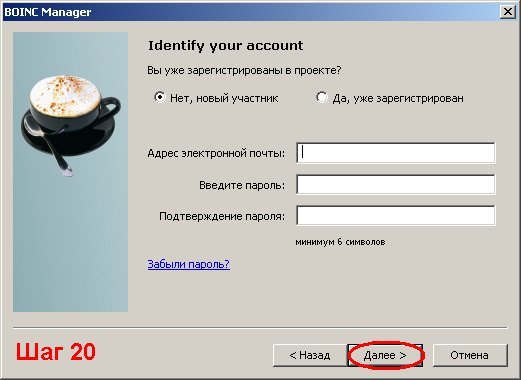
Технологии: "Искусственный интеллект" как обучают нейронные сети

Мы переживаем самый настоящий бум ИИ — чат-боты, нейросети для рисования, продвинутые системы распознавания и не только. Однако для работы с ИИ нужны соответствующие вычислительные мощности. Для этого могут использоваться в том числе нейронные ускорители. Что это за устройства, каковы их особенности и возможности?
Немного про обучение нейросетей
Для начала стоит понять, как именно происходит машинное обучение и почему для этого не подойдет любая вычислительная техника.
Если очень упростить, то нейросетевые операции используют буквально два основных действия — это умножение и сложение. Например, для распознавания каких-либо визуальных образов необходимо предоставить набор изображений и коэффициенты (веса), по которым мы будем искать конкретные признаки. Путем перемножения этих коэффициентов на анализируемое изображение нейросеть получает определенное значение. И если оно больше порогового, то она выдает результат. Например, что перед нами определенная цифра или объект.
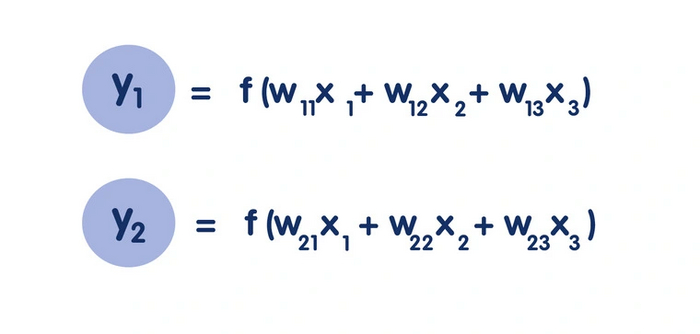
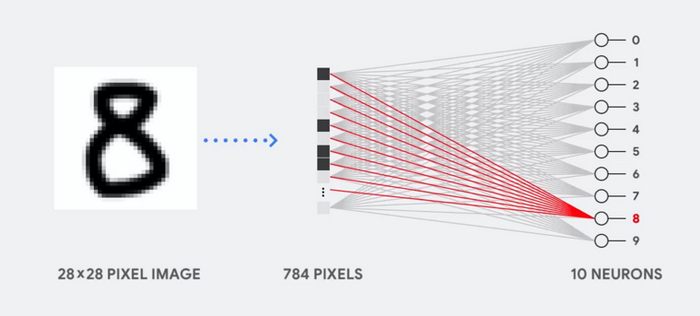
Главная проблема в том, что количество этих коэффициентов невероятно больше. Например, нейросеть из 10 нейронов, способная распознавать изображения 28 на 28 пикселей, требует 784 коэффициента для каждого слоя — итого 7840 весов.
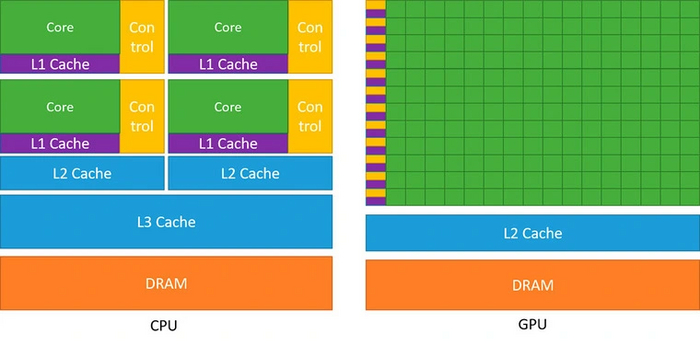
Как именно обрабатывать все эти вычисления? На первый взгляд, кажется логичным использовать центральный процессор (CPU). Однако он имеет одно существенное ограничение — низкий параллелизм. В архитектуре фон Неймана арифметико-логическое устройство (АЛУ) выполняет операции последовательно, каждый раз обращаясь к памяти. Да, в процессоре может быть множество ядер и АЛУ, но даже серверные модели предлагают в среднем не больше 64 ядер.
Центральный процессор может похвастаться высокой гибкостью — на нем можно запускать самые разные задачи и ПО. Однако для машинного обучения его архитектура подходит несильно, поскольку процесс требует выполнения множества однотипных задач сложения и умножения.
Куда большим уровнем параллелизма обладают видеокарты — GPU. Современная видеокарта способна выводить за раз 8 294 400 пикселей для разрешения 4K. И так 60 раз в секунду или даже чаще. Все это стало возможным исключительно благодаря многоядерной структуре. В GPU используются тысячи ядер, что и позволяет выполнять параллельную обработку большого объема данных.
Эти вычисления выполняют так называемые CUDA-ядра. Чем их больше, тем выше производительность видеокарты и тем лучше она справляется с высокими разрешениями.
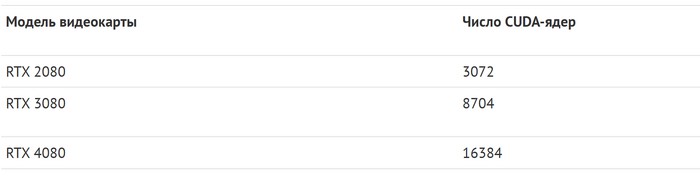
С совершенствованием архитектуры появились так называемые «тензорные ядра». Проще говоря, это вычислительный блок, который способен перемножать сразу целые матрицы.
Предположим, вам необходимо перемножить матрицу А на B:
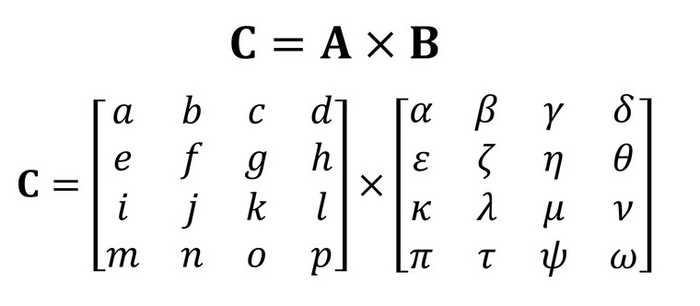
Расписав все это на шаги умножения и сложения, мы получим вот такой немаленький набор однотипных действий:
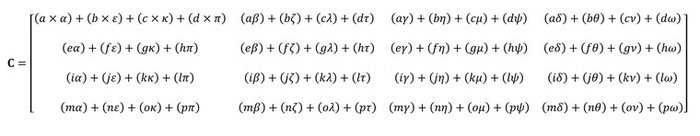
Ядро CUDA за один такт может выполнить простейшую операцию вроде 1 x 1. То есть для подсчета всей матрицы нам потребуется множество ядер и несколько тактов. Тензорные ядра работают сразу с матрицами и способны получить результат за один такт. Они как нельзя лучше подходят для машинного обучения.
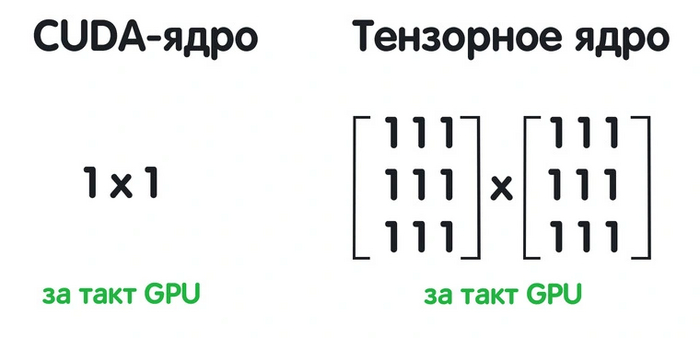
Зачем в принципе нужны тензорные ядра в видеокартах? Ответ кроется в технологии DLSS (Deep Learning Super Samplin). Это метод масштабирования, использующий возможности нейронных сетей, для которого как раз и нужны тем самые тензорные ядра. Не забывайте, что изображение — это фактически та же самая матрица.
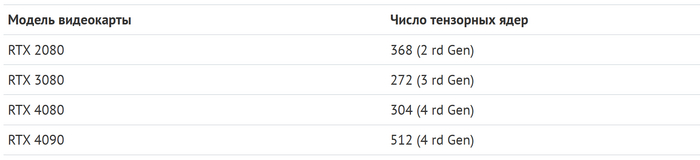
Именно за счет CUDA и тензорных ядер высокопроизводительные десктопные видеокарты вполне можно использовать для тренировки и запуска нейросетей.
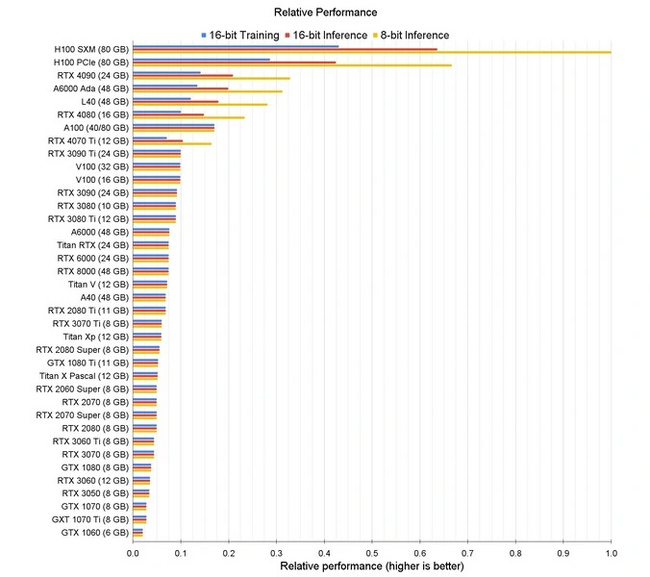
Если говорить о сугубо профессиональных решениях, то Nvidia пошла еще дальше, создав специализированные ускорители в том числе для обучения ИИ. Например, линейка устройств Tesla.

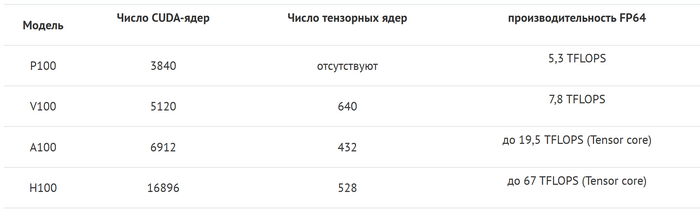
Архитектура этих устройств уже учитывает специфику задачи, а также такие платы имеют больший объем видеопамяти и шину по сравнению с десктопными.
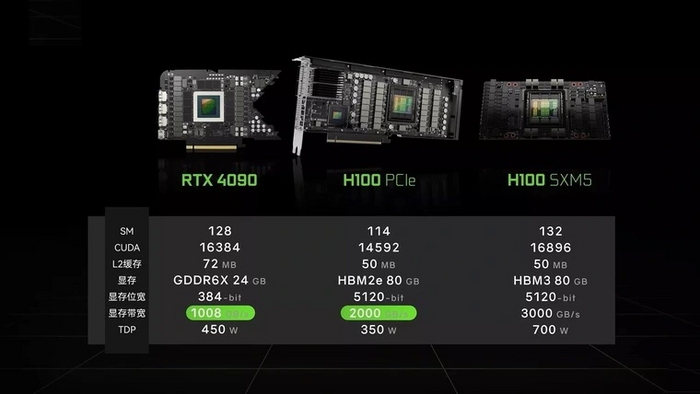
Все это дает ощутимый прирост в производительности конкретно под CNN (сверточные нейросети) и трансформеры (глубокие нейронные сети).
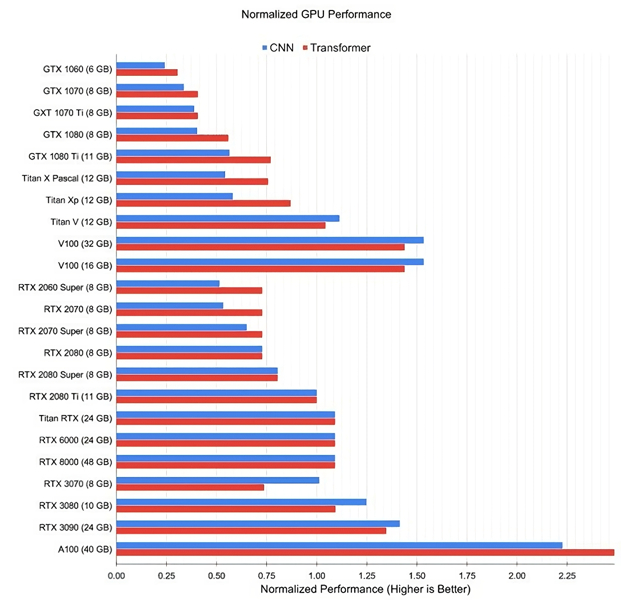
Несмотря на главенствующую позицию Nvidia, ее GPU-ускорители являются не единственным решением для обучения и выполнения нейросетей.
Тензорные процессоры Google
Платы Tesla от Nvidia хоть и считаются узкоспециализированными GPU, но все еще относительно универсальные — с их помощью можно вести моделирование погоды, анализ финансового риска и различные научные исследования. С началом активного развития ИИ специалисты задумались: а что, если спроектировать устройство исключительно для работы с машинным обучением. Так появилось понятие TPU — Tensor Processing Unit, а первые наработки представила Google в 2016 году.
Работа с нейросетями обычно включает два основных этапа — обучение и выполнение. Первый процесс самый трудоемкий, поскольку требует множества вычислительных операций с плавающей точкой. Однако для выполнения уже обученной нейронной сети (распознавание объектов, задачи сортировки и поиска) не требуется высокая точность, в приоритете выполнение большого объема операций умножения и сложения. И вот здесь специализированные тензорные процессоры показали свои возможности.
Модель TPU v1 имела довольно скромные характеристики — 28 МБ встроенной памяти и ОЗУ 8 ГБ DDR3. Устройство было ориентировано на работу с фирменной математической библиотекой TensorFlow от Google. Внутреннее применение тензорного процессора показало, что плата более энергоэффективная — производительность на ватт в 25-80 раз больше по сравнению с GPU и CPU. Сравнивали разработку с актуальными на то время Intel Haswell Xeon E5 2699 v3 и NVIDIA K80. Тестировали на примере сверточных (CNN), рекуррентных (RNN) и многослойных нейросетей.
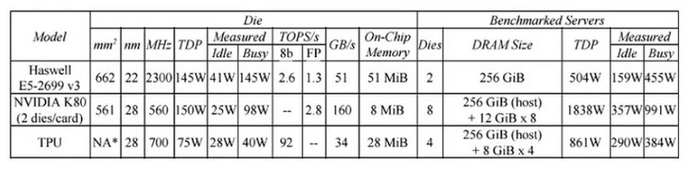
Уже в 2017 году был представлен TPU v2, а дальше — TPU v3, TPU v4 и TPU v5e. Новейший Cloud TPU v5p имеет 95 ГБ памяти HBM3 и производительность в BF16 — 459 Тфлопс.
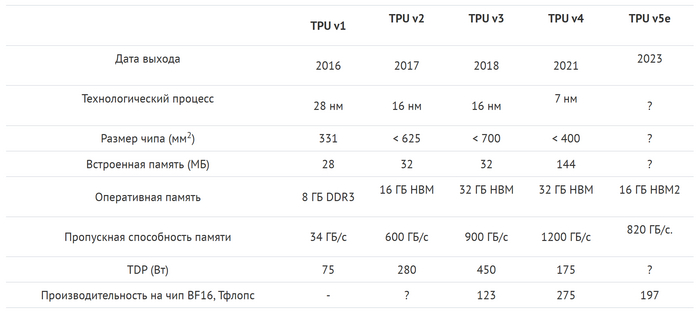
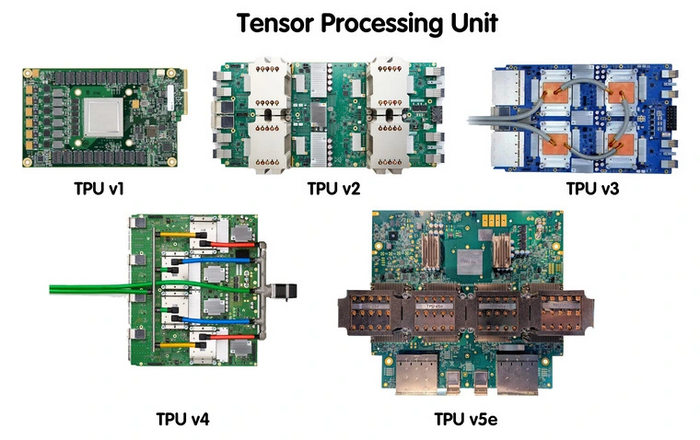
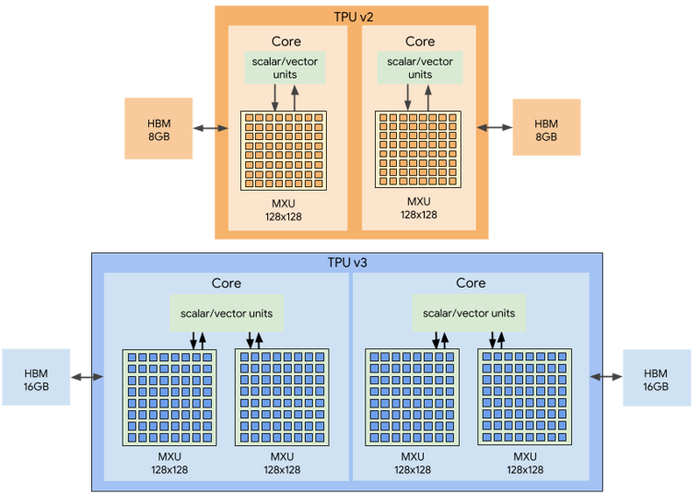
Ключевой особенностью TPU стала ориентация на обработку матриц. Инженеры сделали упор на множители и сумматоры, откинув все лишнее и сформировав архитектуру конвейерного массива. Например, TPU v2 (4 чипа) использует два конвейерных массива по 128 х 128, что в сумме дает 32 768 ALU. Производительность всего блока уже выросла до 180 TFLOPS. Это позволило не только выполнять обученные нейросети, но и тренировать их с нуля.
Например, один Cloud TPU (8 ядер и 64 ГБ ОЗУ) более чем в 5 раз быстрее Nvidia V100. Эти результаты получены по количеству обрабатываемых изображений в секунду на оптимизированных под TPU моделях.
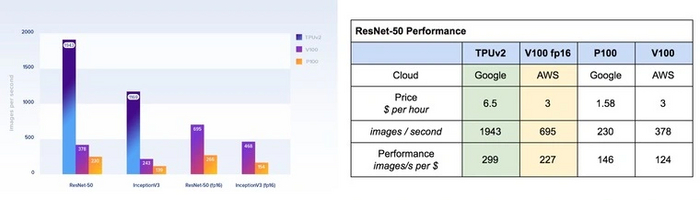
В TPU v3 увеличили число доступных множителей MXU на ядро, что по заявлению специалистов Google повысило производительность до 8 раз.
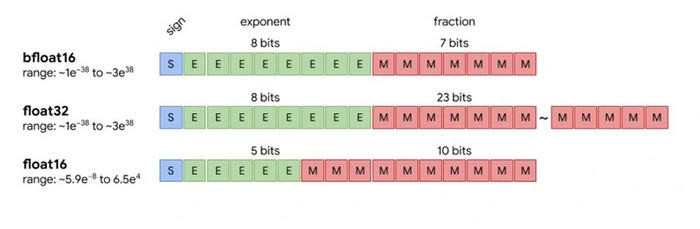
Помимо этого инженеры разработали новый формат представления данных. Для машинного обучения обычно используется FP32 — формат с плавающей точкой с одинарной точностью. Однако расчеты в нем требуют повышенной вычислительной мощности. Для оптимизации работы с TPU инженеры разработали формат Bfloat16 для операций умножения. За счет этого удалось снизить объем данных, который передается по каналам связи, повысив производительность системы.
Первоначально тензорные процессоры использовались в системе AlphaGo. Это тот самый компьютер, который обучался игре в «го» и смог победить в 2016 году Ли Седоля — многократного призера различных соревнований. Как выяснилось позже, обыграть корейского мастера смогли всего 50 плат TPU. Позже разработчики провели игру с еще одним мировым профессионалом Кэ Цзе. AlphaGo разгромила его с использованием всего одной платы TPU. Более того, даже пять профессионалов в совместной игре не смогли одолеть компьютер.

Также компания использует тензорные процессоры в сервисе Google Street View, выделяя текст на уличных знаках с фотографий. В Google Фото один тензорный процессор способен обработать до 100 миллионов изображений в день. На текущий момент решения Google TPU — это облачные платформы и сторонним разработчикам по регионам доступны ограниченно в зависимости от версии.
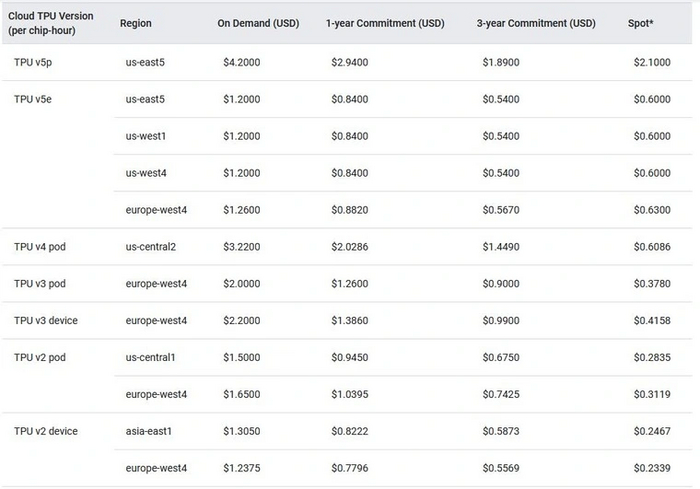
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...