
Ответ на пост «Про "нежизнеспособность" экономической модели СССР»1
Напишите пожалуйста, какой был рост ВВП СССР с 1953 по 1963 годы?
Какова была доля ВВП СССР в 1953 и 1963 году относительно общемирового ВВП?
Напишите пожалуйста, какой был рост ВВП СССР с 1953 по 1963 годы?
Какова была доля ВВП СССР в 1953 и 1963 году относительно общемирового ВВП?

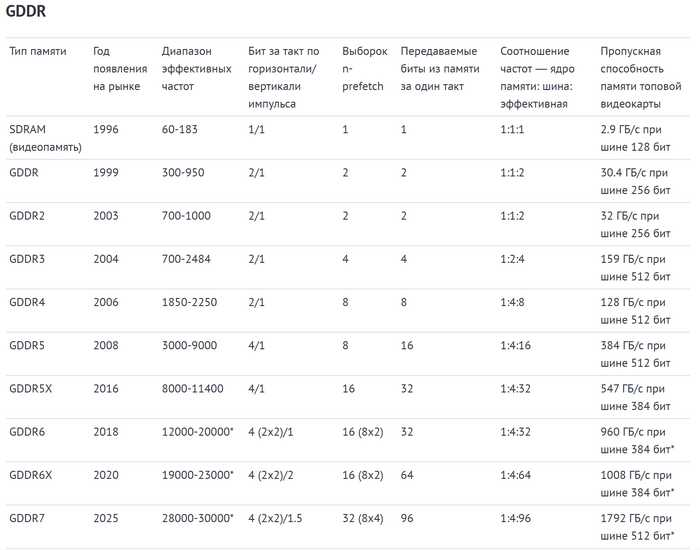
Поколения оперативной и видеопамяти сменяются через каждые несколько лет. В каждом из них производятся улучшения, нацеленные на повышение производительности. Значением, измеряющим скорость работы памяти, является эффективная частота. Однако она не является частотой работы чипов памяти, а достигается благодаря многим ухищрениям.
До середины 90-х годов прошлого века сменилось множество поколений оперативной памяти. Относительно современный период развития ОЗУ начинается в 1996 году с появления Synchronous Dynamic Random Access Memory (SDRAM). Это первая разновидность оперативной памяти, у которой появился тактовый генератор. Память стала синхронной. Это значит, что все ее компоненты — ядро памяти, буферы ввода-вывода и внешняя шина — работают на одной частоте.
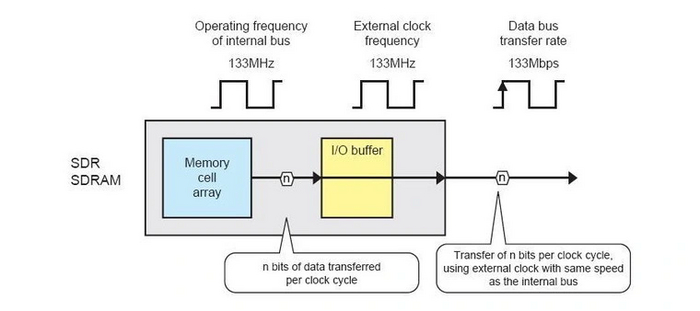
Изначально новый тип памяти был достаточно дорог. В основном, он использовался в производительных графических адаптерах. В качестве ОЗУ SDRAM стала массово распространяться с 1997 года, когда на рынке появились процессоры Intel Pentium II и AMD K6.
Типичная частота SDRAM — 66–133 МГц. Напряжение питания — 3.3 В. Как и у всех последующих типов ОЗУ, ширина шины памяти модуля составляет 64 бита. Однако чипсеты того времени не поддерживали многоканальные режимы памяти. Поэтому пропускная способность памяти (ПСП) в системах с несколькими модулями SDRAM была точно такой же, как и в компьютерах с одной планкой: от 0.5 до 1 ГБ/c. В видеокартах предельная ширина шины была вдвое выше, да и сама память могла работать на более высоких частотах — 150-183 МГц. Это давало ПСП вплоть до 2.9 ГБ/c.
В 2000 году на свет появилась первое поколение памяти типа DDR (Double Data Rate, удвоенная скорость передачи данных). Основы работы DDR стали ключевыми для возможности линейного наращивания производительности ОЗУ, и используются в ее всех последующих поколениях.
DDR основана на предшественнице SDRAM. Ключевое отличие в том, что данные из ядра памяти выбираются не один раз за такт, а дважды. Эта технология получила название 2n-prefetch. Чтобы успевать передавать удвоенное количество данных по внешней шине без увеличения ее физической частоты, информация тоже стала передаваться дважды за такт — на фронте и спаде тактового сигнала.
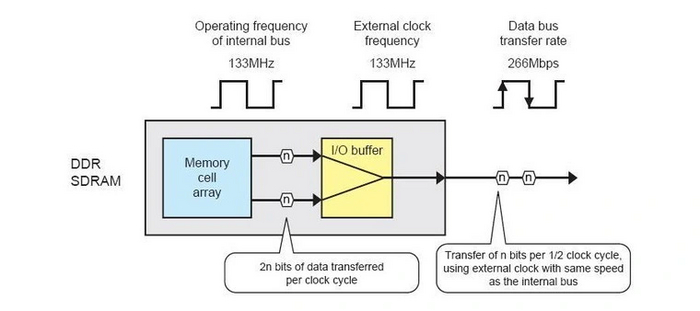
При частоте внутренних компонентов в те же 133 МГц, что и у SDRAM, память DDR передает вдвое больше информации. То есть, аналогично SDR при частоте 266 МГц. Поэтому было введено понятие «эффективная частота памяти». Оно показывает, на какой частоте должна работать память SDR, чтобы получить такую же пропускную способность. Это и стало основной характеристикой новой ОЗУ.
При этом стандарт JEDEC подразумевает использование термина «мегатрансфер в секунду» вместо «мегагерц», что означает «миллионов произведенных транзакций передачи в секунду». Но производители памяти в маркетинговых материалах вместо этого агрессивно использовали эффективную частоту в МГц, поэтому термин «МТ/c» не прижился на рынке памяти. Таким образом, с приходом DDR реальная частота работы микросхем памяти перестала упоминаться.
Стандартное напряжение питания DDR составило 2.5 В. Распространение новая память получила c приходом на рынок процессоров Intel Pentium 4 и AMD Athlon. Типичная эффективная частота DDR — 266-400 МГц, хотя существуют модули, которые способны работать на частоте до 700 МГц.
Важным моментом в период распространения DDR стало появление двухканальных контроллеров памяти у чипсетов. Вследствие этого на некоторых материнских платах стало возможным удвоить пропускную способность ОЗУ добавлением второй планки. В одноканальном режиме ПСП массовой DDR составляет от 2.1 до 3.2 ГБ/c, разогнанных модулей — до 5.6 ГБ/c.
Два первых поколения графической памяти получили названия GDDR и GDDR2 (сокращение от Graphics DDR). Они работают по принципу, схожему с обычной DDR. Оба вида получили оптимизации для увеличения тактовой частоты, жертвуя повышением задержек — ведь они для видеопамяти, в отличие от системной ОЗУ, не так важны. GDDR может работать со скоростью до 950 МГц, GDDR2 — до 1000 МГц.
Ширина шины памяти у топовых видеокарт к моменту расцвета графической DDR увеличилась до 256 бит. Из-за сравнимых частот оба поколения GDDR вместе с такой шиной достигали примерно одинаковой пропускной способности — 30-32 ГБ/c.

В конце 2003 года появилась память DDR второго поколения. Технологию выборки усовершенствовали: теперь это 4n-prefetch, которая выбирает данные из памяти четыре раза за такт. Чтобы успевать передавать столько данных, частоту буфера и шины памяти по сравнению с DDR первого поколения увеличили вдвое. Благодаря этим изменениям эффективную частоту удалось еще раз удвоить без поднятия частоты самой памяти.
Для более простого понимания разберем пример. У микросхем DDR с частотой 133 МГц шина памяти и буфер вывода работают на такой же частоте. Эффективная частота ОЗУ при этом составляет 266 МГц — за счет передачи данных дважды за такт. У микросхем DDR2 с частотой 133 МГц шина памяти и буфер работают на удвоенной частоте в 266 МГц. А за счет передачи данных дважды эффективная частота вырастает еще в два раза — до 533 МГц.
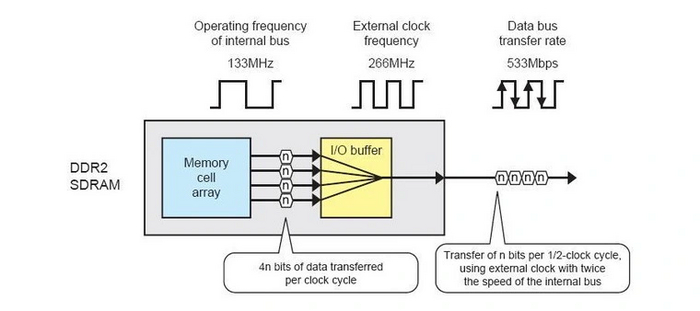
Возросшая эффективная частота поспособствовала кратному увеличению пропускной способности. Но более «широкая» выборка данных практически кратно увеличила и задержки памяти. Поэтому первые модули DDR2 и чипсеты с их поддержкой не могли похвастать ощутимым увеличением производительности, а то и вовсе оказывались медленнее решений на DDR.
Чтобы получить видимый прирост производительности от новой памяти, потребовались процессоры нового поколения — Intel Core 2 и AMD Athlon X2. Их распространение началось в 2007 году. Надо сказать, что подобный подход к раскрытию потенциала новой памяти сохранится и в отношении каждого последующего поколения ОЗУ: и DDR3, и DDR4, и самой современной DDR5.
При эффективной частоте от 533 до 1200 МГц пропускная способность памяти составляла от 4.2 до 9.6 ГБ/c. Двухканальный режим, который к тому времени значительно распространился у чипсетов материнских плат, помогал удвоить эти значения. Стандартное напряжение питания DDR2 составило 1.8 В. У планок с повышенной частотой оно могло достигать 2.1 В.
GDDR3 была разработана для видеокарт на базе обычной DDR2. Как и в прошлых поколениях GDDR, для нее использовались частотные оптимизации. Благодаря им эффективная частота GDDR3 с 2004 по 2009 год выросла с 800 до 2500 МГц.
За счет GDDR3 пропускная способность памяти видеокарт заметно выросла. У моделей с 256-битной шиной она достигла 70 ГБ/c. Но самую «крутую» реализацию GDDR3 получила линейка видеокарт NVIDIA GeForce GTX200. Благодаря широкой 512-битной шине скорость обмена данных с памятью у топа серии GTX285 достигла отметки в 159 ГБ/c.

2007 год принес компьютерному миру новую память DDR3, вновь удвоившую эффективные частоты относительно прошлого поколения. Принцип повышения производительности оказался таким же, как и в прошлый раз. Выборка из памяти теперь производится восемь раз за такт вместо четырех (8n-prefetch), а частоты работы буфера и шины вновь удвоены. При этом само ядро памяти работает в диапазоне 100-266 МГц, как и у DDR2.
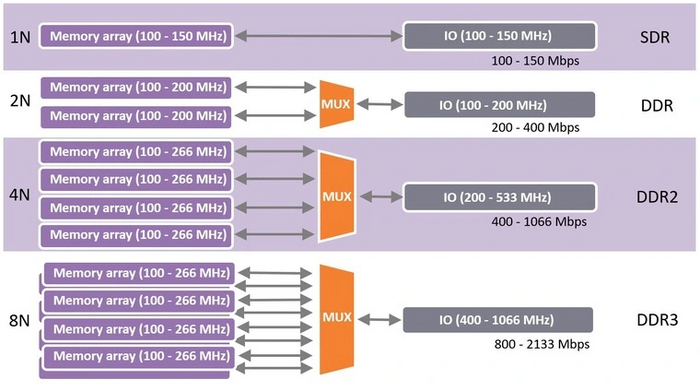
«Детские болезни» у новой памяти на старте продаж были те же самые: низкий рост производительности и повышенные задержки. Впервые заметный прирост скорости работы с памятью DDR3 обеспечила процессорам Intel Core i7 первого поколения, которые были выпущены в конце 2008 года. Тогда под платформу LGA1366 был разработан новый чипсет с трехканальным контроллером памяти. На тот момент скорость памяти составляла скромные 800–1066 МГц. Со временем массовые планки достигли частот в 1600–1866 МГц. Важным новшеством DDR3 стала поддержка технологии Extreme Memory Profile (XMP). Она позволяет модулю памяти иметь специальные профили для работы на повышенных частотах, обеспечивая «легальный» разгон. Благодаря XMP топовые планки DDR3 смогли достичь потолка частоты в 2933 МГц, что дает пропускную способность для одного модуля в 23.4 ГБ/c.
Стандартное напряжение DDR3 составило 1.5 В, но при задействовании профиля XMP могло повышаться до 1.65 В. В 2010 году был утвержден стандарт DDR3L с пониженным напряжением питания 1.35 В. Первые планки с его поддержкой использовались в ультрабуках, но спустя три года стали распространяться в обычных ноутбуках и десктопных компьютерах.
Графическая память GDDR4 основана на обычной DDR3. Еще до ее выхода на рынок, во второй половине 2006 года, свет увидела первая видеокарта с GDDR4 — ATI Radeon X1950 XTX. При этом по эффективной частоте новая память даже в момент выхода недалеко ушла от предшественницы. А позже — и вовсе уступила «старой» GDDR3.
Спустя полтора года после появления развитие GDDR4 приостановилось в связи со скорым выходом видеопамяти следующего поколения. Ее максимальная эффективная частота в серийных видеокартах составила 2250 МГц.
Память GDDR5 также основана на DDR3, и использует аналогичную выборку 8n-prefetch. Но у всех прошлых поколений памяти эффективная частота вдвое превышает частоту шины. А главное новшество GDDR5 — не вдвое, а вчетверо большая эффективная частота.
Это стало возможным благодаря одновременной трансляции двух параллельных сигналов, у каждого из которых все также по две передачи данных за такт. И хотя память использует в названии аббревиатуру «DDR», технически это QDR — Quad Data Rate (учетверенная скорость передачи данных). Для более эффективного использования пропускной способности у широких шин видеокарт GDDR5 имеет не 64-битные, а 32-битные каналы доступа. Обе эти особенности сохранятся и у всех последующих поколений GDDR.
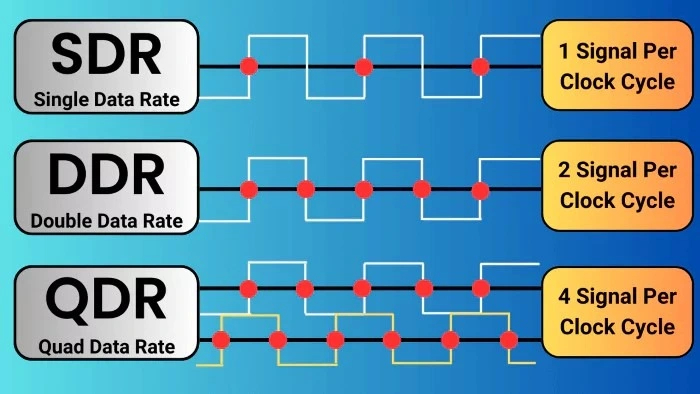
Это поколение видеопамяти очень долго господствовало на рынке. Первая видеокарта с GDDR5 появилась в 2008 году: ей стала ATI Radeon HD4870. Последние модели появились в 2019 году — это NVIDIA GeForce GTX 1660 и GTX 1650. За этот долгий временной период, благодаря новым техпроцессам и оптимизациям, эффективные частоты памяти возросли с 3600 до 9000 МГц.

При использовании 512-битной шины новая память уже на старте обеспечила бы на две трети возросшую пропускную способность по сравнению с топовыми вариантами GDDR3/GDDR4. Однако производители видеокарт решили пойти путем экономии, сузив шины обмена данными у флагманских видеокарт до 256 или 384 бит. В итоге, у первой видеокарты с GDDR5 ПСП составила 115 ГБ/c, а у последних решений на базе этой памяти достигла внушительных 336 ГБ/c.
2014 год подарил миру оперативную память нового поколения — DDR4. Как и DDR3, она использует выборку 8n-prefetch. Но теперь данные выбираются одновременно из двух банков памяти, а не из одного. Впрочем, обе выборки в итоге все равно проходят через мультиплексор, который объединяет их поток. Поэтому такая выборка не равнозначна более широкой 16n-prefetch, но эффективнее, чем обычная 8n у DDR3.
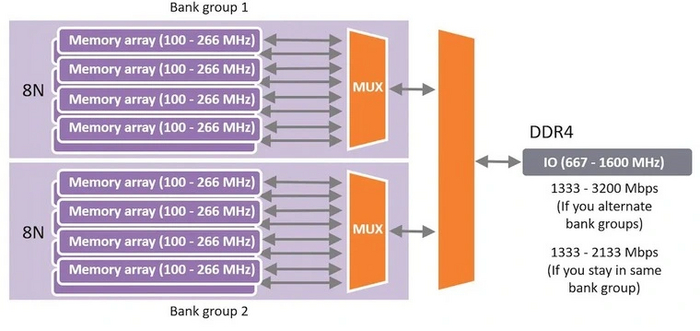
Подобное решение не могло полностью скомпенсировать отсутствия удвоенного числа выборок, как между прошлыми поколениями памяти. Поэтому двукратного роста скорости DDR4 не показала. Эффективные частоты стандартной памяти начинаются с 2133 МГц и заканчиваются на отметке 3200 МГц. Топовые планки с поддержкой XMP позволяют увеличить этот потолок до частоты 5000 МГц — на 70 % больше, чем у флагманской DDR3.
Стандартное напряжение питания DDR4 составило 1.2 В. Планки с поддержкой XMP обычно требуют 1.35 В, но у топовых модулей это значение может достигать 1.6 В. Впервые памятью DDR4 обзавелась высокопроизводительная платформа Intel LGA2011-v3. Помимо ОЗУ нового поколения, процессоры под нее получили целых четыре канала DDR4-2400.
Широкое распространение DDR4 началось в 2015 году c выходом шестого поколения Core и платформы Intel LGA1151, которая поддерживала и прошлую DDR3. Разницы между двумя видами памяти на ней еще практически не было — чуть более высокие частоты нивелировали повысившиеся задержки. Полноценно новая память стала раскрываться только в 2017 году, с приходом платформ LGA1151 v2 от Intel и AM4 от AMD.
Один топовый модуль DDR4-5000 способен обеспечить пропускную способность до 40 ГБ/c. Однако контроллеры памяти процессоров оказались не готовы к прямой работе с такими частотами. Поэтому с приходом высокочастотной DDR4 последним платформам с ее поддержкой была добавлена возможность использования делителей памяти. Они позволяют контроллеру работать с вдвое меньшей частотой, чем сам модуль.
В этот раз передовые технологии первой получила не оперативная, а видеопамять — GDDR5X. Она была выпущена в 2016 году, и получила в два раза более широкую выборку 16n-prefetch. Таким образом, эффективная частота с этого поколения в восемь раз превышает частоту шины памяти.
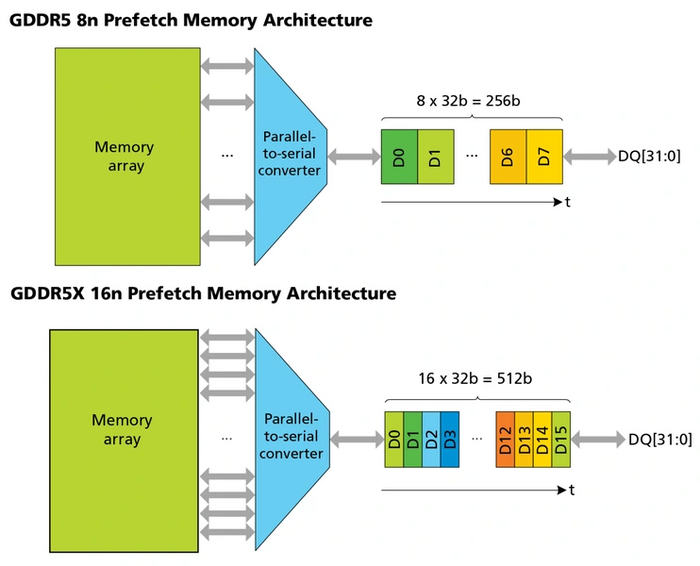
Благодаря более широкой выборке производительность могла бы увеличиться вдвое. Но память получилась горячей, поэтому частоту ее ядра пришлось понизить. В результате максимальная эффективная частота увеличилась по сравнению с GDDR5 не так сильно — с 9000 до 11400 МГц.

Пропускная способность в топовых видеокартах на базе GDDR5X достигла значения в 547 ГБ/c. При этом напряжение питания памяти снизилось с 1.5 до 1.35 В.
Из-за высокого тепловыделения GDDR5X массовой так и не стала. Эту роль на себя приняла GDDR6, впервые увидевшая свет в 2018 году. Она имеет аналогичное напряжение и принцип формирования эффективной частоты, но с одним важным улучшением. Теперь каждый 32-битный канал памяти поделен на два внутренних по 16 бит, а вместо однопоточной выборки используется двухпоточная 16n-prefetch (или 2x8n). Это позволяет отправлять больше запросов к памяти одновременно, и повышает ее эффективность в сложных задачах.
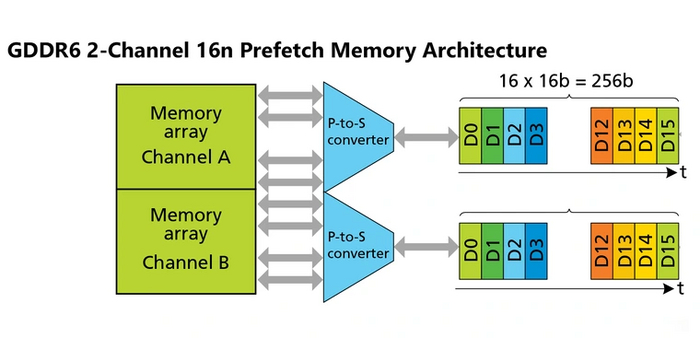
Эффективная частота памяти снова возросла, охватив широкий диапазон от 12000 до 20000 МГц. GDDR6 остается актуальной и на сегодняшний день, достигнув во флагманских видеокартах AMD пропускной способности в 960 ГБ/c.

Следующее поколение видеопамяти увидело свет в 2020 году, дебютировав в топовых видеокартах серии GeForce RTX 3000. GDDR6X представляет собой дальнейшее развитие идей GDDR6, в очередной раз увеличивая отрыв эффективной частоты от частоты шины памяти до шестнадцатикратного.
В этом памяти помогла новая технология кодирования сигнала 4 Pulse Amplitude Modulation (PAM4), которая заменила ранее используемую NRZ. Она позволяет передавать данные в одном импульсе не дважды, а четырежды за такт. Это происходит благодаря четырем уровням кодирования сигнала, тогда как ранее их было только два.
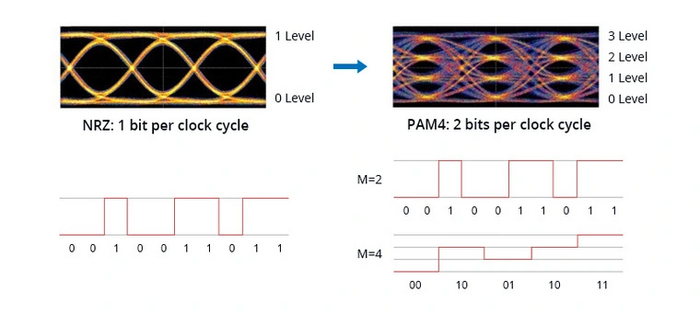
GDDR6X оказалась лишь немного быстрее предшественницы, так как изменений в самой выборке не произошло. На момент выхода ее эффективная частота достигала 19 ГГц, тогда как GDDR6 довольствовалась планкой в 16 ГГц. Оба вида памяти развивались параллельно, поэтому разрыв между ними не увеличился: сегодня GDDR6 может обеспечить 20 ГГц, а GDDR6X — 23 ГГц эффективной частоты. При этом память с приставкой «X», как и в прошлом поколении, оказалась заметно горячее.
Технологии, применяемые в GDDR6, послужили основой для обычной DDR5, впервые появившейся на рынке в 2021 году. Этот тип ОЗУ также использует двухпоточную выборку 16n-prefetch, разделяя каждый канал памяти на два внутренних. Ключевое отличие от GDDR6 — DDR5 передает данные за такт дважды, а не четырежды. То есть это истинная DDR, а не QDR. Поэтому эффективная частота у нее заметно ниже, чем у графической предшественницы.
В каждый модуль DDR5 встроена коррекция ошибок (ECC), тогда как у предшествующих поколений DDR она была только в серверных планках. За счет этого новое поколение модулей имеет два канала по 40 бит. В каждом из них для ECC используется 8 бит, а для данных — 32 бита. То есть, ширина шины для передачи данных осталась неизменной — это те же 64 бита, что и у прошлых поколений памяти, просто поделенные на две части.
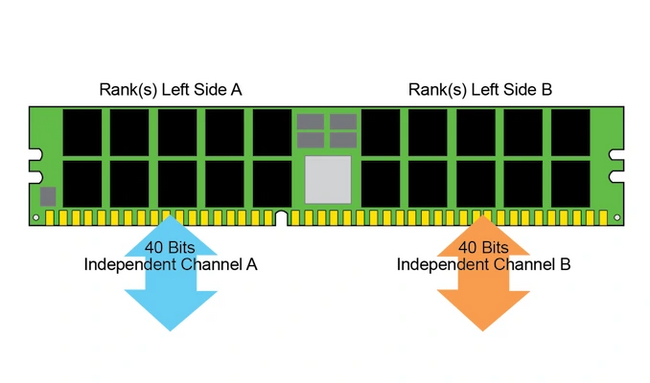
В отличие от DDR4, у которой данные с двух выборок попадали в один мультиплексор, каждый канал DDR5 работает независимо. Поэтому новое поколение памяти наконец принесло ожидаемое удвоение эффективных частот. Даже самая медленная DDR5 работает на частоте в 4800 МГц, что практически равно скорости самой топовой ОЗУ прошлого поколения.
DDR5 дебютировала в 2021 году вместе с процессорами Core 12 поколения и платформой Intel LGA1700. Как и в случаях с прошлыми поколениям ОЗУ, её первые модули обладали высокими задержками и практически не имели преимуществ в работе перед DDR4. Но с массовым распространением новой памяти и постепенным снижением таймингов прирост от нее стал заметен даже на первой платформе с ее поддержкой, не говоря о более новых AMD AM5 и Intel LGA1851.
Но к 2023 году скорости DDR5 стали потихоньку упираться в очередное препятствие. Длинные дорожки, соединяющие контроллер ОЗУ в процессоре и чипы памяти на планках DIMM и SO-DIMM, стали вносить в работу быстрой DDR5 помехи. Из-за этого дальнейший рост частот стал проблематичным.
Чтобы обойти эту проблему, было представлено два решения. Первый — появившийся в 2023 году новый форм-фактор памяти CAMM2. Он сокращает длину соединений между ЦП и чипами памяти, значительно уменьшая эти помехи. Есть и еще одно ключевое преимущество: возможность организовать широкий 128-битный доступ к памяти, заменяя одним модулем CAMM2 два модуля DIMM или SO-DIMM.
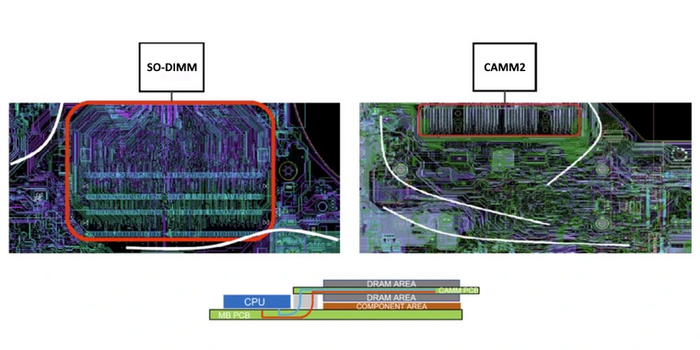
Однако CAMM2 нацелен больше на ноутбуки— ведь в них модули DDR5 SO-DIMM нередко заменялись распаянной на плате ОЗУ. Для декстопных ПК гораздо больше подошло второе решение, появившееся в 2024 году — планки CUDIMM. Они схожи с обычными планками DDR5 DIMM и имеют обратную совместимость, но для решения вопроса с помехами оснащаются собственной микросхемой тактового генератора. Такой микросхемой могут оснащаться не только полноразмерные модули DIMM, но и компактные планки SO-DIMM и CAMM2.
К концу 2023 года частота DDR5 уперлась в потолок чуть выше 8000 МГц, но благодаря CUDIMM и CAMM2 снова стала расти. На начало 2025 года выпускаются модули DDR5 с эффективной частотой в 10000 МГц, которые в разгоне уже превышают потолок в 12000 МГц.
При этом DDR5 продолжает развиваться, а вот контроллеры памяти в процессорах пока такую скорость не осиливают. Если для быстрой DDR4 приходилось использовать делитель памяти 1:2, то для топовой DDR5 необходим уже делитель 1:4 — тогда контроллер работает лишь на одной четверти от эффективной частоты самих планок.
Графическая видеопамять GDDR7, как и три поколения ее предшественниц, увидела свет вместе с очередной серией видеокарт NVIDIA. В январе 2025 года она дебютировала в моделях линейки RTX 5000, первыми из которых стали RTX 5080 и RTX 5090.

GDDR7 является дальнейшим развитием и объединением ранее использованных идей. У DDR5 она позаимствовала встроенную коррекцию ошибок (ECC). У GDDR6 — деление одного канала передачи на внутренние. Причем уже на два, а на целых четыре. Каждый из них имеет ширину в 10 бит, 2 из которых используются для работы ECC. Таким образом, общая ширина передачи данных остается равной 32 битам. Но, как и в GDDR6, для каждого внутреннего канала используется своя выборка 8n. Это обеспечивает памяти GDDR7 четырехканальную выборку 32n-prefetch (4x8n).
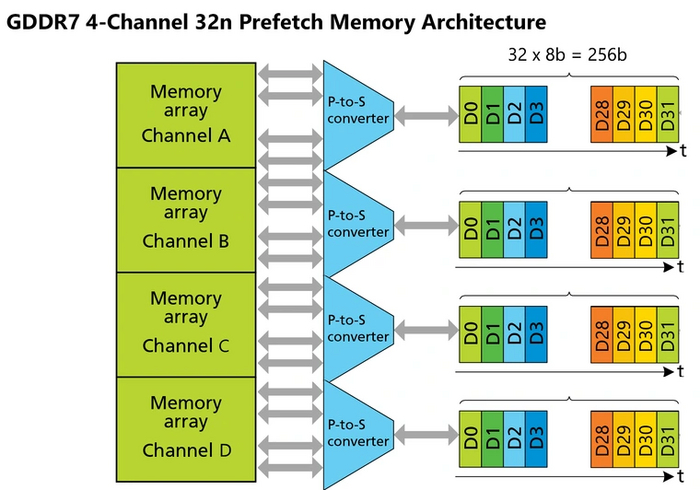
По сравнению с двумя прошлыми поколениями видеопамяти выборка увеличилась вдвое. А вот увеличить аналогично частоту буфера — задача не из легких. Тут бы пригодилась технология PAM4, используемая в GDDR6X. Но помехи воспрепятствовали распознаванию четырех уровней сигнала на столь высоких частотах. Поэтому было решено использовать 3 Pulse Amplitude Modulation (PAM3) — она работает аналогично предшественнице, но позволяет передавать данные в одном импульсе не четырежды, а трижды за такт.
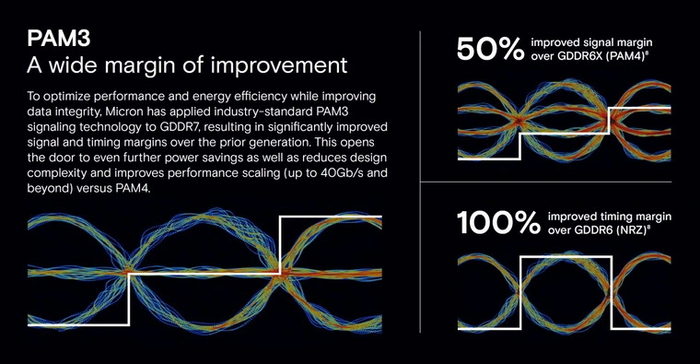
Уже в первых видеокартах GDDR7 достигла эффективной частоты в 28000-30000 МГц. Ближе к концу жизненного цикла для неё ожидаются значения, эквивалентные 48000 МГц (или МТ/c — кому как удобнее ).
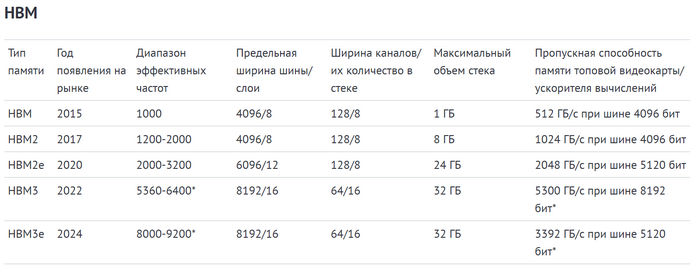
High Bandwidth Memory (HBM) — память с высокой пропускной способностью, предназначенная для конкуренции с семейством DDR в высокопроизводительных видеокартах, профессиональных и серверных решениях. HBM интегрируется на подложку вычислительного чипа (ЦП или ГП), поэтому не отнимает место на плате, как в случае с чипами DDR/GDDR.
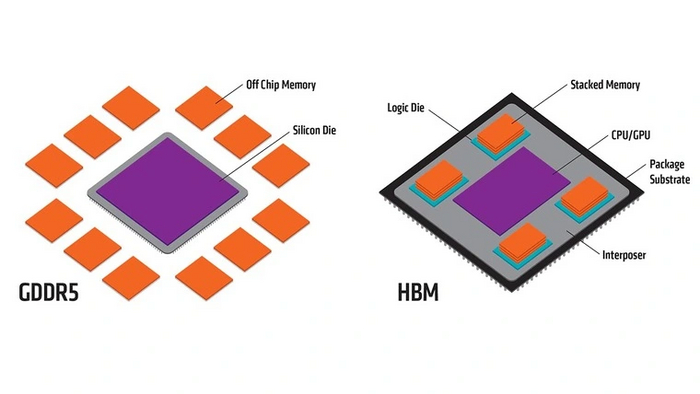
HBM — это многослойная память, слои которой накладываются друг на друга подобно этажам в доме. За счет непосредственной близости к вычислительному кристаллу стало возможным значительно расширить интерфейс взаимодействия с ней. Один канал связи с памятью HBM обладает шириной в 128 бит. На каждый слой приходятся два таких канала. При этом память точно так же, как и DDR, может передавать данные дважды за такт. Четыре слоя образуют стек, который в итоге имеет 1024-битную шину доступа.
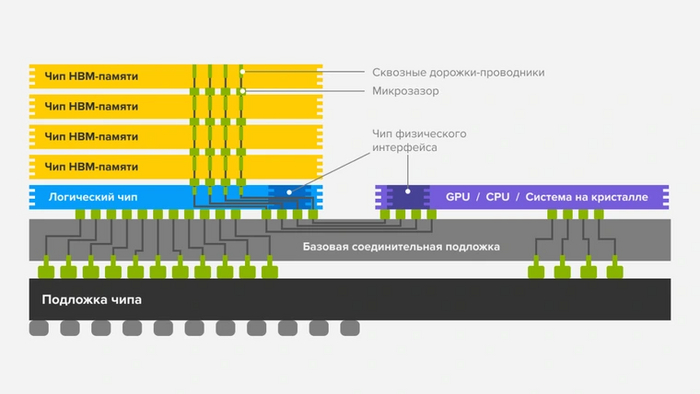
Cтек HBM первого поколения имеет объем в 1 ГБ. Дебютным графическим процессором с поддержкой HBM стал AMD Fiji. Он использует четыре стека HBM. Таким образом получаются 4 ГБ памяти с шиной доступа в 4096 бит.
Невероятные цифры по сравнению с GDDR, не так ли? Но эффективная частота HBM намного ниже, чем у ее конкурента — около 1000 МГц. Однако и этого хватило, чтобы значительно превысить показатели ПСП GDDR5 в момент появления на рынке. Первое поколение памяти в потребительских видеокартах появилось в серии видеокарт AMD Fury в 2015 году. Ее пропускная способность составила 512 ГБ/c против 336 ГБ/c у топовых решений на GDDR5. Однако был и явный минус — малый объем памяти при четырех стеках, который являлся ограничением для первого поколения HBM.
Этого недостатка лишилась HBM2, появившаяся в 2017 году. Стек HBM2 имеет объем в 4 ГБ и такую же 1024-битную шину, но работает на частоте до 2000 МГц. Как и прежде, для получения полной 4096-битной шины нужно четыре стека, из которых получается 16 ГБ HBM2. Изначально HBM2 появилась в профессиональных ускорителях NVIDIA Quadro GP100, а затем и в игровых картах AMD: Vega 64 и Vega 56.
В отличие от серии Fury, в этот раз игровые модели AMD получили два стека, которые образовали 8 ГБ памяти при 2048-битной шине. Наиболее полно в игровых видеокартах HBM2 раскрылась в 2019 году. Тогда была выпущена топовая модель Radeon VII с четырьмя стеками и максимальной скоростью памяти, пропускной способность которой достигла 1024 ГБ/c.
К сожалению, на этом история перспективной памяти в игровых ПК пока завершается. И NVIDIA, и AMD используют память типа HBM в профессиональных и серверных ускорителях, но в игровые видеокарты она больше не попадает. Это связано в первую очередь с высокой стоимостью HBM: топовая GDDR на данный момент немного медленнее, но ощутимо дешевле.
В ускорителях вычислений развитие памяти продолжилось. В них в 2020 году появилась обновлённая HBM2 со стеками размером 8 ГБ. Параллельно ей началось распространение HBM2e. Она представляет собой улучшенную версию HBM2 с поддержкой 12 слоев памяти вместо 8. Это позволяет увеличить максимальную ширину шины до 6144 бит и расширить предельный объем памяти стека до 24 Гб. При этом повысилась и частота памяти — до 3200 МГц против 2000 МГц у HBM2. Предельная ПСП может достигать 2457 ГБ/c, но в реальных продуктах максимальная конфигурация HBM2e не использовалась.
HBM3 увидела свет в 2021 году. Она поддерживает до 16 слоев памяти. Это позволяя расширить шину доступа до 8192-битной, а объем памяти стека — до 32 ГБ. Для более эффективного распараллеливания доступа один слой теперь имеет не два 128-битных, а четыре 64-битных канала памяти. К тому же, максимальная частота памяти возросла в два раза — до 6400 МГц. Это позволяет увеличить пропускную способность до 6553 ГБ/c.
HBM3e была представлена в 2023 году. При схожих с HBM3 основных характеристиках, её эффективная частота памяти может достигать 9600 МГц. За счёт этого обеспечивается невероятная пропускная способность — до 9830 ГБ/c.
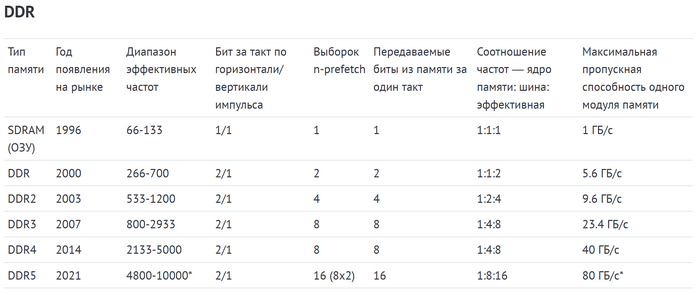
Вы познакомились практически со всеми видами оперативной и видеопамяти за последние три десятилетия. Сравнить их основные технические характеристики можно в таблицах ниже. Для удобства память SDRAM присутствует в них дважды – и в качестве оперативной, и в качестве видеопамяти.

Рынок форматов ОЗУ долго существовал без каких-либо новшеств. Модули DIMM и SO-DIMM не меняли своей конструкции с конца 90-х годов до наших дней, лишь разменивая поколения DDR. Первой весточкой грядущих изменений недавно стал формат CAMM2, а теперь появился еще один — CUDIMM. В чем его преимущества и недостатки? Станет ли он массовым, или останется нишевым решением?
Первый вопрос, который закономерно возникнет у читателя: зачем нужно вводить новые решения, если старые годами работали стабильно и зарекомендовали себя с хорошей стороны? На первый взгляд это действительно непонятно. Но если вникнуть в изначальную мотивацию разработки что CAMM2, что CUDIMM, мы увидим одну и ту же причину для обоих — достижение более высоких частот ОЗУ.
В последние годы чипы оперативной памяти развиваются очень быстро. C массовым распространением ОЗУ типа LPDDR, которая распаивается на платах устройств, производители получили доступ к более высоким частотам, чем могут предложить сменные планки. В первую очередь потому, что в случае с распаянными чипами длина соединений между ними и контроллером памяти в процессоре гораздо короче, а перекрестных помех заметно меньше.

Из-за этого память с самыми высокими частотами по умолчанию уже много лет попадает сначала в смартфоны, а потом в ноутбуки с распаянной LPDDR. И лишь после этого очередь доходит до модулей DIMM. К примеру, в смартфонах первая LPDDR5-5500 появилась уже в конце 2019 года, тогда как в десктопных компьютерах дебют DDR5 с аналогичной частотой состоялся почти через пару лет.
И CAMM2, и CUDIMM призваны сравнять быстродействие сменных модулей памяти и распаянной ОЗУ. Цель у них одна, а вот способы ее достижения разные.
CUDIMM, в отличие от CAMM2, не является совершенно новым форм-фактором оперативной памяти. Это разновидность обычных модулей Unbuffered DIMM (UDIMM) с одним важным отличием — собственным тактовым генератором Clock Driver (CKD).

Для большинства читателей не секрет, что контроллер памяти в современных компьютерных системах находится в процессоре. В случае с UDIMM именно контроллер памяти задает тактовую частоту микросхем и согласует тайминги так, чтобы обеспечить оптимальную работу системы.
Проблема в том, что при высокой частоте тактовый сигнал по длинным соединениям, свойственным системам с модулями UDIMM, превращается в этакую «кашу». Памяти DDR4 в свое время это не коснулось, так как даже топовые планки не превысили порог эффективной частоты в 5 ГГц. А вот DDR5 этому подвержена: чтобы «прыгнуть» выше 8 ГГц по ОЗУ, необходимо обзавестись процессором с удачным контроллером памяти. Иначе стабильности на таких частотах «оперативки» не видать.

CUDIMM призваны решить эту проблему. Здесь сигналы от процессора поступают не на чипы памяти, а на генератор CKD. Он служит буфером, который принимает тактовый сигнал, а затем регенерирует его и перераспределяет на чипы памяти. Все это делается с учетом расстояний соединений и задержек между компонентами модуля.
Благодаря такой конструкции сигнал высокой частоты доходит до памяти без частотной «каши». Поэтому становится намного легче реализовать возможности самых быстрых чипов DDR5.

Идея CUDIMM не нова и уходит корнями в регистровую память RDIMM. Такая ОЗУ устанавливается в серверы и имеет отдельный регистровый чип. Отличие в том, что функциональность такого чипа шире. Он, помимо тактового сигнала, буферизует также команды (CMD) и адреса (ADR). Это нужно, чтобы согласовывать работу при большом количестве чипов и модулей ОЗУ.

В серверах можно встретить три или четыре модуля на каждый канал памяти. В десктопах подобное согласование не нужно, так как модулей на канал максимум два. Да и большого количества чипов на одной планке тут не встречается. Поэтому чип на CUDIMM устроен намного проще, чем на RDIMM. У него всего 35 контактов, половина из которых — питание и заземление.
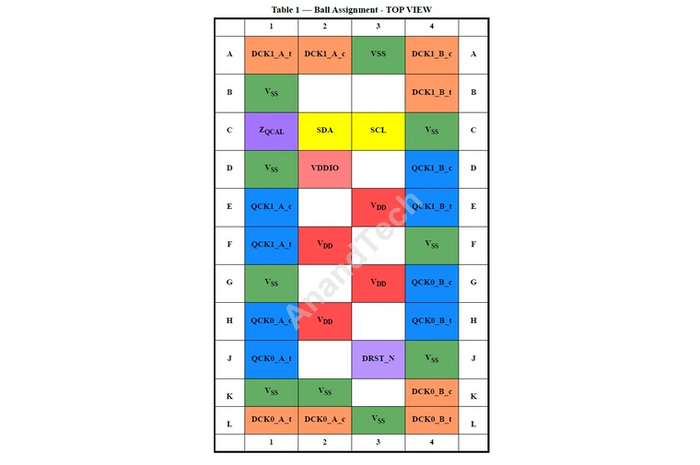
Благодаря относительной простоте устройства, себестоимость производства и внедрения чипа CKD на модули CUDIMM заметно меньше, чем в случае с регистровым чипом на RDIMM.
В отличие от CAMM2, модули CUDIMM совместимы с обычными разъемами DIMM. То есть, их можно установить и в существующие платы с поддержкой памяти DDR5. Для более гибкой подстройки под разные конфигурации микросхема CKD имеет три режима работы фазовой подстройки частоты (Phase Lock Loop, PLL), между которыми можно переключаться в зависимости от ситуации.
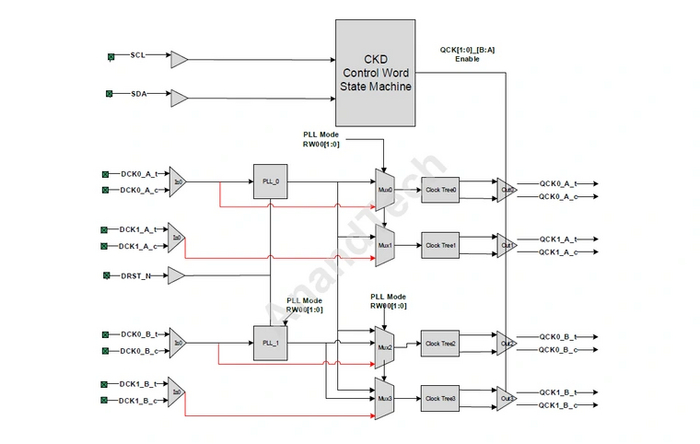
Dual PLL. Используется два входящих импульса, чтобы генерировать два независимых импульса для каждого из внутренних каналов планки памяти DDR5. Этот метод предпочтителен при хорошем качестве входящего сигнала.
Single PLL. Используется один из входящих импульсов, чтобы генерировать два одинаковых импульса на оба внутренних канала планки памяти DDR Данный метод нужен тогда, когда по одному из входящих импульсов слишком много «шума», а сохранить высокую частоту требуется.
PLL Bypass. Режим обхода, отключающий регенерацию импульсов на CKD. В этом режиме CUDIMM работает как обычная планка UDIMM, со всеми ее достоинствами и недостатками. Официально данный режим рекомендуется для частот от 6000 МГц и ниже, но может использоваться и на более высоких значениях.
Три режима работы обеспечивают планкам CUDIMM наиболее широкую совместимость как с существующими, так и с будущими процессорными платформами. В остальном новый формат не отличается от обычных UDIMM. Здесь точно так же можно использовать готовые частотные профили XMP и EXPO, а для настройки планки и мониторинга ее состояния используется стандартная интерфейсная шина I2C или I3C.
Модули CUDIMM стандартизированы JEDEC в начале 2024 года. Несмотря на то, что многие производители продолжают развивать обычные высокочастотные модули UDIMM, планки нового формата уже выпущены несколькими китайскими компаниями. В их числе V-Color, Biwin и Asgard.

На данный момент крупные производители пока не анонсировали собственные модули CUDIMM. Возможно потому, что еще не до конца проработан вопрос их совместимости с процессорами Intel и AMD прошлых поколений. Но каких-то конструктивных препятствий для работы CUDIMM с любым процессором, оснащенным контроллером памяти DDR5, нет. Для этого должно понадобится лишь обновление BIOS.
Память с тактовым генератором будет распространяться не только в формате CUDIMM. Стандартом JEDEC уже предусмотрены планки CSODIMM, которые в некоторых источниках также называют Mini CUDIMM. Они представляют собой ноутбучные DDR5 SO-DIMM с чипом CKD.

На производительные модули CAMM2/LPCAMM2 будет устанавливаться точно такой же чип. Учитывая изначально короткие соединения у планок этого формата, CKD даст им еще больше возможностей по достижению предельного потолка частот.
CUDIMM — не революция, а плановая эволюция модулей оперативной памяти. В чем-то она напоминает ситуацию с переводом чипов с плоских планарных транзисторов на трехмерные FinFET: когда возможности стали упираться в одну технологию, на смену ей пришла другая. То же самое и с ОЗУ: когда частоты возросли настолько, что передавать сигнал без помех стало затруднительно, на помощь пришло новое решение — дополнительный тактовый генератор.
Пока частоты топовых модулей UDIMM и CUDIMM примерно равны. Но с выходом платформы Intel LGA1851 и расширением ассортимента CUDIMM на рынке, такие планки смогут достичь более высокого частотного потолка — от 10 ГГц и выше.

В ноутбуках, неттопах и моноблоках с появлением новых поколений процессоров пригодится компактная память CSODIMM. Но наибольший прирост принесут обновленные CAMM2/LPCAMM2: этому поспособствуют и короткие соединения, и применение тактового генератора.
Нужна ли такая высокочастотная память прямо сейчас? Массовому пользователю — нет, но энтузиастам пригодится. Поэтому основной массой планок DDR5 в ближайшее время останутся старые добрые UDIMM, которых будет достаточно для большинства применений. И лишь для топовых конфигураций будет профит от более редких и дорогих CUDIMM. Это касается и компактных вариантов нового формата памяти — что CSODIMM, что CAMM2/LPCAMM2 с CKD.
Однако со временем память с тактовым генератором будет проникать в более низкие ценовые сегменты. Если высокий темп роста частот сохранится, то не исключено, что с выходом DDR6 чип CKD станет не опциональным, а обязательным атрибутом практически всех планок нового поколения памяти.

Одна из главных характеристик процессоров и других микрочипов — техпроцесс. Что означает этот термин и насколько он влияет на производительность?
Ключевым элементом практически каждой вычислительной схемы является транзистор. Это полупроводниковый элемент, который служит для управления токами. Из транзисторов собираются основные логические элементы, а на их основе создаются различные комбинационные схемы и уже непосредственно процессоры.

Чем больше транзисторов в процессоре — тем выше его производительность, ведь можно поместить на кристалл большее количество логических элементов для выполнения разных операций.
В 1971 году вышел первый микропроцессор — Intel 4004. В нем было всего 2250 транзисторов. В 1978 мир увидел Intel 8086 и в нем помещались целых 29 000 транзисторов. Легендарный Pentium 4 уже включал 42 миллиона. Сегодня эти числа дошли до миллиардов, например, в AMD Epyc Rome поместилось 39,54 миллиарда транзисторов.
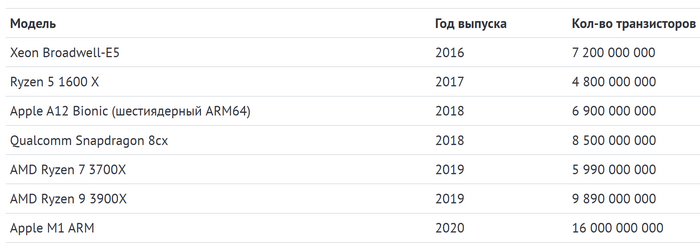
Много это или мало? По информации на 2020 год на нашей планете приблизительно 7,8 миллиардов человек. Если представить, что каждый из них это один транзистор, то полтора населения планеты с легкостью поместилась бы в процессоре Apple A14 Bionic.

В 1975 году Гордон Мур, основатель Intel, вывел скорректированный закон, согласно которому число транзисторов на схеме удваивается каждые 24 месяца.
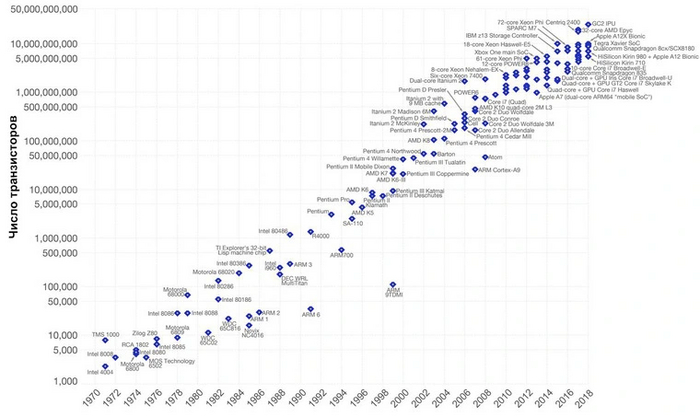
Нетрудно посчитать, что с момента выхода первого процессора до сего дня, а это всего-то 50 лет, число транзисторов увеличилось в 10 000 000 раз!
Казалось бы, поскольку транзисторов так много, то и схемы должны вырасти в размерах на несколько порядков. Площадь кристалла у первого процессора Intel 4004 — 12 мм², а у современных процессоров AMD Epyc — 717 мм² (33,5 млрд. транзисторов). Получается, по площади кристалла процессоры выросли всего в 60 раз.

Как же инженерам удается втискивать такое огромное количество транзисторов в столь маленькие площади? Ответ очевиден — размер транзисторов также уменьшается. Так
и появился термин, который дал обозначение размеру используемых
полупроводниковых элементов.
Упрощенно говоря, техпроцесс — это толщина транзисторного слоя, который применяется в процессорах.
Чем мельче транзисторы, тем меньше они потребляют энергии, но при этом сохраняют текущую производительность. Именно поэтому новые процессоры имеют большую вычислительную мощность, но при этом практически не увеличиваются в размерах
и не потребляют киловатты энергии.
Первые микросхемы до 1990-х выпускались по технологическому процессу 3,5 микрометра. Эти показатели означали непосредственно линейное разрешение литографического оборудования. Если вам трудно представить, насколько небольшая величина в 3 микрометра, то давайте узнаем, сколько транзисторов может поместиться в ширине человечного волоса.
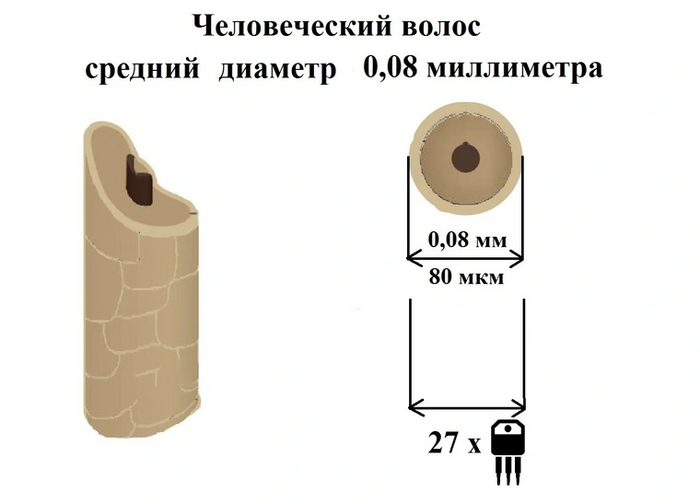
Уже тогда транзисторы были настолько маленькими, что пару десятков с легкостью помещались в толщине человеческого волоса. Сейчас техпроцесс принято соотносить с длиной затвора транзисторов, которые используются в микросхеме. Нынешние транзисторы вышли на размеры в несколько нанометров.
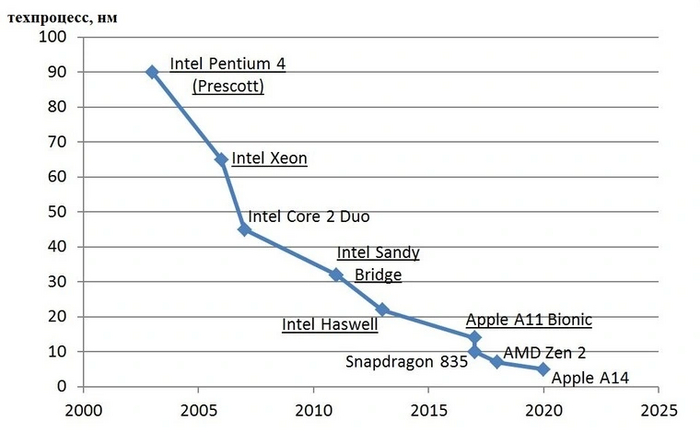
Для Intel актуальный техпроцесс — 14 нм. Насколько это мало? Посмотрите в сравнении
с вирусом:

Однако по факту текущие числа — это частично коммерческие наименования. Это означает, что в продуктах по техпроцессу 5 нм на самом деле размер транзисторов не ровно столько, а лишь приближенно. Например, в недавнем исследовании эксперты сравнили транзисторы от Intel по усовершенствованному техпроцессу 14 нм и транзисторы от компании TSMC на 7 нм. Оказалось, что фактические размеры на самом деле отличаются не на много, поэтому величины на самом деле относительные.

Рекордсменом сегодня является компания Samsung, которая уже освоила техпроцесс 5 нм. По нему производятся чипы Apple A14 для мобильной техники. Одним из является Apple M1 — ARM процессор, который установлен в ноутбуках от Apple.

Уменьшение размеров транзисторов позволяет делать более энергоэффективные и мощные процессоры, но какой предел? На самом деле ответа никто не знает.
Проблема кроется в самой конструкции транзистора. Уменьшение прослойки между эмиттером и коллектором приводит к тому, что электроны начинают самостоятельно просачиваться, а это делает транзистор неуправляемым. Ток утечки становится слишком большим, что также повышает потребление энергии.
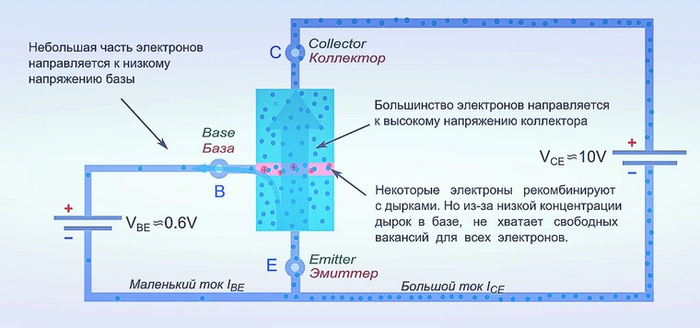
Не стоит забывать, что каждый транзистор выделяет тепло. Уже сейчас процессоры Intel Core i9-10ХХХ нагреваются до 95 градусов Цельсия, и это вполне нормальный показатель. Однако при увеличении плотности транзисторов температуры дойдут до таких пределов, когда даже водяное охлаждение окажется полностью бесполезным.
Самые смелые предсказания — это техпроцесс в 1,4 нм к 2029 году. Разработка еще меньших транзисторов, по словам ученых, будет нерентабельной, поэтому инженерам придется искать другие способы решения проблемы. Среди альтернатив — использование передовых материалов вместо кремния, например, графена.

Магнитная лента не исчезла насовсем и до сих пор используется в дата-центрах.
Это — одно из главных преимуществ магнитных лент. Когда в середине девяностых на прилавках магазинов появились коммерческие винчестеры объёмом в 1 ГБ, ленточные картриджи модели DDS-3 уже вмещали в двенадцать раз больше информации.
Немного истории
Некоторые исторические данные о ценах, чтобы увидеть, как менялась стоимость гигабайта. Конечно, гигабайт был смехотворной концепцией для всех, кроме true 13375 в 80-х.

Данные это подтверждают: существует очень сильная экспоненциальная корреляция в соотношении пространства/стоимости (r=0,9916). За последние 30 лет стоимость единицы пространства удваивалась примерно каждые 14 месяцев (увеличиваясь на порядок каждые 48 месяцев). Уравнение регрессии имеет вид:

Несколько терабайтных+ накопителей недавно преодолели барьер в $0,10/гигабайт, установив следующую веху в $0,01/гигабайт или $10/терабайт. Это вызывает скептицизм даже у самых ярых сторонников экспоненциального прогресса технологий. Как долго может продлиться эта тенденция? Приближаемся ли мы к концу эпохи закона Мура?
Наше время
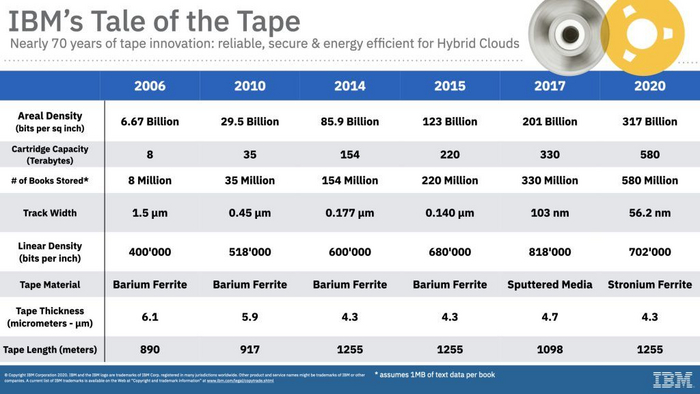
В наше время сложилась аналогичная ситуация. Современные картриджи содержат больше километра ленты шириной в 12,6 миллиметра. На неё можно записать до 580 ТБ сжатых данных. При этом объём жёстких дисков для enterprise-сегмента лишь недавно побил отметку в 30 ТБ.

По сегодняшним потребительским стандартам магнитные ленты медленные, неудобные в использовании и относительно дорогие. Как оказалось, магнитная лента может предложить емкость, недоступную для современных жестких дисков. По крайней мере, IBM и Fujifilm считают, что их недавно разработанный магнитный слой из феррита стронция (SrFe) позволит лентам LTO-8 хранить до 580 ТБ данных. Речь идет о плотности записи 317 ГБ/кв.дюйм, при длине ленты 1255 метров и общей емкости 580 ТБ.

Магнитная лента развивается подобно жестким дискам. Разработчики стремятся уменьшить ширину дорожки, чтобы увеличить плотность записи, уменьшить толщину ленты, чтобы увеличить длину ленты в картридже, и внедрить новые методы для надежной записи и последовательного чтения данных.
Стоимость хранения данных на магнитной ленте значительно ниже, чем у любых других накопителей. Один гигабайт на жёстком диске обходится примерно в $0,025. Для ленты этот показатель составляет $0,008. Известен случай с одной крупной генетической лабораторией, когда переход на магнитную ленту сократил расходы на хранение данных с $800 тысяч всего до $7 тысяч. При этом крупные ИТ-компании сегодня продолжают разрабатывать технологии, расширяющие возможности магнитных лент.
Известно, что ошибки на магнитной ленте возникают на четыре–пять порядков реже, чем в HDD. При правильном хранении они могут прослужить около 30 лет. Это больше, чем любые другие популярные сегодня накопители — HDD или SSD. Согласно статистике одного из крупных облачных провайдеров средний срок службы жёстких дисков редко превышает четыре года. Что касается твердотельных накопителей, по некоторым данным, они проживут порядка десяти лет, но только если устройствами регулярно пользоваться.
ИТ-компании по-прежнему разрабатывают технологии, задача которых — продлить срок жизни магнитной ленты. Два года назад IBM совместно с Sony представили плёнку, покрытую дополнительным смазочным слоем. Он защищает поверхность ленты от повреждения при её движении на скорости десять метров в секунду во время чтения.
Одной из главных причин «ренессанса» магнитной ленты является тот факт, что многие недостатки, которыми она обладала в свои ранние годы, сегодня удалось исправить. Ранее накопитель подразумевал лишь последовательный доступ к данным, поэтому на поиск и чтение информации уходило 50–60 секунд. Для сравнения, у жёсткого диска этот показатель равен 5–10 миллисекундам.
Современные технологии нивелировали влияние этого недостатка. Новые картриджи поддерживают файловую систему LTFS. Она индексирует содержимое ленты, что ускоряет чтение данных и создаёт иллюзию произвольного доступа к ним.
Более того, ленточные хранилища, устанавливаемые в дата-центрах, автоматизированы. Масштабные роботизированные библиотеки могут занимать целый машинный зал. Особые манипуляторы выполняют автоматический поиск необходимых картриджей и оперативно загружают их в считывающие устройства.

Компании, которым необходимо обрабатывать (и архивировать) большое количество данных. В первую очередь — ИТ-гиганты и облачные провайдеры. Ленты хранят бэкапы и другие редко используемые данные. К примеру, в 2011 году баг в системе привёл к удалению писем пользователей Gmail. Тогда компания Google восстановила данные именно с магнитных лент.
Магнитными лентами пользуются и исследовательские организации, например CERN. Каждую секунду Большой адронный коллайдер генерирует один гигабайт данных. Суммарный объём информации, собранной институтом по сей день, превышает 330 петабайт.
Для их хранения организация использует систему CASTOR на магнитной ленте, разработанную инженерами CERN. Её регулярно обновляют и переводят на более совершенные типы картриджей, чтобы увеличить ёмкость, надёжность и скорость работы. Вышедшие из эксплуатации накопители организация отдаёт инвесторам в качестве сувениров.
Также среди пользователей магнитной ленты можно выделить ИТ-компании, которые работают в области Big Data и разрабатывают системы искусственного интеллекта. Накопитель используют для хранения данных, генерируемых IoT-устройствами. К примеру, всего один беспилотный автомобиль может собирать до 30 ТБ данных в день.
Каждый год количество данных, которые генерирует человечество, экспоненциально растёт. Распространение IoT-устройств, систем искусственного интеллекта это только усугубляет. Количество компаний, использующих решения на основе магнитной ленты, будет расти вместе с этими рынками. Есть технологии вроде ДНК-хранилищ, которые в перспективе заменят магнитную ленту на посту «холодного хранилища», но об их практической реализации в крупных масштабах пока говорить не приходится.
Совершим небольшой экскурс в историю технологии пробивной силы.

Перфокарты (от латинского perforo — пробиваю) — это носители информации из тонкого картона, данные на которых кодируются с помощью отверстий, проделанных в определенных точках. Впервые они появились в 1804 году, когда французский изобретатель Жозеф Жаккар, представил ткацкий станок с высочайшей для той эпохи степенью автоматизации. С помощью перфокарт Жаккар мог формировать самые разные узоры на тканях.
Нити у станка пропускались через отверстия в жестяных пластинах. Последовательность отверстий — в современной терминологии — «программировала» место, которое нить занимала в будущем узоре.
В текстильном деле метод широко применяется по сей день: так, многие вязальные машины, например марки Brother, работают на перфокартах.
Изобретение Жаккара вдохновило английского математика-новатора Чарльза Бэббиджа. Он решил позаимствовать идею перфорированных пластин и использовать их для создания аналитической вычислительной машины. Её блок-схему он предложил в 1834 году. Правда, замысел первого «компьютера» на перфокартах существенно опередил своё время.
Из соображений исторической справедливости нельзя не упомянуть современника Бэббиджа — русского изобретателя Семёна Корсакова. В 1832 году он собрал механический гомеоскоп с неподвижными частями: он помогал найти лекарство в структурированной перфорированной таблице по определённым признакам заболевания (симптомам).
Активно перфокарты начали использовать на рубеже веков. В 1890 году американский инженер Герман Холлерит сконструировал «табулирующую машину», предназначенную для обработки результатов переписи населения Соединённых Штатов. Её создание было продиктовано тем, что ручной анализ материалов предыдущей переписи занял несколько лет.

Холлерит представил перфокарты с двенадцатью рядами по двадцать дырок в каждом. Они кодировали информацию о возрасте жителя США, семейном положении, количестве детей и так далее. Перфокарты помещались в специальный аппарат, который автоматически подсчитывал число тех или иных конфигураций пробитых отверстий. По сути, это была первая в мире система для обработки больших данных.
После успеха и тиражирования своего изобретения в 1896 году Холлерит открыл фирму Tabulating Machine Co. Спустя пятнадцать лет она объединилась с двумя другими конторами по автоматизации статистических подсчётов и превратилась в Computing Tabulating Recording. Последняя, в свою очередь, позже была преобразована в ныне известную IBM.

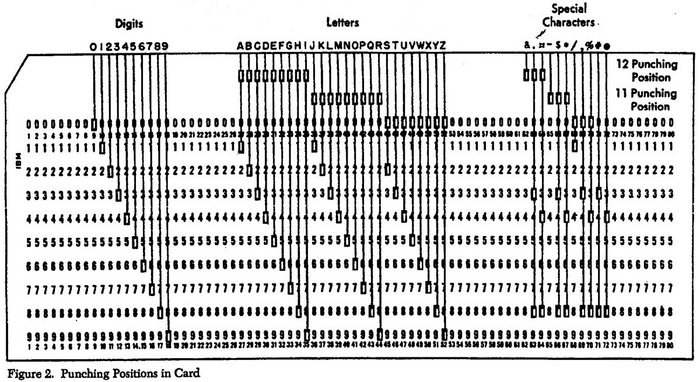
В IBM продолжили разработку «перфотехнологий» и в 1928 году представили новую карту (IBM Card) размерами 7⅜ х 3¾ дюйма. Она имела 80 столбцов и 12 строк, а пробиваемые в ней отверстия были прямоугольными.
Сначала она использовалась со счётными машинами и компьютерами фирмы, но впоследствии завоевала статус технологического стандарта. Перенял его в дальнейшем и Советский Союз.

Для считывания перфокарт использовались два метода — электромеханический и фотоэлектрический. В первом случае поверхность носителя информации подвергалась воздействию металлических прощупывающих щёток. Пройдя через отверстие в картоне, они замыкали контур электроцепи, сигнализируя о наличии проёма в этом месте. Во втором случае в схеме задействовались фотодиоды, у которых падало сопротивление при попадании на них света через пробой.
В 1920–1950-е годы перфокарты безраздельно доминировали в качестве носителя. С их помощью как обрабатывали данные, так и хранили их. Однако с увеличением темпов технического прогресса обнаружилось, что перфокарты становятся «бутылочным горлышком» индустрии.

Виной тому была их скромная ёмкость. На стандартной перфокарте кодировалось до 80 символов. А значит для запоминания одного мегабайта данных требовалось свыше 13 тыс. картонных носителей. Кроме того, скорость чтения и записи на перфокарты оставляла желать лучшего. Через считыватели нельзя было пропустить больше 1 тыс. перфокарт в минуту.
По этим причинам усилия многих инженерных школ были брошены на разработку новых технологий хранения данных. И в скором времени перфокарты заменили более «прогрессивной» магнитной лентой.
Окончательно свои позиции перфокарты уступили в 1980-х, вытесненные более надёжными и ёмкими магнитными лентами и гибкими дисками. Однако свой след в истории они оставили, и заметный. Достаточно сказать, что на перфокартах был реализован ввод данных в электронно-счётный комплекс для вычисления и корректировок орбиты первого искусственного спутника Земли, запущенного СССР в 1957 году.
Перфокарты стали настолько обыденной деталью в технологической индустрии, что мыслились как неотъемлемый её атрибут. Об этом даже писали фантасты. У Роберта Шекли в романе «Корпорация „Бессмертие“» (1958) люди XXII века летают на гелитакси и умеют переносить сознание из одного тела в другое, однако в работе по-прежнему задействуют перфокарты.
При всем при этом Роберт Шекли может быть не так далек от правды, как видится сегодня. Компания IBM — которая расформировала департамент, занимавшийся перфокартами — разрабатывает новую технологию сверхплотной записи информации. Она называется Millipede, и в её основе лежит метод перфорирования носителя.
Крохотные иглы продавливают на кусочке пластика нанометровые углубления, каждое из которых означает один бит. Millipede позволяет записать на кусочке пластика размером с почтовую марку порядка 25 Гбайт данных. Так что, быть может, в ходе четвёртой промышленной революции «перфокарты» ждёт ренессанс.
Перфокарты начали повсеместно использоваться в конце XIX века и оставались массовым инструментом вплоть до 60-х годов XX-го. Однако мало кто знает, что их история началась задолго до появления компьютера.

Одним из наиболее важных музыкальных инструментов средневековья были колокола. Однако традиционная звонница не особенно проста в управлении. Сложности с большим количество верёвок, прикрепленных к языкам инструмента, испытывали даже обученные звонари.

Карильон в Олимпийском парке Мюнхена
Для решения этой проблемы появились карильоны — механические звонницы. Педальный механизм приводил в движение сложную систему рычагов, позволяя управлять инструментом усилиями одного человека.

Барабан карильона на колокольне города Брюгге
В XIV веке для дальнейшего удобства карильоны начали автоматизировать. Они получили металлический цилиндр с зубьями, двигавший рычаги в нужной последовательности по мере вращения. Этот прорыв положил основу Европейской традиции механических инструментов. В частности, по схожему принципу работают шарманки.
Со временем этот принцип барабанной автоматизации начал проникать и в другие сферы деятельности человека. В частности, его вариация нашла применение в текстильной промышленности. Текстильщик Базиль Бушон в XVIII веке автоматизировал ткацкий станок для вышивки сложных рисунков на китайских шелковых платьях.

Автоматизированный станок Базиля Бушона
Бушон «перевернул» знакомый ему с детства принцип барабанной автоматизации. В карильонах и шарманках рычаги управляются зубьями, закреплёнными на барабане. В машинах Базиля рисунок «программировался» отверстиями на бумажной ленте, через которые проходили челноки. Так, появилась первая «перфокарта».
Модель, созданная Бушоном, не была идеальна — для движения перфоленты требовался отдельный оператор. Но у технологии имелся потенциал. Поэтому, когда в начале XIX века такие станки оптимизировал другой француз — Жозеф Мари Жакар — они приобрели популярность. Жаккардовы устройства распространились по всей Европе. При этом перфокарты используются в текстильном производстве и по сей день.
Именно Жаккардовым станком вдохновлялся Чарлз Бэббидж при проектировании своей знаменитой аналитической машины — перфокарты показались ему идеальным методом ввода данных.
Предполагалось использование перфокарт трёх типов — с входными данными, информацией о планируемой арифметической операции, и инструкциями для выгрузки информации из оперативной памяти. Однако при жизни Бэббиджа полноценный прототип не был реализован, сохранились лишь перфокарты, предположенные для демонстрации.

Карты Чарльза Беббиджа
В массовое пользование перфокарты вошли значительно позже, с изобретением табуляторов — электромеханических машин для авторизации обработки данных. Их потенциал в сферах статистики и бухгалтерского учёта стал гарантией коммерческого успеха и поспособствовал росту IBM.
Правительство США закупило ряд таких машин для проведения переписи населения в 1890 году. Эксперимент оказался удачным и их примеру последовало множество стран. Например, в 1897 году табуляторы использовались в единственной в истории переписи Российской Империи.
Используемые во время переписи населения перфокарты имели всего 24 колонки в ширину и создавались из непрочной бумаги. Более того, они умели хранить лишь примитивную информацию из опросников, например, в каком поле при ответе на вопрос человек поставил галочку. Со временем этого оказалось недостаточно и появилась необходимость в кодировках, которые бы позволили хранить на перфокартах больше информации.
Первый стандарт перфокарты для вычислительных систем, стал самым массовым — это был IBM-80. Такие карты имели 80 колонок и позволяли с помощью комбинаций прокалываний кодировать символы латинского алфавита и цифры. Со временем в стандарт были добавлены комбинации для знаков пунктуации и специальных символов. Используемая кодировка называлась EBCDIC (Extended Binary Code Decimal Interchange Code).

Пробитая перфокарта стандарта IBM-80
Для удобства пользователей мейнфреймов IBM также изготавливался мобильный вариант этих карт, состоявший из 40 колонок.

Пробитая отечественная перфокарта
В Советском Союзе использовались кириллические перфокарты, изготовленные по ГОСТ 10859-64. Стандарт был введён в 1964 году, и в 1969 году обновлён для кодирования 7-битных данных.
Перфокарты — это лучше, чем ничего. Но особенности формата создают целый ряд проблем. Обращаться с программами, написанными на перфокартах, было попросту неудобно.
Для одной программы зачастую требовались десятки, сотни или даже тысячи перфокарт. Если ветер разбросал стопку карт по комнате, несчастным программистам приходилось вручную восстанавливать их порядок. Конечно, существовали машины автоматической сортировки перфокарт — вроде IBM 82 — но они были дорогими. Их в основном использовали в больших компьютерных центрах для распределения задач по важности.

Сортировщик перфокарт IBM 82
При этом перфокарты занимали много места. В иных случаях для их хранения использовали целые ангары. Кстати, чтобы внести в программу изменения или исправить ошибку, нужно было искать отверстие на перфокарте и буквально заклеивать его. Отсюда и пошло употребление слова «патч».
Из-за большого количества неудобств от этого формата хранения данных отказались. Перфокарты заменила магнитная лента, которая до сих пор используется в дата-центрах.
Магнитные картриджи последнего поколения имеют емкость в 12 терабайт
уже 18ТБ, если говорить про LTO-9 стандарт. и это без аппаратного сжатия, которое на драйве реализовано.
есть ещё проприетарные форматы для тех же мейнфреймов, там ёмкость еще больше, но большинству такие картриджи и летоприводы не нужны.
Как массовый продукт плёнка умерла — её заменили жесткие диски и оптические носители
вовсе нет.
у неё просто своя ниша. и этот рынок медленно, но растёт, по данным того же IDC.
просто у дисков и ленты слегла разные задачи. никто не может конкурировать с лентой по стоимости совокупного владения за ГБ хранимых данных, если мы говорим про большие инсталляции и данные, к которым по ряду причин не часто обращаются, но долго хранят (архивы, резервные копии, регуляторные ограничения на срок хранения информации). а для больших цодов и плотность и энергопотребление являются очень важными аспектами (когда мы говорим про ПБ данных, которые многими копиями лежат на разных площадках)
ну и чтобы все поняли, что тема до сих пор перспективная, вот пример - в 2020 году новый рекорд по плотности размещения данных 317 Gbpsi (гигабита на квадратный инч или что-то вроде 6.4516 см^2), а чуть раньше были рекорды по скорости записи на ленту... в общем, инвестируют, исследуют и производят.
у пресловутого LTO формата весьма понятный вектор развития

