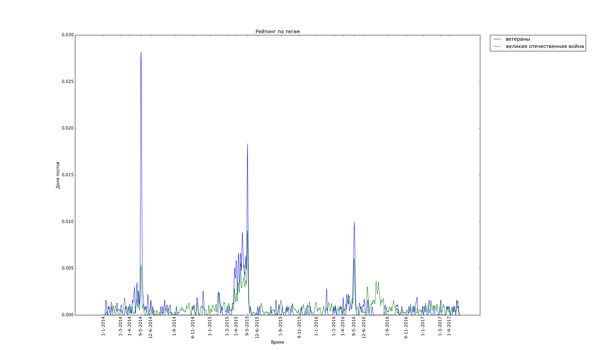
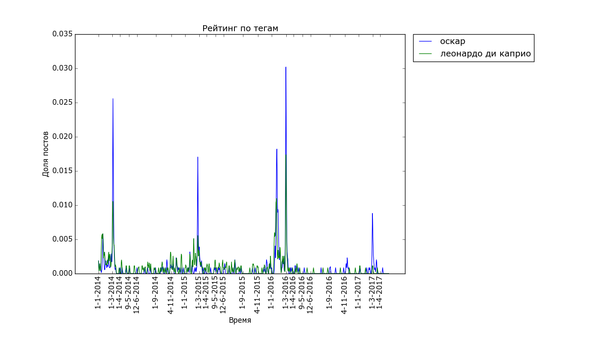
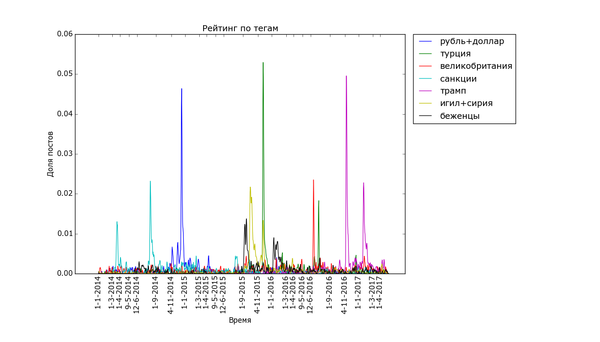
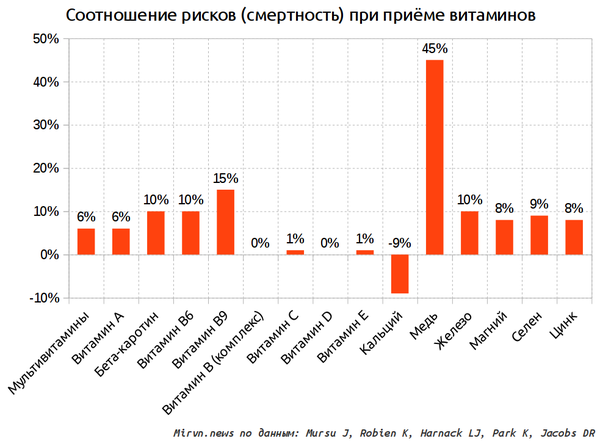
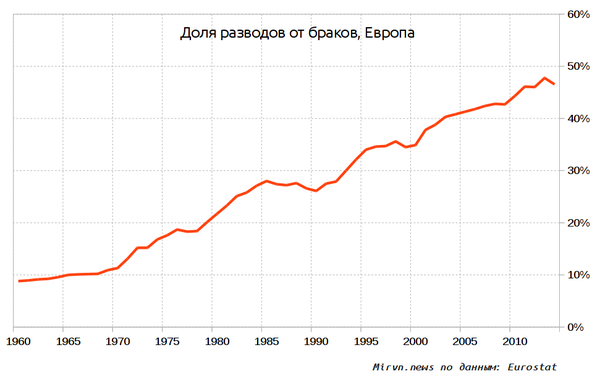
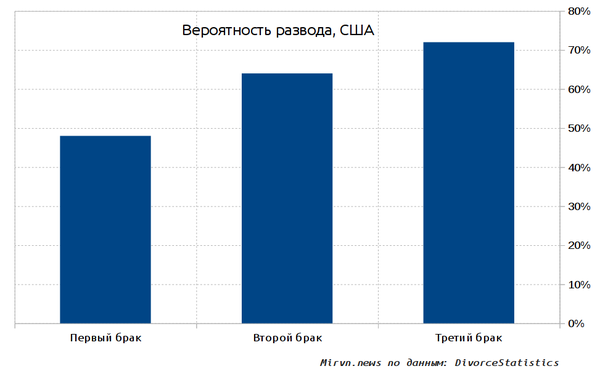
Привет, Пикабу!
Я программист, и моё хобби - статистика, анализ данных и машинное обучение. Чтобы отвлечься от пережёвывания однообразных банковских и социальных данных, пару недель назад я расковырял данные Пикабу о лучших постах. Я хотел бы поделиться с вами результатами этого небольшого исследования и разобрать на его примере один типичный случай неправильного применения статистики. Попробуйте обнаружить её в ходе повествования.
Сначала немного о способе получения информации. К сожалению, доступ к полной статистике посещения, кликов и размещения постов имеет разве что админ, и вряд ли со мной поделится. Поэтому пришлось довольствоваться тем, что есть, а именно кодом страниц Пикабу. Его можно увидеть в браузере, нажав правой кнопкой мыши на страницу и выбрав "Просмотреть код" или посмотрев, что приходит в ответ на запрос страницы (F12 в Chrome). Эту длинную HTML-простыню несложно распилить на сегменты, отвечающие за каждый пост, а из них, в свою очередь, наковырять чего-нибудь интересного. Разумеется, сохранять все данные вручную, было бы невероятной тратой сил, поэтому я написал бота, обходящего "Лучшее". К счастью, адрес страниц Пикабу имеет простой формат "http://pikabu.ru/best/XX-XX-XXXX?page=YY".
Выкачивать всю информацию, включающую в себя многомегабайтные картинки, было бы грустно для свободного места на моём компьютере, поэтому пока что я остановился только на базовых данных: названии поста, тегах, рейтинге, количестве комментариев и дате отправки. Также я решил, что абсолютно все посты меня не интересуют, поэтому ограничился лишь 15 страницами "Лучшего" каждого дня начиная с 1 января 2014 года по 1 апреля 2017. Вышло 361604 записи.
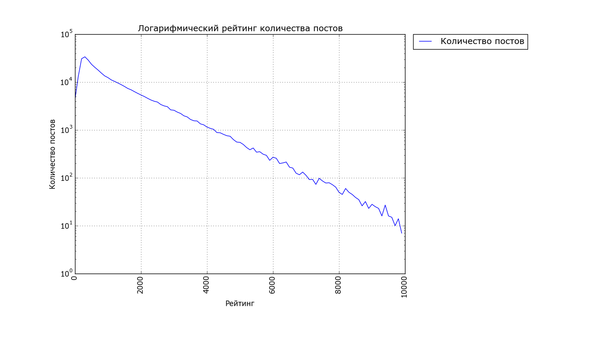
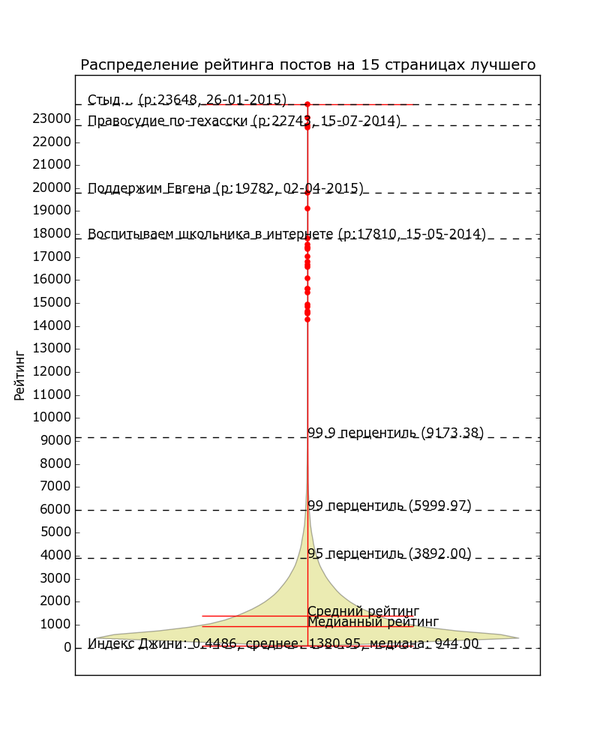
Даже из этих простеньких данных можно состряпать что-нибудь интересное. Для начала давайте просто посмотрим на количество постов с различным рейтингом. По вертикали отложен рейтинг, толщина жёлтой области по горизонтали - количество постов с данным рейтингом, жирные красные точки - единичные посты с высоким рейтингом.
Мобильная версия с читабельным текстом:
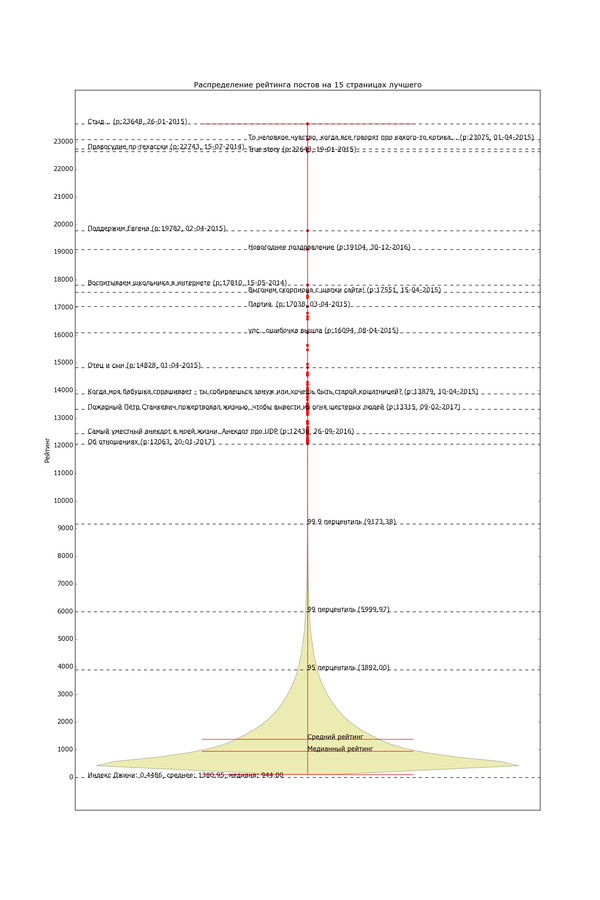
Версия с высоким разрешением и большим количеством информации (откройте в полное окно во избежание шакалов):
Невооружённым глазом видно, как график очень быстро сужается. Распределение рейтинга по постам довольно неравномерно. Половина постов в "Лучшем" имеет рейтинг в диапазоне от 0 до 944 (жирный кусок "юлы"). Если сложить весь рейтинг и поделить поровну, получится 1380 рейтинга на пост. Только 5% постов в лучшем имеют рейтинг выше 3892 (95 перцентиль) и лишь 1% - выше 6000. Хоть график тянется довольно высоко, его высокие уровни почти не населены. В верхней половине графика находятся 80 постов "элиты" с рейтингом выше 12 тысяч (красные точки); остальная 361 тысяча - в нижней половине. Вот такое вот неравенство.
Проанализировав данные при помощи стандартной метрики неравенства, индекса Джини, я получил значение в ~0.45. 0 означало бы абсолютно одинаковое распределение рейтинга, 1 - абсолютное неравенство. Для сравнения стоит заметить, что неравенство распределения доходов россиян по индексу Джини оценивается в ~0.41, американцев в ~0.43, французов в ~0.31, а чилийцев - в ~0.55.
Вообще такой график соответствует часто встречающемуся в различных системах закону "богатые становятся богаче". На Пикабу такое поведение связано с тем, что разные читатели просматривают разное количество страниц. Лишь небольшая их доля отлавливает посты в свежем. Только если посту повезло, и рыцари свежего одарили его плюсам, он "получает доступ" к более широкой аудитории людей, пролистывающих "Горячее" до конца. Если и там он поднялся, то свою порцию плюсов накидывают обитатели первых страниц "Лучшего" и "Горячего", а затем и просто люди заходящие только на первую страницу "Лучшего". Разумеется публика не столь стратифицирована, кто-то, кто обычно сидит в свежем, может сегодня только посмотреть пару страниц "Горячего", а кто-то, сидящий в "Горячем", может вовсе не зайти на Пикабу. Тем не менее, "подъём" поста - многоступенчатый и самоподдерживающийся процесс с положительной обратной связью (чем популярнее пост, тем он станет ещё популярнее в будущем). Качество контента играет роль, но если на каком-то этапе из-за случайных флуктуаций иссякает "топливо", то увы. Хотя вообще и пост может оказаться неоч для "Лучшего", это да.
Что самое интересное, "топ топа" не особо отличается от случайных постов в лучшем. То есть, они довольно хорошие, без треша, но за исключением нескольких постов от 0x00, вряд ли бы я бы опознал их на общем фоне:
Стыд
То неловкое чувство, когда все говорят про какого-то котика...
Правосудие по-техасски (0x00)
True story
Новогоднее поздравление
Воспитываем школьника в интернете
Выгоним Скорпиона с шапки сайта
Moderator vs Zombies (0x00)
Наверное, это можно интерпретировать так: шанс попасть на самый верх есть у каждого, но его можно здорово повысить умением создавать длинные гифки-мультики.
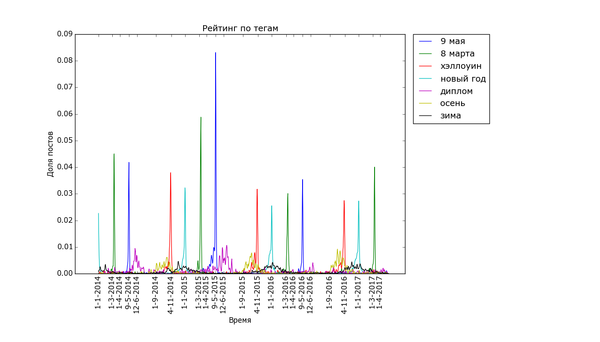
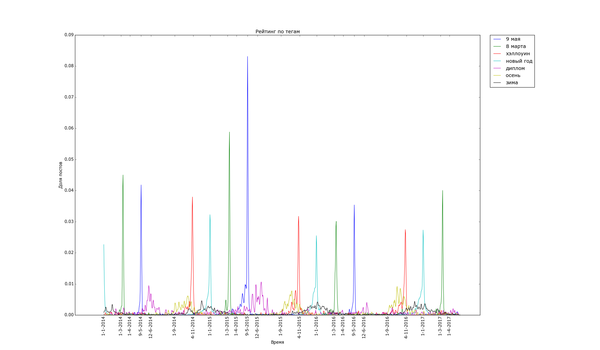
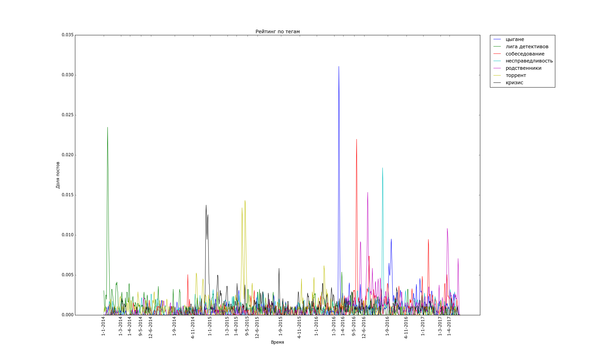
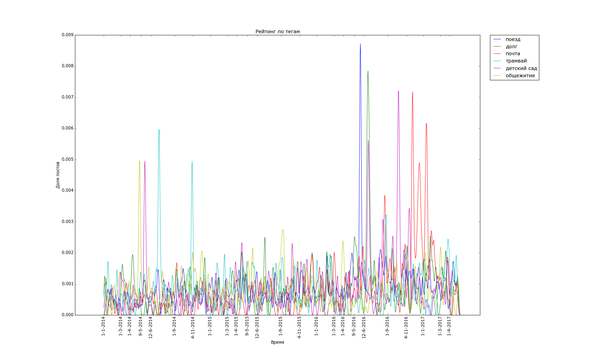
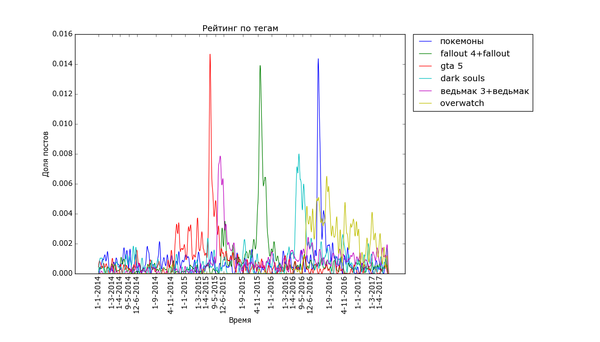
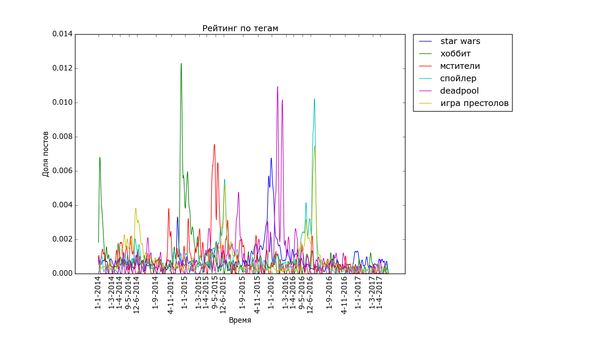
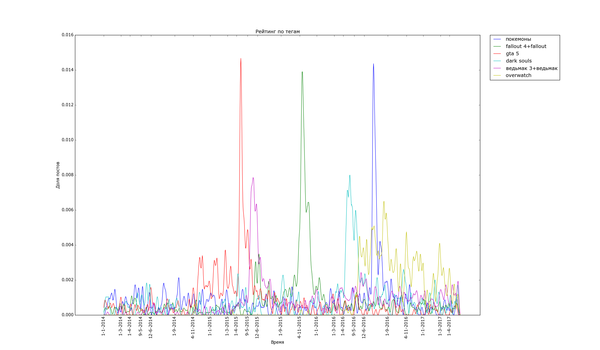
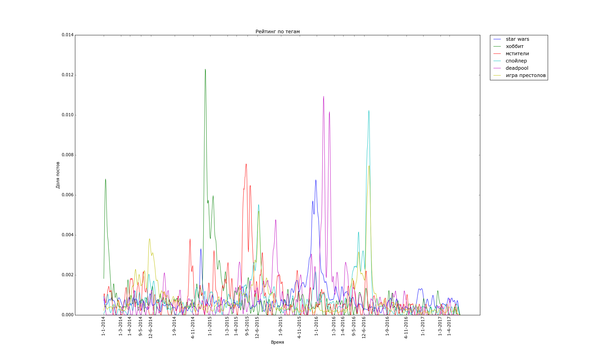
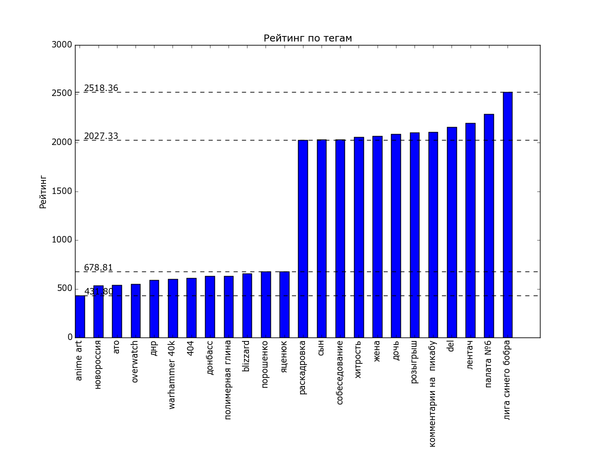
Теперь посмотрим на распределение рейтинга по тегам. Для полученных данных я подсчитал, сколько раз используется каждый тег. Для тегов, встречающихся более чем в 200 постах, вычислил средний рейтинг постов с этим тегом. В итоге:
Мобильная версия:
Ииии в самом топе по рейтингу... с уверенным отрывом... "лига синего бобра". Хах. Кто бы мог подумать. Я один не замечал этот тег раньше? Второе и третье место занимают "палата №6" и "лентач". Вообще состав тегов правой половины графика намекает на то, что на Пикабу ценятся кулстори из личной жизни ("сын", "отец", "дочь", "жена"), с работы ("клиенты", "собеседование", "начальник") и из понятной всем повседневной жизни ("почта России", "очередь", "яжмать", "азиаты" (?)). Не стесняется Пикабу таскать контент с bash im и заниматься самолюбованием ("комментарии на Пикабу").
На донышке находится политота - туда ей и дорога! - аниме, некоторые игры и хобби. Рискну предположить, что политика просто всех так достала, что большинство её уже просто пролистывает или помещает тег в игнор. Остальное - просто слишком специализированное, так что если и выходит в "Лучшее", то далеко не уходит просто за счёт того, что на Пикабу слишком мало людей, которым был бы интересен, скажем, рисунок карандашом.
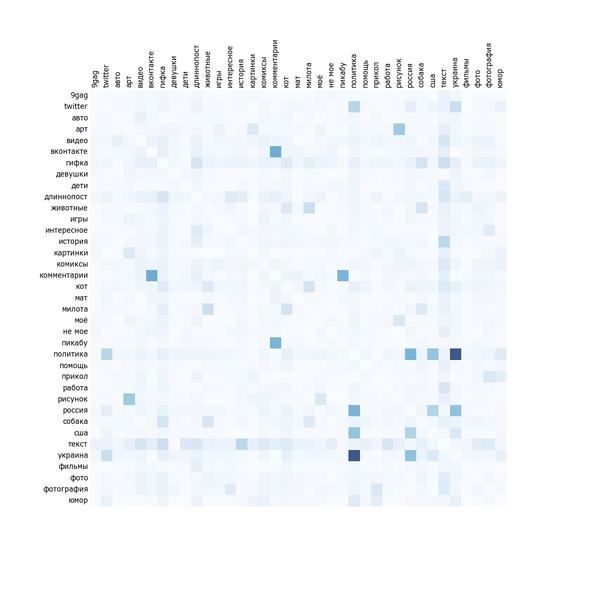
Прошлый анализ никак не учитывал, что пост может быть одновременно отмечен несколькими тегами, входящими в перечень (скажем, и "blizzard", и "собеседование"). Скажем, если аудитория не любит "тег 1" и любит "тег 2", при этом "тег 2" почти всегда встречается с "тегом 1" и постов с "тегом 1" гораздо больше, то это может привести к "занижению ценности" "тега 2". Чтобы оценить степень проблемы, посмотрим на матрицу корреляции самых популярных тегов:
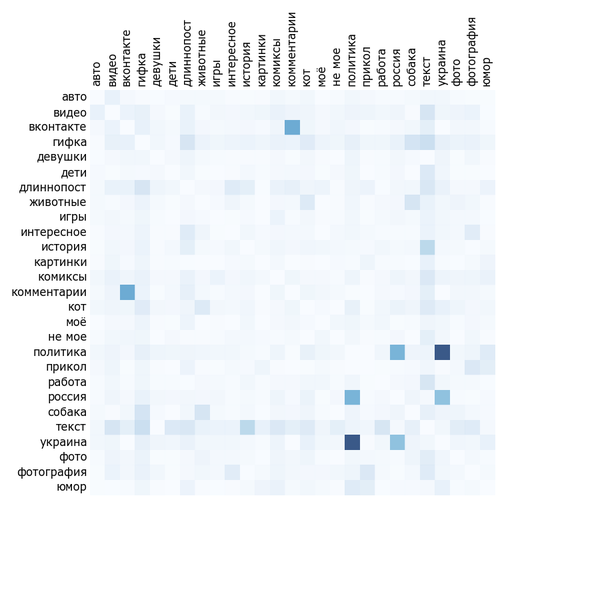
Мобильная версия:
Чем синее квадрат на пересечении, тем чаще эти два тега встречаются вместе. Очевидно, что рисунок симметричен. Хоть тег сам с собой встречается постоянно, диагональ специально сделана белой для читабельности.
В общем-то анализ не слишком показателен. Тегов всего 37 на большой картинке. Невооружённым глазом видна плеяда "политика", "Украина", "США", "Россия", "twitter". "Милота", "собаки", "коты" и "животные" часто встречаются вместе. Также можно увидеть, что "моё", "рисунок" и "арт" часто встречаются вместе. Комментарии чаще всего с Пикабу или ВКонтакте. Текст коррелирует вообще со всем, причём "не моего" текста на Пикабу больше, чем "моего". Будем надеяться, что влияние статистических артефактов окажется малым.
Кто-то может сказать, что вышеперечисленные умозаключения довольно капитанские. Я же отвечу, что приятно, когда формальный анализ сходится с интуитивными предположениями.
Итак, промежуточные выводы:
1) Постов с рейтингом выше шести тысяч исключительно мало.
1.5) Тем не менее, повезти может каждому, было бы начальное внимание к посту (от 100 плюсов).
1.75) Коэффициент везения зависит от качества контента и от количество "0" в нике.
2) Для более высокого рейтинга постов лучше постить что-то, что понятно каждому.
2.5) Но не политику. Кармалюбствовать на политике не выгодно.
В следующих частях: временной анализ (общий и по тегами), рассказ про статистическое искажение, ссылка на исходный код.