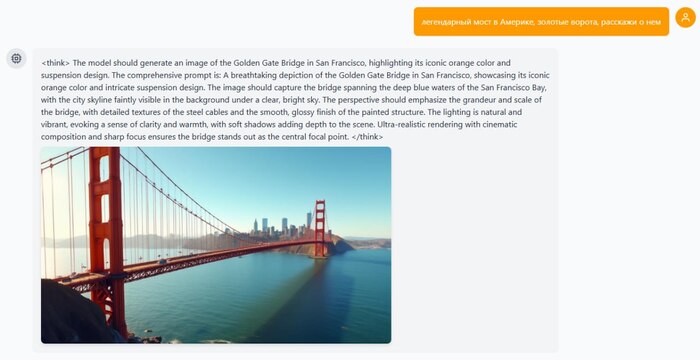
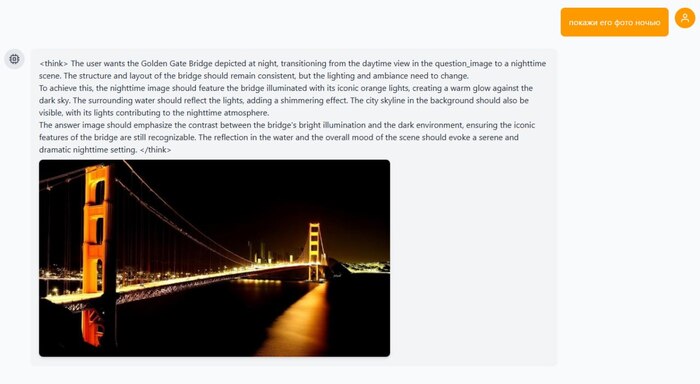
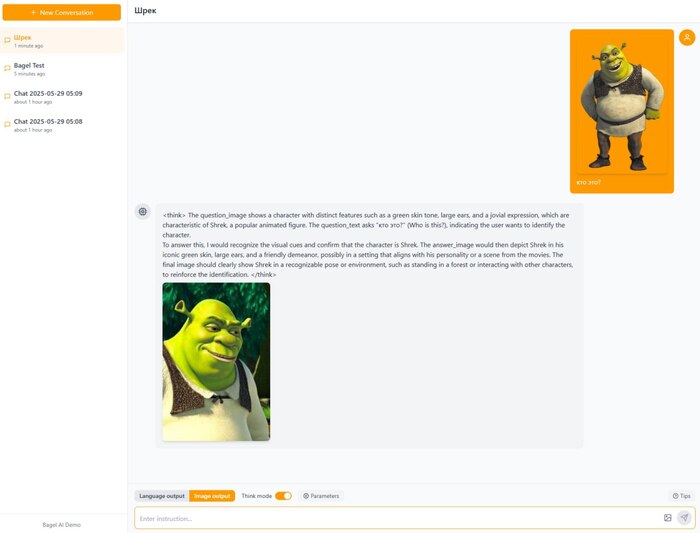
ByteDance опять роняет запад! Они открылм код BAGEL — единой мультимодальной модели нового поколения, которая «видит», «читает» и «рисует» в одном флаконе. Проект вышел 20 мая 2025 года и сразу доступен под Apache 2.0 — можно дообучать и использовать коммерчески.
🔘 принимает текст + изображения и отвечает тем же смешанным форматом;
🔘 генерирует, редактирует, переносит стили;
🔘 разворачивает краткие запросы в режиме <think>;
🔘 лидирует среди open-source VLM: MME-P 1687, MMBench 85 %, MMMU 55 %, MMVet 67 %.
🔘мультиязычность, понимает и на русском, но отвечает на английском.
BAGEL построена на Mixture-of-Transformer-Experts (MoT): токены маршрутизируются между «экспертами», что увеличивает ёмкость без заметных задержек. Визуальная часть кодируется двумя энкодерами — ViT отвечает за пиксельные детали, VAE — за семантику. Далее объединённые представления поступают в MoT-декодер, обученный в парадигме Next Group of Token Prediction, поэтому модель одинаково уверенно продолжает как текст, так и визуальные токены.
Уже доступны GGUF-веса (ema)
📖 Страница проекта — https://bagel-ai.org/