


Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

У компании Intel получилось, как у Чебурашки из мультфильма - мы строили-строили, и наконец построили. Вернее, наклепали брака и опозорились на весь мир. Практически все владельцы процессоров Intel 13-х и 14-х поколений, которым выпала торжественная честь их эксплуатировать, спустя год-два их использования стали проклинать Intel на чём свет стоит. Причиной этих проклятий в адрес компании явился преждевременный массовый выход из строя этих чудо-процессоров.
Да, именно выход из строя, а не нестабильная работа, как это любит преподносить сама Intel и её многочисленные фанаты. Давайте уже называть вещи своими именами. Если процессор становится неспособен выполнять свои задачи с необходимым качеством, то он неисправен. Здесь всё просто – либо исправен, либо неисправен.
А как их рекламировали! У 13-го поколения в играх производительность выше на 24%, в однопотоке на 15%, в многопотоке на 41%, при обработке фото и видео на 34%.

Маркетологи Intel отработали на отлично, завернули этот брак в красивую праздничную обертку. А через год-два эта обертка слезла и под ней вместо процессора оказалась гнилая тыква. В общем, технари со своей задачей не справились.
Первое время Intel проблему преждевременного выхода из строя процессоров признавать не хотела. Но когда претензии по неисправностям начали расти, как снежный ком, Intel пришлось признать эту проблему. И в сентябре 2024 года компания сообщила, что причиной является повышенное рабочее напряжение процессора, которое он же сам ошибочно и запрашивает.
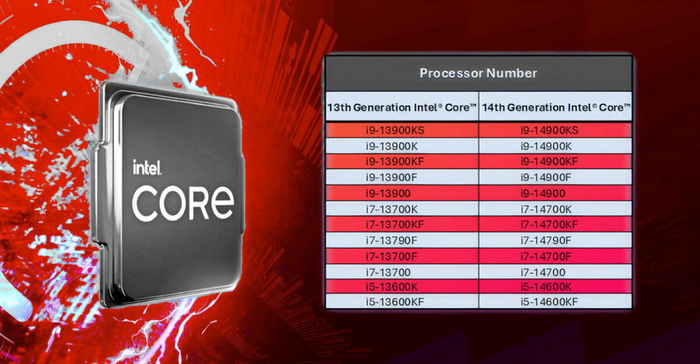
Список процессоров 13-го и 14-го поколений подверженных браку
То есть, при той или иной вычислительной нагрузке на процессор, он всегда запрашивает от материнской платы напряжение питания значительно выше необходимого. Так заявляет Intel. Из-за этого процессор за короткий промежуток времени деградирует до неработоспособного состояния.
Intel заявляет, что этой напасти можно избежать путем обновления BIOS, в микрокод которого внесены соответствующие исправления уменьшающие напряжение питания. Но дело в том, что процессорам, которые уже успели поработать с повышенным напряжением этот «костыль» уже не поможет, поскольку необратимые процессы разрушения в процессоре уже произошли.
И проблема в процессорах находится на физическом уровне, так как микрокод управляющий напряжением питания прошит в самом процессоре. И перепрошить его уже нельзя, да и зачем у полудохлого процессора это делать. А можно только заменить на новый процессор с «правильным» микрокодом.
Но неужели опытные инженеры Intel так легко прошляпили эти ошибочные запросы на критически высокое напряжение? Может дело совсем в другом, и это было сделано умышленно. Постараюсь сейчас это объяснить, для этого вспомним немного хронологию развития процессорной архитектуры. Кому это не особо интересно, можно сразу перейти ниже по тексту к описанию 12-го поколения Alder Lake и далее.
Немного истории
В конце 2008 года звезды удачно сошлись над компанией Intel и миру был явлен новый процессор с прорывной на то время архитектурой Intel Core.

Процессор 1-го поколения Nehalem на новой архитектуре Intel Core
В отличие от предыдущих «склеек» двух кристаллов Core 2 Duo под одной крышкой в процессорах Core 2 Quad, новая архитектура не имела их глобальных недостатков. Таких, как обмен данными между процессором и оперативной памятью через северный мост, который имел низкую пропускную способность и фактически не мог реализовать весь потенциал оперативной памяти. И потому с таким «узким бутылочным горлышком», увеличение производительности этих ядер не имело никакого смысла.
Nehalem – все лучшее теперь впереди
В новой же архитектуре Intel Core 1-го поколения Nehalem северный мост был интегрирован в сам процессор. Линии связи процессора с оперативной памятью уменьшились и между ними стала использоваться новая шина связи «QuickPath Interconnect» с пропускной способностью до 25.6 ГБ/c, что было в два раза больше, чем у топовых процессоров с северным мостом, расположенным на материнской плате. Благодаря чему скорость обмена данными между процессором и оперативной памятью значительно возросла.

Сами же ядра процессора стали располагаться на одном цельном кристалле, что позволило увеличить скорость обмена данными между его ядрами. Была внедрена полноценно работающая технология многопоточности Hyper-Threading, которая дала ядрам возможность обрабатывать два потока данных. В предыдущих процессорах были лишь жалкие малоэффективные попытки использования этой технологии. Добавилась кэш-память 3-го уровня (L3), которая значительно увеличила быстродействие. У предшественника, Core 2 Quad, была кэш-память только первого (L1) и второго (L2) уровней.
Не менее важной явилась новая технология Turbo Boost, благодаря которой частота некоторых ядер динамически повышалась при увеличении на них вычислительной нагрузки. Добавлена поддержка набора новых инструкций SSE4.2.
Однако эти новшества не смогли в полной мере реализовать потенциальные возможности новой архитектуры Intel Core. И потому у неё остался большой модернизационный потенциал, который предполагал очень оптимистичный прирост производительности в последующих поколениях процессоров Intel Core.
Sandy Bridge – большой прогресс налицо
И во 2-м поколении процессоров Sandy Bridge представленных в начале 2011 года производительность ожидаемо увеличилась до значимых 20%. Я умышленно называю Sandy Bridge новым поколением процессоров, а не новой архитектурой. Поскольку считаю, что в данном случае это лишь модернизация и улучшение одной единственной архитектуры Intel Core в последующих поколениях процессоров.
В Sandy Bridge была проведена большая работа по модернизации архитектуры. Топовые модели имели четыре ядра и восемь потоков. Для соединения ядер с кэш памятью и графическим ядром была использована новая скоростная кольцевая шина с шириной 256 бит и скоростью обмена до 96 Гбит/c, что в несколько раз быстрее, чем у процессоров предыдущего поколения Nehalem.
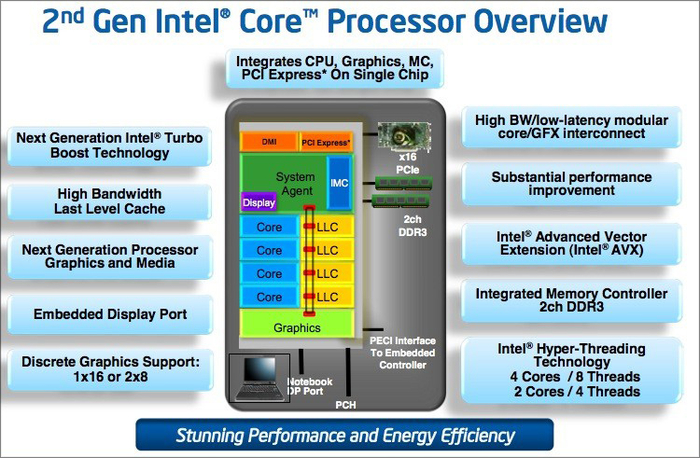
Структурная схема процессора 2-го поколения Sandy Bridge
Эта шина позволяла обеспечить обмен с необходимой скоростью аж 20 ядер процессора. Это решение оказалось удачным и использовалось без значимых улучшений и в последующих поколениях процессоров. Появилась поддержка новых 256-битных мультимедийных инструкций AVX.
Это был успех Intel, который AMD и не снился. Именно в Sandy Bridge было заложено много принципов работы, которые стали стандартными, и по сей день используются в большинстве процессоров Intel.
Ivy Bridge – Intel уверенно движется вперед
В 2012 году вышли процессоры 3-го поколения Ivy Bridge. Они имели поддержку 3-го поколения шины PCI-E, в отличие от предыдущего поколения процессоров со 2-м поколением шины.
Встроенная графика стала более производительная. Топовые модели также имели четыре ядра и восемь потоков. Техпроцесс уменьшился с 32 до 22 нм, и впервые в этом поколении процессоров, Intel отказалась от 2D транзисторной топологии в пользу трехмерной топологии 3D (Tri-Gate). Это позволило снизить энергопотребление до 50% на ту же производительность. Общий прирост производительности по отношению к предыдущему 2-му поколению составил 10-15%. Что явилось хорошим результатом.
Haswell – легенда своего времени
В 2013 году Intel явила миру 4-е поколение процессоров Haswell. У них появилась поддержка новых 256-битных мультимедийных инструкций AVX2 и двенадцатой версии DirectX графическим ядром. Техпроцесс остался прежним 22 нм. Скорость обмена данными между ядрами с кэш памятью увеличилась. Топовые процессоры всё также имели 4 ядра и 8 потоков. Прирост производительности составил до 20%.
Флагманы i7-4770k и i7-4790k были одними из лучших в прошлом десятилетии. Последний вообще был легендой того времени и оставался актуальным длительное время, несмотря на выход нескольких последующих поколений. Его потребление составляло смешные по нынешним меркам 88 Вт.

Пожалуй, 4-е поколение было последним успешным творением Intel. Дальше дела у компании начали стремительно ухудшаться, ибо модернизационный потенциал архитектуры Intel Core в 4-м поколении процессоров был уже практически полностью исчерпан.
Broadwell – самые неудачные процессоры
Выпущенные в начале 2015 года процессоры 5-го поколения Broadwell оказались неудачными. Их модельный ряд был очень скудным, объемы продаж низкими. Broadwell являлся всё тем же 4-м поколением, но перенесенным на более тонкий техпроцесс с 22 на 14 нм. Пользователи отказывались переходить на процессоры 5-го поколения, так как производительности 4-го поколения полностью хватало для любых вычислительных нагрузок.

С выходом 5-го поколения у Intel началась череда неудач. Выжимать из архитектуры Intel Core увеличение производительности становилось все труднее и труднее, модернизационный потенциал архитектуры практически исчерпал себя.
Именно это поколение, можно считать в истории Intel переломным моментом, после которого компания, набирая скорость понеслась вниз ко дну. Пока только понеслась, но дно ещё не пробила.
Skylake - DDR-3 и DDR-4, два в одном, но вышло плохо
В сентябре 2015 года вышло 6-е поколение процессоров – Skylake изготавливаемые все по тому же 14 нм техпроцессу. При их проектировании Intel решила усидеть на двух стульях, реализовав одновременно поддержку двух стандартов оперативной памяти DDR-3 и DDR-4. Для этого инженеры «вкорячили» в процессор контроллер оперативной памяти поддерживающий два этих стандарта. Ну а в остальном это очередная оптимизация предыдущего поколения. Количество ядер у топовых моделей i7 6700 составляет четыре, как и прежде.

Структурная схема процессора (с одновременной поддержкой памяти стандарта DDR-3 и DDR-4)
Популярности эти процессоры не имели по нескольким причинам. Во-первых, их использование с памятью DDR-3 не давало существенного прироста производительности. Этот прирост не оправдывал затрат на приобретение такого процессора и новой материнской платы. А материнскую плату нужно было обязательно приобретать новую, поскольку сокет этого процессора LGA 1151 не совместим с сокетом предыдущего поколения.
Во-вторых, использование процессора с памятью DDR-4 хоть и давало относительно неплохой прирост производительности, но было дорогим решением. Материнки, поддерживающие память DDR-4, были значительно дороже поддерживающих DDR-3. И сама оперативная память была еще дорогая.
Kaby Lake – прогресс остановился
В январе 2017 года вышло 7-е поколение Kaby Lake. Это незначительная оптимизация предыдущего поколения. Даже поддержку устаревающей памяти DDR-3 у контроллера памяти не «открутили», все так и оставили. Техпроцесс всё тот же 14 нм. Количество ядер у топовых моделей процессоров осталось прежним, равным четырем.
Coffee Lake – AMD наступает на пятки, нужно что-то делать
В октябре того же 2017 года вышло уже 8 поколение Coffee Lake. К выходу этого поколения компания AMD выпустила кардинально новые процессоры Ryzen, которые начали здорово наседать на Intel. И теперь Intel зашевелилась и начала «прикручивать» в своих процессорах дополнительные ядра.
Это дало увеличение производительности до приличных теперь 30%, еще раз подтверждая, что решительный шаг вперед – это результат хорошего пинка в зад. Топовые процессоры i7 стали иметь 6 ядер и 12 потоков. Процессоры линейки i5 также имели 6 ядер, но без гиперпоточности, то есть 6 потоков. Техпроцесс без изменений, 14 нм.
Coffee Lake Refresh – ещё больше ядер, лишь бы Ryzen не догнал
Через год, в октябре 2018 года вышло 9 поколение Coffee Lake Refresh. В надежде опередить AMD и восстановить свое первенство в процессоростроении, Intel и дальше продолжила «прикручивать» ядра в своих процессорах.

Ещё больше ядер
Для этого она переработала кольцевую шину, обеспечивающую обмен данными между ядрами, кэш памятью, контроллером памяти, графическим ядром. Её производительности теперь стало хватать для обслуживания более чем 4-х ядер. У топовых процессоров индекс изменился с i7 на i9, количество ядер увеличилось уже до 8-и с 16 потоками, прирост производительности составил порядка 30%. У линейки i7 также стало 8 ядер, но без гиперпоточности (8 ядер, 8 потоков). У i5 стало 6 ядер, так же без гиперпоточности.
Comet Lake – нас не догонишь…..
В мае 2020 года вышло 10 поколение Comet Lake – детище священной войны с AMD. Решение Intel ожидаемо – происходит дальнейшее увеличение ядер и потоков. Линейке топовых i9 процессоров «прикрутили» еще ядра, теперь у них стало 10 ядер и 20 потоков. А всем остальным линейкам, за исключением Celeron, «включили» гиперпоточность, которой не было в некоторых линейках у предыдущего поколения. И опять новый сокет, и новые материнские платы. Хоть AMD и кусает уже Intel за пятки, но последние не забывают заставлять пользователей менять материнки. Техпроцесс без изменений, всё тот же 14 нм.
Rocket Lake – достойный процессор
В марте 2021 году вышло 11 поколение Rocket Lake – это последнее поколение, которое выпускалось по 14 нм техпроцессу и по совпадению, последнее удачное решение Intel.

Прирост производительности по отношению к предыдущему поколению составил 15-30%. Этого удалось добиться благодаря увеличению IPC – количества инструкций, которое процессор мог выполнять за один такт. Также был усовершенствован контроллер оперативной памяти, который стал обладать большей пропускной способностью, и позволял работать с более высокочастотной памятью. Появилась поддержка PCI-E 4-й версии. Это позволило процессору работать с устройствами, поддерживающими этот протокол без потери производительности.
Особой популярностью пользовался среднебюджетный процессор Core i5-11400, который имел приемлемую стоимость и хорошую производительность, которой хватало и для игр с высокими настройками графики и для тяжелых приложений.
Alder Lake – начало конца компании
В ноябре 2021 года вышло сие чудо – 12 поколение Alder Lake с сомнительным техническим решением – гибридной топологией ядер процессора. Процессор теперь состоял из разных по производительности ядер, производительных Р-ядер и энергоэффективных Е-ядер не поддерживающих гиперпоточность. Такое техническое решение получившее дальнейшее развитие в последующих поколениях оказалось для Intel провальным.

Процессор с производительными Р- ядрами и энергоэффективными Е-ядрами
Зачем в десктопных компьютерах, где электроэнергия неограниченно поступает из сети, нужны процессоры с энергоэффективными ядрами? Учитывая, что, например, видеокарта RTX 4090 легко может потреблять до 500 Вт. Какие там единицы, пусть даже десятки Ватт Intel собралась экономить в десктопах, зачем, для чего?
Причина же кроется в том, что Intel не смогла запихнуть в свои процессоры только производительные ядра, а очень хотела бы. Эти ядра банально не влезли в установленный теплопакет, и кроме того, для их размещения требовался кристалл, имеющий большую площадь. Поэтому пришлось некоторую их часть заменить на ущербные низкопроизводительные ядра, несущие гордое название – энергоэффективные. Их можно было впихивать гораздо больше. Так сказать, для количества, для красивой картинки. Потребителю нужно было показать большое количество ядер, как у Ryzen-ов. Пусть даже они будут ущербными, количество ядер рулит.
Да и возможности внутренней шины обмена данными уже были исчерпаны, большое количество производительных ядер она уже не «вывозила», а с энергоэффективными справлялась за милую душу.
Из-за новой гибридной топологии ядер возникли дополнительные неприятные проблемы. Дело в том, что планировщик операционной системы должен правильно распределять вычислительную нагрузку между производительными и энергоэффективными ядрами. А в этом до сих пор имеются определенные проблемы. Windows 10 и предыдущие её версии вообще не были предназначены для работы с гибридными процессорами, а потому они не способны правильно распределять нагрузку между «разносортными» ядрами.
В Windows 11 уже появился «костыль» под названием Thread Director, который должен правильно распределять нагрузку между ядрами, но и он работает плохо. Задумка вроде хорошая. Планировщик, используя технологию Thread Director должен непрерывно получать от процессора информацию о загрузке его ядер, их энергопотреблении, исполняемом коде, температурах ядер и на основании этих данных правильно распределять нагрузку. Но реализация, как это часто бывает отвратительная, технология эта еще сырая и недоработанная. Доходило до смешного, сама Intel рекомендовала при проблемах в играх отключать Е-ядра. Сама их туда «вкорячила», за них получила деньги и теперь рекомендует их отключить. Забавно.
Техпроцесс уменьшился до 10 нм. Появилась поддержка стандарта памяти DDR-5, но при этом оставили поддержку DDR-4, такое Intel уже проделывала и в предыдущих поколениях. Топовая линейка процессоров i9 имела 8Р и 8Е-ядер, линейка i7 имела 8Р и 4Е-ядра, а бюджетные линейки не имели Е-ядер вообще.
Еще это поколение прославилось новым сокетом LGA1700, который быстро деформировался, что зачастую приводило к пропаданию контактов процессора с сокетом. При этом ещё и деформировался процессор.

Искривление основания процессора на сокете LGA1700
Raptor Lake – Intel несется ко дну
В конце 2022 года вышло 13-е поколение Raptor Lake. Потребителю нужно было дать новый продукт и постараться не отдать лидерство AMD. Но модернизационный потенциал архитектуры Intel Core был уже полностью исчерпан. Всё что Intel смогла оптимизировала, тактовые частоты выгнала до предела. Но что-то же нужно было сделать в новом поколении, например, еще хоть немного поднять частоты и увеличить количество ядер. Это было бы для потребителя неоспоримым фактом совершенно другого процессора с новой архитектурой.
Именно так Intel и сделала. Но как ничего не оптимизируя в архитектуре процессора, суметь поднять его тактовую частоту, если частота и напряжение питания уже и так имеют предельные значения? Правильно, нужно ещё увеличить напряжение питания, пусть даже оно будет выше допустимого значения. Intel прекрасно знала, что такое безумное решение неминуемо приведет к катастрофически быстрой деградации и преждевременному выходу процессоров из строя. Но другого выхода у компании не было. Intel рассчитывала, что процессоры будут успевать отработать установленный гарантийный срок без заметной деградации, но она очень сильно просчиталась.
В результате чего, уже в 2023 году, задолго до окончания гарантийного срока, счастливые обладатели этих процессоров воочию увидели результат быстрой деградации и начали сталкиваться с большими проблемами. Многие игры попросту не хотели запускаться на топовых линейках этих процессоров, выдавая различные ошибки. В феврале 2024 года компания Epic Games открыто обвинила Intel в сбоях игр на движке Unreal Engine.

Забавно, что для устранения подобных сбоев Intel даже предложила пользователям уменьшать тактовую частоту и напряжение питания, то есть банально вернуться к предыдущему 12-у поколению, получив от пользователей при этом деньги за 13-е. Это первый процессор в истории Intel с таким беспрецедентным количеством брака.
Причем эти проблемы не затрагивали бюджетные младшие линейки процессоров с базовой мощностью менее 65 Вт. Дело в том, что у них и тактовые частоты, напряжение питания и рабочая температура изначально ниже, что значительно замедляло их деградацию.
Ну и продолжая уже сложившуюся традицию по увеличению количества немощных ядер в своих процессорах, Intel и в этот раз не преминула этим воспользоваться. И для количества, ещё прикрутила в этом поколении дополнительные Е-ядра. Теперь линейка i9 имела 8Р и 16Е-ядер вместо 8Р и 8Е-ядер у предыдущего поколения. То есть в два разу увеличили количество Е-ядер. У линейки i7 ситуация аналогична, немощных ядер стало в два раза больше. Техпроцесс без изменений – 10 нм.
Raptor Lake Refresh – дно пробито
В октябре 2023 года вышло 14-е поколение Raptor Lake Refresh. Основным отличием этого поколения от предыдущего является другая маркировка на корпусе процессора, которая читается как, 14-е поколение. У предыдущего поколения такой маркировки не было, она была другой. Поэтому факт изменившейся маркировки является и фактом новой архитектуры процессоров Intel Core. Ну просто, это самое значимое изменение, других важных изменений не произошло.

Даже проблему преждевременного выхода процессоров из строя из-за повышенного напряжения питания, которое сам же процессор и запрашивает, не устранили. А зачем, и так сойдет, втюхали же пользователям предыдущее дефектное поколение, и это втюхаем.
Да, чуть не забыл об еще одном улучшении, которому была удостоена линейка i7. Ей прикрутили ещё 4-е немощных ядра, и их стало 8P+12E-ядер против 8P+8E в 13-м поколении. Для других линеек ядер видимо не хватило, они неожиданно закончились.

Рассказ пойдет о людях, которые оказали значительное влияние на становление сообщества в нише Open Source.
Ричард Мэтью Столлман родился в 1953 году в семье учителя и продавца печатных станков. С раннего возраста он увлекался вычислительными машинами. Тогда еще не было персональных компьютеров, поэтому Ричард читал сопутствующую литературу — книги по программированию и техническую документацию.
В старшей школе его пригласили на стажировку в исследовательский центр IBM, где он впервые начал программировать. В 1970 году Столлман поступил на физический факультет Гарвардского университета. Общение с ровесниками давалось ему тяжело, поэтому он посвящал все свободное время учёбе и работе.
Еще на первом курсе Ричард начал подрабатывать лаборантом в Массачусетском технологическом институте (MIT).Именно работа в MIT оказала наибольшее влияние на подход Столлмана к написанию программ. В лаборатории царила атмосфера академического сотрудничества — люди свободно обменивались кодом и помогали друг другу с проектами. Но к концу 1970-х ситуация начала меняться — открытые программы стал замещать проприетарный софт.
Столлману не понравился тот факт, что университет перестал быть местом для открытого обмена идеями и программными инструментами. Поэтому он ушел из MIT и начал заниматься популяризацией открытого ПО.
Перед собой Ричард поставил две задачи — создать свободную операционную систему и легальную базу для её распространения. И в 1983 году родился проект GNU (GNU’s Not Unix), призванный стать открытой и улучшенной копией Unix (которая в то время была проприетарной). В его рамках также разработали открытую лицензию GPL. Она закрепила право бесплатно использовать программные продукты, модифицировать их и продавать.

В 1985 году Ричард основал Фонд свободного ПО, под эгидой которого были выпущены GNU GCC (компилятор C), GNU GDB (дебаггер) и GNU Emacs (культовый текстовой редактор). Эти инструменты и лицензия GPL позднее послужили основой для операционной системы Linux.
После распространения Linux Столлман стал часто выступать на ИТ-конференциях. Он путешествует по миру, читая лекции на темы этики и интеллектуальной собственности. При этом Ричард Столлман продолжает исполнять обязанности президента Фонда свободного программного обеспечения по сей день.
Линус Бенедикт Торвальдс родился 28 декабря 1969 года в финской семье шведского происхождения. В детстве Линус увлекся микрокомпьютерами и начал программировать: сперва на Бейсике, а затем и на машинном коде.
Самым крупным проектом его молодости была модификация операционной системы Sinclair QL, для которой он самостоятельно написал ассемблер и текстовый редактор. Неудивительно, что Линус без проблем поступил в главный вуз страны — Университет Хельсинки.

Именно там в конце 80-х он познакомился с Unix-подобной операционной системой под названием Minix. Линусу нравилась её портативность и легковесность, но не устраивали условия лицензии.
В 1991 году он решил создать собственную бесплатную альтернативу Minix для 32-битных процессоров Intel. Для этих целей он использовал инструменты проекта GNU, основанного Столлманом.
То, что начиналось как хобби, вскоре превратилось в одну из самых популярных операционных систем и международный феномен — Linux.Через какое-то время вокруг ОС сформировалось массивное сообщество, которым нужно было управлять.
Поэтому Линус был вынужден занять руководящую роль и отойти от разработки как таковой. По состоянию на 2006 год лишь два процента исходников ядра Linux были написаны лично Торвальдсом.
Как руководитель Линус известен своей прямотой, иногда доходящей до грубости. В прошлом году ему пришлось извиняться за своё поведение. Торвальдс даже временно покинул пост координатора Linux-проекта. Но вскоре вернулся к своим обязанностям и планирует дальше развивать экосистему open source.
Гвидо Ван Россум родился в 1956 году в Харлеме — столице Северной Голландии. В возрасте десяти лет молодому Гвидо подарили конструктор из электронных компонентов. Исчерпав книжку с примерами, он начал собирать собственные схемы. Этот опыт привил ему любовь к электронике. В старшей школе Россум интенсивно изучал физику и хотел проектировать электронные приборы.
Программированием, в отличие от Торвальдса и Столлмана, Гвидо начал заниматься значительно позже. В 70-х он поступил в Амстердамский университет на математический факультет. В здании вуза располагался мейнфрейм, возможности которого поразили Гвидо.
Он начал изучать Agol, Fortran и Pascal, а впоследствии и вовсе перевёлся на факультет информатики.Еще будучи студентом, Россум начал работать программистом. Под руководством Эндрю Таненбаума, создателя Minix, он включился в разработку операционной системы Amoeba, и позже — интерпретированного, объектно-ориентированного языка ABC. По всем меркам этот язык опережал своё время, но надежды, которые на него возложили, не оправдались.
Продукт провалился и через три года его разработку забросили.Во время рождественских каникул 1989 года Россум начал самостоятельно разрабатывать новый язык программирования, включавший в себя лучшие идеи «мертвого» ABC. Проект получил название Python — в честь комедийной группы Монти Пайтон, которую он так любил.В 90-е Python обогнал по популярности не только своих предшественников, но и многие современные языки. Вокруг него образовалось активное сообщество, а Гвидо был окрещен «Великодушным пожизненным диктатором» проекта.

Позднее Россум переехал в США. Там он работал в Google и популяризировал программирование среди детей. В 2008 году Гвидо начал помогать еще молодой команде Dropbox и трудится в её составе до сих пор.Что касается Python, то его популярность только растёт. Сегодня миллионы людей начинают свой путь в мире программирования именно с него.
Чтобы open-source технологиями пользовались, нужно, чтобы кто-то про них писал. И Тима О’Райли буквально «сформировал» язык, которым мы говорим про open-source.

Тим О’Райли родился в 1954 году на юго-востоке Ирландии. Еще в детстве он переехал в Сан-Франциско. В отличие от других людей, упомянутых в статье, Тим получил гуманитарное образование, и выпустился из Гарварда с дипломом по античной литературе.
Вскоре после выпуска О’Райли женился, а также получил грант на перевод греческих басен. Но семью академическими грантами не накормишь — О’Райли начал искать способ построить карьеру.
Знакомый — инженер по имени Питер Брайер — предложил Тиму работу — писать техническую документацию для продуктов его компании. Несмотря на то что О’Райли ни разу в жизни не видел компьютеров, он согласился. Так, началось его путешествие в мир IT.К середине 80-х Тим накопил достаточно знаний, чтобы основать свою компанию. За это время он разработал собственный технический язык — простой и доступный даже таким гуманитариям, как он сам. Изначально его организация занималась производством документации на заказ, но позже превратилась в целую издательскую империю — O’Reilly.
Первым «прорывом» O’Reilly стала книга «The Whole Internet User's Guide and Catalog». Она вышла в свет в 1992 году, на заре интернета — и долгое время оставалась одним из самых авторитетных ресурсов по теме. Ежегодно компания продавала по 250 тыс. копий этой книги.
Когда в середине 90-х к Тиму обратились Cisco с предложением купить компанию. Он им отказал, уверенный, что сможет самостоятельно развивать бизнес. Так и получилось — сейчас его издательство зарабатывает более 50 миллионов долларов в год.
Помимо издательской деятельности, Тим активно участвовал в жизни Кремниевой долины. За способность предсказывать тренды его прозвали «оракулом». В 1998 году именно он популяризировал термин open source software, в нулевых опубликовал работу про Web 2.0. Последние несколько десятков лет он остается одной из самых видных фигур культуры мэйкеров.
Как в свое время коммерческие решения практически вытеснили (хотя и временно) свободно распространяемый код.

Период Второй мировой войны стал временем технологических прорывов для США. Сотрудничество научных институтов с военными организациями принесло плоды в сфере радио, криптографии и полупроводников.
После войны проведенные исследования положили основу таким изобретениям, как транзистор, а научные связи превратились в бизнес-контакты. Началось активное развитие ЭВМ.
Первый коммерческий компьютер IBM 701 — носил неофициальное название Defense Calculator. С 1952 по 1955 год с конвейера сошли лишь 19 экземпляров этой ЭВМ. Приобрести их было нельзя, но можно было арендовать на месяц за немалые деньги — порядка $12 тысяч ($107 тыс. по современным меркам).
Список компаний, которые позволили себе такую роскошь, ожидаемо состоит почти целиком из научных и государственных организаций. При этом за такие деньги они получали «голое» железо без какого-либо программного обеспечения и операционной системы.
Чтобы упростить работу, инженеры передавали программы друг другу. В индустрии царил дух академического сотрудничества. Научные институты, военные заказчики и большие бизнесы создавали группы для обмена знаниями, а их продукты труда носили статус общественного достояния.
Наиболее известными группами, участники которых делились «исходниками» друг с другом, были PACT, SHARE и DECUS. Первая из них, PACT — Project For the Advancement Of Coding Techniques — состояла из представителей военных подрядчиков, вроде Lockheed и Douglas, а также IBM.
Вместе они разработали серию одноимённых компиляторов для IBM 701 и 704, которые использовали методы хеширования. Руководство группы подчеркивало «ценность кооперации» в работе над подобными проектами и обещало сохранить этот дух в будущем.
Преемником PACT стала появившаяся в 1955 году группа SHARE, создавшая операционную систему SOS (Share Operating System). Это примитивное, по современным меркам, решение для ввода и вывода информации выросло на внутренних разработках General Motors. Именно SOS заложила основу для первых операционных систем пакетной обработки, которые выполняли несколько заданий, подготовленных одним или разными пользователями. Подобные системы доминировали на рынке ЭВМ в конце 50х — начале 60х.
В 1961 году появилась еще одна группа под названием DECUS (Digital Equipment Computer Users' Society). Её участники обменивались друг с другом программами на магнитных лентах. DECUS просуществовала довольно долго — в 1998 году в ней все еще состояли 50 тыс. человек.
Благодаря научному сотрудничеству и обмену ПО появились языки программирования Interlisp и UCI Lisp, и эта культура дала толчок к развитию открытой ОС Unix. Но в конце 60-х – начале 70х произошло несколько важных событий, приостановивших развитие open source. Они сделали программы продуктом, который можно монетизировать.

Если в комплекте с IBM 701 не было ПО, то в последующих мейнфреймах его становилось всё больше. Весь этот софт был включён в стоимость системы, и поставлялся в комплекте. С точки зрения регуляторов, это было посягательством на монополию. После небольшого давления и угрозы судебного разбирательства IBM сдались, и в 1969 году начали продавать ПО отдельно. Это привело к появлению рынка программ для машин IBM.
Относительно высокоуровневые языки — FORTRAN и COBOL — получили широкое распространение, а микрокомпьютеры пришли в дома энтузиастов. Начала формироваться грань между пользователями и программистами. Появились сложные программные системы, в том числе ориентированные для персонального использования. И их создатели, вполне логично, хотели защитить свой труд. Это повлекло за собой публичное обсуждение: можно ли патентовать программные продукты? Каким образом на них распространяются законы об интеллектуальной собственности?
В 1974 была организована специальная комиссия, которая закрепила права программистов в американском законодательстве. С того момента производители ПО встали в один ряд с изобретателями. Немного позже апелляционный суд США принял решение, что авторское право распространяется на компьютерные программы. Разработчики получили возможность контролировать, кто пользуется результатами их труда. И в 1983 году свободно распространяемое ПО уступило проприетарному. Тогда IBM перестали раскрывать исходный код своих программ.
Так, закончилась целая эпоха свободного обмена софтом. Но были и люди, которые не собирались с этим мириться. Люди, благодаря которым свободный софт процветает и сейчас.




Компания NVIDIA является крупнейшим в мире производителем графических процессоров. Ее разработки на первом месте не только в игровых видеокартах, но и в решениях для различных вычислений. В том числе — в задачах искусственного интеллекта. В чем преимущества чипов NVIDIA, и почему конкурентам сложно их догнать в этом направлении?
GPU, или «графический процессор». Впервые это название было использовано в 1999 году для чипа видеокарты GeForce 256, в состав которого вошел блок аппаратной трансформации и освещения. В играх он выполнял эти нехитрые расчеты, освобождая от них центральный процессор ПК.
Но это было только начало. В 2001 году в графических процессорах появились куда более сложные компоненты — шейдерные блоки. Вначале степень их программируемости была ограниченной. Но уже через пару поколений видеокарт шейдеры получили поддержку графических вычислений с плавающей запятой (Floating Point, FP), а их количество в чипах кратно возросло.
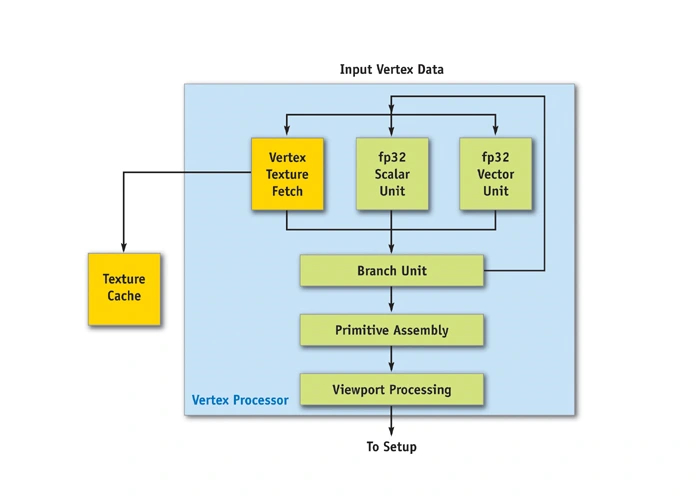
В линейке GeForce 6000 родом из 2004 года вертексные шейдеры впервые научились выполнять вычисления формата FP32
Уже тогда некоторые исследователи стали проводить собственные испытания в попытках ускорить математические вычисления с помощью ГП. Этот процесс был сложным, так как для расчетов приходилось переформулировать задачи в вызовы графических API DirectX или OpenGL. Для доступности подобных вычислений в сторонних программах был необходим собственный API, который невозможно было создать без поддержки производителей видеокарт.
В 2006 году на конференции SIGGRAPH, посвященной компьютерной графике, компания ATI представила «Close to Metal». Это был первый API для выполнения неграфических вычислений на видеокартах ATI, который вскоре был переименован в ATI Stream.

В это время в недрах NVIDIA была почти готова новая графическая архитектура Tesla, которая изначально проектировалась с учетом возможности неграфических расчетов. После выпуска первых игровых видеокарт на ее основе, в феврале 2007 года компания представила свой собственный API для вычислений — CUDA. А три месяца спустя были выпущены первые продукты NVIDIA, предназначенных специально для вычислений: Tesla С870, D870 и S870. Этот момент можно считать началом главы массово доступных вычислений на графических процессорах.

Темп вычислений на графических чипах NVIDIA и ATI уже в 2007 году в несколько раз превышал значения, которые могли обеспечить центральные процессоры того времени. Топ NVIDIA обеспечивал 384 Гфлопс, а флагман ATI — 475 Гфлопс. По сравнению с 48 Гфлопс, которыми мог оперировать старший ЦП линейки Intel Core 2 Quad, разница была практически на порядок.
Однако все упиралось в возможность многопоточной обработки. NVIDIA G80 обладал 128 шейдерными процессорами, а конкурирующий ATI R600 — целыми 320. Распределить нагрузку между таким количеством вычислительных единиц в то время, когда даже четыре ядра процессора еще не везде использовались, было задачей не из простых. Но главный вектор продвижения все же нашелся — им стали научные проекты. Основная масса расчетов для них масштабируется практически линейно, поэтому именно они извлекали больше всего пользы из CUDA и Stream.
Через некоторое время неграфические вычисления нашли применение и в домашних ПК. С их помощью мощности видеокарт стали использоваться в различных программах для конвертации и кодирования видео. А в августе 2008 года NVIDIA решила использовать CUDA для просчетов PhysX — движка физического поведения объектов в играх.
В 2009 году свет увидел DirectX 11, в состав которого был включен API для неграфических вычислений DirectCompute. Практически одновременно с ним появляется и другой похожий, но открытый API — Open CL. Именно в его пользу делает выбор AMD, потихоньку забросив развитие Stream. А вот NVIDIA хоть и реализовывает поддержку новых API, но при этом не отказывается от своей CUDA. И, как покажет практика, совсем не зря.
После появления универсальных шейдерных процессоров их количество в чипах росло по экспоненте. Благодаря этому топовый чип GF100, появившийся через три года после G80, работал с вычислениями вчетверо быстрее своего «предка». Ускорение, которые давали вычисления на ГП по сравнению с ЦП, становилось все больше, а сами вычисления распространялись все шире.
В 2012 году c помощью API CUDA группа энтузиастов в университете Торонто решает создать одну из первых сверточных нейросетей для распознавания изображений. Для этого они используют более миллиона изображений и три терафлопса вычислительной мощности, которые обеспечили две видеокарты GTX 580 на базе ГП GF110. Проект получает название AlexNet. Он был представлен на конкурсе ImageNet Large Scale Visual Recognition Challenge, получив первое место за распознавание c минимальным количеством ошибок.
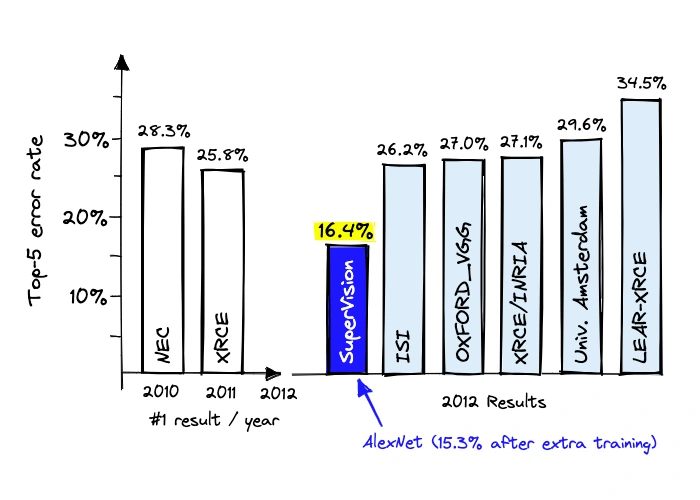
Архитектура AlexNet оказала существенное влияние на многие последующие проекты в области глубокого обучения с помощью графических процессоров. И, как следствие, в разы увеличила интерес к самим ГП в роли вычислительных чипов для подобных расчетов.
До 2017 года NVIDIA продолжала наращивать «чистую» мощь своих графических процессоров. Если в 2007 году топовый G80 мог обеспечить 384 Гфлопс при расчетах, то в 2017 году чип GP102 достигал в них уже 12 Тфлопс. Но компания продолжала искать пути по более существенному наращиванию производительности, так как задачи для ГП со временем становились все сложнее и сложнее.
Конец 2017 года можно считать переломным моментом для нейросетевой отрасли. Тогда NVIDIA представила первый графический процессор с тензорными ядрами — GV100 на архитектуре Volta. В то время, как шейдерные процессоры могли работать с вычислениями полной точности (FP32), тензоры поддерживали только половинную (FP16), но с гораздо большим темпом. Вдобавок к этому появилась возможность использовать целочисленные вычисления (INT32) на шейдерах одновременно с плавающими. Для эффективного задействования всех вычислительных элементов вместе с чипом и видеокартами на его основе NVIDIA представила API CUDA версии 7.0.
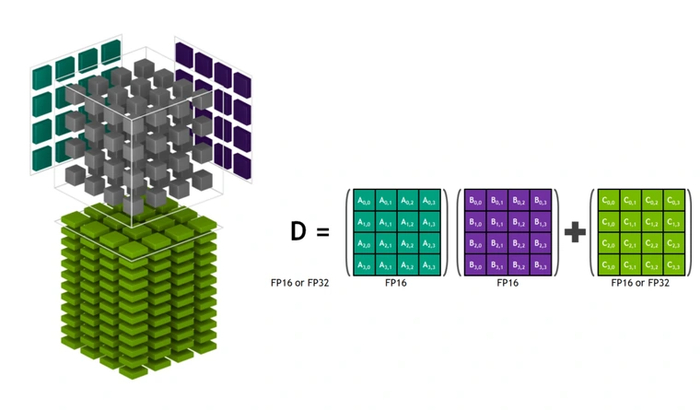
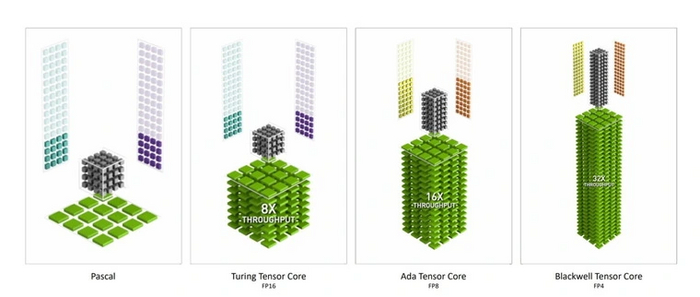
Эксперимент был успешным: производительность в задачах глубокого обучения возросла кратно, ведь высокая точность им была не нужна. Чипы AMD, до этого хоть как-то конкурирующие за счет вычислительной мощности шейдеров, остались далеко позади. А NVIDIA занялась разработкой следующей графической архитектуры — Turing. Теперь каждое поколение компания совершенствовала тензорные ядра. Помимо рабочих нагрузок, они пригодились и в играх для технологии повышения производительности DLSS. В 2022 году NVIDIA представила графическую архитектуру Ada Lovelace. Ее тензорные ядра поддерживают вычисления в менее точном формате FP8, но в двойном темпе по сравнению с FP16. Таким образом, даже без учета роста количества тензоров, пиковую производительность обучения удалось удвоить. В следующей архитектуре Blackwell появилась поддержка вычислений FP4, которая в очередной раз удваивает пиковую производительность тензоров.
Сила ГП NVIDIA не только в «железе», но и в программной поддержке. С выходом каждой графической архитектуры компания обновляет API CUDA и предоставляет разработчикам подробные инструкции по работе с ним. Благодаря этому производители ПО своевременно учатся использовать особенности новых чипов, что позволяет «выжимать» из них в реальных задачах практически всю возможную производительность.
На сегодняшний день ГП NVIDIA — самые востребованные чипы для обучения и работы различных нейросетей. Высокая вычислительная мощность и постоянно развивающаяся программная платформа CUDA, совместимая со многими популярными фреймворками вроде TensorFlow и PyTorch, делают их лучшим выбором для вычислений глубокого обучения. И лидер этого рынка в лице Open AI, и недавно «выстрелившая» DeepSeek обучали свои модели именно на чипах от NVIDIA.
Для вычислительных центров компания выпускает отдельную линейку карт GPU Accelerator (бывшая Tesla). Многие из них основаны на тех же графических процессорах, что и игровые видеокарты. Но для наиболее производительных решений NVIDIA в последнее время разрабатывает отдельные чипы, совершенствуя их чуть раньше более доступных решений.

Тем не менее, все основные элементы графической архитектуры даже в таких «больших» чипах схожи с теми, что используются в игровых видеокартах GeForce. Поэтому их тоже можно использовать для несложных задач глубокого обучения, если хватает видеопамяти. В этом кроется огромный плюс: единая графическая архитектура и поддержка CUDA для игровых, профессиональных и вычислительных решений делает ГП NVIDIA доступными как для крупных фирм, так и для небольших стартапов.
В этом плане NVIDIA поступает умно: даже с одной игровой картой вместе с CUDA и ее развитыми инструментами разработчик может получить желаемый результат — пусть и заметно медленнее, чем с вычислительным сервером. При этом он привязывается к API, и при переходе на более производительные решения вновь будет использовать ГП NVIDIA.
Но лавры CUDA не дают покоя многим другим компаниям, в частности — Intel. В ответ она разработала открытый стандарт oneAPI, который призван унифицировать вычисления на различных чипах: центральных и графических процессорах, программируемых матрицах и специализированных ускорителях. В 2024 году Intel вместе с Google, Qualcomm, Samsung, ARM, Fujitsu, Imagination и VMware создали консорциум Unified Acceleration Foundation. Его целью будет дальнейшее развитие инициатив oneAPI.
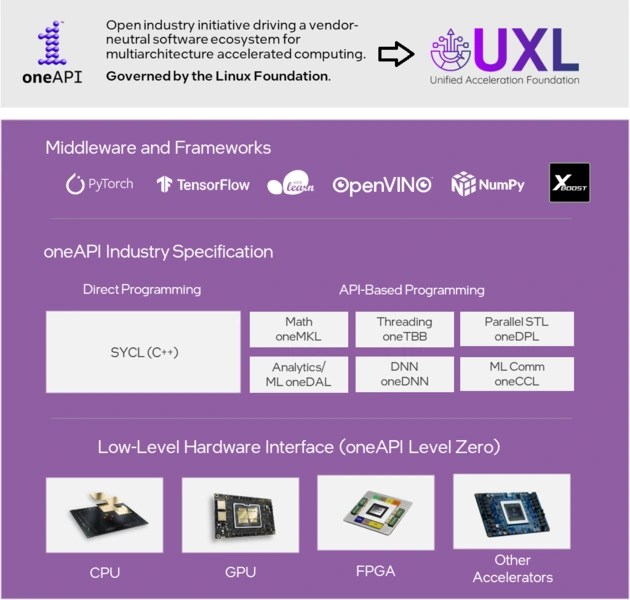
Изменит ли как-то это баланс оборудования на рынке нейросетей — вопрос будущего, причем не самого ближнего. Сегодня реальный конкурент у NVIDIA на этом направлении все также один: это компания AMD с картами Instinct. С 2020 года «красные» разделили свою графическую архитектуру на две параллельно развивающиеся ветви. RDNA предназначена для игровых и профессиональных видеокарт, а CDNA — для центров обработки данных. Современные чипы AMD используют программный стек ROCm, и могут ускорять вычисления невысокой точности с помощью матричных блоков. Но до возможностей API CUDA и производительности тензорных ядер NVIDIA им все еще далеко.

Возможно, в скором времени определенную конкуренцию NVIDIA смогут предложить и чипы от Huawei. Компания разрабатывает собственные ИИ-ускорители, и последнее решение в лице Ascend 910C выглядит довольно неплохо. Однако стоит учитывать, что Huawei ограничена санкциями и не имеет доступа к самым современным техпроцессам. Поэтому, скорее всего, ускорители компании останутся эксклюзивным решением для китайского рынка, а будущие поколения из-за ограничений техпроцесса не получат существенного роста производительности на чип.

А пока лидерство NVIDIA в этой сфере не подлежит сомнению. Благодаря буму нейросетей ее доходы от вычислительных решений впервые превысили аналогичные от игровых видеокарт уже в 2023 году. 2024 год оказался для компании еще более успешным: на оборудовании для вычислений она заработала вчетверо больше, чем на игровом рынке. посмотрим что ей принесет год грядущий. Важно то, что NVIDIA не забывает вкладывать часть полученной прибыли в новые разработки. Каждый год компания представляет их на конференции GPU Technology Conference (GTC), основной темой которой в последнее время является искусственный интеллект. В этом году GTC прошел с 17 по 21 марта. NVIDIA раскрыла подробности о будущих графических архитектурах Blackwell Ultra и Rubin, а также презентовала новый вычислительный чип B300.
К сведению:
В 2006 году на конференции SIGGRAPH, посвященной компьютерной графике, компания ATI представила «Close to Metal»
Самое интересное, что первоначально ATI удалось реализовать вычисления не на универсальных шейдерах, а на пиксельных. Для этого в чипе R580, который стал основой для первой вычислительной карты, они уместили аж 48 (!) пиксельных шейдеров с продвинутым управляющим блоком.
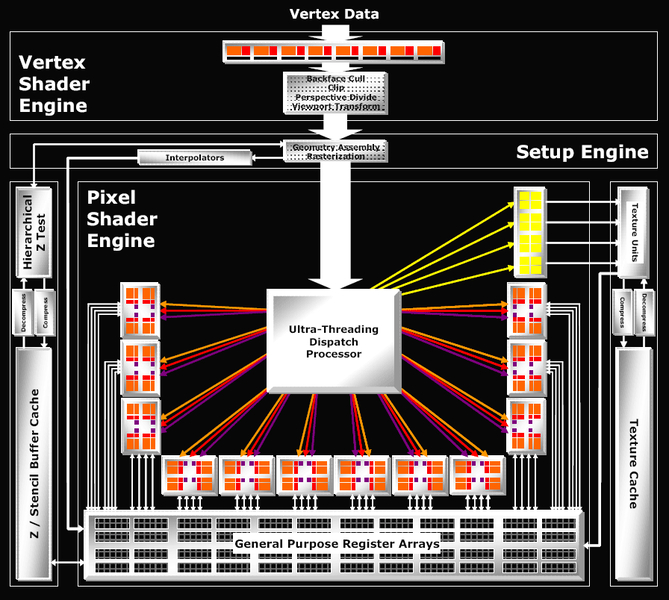
Для сравнения: у старшего R520 из того же поколения, который был выпущен на 3 месяца раньше, было всего 16 пиксельных шейдеров, а у G70/G71 от главного конкурента - 24.

Человеческий мозг — восхитительное устройство. Он вдохновляет современных исследователей, которые создают искусственные нейроны, словно ученики скульптора, копирующие бюст Сократа. И результат тому — искусственная нейронная сеть (ИНС), одно из самых обсуждаемых явлений современности.
Глубокое понимание нейросетей предполагает, что вы в курсе понятий математическая функция, перцептрон и матрица весов. Мы же предлагаем поговорить про это явление на общечеловеческом языке, чтобы всем было понятно.
Искусственная нейронная сеть неспроста получила такое название, ссылаясь к работе нейронов головного мозга. Под нейросетью понимается система вычислительных единиц — искусственных нейронов, функционирующих подобно нейронам мозга живых существ. Как и биологические, искусственные нейроны получают и обрабатывают информацию, после чего передают ее дальше. Взаимодействуя друг с другом, нейроны решают сложные задачи.Среди них:
определение класса объекта,
выявление зависимостей и обобщение данных,
разделение полученных данных на группы на основе заданных признаков,
прогнозирование и т. д.
Нейронная сеть воспроизводит психические процессы, например, речь, распознавание образов, творческий выбор, мышление. Те области, которые еще вчера мыслились нами как возможности исключительно человеческого разума, становятся доступными искусственному интеллекту. Другое преимущество нейросетей перед традиционным ПО — возможность обучаться. Нейронные сети апгрейдятся на основе поступающих данных о мире людей, опыта и ошибок. И, надо сказать, они уже здорово эволюционировали.
Термин «нейронная сеть» появился еще в 1943 году, но популярность эта технология обрела только в последние годы: посредством магазинов приложений стало распространяться ПО, созданное при помощи нейросетей, в колонках новостей запестрели заголовки о фантастических возможностях искусственного интеллекта. Сегодня нейронные сети используются во множестве сфер.
Искусственными нейронными сетями сейчас пользуются люди, далекие от сложных математических моделей. Когда создатели ПО поняли, что нейросети — это как минимум весело, рынок приложений для смартфонов наводнился программами для работы с изображениями на основе искусственных нейронных сетей. ПО для обработки изображений (DeepDream, Prisma, Mlvch), «старения»,замены лиц на фотографиях и видео моментально стало вирусным. На самом деле, это весомое оружие в век соцсетей. Приложения типа знаменитого FaceApp могут не только позабавить — с ними можно здорово изменить внешность: нанести профессиональный мейкап, изменить волосы, скорректировать черты лица и даже добавить эмоции и мимику. Причем сейчас все это выглядит настолько натуралистично, что едва ли с первого взгляда заподозришь подвох.

Нейросети знают многое о человеческих лицах: по фотографии они могут определить возраст, пол, настроение, спрогнозировать, как лицо будет выглядеть в старости, анимировать статическое изображение, заставив Барака Обаму говорить то, что он не говорил, и оживить знаменитую Мону Лизу. По фотографии теперь можно найти человека, а китайские нейросети Megvii даже ищут собак по изображению носа. Причем ИНС работает не только с изображениями, но и со звуком. Массачусетский технологический институт недавно представил нейросеть (Speech2Face), определяющую национальность, пол и возраст человека по голосу.
Звучит впечатляюще и пугающе. Конечно, мы можем развлекаться, играя со своей фотографией, но только представьте, какой отнюдь не развлекательный потенциал у этой технологии. Уже сейчас можно найти любого человека по фото, создать реалистичные несуществующие лица для рекламы, модельного бизнеса или кино, заставить статичные изображения говорить и двигаться. Нетрудно представить, что нейросети скоро станут целой индустрией.
Нейросети способны помогать правоохранительным органам искать преступников, бороться с наркобизнесом и терроризмом, быстро находить в интернете противозаконный контент. Как и при использовании камер наблюдения, здесь есть свои сложности, ведь нейросети можно применять как для поиска пропавших детей в отряде «Лиза Алерт», так и для ужесточения контроля над населением.

Уже есть несколько примеров проектов внедрения искусственных нейронных сетей в России. В ГИБДД хотят научить нейросеть обнаруживать факт кражи автомобильных номеров. По изображению автомобиля ИНС сможет установить, соответствует ли машина своему номеру. Это поможет своевременно выявлять подделку или кражу номеров. Руководитель Департамента транспорта Москвы Максим Ликсутов подтвердил, что данная программа сейчас проходит тестирование.
Еще один пример возможностей нейросетей в распознавании изображений – эксперимент Департамента информационных технологий Москвы по созданию сервиса для передачи показаний приборов учета воды. Возможно, вскоре нам не придется вводить показания вручную, достаточно будет лишь сфотографировать свой счетчик, а нейросеть сама распознает цифры с изображения.
Нейросети — настоящий подарок для бизнеса и горе для работников. Мы живем в эпоху, когда данные имеют огромную ценность. Поверьте, мировые корпорации уже проанализировали ваш профиль в соцсетях и предоставляют вам персонализированную рекламу. Только представьте, что способности сетей искусственных нейронов к анализу и обобщению можно использовать для получения еще большего массива знаний о потребителях. Например, в 2019 году компания McDonald’s наняла специалистов по разработке нейросетей для создания индивидуальной рекламы. Потом не удивляйтесь, откуда бизнес знает о том, какую еду, одежду и косметику вы предпочитаете.
В банковской сфере нейросети уже применяются для анализа кредитной истории клиентов и принятия решений о выдаче кредита. Так, в 2018 году «Сбербанк» уволил 14 тысяч сотрудников, которых заменила «Интеллектуальная система управления» на основе нейросети. Вместо людей рутинные операции теперь выполняет обучаемый искусственный интеллект. По словам Германа Грефа, подготовку исковых заявлений нейросети проводят лучше штатных юристов. Также финансисты обращаются к прогностическим способностям искусственного интеллекта для работы с плохо предсказуемыми биржевыми индексами.
Что будет, если нейросеть познакомить с шедеврами мировой живописи и предложить написать картину? Будет новое произведение искусства. Предложите нейросети сочинения Баха, и она придумает похожую мелодию, книги Джоан Роулинг – она напишет книгу «Гарри Поттер и портрет того, что похоже на большую кучу золы». Книга «День, когда Компьютер написал роман», созданная японской нейросетью, даже получила премию HoshiShinichiLiteraryAward.
Специалисты компании OpenAI заявляют, что их программа по созданию текстов пишет любые тексты без человеческого вмешательства. Тексты за авторством нейросети не отличаются от тех, что написаны человеком. Однако в общественный доступ программа не попала, авторы опасаются, что ее будут использовать для создания фейк-ньюс.
В 2018 году на аукционе «Сотбис» за полмиллиона долларов был продан необыкновенный лот: «Эдмонд де Белами, из семьи де Белами. Состязательная нейронная сеть, печать на холсте, 2018. Подписана функцией потерь модели GAN чернилами издателем, из серии одиннадцати уникальных изображений, опубликованных Obvious Art, Париж, в оригинальной позолоченной деревянной раме». Робби Баррат, художник и программист, научил нейросети живописи настолько, что теперь она уходит с молотка как шедевры искусства.

Появились нейросети-композиторы и даже сценаристы. Уже снят короткометражный фильм по сценарию, написанному искусственным интеллектом («Sunspring») — вышло бессмысленно и беспощадно, как заправский артхаус. Тем временем нейросеть от Яндекса произвела на свет пьесу для симфонического оркестра с альтом и альбом «Нейронная оборона» в стиле группы «Гражданская оборона», а позже начала писать музыку в стиле известных исполнителей, например группы Nirvana. А нейросеть под названием Dadabots имеет свой канал на YouTube, где генерируется deathmetal музыка.
Удивительно, как органично нейросети вписались в мир современного искусства. Получим ли мы робота-Толстого через пару лет? Сможет ли нейросеть постигнуть все глубины человеческих проблем и чувств, чтобы творить не компиляцию, а настоящее искусство? Пока эти вопросы остаются открытыми.
Нейросети уже помогают улучшить качество диагностики различных заболеваний. Анализируя данные пациентов, искусственный интеллект способен выявлять риск развития сердечно-сосудистых заболеваний, об этом заявляют ученые Ноттингемского университета. По данным исследования, обученная нейросеть прогнозирует вероятность инсульта точнее, чем обычный врач по общепринятой шкале.
В открытом доступе появились даже приложения для диагностики на основе нейросетей, например SkinVision, которое работает с фотографиями родинок и определяет доброкачественность или злокачественность вашего невуса. Точность приложения — 83 %.

Все ли так оптимистично в применении нейросетей? Есть ли сценарии, при которых эта технология может нанести вред человечеству? Вот несколько самых актуальных проблем на сегодняшний день.
Фейки. Благодаря возможностям нейросетей появились программы для замены лиц и даже времени года на фото и видео. Как, например, нейросеть Nvidia на основе генеративной состязательной сети (GAN). Страшно представить, какие фото и видео можно получить, если применять подобные программы с целью создания убедительных фейков. Также нейросеть может на основе короткого фрагмента голоса создать синтетический голос, полностью идентичный оригиналу. Подделать чью-то речь? Легко. Подделать чью-то фотографию? Проще простого.
Трудности понимания. Когда процесс обучения нейросети завершается, человеку становится трудно понять, на каких основаниях она принимает решения. До сих пор непонятно, как у ИНС получилось обыграть лучшего игрока мира в Го. В этом смысле нейросеть — ящик Пандоры.

Оружие хакеров и мошенников. Считается, что хакеры могут использовать возможности нейросетей для преодоления систем антивирусной защиты и создания нового поколения вредоносных программ. Также нейросети соблазнительны для мошенников, например, искусственный интеллект, способный имитировать общение с живым человеком и заполучать доверие.
Безработица. Уже сейчас в сети можно встретить немало тестов а-ля «заменят ли роботы и нейросети вашу профессию». С одной стороны, забавно, с другой — пугающе. Нейросети способны оставить без работы дизайнеров, художников, моделей, копирайтеров, административных служащих среднего звена — и это только малый перечень того, где искусственный интеллект показывает сейчас вполне впечатляющие результаты.
Злой суперкомпьютер. Создание искусственного интеллекта, превышающего возможности человеческого разума чревато последствиями. Об этом уже создано множество научно-фантастических книг и фильмов. Может, конечно, все не будет так страшно и фантастично, как в фильме «Превосходство», но оценить риски заранее практически невозможно, а соблазн развивать нейросети все больше и больше слишком велик.
Нейросети стремятся сделать мир более персонализированным: каждому из нас будут предлагаться блюда, музыка, фильмы и литература по вкусу. В сериалах мы сможем выбирать развитие сюжета, кстати, Netflix уже экспериментирует с такими решениями.
Так как искусственный интеллект уже начал выполнять человеческие задачи, миллионы квалифицированных специалистов могут постепенно лишаться рабочих мест. Работодателю будет проще запустить нейросеть, чем нанимать человека. По тонкому замечанию Антона Балакирева, руководителя интернет-портала Robo-sapiens.ru, нейросети не уходят на пенсию, не страдают алкоголизмом и депрессией. Идеальный работник.
Однако искусственный интеллект по-прежнему не может заменить человеческий мозг. В вопросах ответственности, норм морали и нравственности, а также критических систем безопасности нам не следует доверять нейросети безраздельно, пусть она и умнее нас. Доверяй, но проверяй.

Пару десятилетий назад систему распознавания лиц можно было увидеть разве что в шпионских боевиках. Сегодня это практически неотъемлемая часть смартфона и даже инфраструктуры крупных городов. Что это за технология, как она работает и где применяется?
Первые исследования по идентификации лиц проводились еще в 1960 году. Вуди Бледсо, профессор Техасского университета, основал свою небольшую компанию Panoramic Research Incorporated, где тестировал всевозможные алгоритмы, в том числе по распознаванию символов, вместе с коллегами. Несмотря на то, что особых успехов компания не снискала, согласно неподтвержденным источником оставаться на плаву ей позволяло ЦРУ.
Вуди Бледсо мечтал создать «интеллектуальную машину», в возможности которой входило распознавание лиц. В 1963 году он представил проект, согласно которому его система должна была идентифицировать по фотографиям десять лиц. Сегодня это выглядит ничтожно, но в те годы вычислительная техника представляла собой массивные шкафы с магнитными лентами и перфокартами. Не существовало даже универсального метода для элементарной оцифровки фотографий.

Спустя четыре года проб и ошибок было решено распознавать лицо на основе нескольких ключевых точек: нос, губы, ширина рта и так далее. Созданная система в итоге смогла идентифицировать лица, опираясь на вводимые данные и предлагая правильный вариант фотографии. Однако оставалась проблема с улыбкой, разными ракурсами и возрастами для одного того же человека. Из-за таких изменений алгоритм мог идентифицировать одного и того же человека на фотографиях как разных людей.
В итоге к 1967 году была спроектирована более совершенная система, которая уже успешно идентифицировала лица на основе обычных вырезок из газет. Что самое важное, была доказана высокая эффективность. Человек справлялся с сопоставлением подгруппы из 100 человек за три часа. Машина — за три минуты, пусть и с некоторыми огрехами.
В 1973 году удалось создать автоматизированную систему, которая из цифровых фотографий была способна самостоятельно извлекать данные о чертах лица. Ранее эти параметры приходилось вводить вручную. Несмотря на все эти достижения, практическое применение системы распознавания лиц началось лишь с 2010-х годов.
Причин несколько:
Рост вычислительной мощности. Только в последние годы производительность компьютерной техники стала достаточной, чтобы обрабатывать такие большие объемы данных.
Сформированная база. Десятилетия назад у корпораций и государственных органов не было фотографий не то что обычных граждан, но и многих преступников. Сегодня эта проблема решена благодаря социальным сетям и цифровой базе документов.
Развитие камер. Лишь в последние годы появились относительно недорогие камеры с достаточным качеством съемки, что позволило применять их массово как в смартфонах, так и в системах наблюдения.
Распознавание лица — многоэтапный процесс. В первую очередь задействуются системы считывания, именно они получают снимок лица человека и передают его в центр обработки данных.
Обнаружение — первый этап. В кадр камер обычно попадает не только лицо, но и множество других объектов окружения. Человек сразу же способен определить, где автомобиль, где задний план, а где находится и сам человек. Но для компьютера любая фотография — это всего лишь набор пикселей. Решением этой проблемы стал метод Виолы — Джонса, разработанный в 2001 году.
Он основан на использовании специальных паттернов (масок), чтобы определять светлые и темные зоны. По специальной формуле из темных и светлых пикселей выполняются вычисления, на основании которых выносится результат, соответствует ли маска обрабатываемому участку изображения. В человеческом лице можно выделить конкретные паттерны. Как только алгоритм находит определенное число совпадений, он выносит вердикт — вот в этой зоне расположено человеческое лицо. Предварительно алгоритм обучают на других лицах.
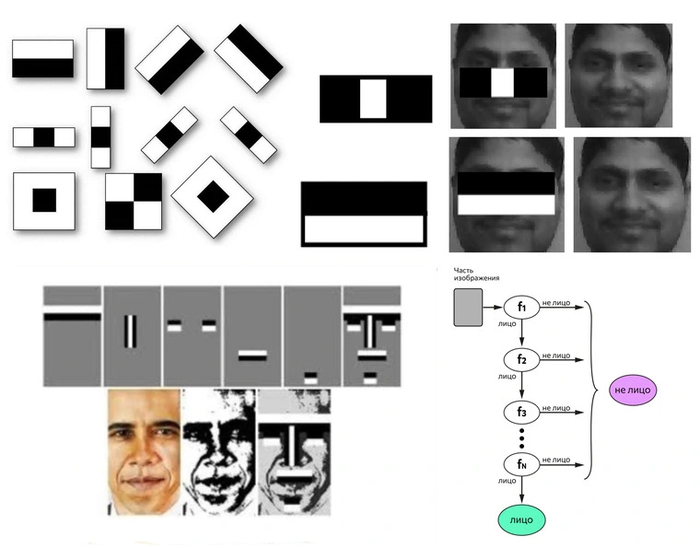
Однако в последние несколько лет все больше систем уже используют нейросети. Они точнее, менее чувствительны к ракурсу съемки, а при достаточном аппаратном обеспечении еще и быстрее.
Нормализация — второй этап после обнаружения лица. Чтобы в дальнейшем было проще определять ключевые параметры, система пытается выстроить «идеальный кадр» — лицо, которое смотрит строго прямо. Здесь могут выполняться различные преобразования вроде поворота, изменения масштаба и других деформаций.
Построение «отпечатка лица» — следующий шаг. Как именно оно выполняется — зависит от используемого алгоритма. Все разнообразие методов можно разделить на две большие группы: геометрические и машинные.
Геометрические методы анализируют отличительные признаки изображений лица и формируют определенный массив данных на их основе. Массив сравнивается с эталоном и, если совпадение выше определенного порога — лицо найдено.
Для анализа обычно используются ключевые точки, между которыми вычисляются расстояния. Количество требуемых точек также зависит от каждого конкретного алгоритма — может использоваться от 68 до 2000 маркеров.

К геометрическим алгоритмам относится метод гибкого сравнения на графах, скрытые Марковские модели, метод главных компонент и другие.
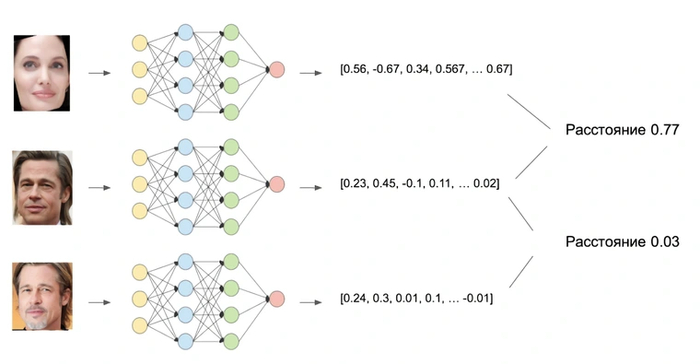
Машинные методы — это нейросети. Они обучаются на огромной базе изображений и, анализируя совокупность определенных признаков, в итоге определяют совпадения лиц. Если максимально упростить, то для каждого фото формируется определенный вектор. Например, для трех фото (Анджелины Джоли и два Бреда Питта) мы получим три разных вектора. Разница между фотографиями Питта будет минимальной, что позволяет сделать вывод — на фото один и тот же человек.
У крупнейших компаний имеются авторские алгоритмы, которые постепенно модифицируются. Например, в 2018 году в тестировании NIST были представлены больше десяти алгоритмов от ведущих компаний в сфере распознавания лиц. Первое место заняла китайская компания Megvii, второе — российская VisionLabs, а замкнула тройку французская фирма OT-Morpho. К другим известным проектам также стоит отнести систему DeepFace (Meta**), FaceNet (Google) и Amazon Rekognition.
Помимо 2D-распознования лиц с коэффициентом ошибок в 0,1% существует технология 3D-распознования. Для нее коэффициент составляет всего 0,0005%. В таких системах используются лазерные сканеры с оценкой дальности или сканеры со структурированной подсветкой поверхности. Самая известная технология — FaceID от компании Apple, однако и у топовых Android-смартфонов также имеются системы распознавания с построением 3D-карты.

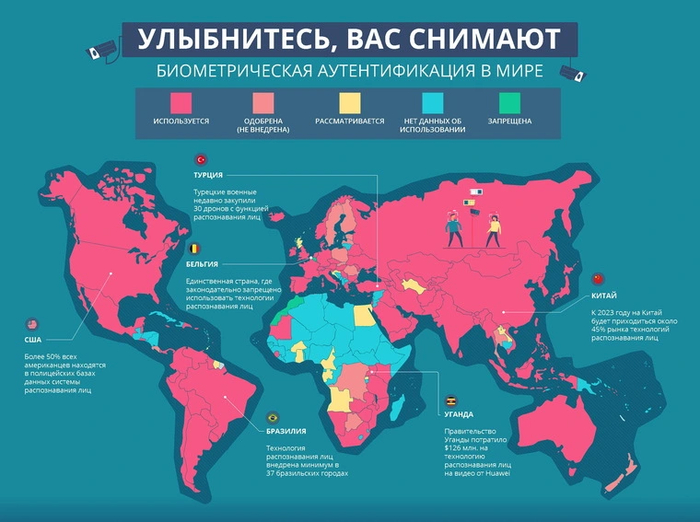
Технология распознавания лиц используется в самых разнообразных сферах, как правило, в той или иной мере связанных с обеспечением безопасности.
Первая и одна из самых больших областей — городские системы видеонаблюдения. Практически во всех крупных развитых странах уже используется или одобрена биометрическая идентификация. Городские камеры в режиме реального времени распознают сотни тысяч лиц, сравнивая результаты с огромными базами данных. Это позволяет оперативно разыскивать преступников и нелегальных мигрантов. Аналогичные системы стоят практически во всех аэропортах, а также многих вокзалах.
Например, в 2018 году во время чемпионата мира по футболу в городах России камеры видеонаблюдения были подключены к системе Find Face Security, благодаря чему удалось выявить и задержать более 150 преступников. Система работает больше чем на десяти стадионах страны. В Китае алгоритмы получают данные со 170 миллионов камер. Если преступник попадется на одну из них, то, например, в Пекине его арестуют уже через семь минут!
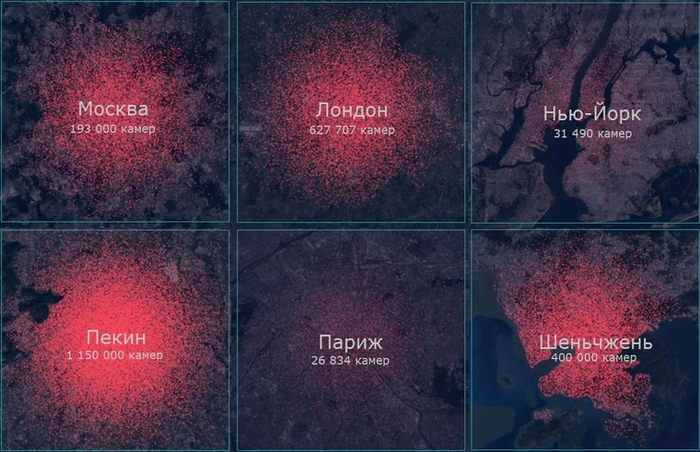
Однако число камер — не абсолютный показатель. Например, площадь Пекина составляет 16 410 км², а это около 70 камер на квадратный километр . Площадь Парижа — всего 105 км², здесь плотность камер намного выше — 255 штук на квадратный километр! При этом следует учитывать и места расположения — многие проулки все равно останутся в «слепой зоне».
Одной из самых современных является система распознавания лиц в Москве. Используемые алгоритмы способны обрабатывать около одного миллиарда изображений всего за 0,5 секунды. При этом используется одновременно сразу четыре разных алгоритма распознавания от компаний NtechLab, TevianFaceSDK, VisionLabsLuna Platform и Kipod.
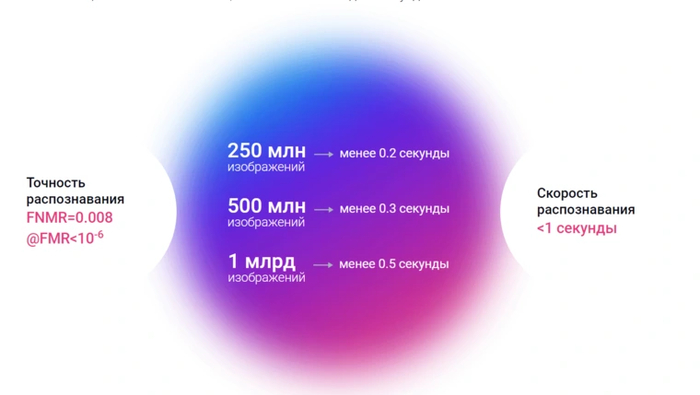
С 2018 года в России также начала работать ЕБС — единая биометрическая система, которая собирает «отпечатки» лиц и голоса пользователей. Благодаря этой разработке появилась возможность оформить какие-либо услуги в банках и других финансовых организациях без непосредственного посещения.
Второе по важности применение систем распознавания лиц — коммерческое. Сюда можно отнести:
Банковские услуги. Распознавание лиц позволяет не только идентифицировать мошенников и людей из черного списка, но и упрощает получение услуг. Например, в России уже проводились пилотные проекты по использованию банкоматов с идентификацией по лицу.
Системы контроля доступа. Обеспечить безопасность предприятия и даже офиса намного проще с развитой системой видеонаблюдения и распознаванием лиц. Это не только упрощает доступ, но и позволяет оперативно выявлять любых людей, которые несанкционированно проникли на территорию.
Сфера торговли. Интеллектуальные системы в магазинах могут предлагать вам, например, одежду подходящего размера, распознав вас по лицу. И это не говоря про быструю оплату по лицу.
Медицина. Продвинутые алгоритмы будут способны выявить отдельные эмоции, например, приступы эпилепсии или инсульты.
Мобильная техника. Идентификация по лицу уже стала таким же популярным методом авторизации, как и отпечаток пальца.

Конечно, в теории быстрое обнаружение опасных преступников всего по паре снимков лица — отличная перспектива. Вот только на практике этика применения технологии нередко может выходить за рамки.
Например, у ФБР есть достаточно большая база под названием Next Generation Identification (NGI) — к 2014 году в ней было уже около 100 миллионов фотографий. Вот только оказалось, что в базе содержатся не только фото преступников, но и людей, которые никогда не привлекались. Более того, используемые алгоритмы гарантировали точность всего в 80-85%. Можно не только забыть про анонимность в глобальном масштабе — ошибки системы вполне могут превратить вас в преступника, если вы на него похожи или просто попали неудачно в кадр камеры.

Другая проблема — усиленная слежка со стороны корпораций. У многих из них и так уже имеется исчерпывающий цифровой портрет, включая ваши фотографии, геолокации и отпечатки пальцев. Однако благодаря данным систем распознавания лиц такие корпорации смогут отслеживать ваши передвижения буквально по минутам. Получается, даже если вы никогда и нигде не выкладывали свои фотографии в социальных сетях и даже на смартфоне, ваше лицо все равно может попасть в чьи-то базы данных.
Немаловажен и тот факт, что по лицу вас могут найти не только государственные органы, но и в принципе любой человек. После же недоброжелателям не составит труда отыскать и другие данные — адрес, телефон и так далее. Все это может вылиться в различные виды мошенничества, угроз и не только.
Во многих странах уже подаются иски на корпорации и государственные структуры, но в крупных городах работа систем распознавания лиц будет неизбежной. Остается только надеяться, что их использование будет максимально правомерным. Впрочем, защититься все еще можно. Алгоритмы несовершенные, поэтому кепка, маска и даже очки могут внести существенные погрешности, из-за которых будет проблематично считать ваш «отпечаток лица»


ЦАП – цифро-аналоговый преобразователь – нужен для преобразования аудиосигнала из цифрого формата в аналоговый; обычно, для передачи в усилитель или немедленного озвучивания.
Все современные форматы записи аудио используют цифровое представление. И треки на CD или blu-ray дисках, и mp3-файлы, и музыка с iTunes – все они хранятся в цифровом формате. И для того, чтобы воспроизвести эту запись, её надо преобразовать в аналоговый сигнал – эту функцию и выполняет цифро-аналоговый преобразователь. Встроенный ЦАП присутствует в любом устройстве, воспроизводящем музыку. Но часто бывает, что качество проигрывания одних и тех же аудиофайлов (или треков с одного и того же диска) на разных плеерах заметно отличается. Если при этом используются одинаковые усилители и наушники, значит, проблема в ЦАП плеера.

ЦАПы бывают разные: дешевые преобразователи с низким энергопотреблением (часто используемые производителями в мобильных устройствах) имеют низкое быстродействие и малую разрядность, что сильно сказывается на качестве звука.

Если у мобильного устройства есть цифровой выход (S/PDIF или USB), можно подключить к нему внешний ЦАП - это гарантирует высокое качество преобразования цифрового звука в аналоговый.

Кроме того, внешний ЦАП может оказаться очень полезным при прослушивании музыки, записанной в loseless-форматах (форматах записи аудио без потерь качества) с высокой дискретизацией, обеспечивающей максимальное подобие записи и оригинала. Поскольку распространяются такие записи, в основном, через Интернет, часто их прослушивают прямо с компьютера. Но качественная звуковая карта редко встречается на ноутбуках и планшетах, да и встроенные в материнскую плату десктопного компьютера звуковые карты не отличаются высоким качеством. И в этом случае весь смысл прослушивания loseless музыки теряется абсолютно. Ситуацию можно исправить, если на компьютере есть цифровой аудиовыход, например, S/PDIF. Подключив к нему ЦАП с частотой дискретизации и разрядностью не меньшей, чем у прослушиваемой записи, можно получить аналоговый сигнал высокого качества.
Еще один приятный бонус можно получить, приобретя ЦАП с поддержкой Bluetooth. Это позволит слушать отличную музыку на подключенных к преобразователю динамиках, не будучи «привязанным» к нему проводами. Для мобильного компьютера (планшета или ноутбука) это может оказаться очень удобным. Кроме того, с таким преобразователем вы сможете проигрывать музыку с других устройств, поддерживающих Bluetooth и легко переключаться между ними.

АЦП – аналого-цифровой преобразователь – нужен, наоборот, для преобразования аналогового аудиосигнала в цифровой формат. АЦП будет незаменим при оцифровке (переводе в цифровой формат) старых аналоговых записей: на грампластинках, аудио и видеокассетах. Также АЦП потребуется при записи в цифровом виде «живого» звука с микрофона. Плееры с функцией записи и компьютерные звуковые карты имеют встроенный АЦП, но если вам важно качество оцифровки, лучше доверить эту задачу специализированному устройству.
Несмотря на совершенно противоположные задачи, АЦП и ЦАП обладают некоторыми общими характеристиками, оказывающими большое влияние на качество преобразования.
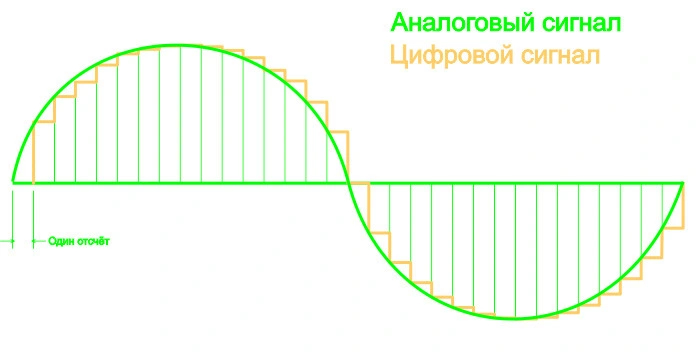
Количество отсчетов в секунду - частота дискретизации
Для АЦП частота дискретизации определяет, с какой частотой преобразователь будет измерять амплитуду аналогового сигнала и передавать её в цифровом виде. Для ЦАП – наоборот, с какой частотой цифровые данные будут конвертироваться в аналоговый сигнал.
Чем выше частота дискретизации, тем результат преобразования ближе к исходному сигналу. Казалось бы, чем выше этот показатель, тем лучше. Но, согласно теореме Котельникова, для передачи сигнала любой частоты достаточно частоты дискретизации, вдвое большей частоты самого сигнала. С учетом того, что самая высокая частота, различимая на слух – 20 кГц (у большинства людей верхняя граница слышимого звука вообще проходит в районе 15-18 кГц), частоты дискретизации в 40 кГц должно быть достаточно для качественной оцифровки любого звука. Частота дискретизации audio CD: 44.1 кГц, и максимальная частота дискретизации mp-3 файлов: 48 кГц, выбраны как раз исходя из этого критерия. Соответственно, ЦАП, проигрывающий аудиотреки и mp3-файлы, должен иметь частоту дискретизации не менее 48 кГц, иначе звук будет искажаться.
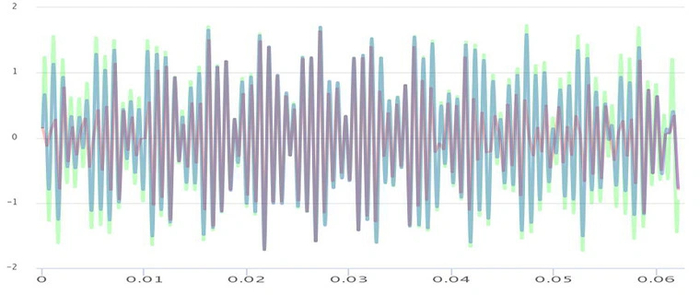
Зеленым цветом показан исходный аудиосигнал, состоящий из нескольких гармоник, близких к 20 кГц. Малиновым цветом обозначен цифровой сигнал, дискретизированный с частотой 44.1 кГц. Синим цветом обозначен аналоговый сигнал, восстановленный из цифрового. Хорошо заметны потери в начале и конце отрезка.
Теоретически, такой частоты дискретизации должно быть достаточно, но практически иногда возникает надобность в большей частоте: реальный аудиосигнал не полностью отвечает требованиям теоремы Котельникова и при определенных условиях сигнал может искажаться. Поэтому у ценителей чистого звука популярны записи с частотой дискретизации 96 кГц.
Частота дискретизации ЦАП выше, чем у исходного файла, на качество звука не влияет, поэтому приобретать ЦАП с частотой дискретизации выше 48 кГц имеет смысл, только если вы собираетесь прослушивать с его помощью blu-ray и DVD-аудио или loseless музыку с частотой дискретизации, большей 48 кГц.
Если вы твердо нацелились на приобретение преобразователя с частотой дискретизации выше 48 кГц, то экономить на покупке не стоит. ЦАП, как и любое другое аудиоустройство, добавляет в сигнал собственный шум. У недорогих моделей шумность может быть довольно высокой, а с учетом высокой частоты дискретизации, на выходе такого преобразователя может появиться опасный для динамиков ультразвуковой шум. Да и в слышимом диапазоне шумность может оказаться настолько высокой, что это затмит весь выигрыш от повышения частоты дискретизации.

Чем выше разрядность, тем выше точность измерения или восстановления амплитуды сигнала
Разрядность – вторая характеристика, непосредственно влияющая на качество преобразования.
Разрядность ЦАП должна соответствовать разрядности аудиофайла. Если разрядность ЦАП будет ниже, он, скорее всего, просто не сможет преобразовать этот файл.
Треки audio CD имеют разрядность 16 бит. Это подразумевает 65536 градаций амплитуды – в большинстве случаев этого достаточно. Но теоретически, в идеальных условиях, человеческое ухо способно обеспечить большее разрешение. И если о разнице между записями с дискретизацией 96 кГц и 48 кГц можно спорить, то отличить 16-битный звук от 24-битного при отсутствии фонового шума могут многие люди с хорошим слухом. Поэтому, если ЦАП предполагается использовать для прослушивания DVD и Blu-ray аудио, следует выбирать модель с разрядностью 24.
Чем выше разрядность АЦП, тем с большей точностью измеряется амплитуда звукового сигнала.
При выборе АЦП следует исходить из того, какие задачи с его помощью предполагается решать: для оцифровывания «шумных» аудиозаписей со старых магнитофонных лент высокая разрядность АЦП не нужна. Если же вы планируете получить качественную цифровую запись со студийного микрофона, имеет смысл воспользоваться 24-битным АЦП.
Количество каналов определяет, какой звук сможет преобразовывать устройство. Двухканальный преобразователь сможет обрабатывать стерео и моно звук. Но для преобразования сигнала формата Dolby Digital или Dolby TrueHD понадобится, соответственно, шести- или восьмиканальный преобразователь.
Соотношение сигнал/шум определяет уровень шума, добавляемого в сигнал преобразователем. Чем выше этот показатель, тем более чистым остается сигнал, проходящий через преобразователь. Для прослушивания музыки нежелательно, чтобы этот показатель был ниже 75 дБ. Hi-Fi аппаратура обеспечивает минимум 90 дБ, а высококачественные Hi-End устройства способны обеспечить отношение сигнал/шум в 110-120 дБ и выше.

ЦАП должен иметь цифровой вход – это может быть S/PDIF, USB или Bluetooth. Выходу ЦАП аналоговый - «джек» (jack) или «тюльпаны» (RCA). У АЦП все наоборот – аналоговый вход и цифровой выход. Хорошо, если преобразователь имеет несколько различных входов и выходов – это расширяет возможности по подключению к нему различных устройств. Если же вход на преобразователе один, убедитесь, что аналогичный выход есть на устройстве, к которому предполагается его подключать.
Преобразователи аудиосигнала скорее относятся к студийному и домашнему оборудованию, поэтому питание большинства преобразователей производится от сети 220В. Но существуют и преобразователи, которые питаются от аккумуляторов и могут быть использованы автономно. Это может оказаться удобным при использовании преобразователя с мобильным устройством – ноутбуком, планшетом, смартфоном или плеером.
Некоторые преобразователи получают питание через разъем micro-USB, при этом получать (или передавать) аудиосигнал через этот разъем они не могут. Если вам важно, чтобы ЦАП мог читать аудиофайлы на USB-носителях, перед покупкой убедитесь, что USB на устройстве используется не только для питания.

Если вам нужно устройство, с помощью которого можно будет оцифровать старые магнитофонные записи или записать на компьютер звук с микрофона, вам нужен аналогово-цифровой преобразователь. Цены на них начинаются от 1100 рублей.

Если вы желаете получить устройство для качественного проигрывания аудифайлов со смартфона с возможностью беспроводного соединения, выбирайте среди ЦАП с поддержкой Bluetooth. Такое устройство обойдется вам в 1400-1800 рублей.

Если же вы желаете услышать все богатство звука, записанного в loseless-формате с высокой частотой дискретизации и битностью 24, вам понадобится соответствующий ЦАП. Стоить он будет от 1700 рублей. Н и конечно не забываем что существуют и профессиональные линейки оборудования как аналогового так и цифрового но и цены там соответствующие. О них поговорим как ни будь в другой раз.

За последнее десятилетие распознавание голоса сделало огромный рывок. Гаджеты без особого труда понимают самые сложные фразы и предложения независимо от акцента и артикуляции. Как это им удается?
Попытки распознавания голосовых команд предпринимались еще с середины прошлого века. И уже тогда было ясно, что перед распознаванием запись голоса следует обработать. Одни люди говорят громче, другие — тише. Также в реальных условиях всегда есть посторонние шумы, не имеющие отношения к человеческой речи. И отдать запись на распознавание «как есть» — только запутать ситуацию и увеличить вероятность ошибок. В чем же состоит обработка звука?
Оцифровка
Звук — это волны. С микрофона он идет в виде аналогового сигнала, а компьютеры с аналоговыми данными работать не умеют. Звук надо оцифровать. Для этого используются АЦП — аналого-цифровые преобразователи. На выходе АЦП звук преобразовывается в цифровой массив. При частоте дискретизации 44 кГц одна секунда звука превращается в 44000 чисел.
Фильтрация
Фильтрация заключается в отсеивании всех частот, не относящихся к человеческому голосу. Это довольно узкий диапазон, лежащий в пределах 75–500 Гц. Слышимый человеком диапазон звуков намного шире — 20–20000 Гц. В таком (или близком) диапазоне выдают сигнал большинство микрофонов. Так что фильтрация позволяет отсеять 97,5 % ненужной информации. Это намного ускоряет дальнейшую обработку сигнала.
Фильтрация может производиться и до оцифровки — с помощью аналоговых фильтров. Но цифровой метод надежнее.
Нормализация
Нормализация нужна, чтобы устранить влияние громкости звука на результат. Слабый сигнал усиливается. Сильный, наоборот, ослабляется. Итоговый сигнал имеет примерно одинаковую амплитуду для всех записей звука — как громких, так и тихих.
До развития ИИ алгоритмы распознавания звука часто работали прямо со звуковым сигналом. Вот такого вида:
Для распознавания текста использовались различные методы математического анализа. Например, в базе данных сохранялись эталонные записи команд, и каждая новая запись сравнивалась с ними с помощью корреляционного анализа. Это позволяло легко найти среди эталонов наиболее подходящий и выполнить соответствующую команду. Способ хорошо работал с отдельными командами, представляющими собой неизменное слово или фразу. А вот с распознаванием обычной речи все было хуже.
Нейросети работают примерно так же, как и человеческий мозг. Они хорошо выявляют качественные признаки и не очень хорошо — количественные. Человек с первого взгляда отличит кошку от собаки, а вот кучку из 50 спичек от кучки из 49 — вряд ли даже с десятого. И вот здесь с распознаванием голоса на основе цифрового сигнала возникают сложности.
Вот три записи. Среди них — два слова «собака», произнесенные разными голосами и одно слово «забота».
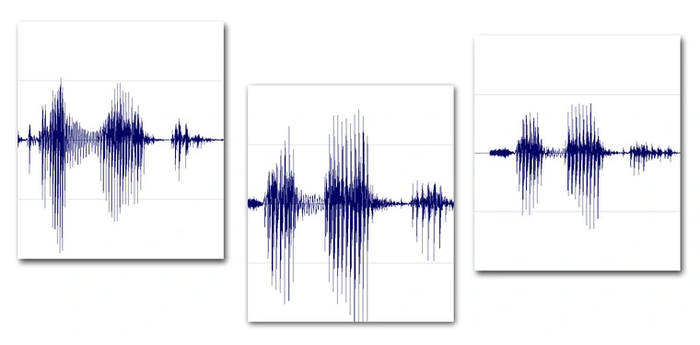
Задача выглядит несложной. Конечно же, второй и третий паттерны намного более похожи друг на друга, чем первый и второй или первый и третий. А значит — первый паттерн — «забота», а второй и третий — «собака»?
Нет. «Собака» — первый и третий. «Забота» — второй. Почему так? Потому что на записи мы в первую очередь обращаем внимание на амплитуды сигналов. Но это — всего лишь громкость. Смысловую нагрузку несет частота сигнала, а вот ее с первого взгляда на записи не видно. И со второго не видно. И вообще не видно до тех пор, пока вы не измерите расстояние между соседними пиками на графике.
Впрочем, решение этой задачи найдено давно — частотный анализ. Возьмем кусочек записи и посчитаем, с какой громкостью на нем звучит каждая частота. И изобразим это в виде графика.
Но такой график — все еще сложная для восприятия штука. А раз она сложна нам, то и нейросетям она тоже не понравится. Поэтому громкость изобразим в виде цвета. Теперь каждая запись предстает в таком виде:
«Собака»
«Собака»
«Забота»
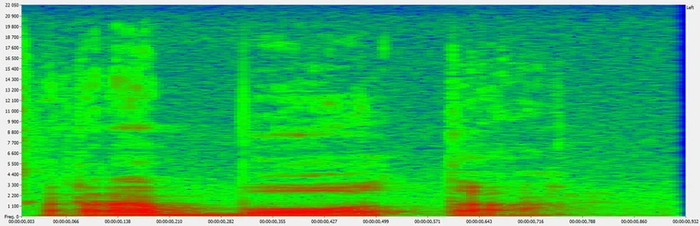
Не правда ли, все стало проще? Нейросетям — тоже. С этими картинками уже вполне можно использовать те же алгоритмы, что позволяют нейросетям обнаруживать на фотографии лица или разбираться в дорожной обстановке.
Более того, такое представление записи позволяет искать не слова, а отдельные фонемы. Фонемы — это элементы, из которых состоит человеческая речь. В разных языках они разные, но их немного. В русском языке, например, их 42 (по некоторым исследованиям больше — 46–48).
Фонемы — это не то же, что и буквы. В разных словах одним и тем же буквам могут соответствовать разные фонемы. Но, распознав все фонемы, уже можно легко собрать из них слово.
Итак, благодаря нейросети мы смогли преобразовать запись голоса в осмысленный текст. Но ведь голосовой помощник на этом не останавливается. Он как-то понимает этот текст и осмысленно на него отвечает. Как это делается? Во-первых, текст токенизируется. Из него выделяются отдельные токены — смысловые единицы. Токенами могут быть слова, их сочетания и целые фразы — это зависит от модели нейросети и ее целей. В голосовых помощниках это обычно слова и пунктуационные знаки. Дальше токены текста проходят через эмбеддинг — каждому токену сопоставляется некий смысловой вектор в N-мерном пространстве. Например, один из простейших методов эмбеддинга предполагает использование двумерного массива:

Так, после эмбеддинга токен «Корова» получит вектор [-,100,0,10,100]. Теперь, приняв набор токенов «Луг, Молоко», нейросеть предположит, что речь идет о корове.
Eще, сравнивая токен «Корова» с другими токенами своего словаря, нейросеть заметит сходство вектора только с одним вариантом — соответствующим токену «Птица». Мы понимаем, что это произошло потому, что птица — тоже животное, и она тоже может обитать на лугу. В данной простейшей модели нейросеть не знает таких терминов, как «животное» и «обитать». Но это не мешает прийти ей к тому же выводу, что и человек.
Очевидно, что эффективность нейросети очень сильно зависит от размеров словаря и от правильности заполнения соответствующей матрицы. Это делается с помощью методов машинного обучения на больших массивах реальных данных. Нейросеть просматривает различные тексты и заполняет словарь на основе встречающихся слов. Например, несколько раз встретив в одном предложении слова «Корова» и «Луг», она увеличит число, стоящее на пересечении соответствующих столбцов и строк.
Теперь, когда каждому слову сопоставлен какой-то смысл, нейросеть может определить, что хотел от нее пользователь. Для этого запрос пропускается через семантический теггер, который определяет семантическую функцию каждого токена. Например, при запросе «Кто на лугу?» нейросеть по токенам «Кто» и «?» поймет, что ей задали вопрос. А «луг» она определит как основную информацию запроса и, сопоставив вектор соответствующего токена с остальными, выдаст ответ: «Корова».
Но чтобы поддерживать разговор, умения отвечать на вопросы мало. Нужно оставаться в контексте беседы, и голосовым помощникам это удается. Для этого используются рекуррентные нейронные сети. Такие сети содержат рекуррентные слои, кроме обычных выходов имеющие дополнительный выход для следующего просчета.
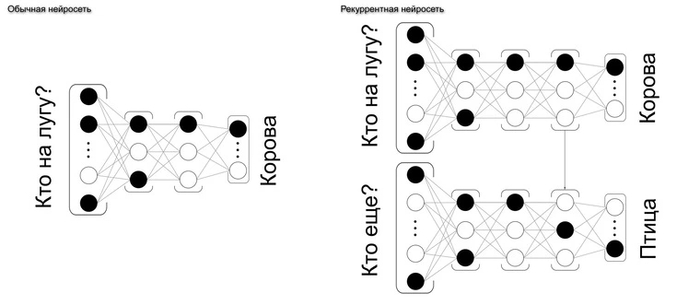
Голосовые помощники могут вести с нами полноценный разговор и выглядеть при этом вполне разумными собеседниками. Но это иллюзия. Нейросети способны выдавать грамотные, разумные и взвешенные ответы, совершенно не понимая сути вопроса. Весь секрет — в современных технологиях и в обширной базе знаний в виде книг и изображений, хранящихся в сети Интернет.
Обучение нейросети требует немалых вычислительных ресурсов, а под словари и базы данных нужны целые массивы накопителей. Поэтому большинство голосовых помощников «живет» на серверах в дата-центрах. Общение же с пользователями происходит через Интернет. Именно поэтому полный функционал умных колонок доступен только при их подключении к Интернету.
