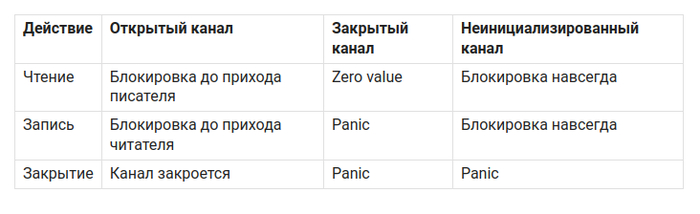
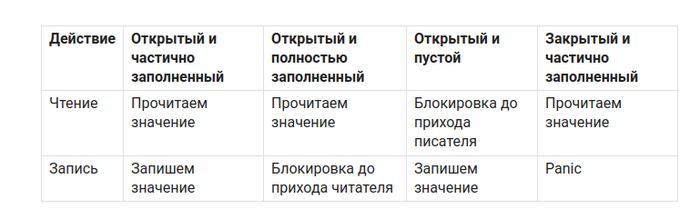
База
Параллельность - выполнение задач в один момент времени на разных логических ядрах.
Конкурентность - выполнение задач последовательно, но со сменой контекста на другую задачу в ожидание завершения иной задачи. У пользователя может возникнуть иллюзия многозадачности даже в однопроцессорной системе, поскольку смена контекста происходит быстро (микросекунды).
Раздельная память
Раздельные ресурсы
Раздельные регистры
Общая память
Общие ресурсы
Общий системный стэк
Общие регистры
Go runtime представляет модель P:M:G.
P - представляет логическое ядро процессора.
M - поток ОС по числу процессоров P.
G - структура, которая выполняет переданную функцию, создаётся по необходимости, минимум одна на старте программы (main). Стэк всего 2кб, может расширятся до 1гб для 64x и до 250кб для 32х систем.
Управление горутинами осуществляется планировщиком Go, а не ОС. Планировщик Go работает в пользовательском пространстве. Мы не можем напрямую управлять на каком процессоре будет исполняться горутина, за это отвечает планировщик.
Канал - очередь сообщений, которая умеет работать в многопоточной среде, работает по принципу FIFO.
Есть два типа каналов: буферизованный и небуферизованный.
Первый может хранить несколько сообщений, второй только одно.
Синхронизация
sync.WaitGroup - счётчик, который позволяет подождать завершения горутин.
sync.Mutex - блокирует доступ к ресурсу.
sync.RwMutex - разделяемая блокировка на чтение и запись. Читать могут несколько горутин, но мутировать данные только одна.
sync.Atomic - атомарная операция чтения и записи. Работает только с простыми значениями.
sync.Map - lock-free структура. Работает так же, как и обычная map, но потокобезопасная, можно использовать в многопоточной среде. Хорошо подходит для случаев, где надо много читать и мало писать. Если надо много писать, то лучше использовать обычную map и sync.RwMutex.
Небуферизованный канал
Буферизованный канал
Ограничения канала
Важные правила
Закрывает канал тот, кто в него пишет.
Если пишет несколько продюсеров, то закрывает тот, кто создал продюсеров.
Не закрытый канал держит ресурсы. Закрывать надо явно.
Паттерны
Микропаттерн, который наполняет канал. Закрываем канал, чтобы не было проблем.
func generator() <- chan int {
ch := make(chant int)
go func(){
for i := 0; i <= 12; i++ {
ch <- i + 1
}
close(ch)
}()
return ch
}
Оборачиваем функцию, добавляя функциональность. Если вам что-то говорит слово декоратор, то это тот самый паттерн.
func wrapper(wg *sync.WaitGroup, fn func()) {
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("Work before func")
fn()
time.Sleep(1 * time.Second)
fmt.Println("Work after func")
}()
}
func main() {
var wg sync.WaitGroup
wrapper(&wg, func() {
time.Sleep(1 * time.Second)
fmt.Println("heavy work")
})
wg.Wait()
}
Собирает результаты из нескольких каналов в один.
func fanIn(input1, input2 <-chan string) <-chan string {
ch := make(chan string)
go func(){
for {
select {
case s := <-input1: ch <- s
case s := <-input2: ch <- s
}
}
}()
return ch
}
Одна или несколько горутин пишут в канал, с другой стороны рабочие горутины читают канал, делают работу и умирают.
func worker(ch <-chan int, wg *sync.WaitGroup) {
wg.Done()
for v := range ch {
fmt.Println(v)
time.Sleep(1 * time.Second)
}
}
func sender() {
ch := make(chan int)
var wg sync.WaitGroup
for i := 0; i < 2; i++ {
wg.Add(1)
go worker(ch, &wg)
}
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
wg.Wait()
fmt.Println("done")
}
Данные обрабатываются цепочкой. Producer -> Producer/Consumer -> Consumer. Стадий обработки может быть сколько угодно.
func producer() <-chan int {
c := make(chan int)
go func() {
for i := 0; i <= 10; i++ {
c <- i + 1
}
close(c)
}()
return c
}
func producerConsumer(c <-chan int) <-chan int {
out := make(chan int)
go func() {
for v := range c {
out <- v * 2
}
close(out)
}()
return out
}
func consumer(ch <-chan int) {
for v := range ch {
fmt.Println(v)
}
}
Хотя для rate limiter есть множество разных алгоритмов, рассмотрим один, основанный на тиках.
func ticker() {
ch := make(chan int, 5)
go func() {
for i := 0; i < 5; i++ {
ch <- i
}
close(ch)
}()
limiter := time.Tick(time.Second)
for v := range ch {
<-limiter // будем ждать секунду
fmt.Println(v)
}
}
Способ прерывания горутин. Необходим, чтобы избегать висящих горутин, останавливать слишком долгие операции.
1. WithCancel
func worker(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("Done")
return
default:
fmt.Println("Working...")
time.Sleep(500 * time.Millisecond)
}
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
go worker(ctx)
time.Sleep(1 * time.Second) // работаем
cancel() // отменяем
time.Sleep(1 * time.Second) // время на завершение
}
2. WithTimeout
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second) // спустя 2 секунды воркер перестанет работать
3. WithDeadline. Можно указать точное время остановки.
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(2*time.Second)) // прибавляем к текущему времени две секунды
Каждый воркер берёт задачу, делает работу и отправляет результат в канал, другая горутина, в нашем случае main, читает результат из канала.
func worker(jobs <-chan int, results chan<- int, wg *sync.WaitGroup) {
defer wg.Done()
for j := range jobs {
time.Sleep(1 * time.Second)
fmt.Println("job", j)
results <- j * j
}
}
func main() {
jobs := make(chan int)
results := make(chan int)
var wg sync.WaitGroup
for i := 0; i < 3; i++ {
wg.Add(1)
go worker(jobs, results, &wg)
}
go func() {
for i := 0; i < 10; i++ {
jobs <- i
}
close(jobs)
}()
go func() {
wg.Wait()
close(results)
}()
for result := range results {
fmt.Println(result)
}
}
Паттерн, при котором акторы общаются только через каналы, и меняют данные только через каналы.
type message struct {
amount int
response chan int
}
func counter(messages chan message) {
for m := range messages {
m.response <- m.amount + 1
close(m.response)
}
}
func main() {
messages := make(chan message)
var wg sync.WaitGroup
go counter(messages)
wg.Add(3)
for i := 0; i < 3; i++ {
go func(i int) {
defer wg.Done()
response := make(chan int)
messages <- message{amount: i, response: response}
fmt.Println(<-response)
}(i)
}
wg.Wait()
close(messages)
}
Это не все паттерны, их целая куча, но уже с этими можно делать интересные вещи, такие как балансировщики нагрузки, pub/sub системы, очереди задач, rate limiter и много всего другого.