


Связный список насмешек

Показать полностью
1
Язык программирования C++ был создан в начале 1980-х годов Бьерном Страуструпом, который работал в компании Bell Laboratories. Он хотел расширить возможности языка C, добавив в него поддержку объектно-ориентированного и обобщённого программирования. Изначально язык назывался “C с классами” (C with Classes), но позже был переименован в C++ в 1983 году. Символ “++” означает операцию инкремента (увеличения на единицу) в языке C и символизирует развитие языка .

С тех пор язык C++ постоянно эволюционировал и стандартизировался. В 1998 году был выпущен первый международный стандарт ISO/IEC 14882:1998, который определял основные правила и синтаксис языка. В 2003 году был выпущен второй стандарт ISO/IEC 14882:2003, который исправлял некоторые ошибки и неоднозначности первого стандарта. В 2011 году был выпущен третий стандарт ISO/IEC 14882:2011, который добавлял много новых возможностей, таких как автоматический вывод типов, лямбда-выражения, перемещающий семантику, умные указатели и другие. В 2014 году был выпущен четвертый стандарт ISO/IEC 14882:2014, который улучшал некоторые аспекты третьего стандарта и добавлял новые библиотеки. В 2017 году был выпущен пятый стандарт ISO/IEC 14882:2017, который расширял возможности языка и библиотек, например, добавляя поддержку параллельного и распределенного программирования. В 2020 году был выпущен шестой стандарт ISO/IEC 14882:2020, который также вводил множество новшеств, таких как модули, кортежи, концепты, корутинны и другие .
Язык C++ оказал большое влияние на другие языки программирования, такие как Java, C#, Python и другие. Язык C++ широко используется для разработки различных видов программного обеспечения, такого как операционные системы, приложения для настольных и мобильных устройств, игры, серверы, встраиваемые системы и другие. Язык C++ отличается высокой производительностью, эффективным использованием ресурсов, гибкостью и мощностью.
Интересные факты и фичи языков программирования у нас в канале, заходи :)
Оптимизация кода в C++ - это процесс улучшения эффективности, скорости и качества кода, написанного на языке C++.

Оптимизация кода в C++ может быть выполнена на разных уровнях, таких как:
Оптимизация на уровне алгоритмов и структур данных. Это означает выбор наиболее подходящих и эффективных алгоритмов и структур данных для решения задачи, учитывая сложность, память, время и другие факторы. Например, использование сортировки слиянием вместо сортировки пузырьком, или использование хеш-таблицы вместо списка для поиска элементов.
Оптимизация на уровне языка. Это означает использование возможностей и особенностей языка C++, которые могут повысить производительность кода. Например, использование константных ссылок вместо копирования объектов при передаче аргументов функциям, использование шаблонов вместо дублирования кода для разных типов данных, использование лямбда-выражений вместо обычных функций для передачи поведения в качестве параметра.
Оптимизация на уровне компилятора. Это означает использование параметров компилятора, которые могут изменить способ генерации исполняемого кода компилятором. Например, использование параметра /O2 для включения оптимизации по скорости выполнения, использование параметра /Ob2 для включения раскрытия функций (inline expansion), использование параметра /GL для включения оптимизации по всему программному модулю.
Оптимизация кода в C++ требует знания того, какие части программы должны выполняться быстро, какой размер и скорость выполнения кода, какие затраты на реализацию новых возможностей, какой минимальный объем работы, необходимый для выполнения задания5 Оптимизация кода в C++ также требует тестирования и профилирования кода для измерения и анализа его характеристик работы, таких как время выполнения, потребление памяти, количество вызовов функций и других. Для этого можно использовать различные инструменты, такие как Visual Studio Debugger, Visual Studio Profiler, Intel VTune Amplifier и другие.
Интересные факты и фичи языков программирования у нас в канале, заходи :)
Массивы в C++ - это одна из основных структур данных, которая позволяет хранить и обрабатывать множество однотипных значений. Массивы в C++ имеют много интересных фактов и особенностей, которые могут быть полезны для изучения и практики.
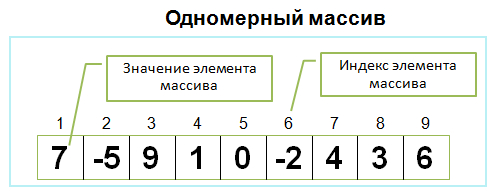
Массивы в C++ имеют фиксированный размер, который должен быть известен на этапе компиляции. Это означает, что нельзя динамически изменять размер массива или присваивать один массив другому. Для работы с динамическими массивами нужно использовать указатели и операторы new и delete, либо стандартные контейнеры, такие как std::vector или std::array.
Массивы в C++ являются непрерывными блоками памяти, в которых элементы расположены последовательно. Это позволяет быстро обращаться к элементам по индексу, но также ограничивает количество доступной памяти для массива. Кроме того, это означает, что имя массива является константным указателем на его первый элемент, поэтому можно использовать арифметику указателей для работы с массивами.
Массивы в C++ могут иметь несколько размерностей, то есть быть многомерными. Многомерные массивы представляют собой массивы массивов, которые могут использоваться для моделирования матриц, таблиц, сеток и других структур. Для объявления многомерного массива нужно указать количество элементов в каждой размерности в квадратных скобках.
Массивы в C++ поддерживают различные способы инициализации, которые позволяют задавать значения элементов при объявлении массива. Для этого можно использовать фигурные скобки и перечислить значения через запятую6. Например, int numbers5 = {1, 2, 3, 4, 5} - это одномерный массив из пяти целых чисел. Если количество значений меньше размера массива, то оставшиеся элементы будут заполнены нулями. Если количество значений больше размера массива, то компилятор выдаст ошибку. Также можно опустить размер массива и позволить компилятору вывести его из количества значений. Например, int numbers[] = {1, 2, 3} - это эквивалентно int numbers[3] = {1, 2, 3}.
Интересные факты и фичи языков программирования у нас в канале, заходи :)

Источник: https://vk.com/wall-119334888_69174
Взято из телеграмма - Инкогнито

В этой статье вместе с техническим экспертом Ауриги Владимиром Суворовым рассказываем о переносе программ на С++ из Windows в Linux. Эта тема включает в себя ряд особенностей, которые будут особенно актуальны для разработчиков, занимающихся портированием приложений. Мы рассмотрим основные различия между Windows и Linux в контексте работы с потоками, а также предоставим рекомендации по выбору библиотек в зависимости от задач проекта.
Поехали!

Для чего нужен перенос программ на Linux?
Миграция на Linux может быть необходима для обеспечения стабильности и непрерывной работы инфраструктуры компаний, особенно в ситуациях, когда становится сложнее продлить или приобрести новые лицензии и получить техническую поддержку от вендоров.
Типы многозадачности
Windows поддерживает два типа многозадачности: преемственную (preemptive multitasking) и кооперативную (cooperative multitasking). В преемственной многозадачности операционная система равномерно распределяет время процессора между потоками, переключая контексты выполнения. В кооперативной многозадачности каждый поток должен явно передавать управление другим потокам. Linux использует только преемственную многозадачность.
Процессы
В операционной системе Windows процессы более изолированы друг от друга благодаря использованию отдельных адресных пространств. При этом каждый поток имеет собственный стек и уровень приоритета выполнения. Кроме того, в Windows существует понятие «фибров», которые являются легковесными потоками и используют стеки других потоков.
В операционной системе Linux также обеспечивается изоляция процессов путем выделения каждому процессу своего собственного адресного пространства. Многопоточность в Linux реализована на уровне библиотеки, при этом ядро операционной системы предоставляет механизмы для управления потоками и распределения ресурсов. В Linux также существуют «процессы-потомки», которые создаются родительским процессом и имеют свои собственные адресные пространства. Это позволяет процессу-предку создавать и управлять отдельными процессами, которые могут выполнять свои задачи независимо друг от друга.

Кроссплатформенные библиотеки для работы с потоками
Как это работает: при переносе программы из Windows в Linux рекомендуется сначала выбрать подходящую кроссплатформенную библиотеку, перенести код на нее, а затем скомпилировать код для работы в Linux.
Ниже приведены примеры библиотек, которыми инженеры из Ауриги активно пользуются при портировании и миграции проектов. Они подходят для большинства задач, но у каждой из них мы указали наиболее распространенные.
1. C++ Standard Thread Library — это библиотека, предоставляемая стандартом языка C. Она предоставляет переносимый и удобный интерфейс для работы с потоками в C++. Хорошо интегрируется с другими компонентами языка, но имеет ограниченные возможности: не поддерживает некоторые специфические функциональности и требует хорошего понимания многопоточности для безопасного использования. Для более сложных сценариев могут потребоваться дополнительные библиотеки или фреймворки.
2. Intel Threading Building Blocks – кроссплатформенная библиотека для разработки приложений на C++, которая может использоваться для разработки приложений под различные операционные системы, в том числе Linux. Эта библиотека хорошо зарекомендовала себя при переносе PPL (Parallel Patterns Library) библиотеки, разработанной компанией Microsoft для работы с многопоточностью на C++.
3. Qt — это кроссплатформенный фреймворк для разработки приложений на C++, который также предоставляет классы для работы с потоками. В наших проектах мы часто используем библиотеку Qt для переноса функциональности, основанной на MFC (Microsoft Foundation Classes) — классах, предоставляемых Microsoft для разработки Windows-приложений.
4. SDL (Simple DirectMedia Layer) — это кроссплатформенная библиотека, разработанная для создания мультимедийных приложений на C++. SDL рекомендуется для работы с изображениями, звуком и вводом.
5. Boost C++ Libraries — это кроссплатформенная библиотека для разработки приложений на C++, которая поддерживает различные операционные системы, включая Linux. Boost рекомендуется использовать в случаях, когда требуется перенос приложений, использующих ATL (Active Template Library) — набор классов Microsoft для разработки Windows-приложений.
6. OpenMP (Open Multi-Processing) — это кроссплатформенная библиотека, позволяющая создавать многопоточные приложения с использованием директив препроцессора. Библиотека особенно полезна в ситуациях, когда требуется обработка большого объема данных параллельно.
7. Библиотека libuv предоставляет возможности для создания многопоточных приложений на C++. Она поддерживается на различных платформах, включая Linux, и предоставляет простой и удобный API для работы с потоками. Наши инженеры обнаружили, что libuv является наиболее удобным и эффективным средством для переноса кода, основанного на Windows Thread Pool API, на Linux или другие платформы.
В следующей статье расскажем о переносе программ на С++ из Windows в Linux в тех случаях, когда готового решения нет.
Больше статей о работе с потоками, а также на другие технические темы в официальном блоге Ауриги.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509









