Зарегистрировался на START.RU, чтобы воспользоваться пробным периодом и оценить контент. Планировал найти время для просмотра, но, к сожалению, из-за постоянной загруженности на работе так и не смог это сделать.
Однако, спустя некоторое время с меня списали 1189 рублей за платную подписку, хотя я ничего не использовал и не активировал подписку вручную.
Обратился в поддержку START.RU, но они ссылаются на пункт 4.9 и утверждают, что я не отменил подписку вовремя. Однако:
• Я не ставил галочку на автопродление;
• Я не пользовался сервисом;
• Планировал воспользоваться пробным периодом, но не успел.
Техподдержка отказывается делать возврат, ссылаясь на правила, и я написал жалобу в Роспотребнадзор.
Если не успеешь вовремя отменить пробную подписку, то готовься к списанию, даже если ничего не использовал.
Будьте аккуратны с пробными подписками. START.RU — в чёрный список.
Была у сети Магнит, под новый год, акция: - за определенную сумму в чеке давали такую скретч - карту. Вот, у меня завалялось несколько. Может, кому надо.
Каналы -помойки вроде «Фильмач», «Синемач», «Смотри кино» вредны
Даже что-то вроде «Лорда» в разы лучше рутубовско-газпромовых проституток.
Такие каналы как «Смотри кино», «Фильмач» и «Синемач» специально созданы, что бы уничтожить пиратские онлайн-кинотеатры, сайты, торрент-трекеры. Если вы уважаете свободный интернет то стоит обходить стороной таких волков в овечьих шкурах.
«Фильмач» на RUTUBE даже получил какую-то примию мол первый миллионник или что-то такое. Его 24/7 рекламят Двач, всякие глупые ботяры (в Вк, тг, пикабушные) и у него практически монополия на загрузку контента там.
Что можно сказать про «Фильмач» -
Хотя не совсем так, тк пираты благородны, а Фильмач просто что-то вроде ряженного под пирата госслужащего без чести.
Пишут про падения трафиков (пока достаточно незначительные) на пиратских порталах из-за вот таких полулегальных пиратах, которые не пираты, а просто инструмент для уничтожения храбрых разбойников))
Видел потешные статьи на эту тему. Вот фрагменты -
"Возможной причиной падения трафика поисковых запросов на пиратские порталы, анонсированного F.A. С.С.T., стали неожиданные конкуренты видеокорсаров — легальные видеохостинги, которые размещают у себя фильмы, ушедших из России мировых киномейджеров. Действительно, зачем бродить по интернету в поисках свежего блокбастера, если его можно посмотреть, например, на RuTube. На платформе, входящей в цифровые активы «Газпром-медиа», есть как минимум три канала с пиратскими киноновинками и миллионными просмотрами: «Смотри кино», «Фильмач» и «Синемач». В пиратских кинозалах на легальном хостинге можно «без СМС и регистрации» посмотреть и новый «Гладиатор 2» Ридли Скотта (премьера 5 ноября 2024 года), и сказку «Злая: Сказка о ведьме Запада» (релиз 18 ноября 2024 года), и романтический ужастик «Носферату» (прокат с 7 ноября 2024 года). Ни один из этих фильмов в российский легальный прокат не выходил.
Что касается именно поисковой выдачи, то «Яндекс» по запросу «Злая: Сказка о ведьме Запада» сразу же после первой ссылки на статью о фильме своего сервиса «Кинопоиск» и до «Википедии» дает ссылки на RuTube и «VK Видео». То же самое происходит и с другими блокбастерами. Более того, «Яндекс» дает смотреть пиратское кино, не выходя из поисковика. В этом случае видеоплеер «Яндекса» показывается контент, например, из «VK Видео» и, естественно, не забывает обложить его рекламой из «Яндекс Директа»."
Короче вот кто против пиратства и торрентов -
Только денежные обороты с пиратством дай бог 1% от нефтегазовых))
Еще немного мерзости -
"Какой уж тут пиратский трафик, когда с ним воюет флот из двух главных легальных видеохостингов страны при поддержке поисковика №1? В итоге складывается парадоксальная ситуация. В отсутствие в репертуаре лицензированных новых блокбастеров официальные онлайн-кинотеатры идут рекламироваться на пиратские видеоплощадки, которых из поиска вытесняют легальные видеохостинги с пиратским контентом. Не пора ли «Иви» и «Кинопоиску» запустить рекламу на RuTube? Так, кажется, будет проще." ( Надеюсь Кинопоиск и Иви пошлет помойный RuTube лесом навсегда)
Самое смешное, что если обычные пользователи загрузят фильмы на RuTube то с вероятностью выше 80% в течении месяца их удалят. RuTube поддерживает вышеперечисленных монополистов. Получается, что там пиратить могут только свои каналы)) На Ютубе хотя бы если загрузил и одобрили то фильм останется, а на нашем аналоге нет.
Пара баянов -
Для коммунистически настроенных ( баян с Пикабу))) -
Чем больше людей переходит на RuTube каналы ( Фильмач и сайт имеет с кинохами) тем сильнее они заместят независимых от толстосумов релизеров, а потом, когда вы расслабитесь удалят весь пиратский контент и подсадят вас на лицензию с конскими ценами.
Ну и хорошим проектам не вредит пиратство. Например топовые сериалы (Во все тяжкие, Игра престолов) наоборот набрали больше зрителей благодаря торрентам (это заявляли авторы и они не закрывали пиратские раздачи). Ну и куча примеров, когда человек скачал игру или музыку с торрентов, а потом купил лицензию для коллекции.
Уже в который раз запускаю фильм/сериал и вижу ужасные склейки. Понимаю, вырезали кусок. Гуглим продолжительность фильма, сравниваем с онлайн платформой - вырезано 10 минут. Ну еб Вашу мать, за что я плачу деньги? За зацензуренный продукт? Только зеленому магазину можно верить, а от онлайн кинотеатров, видимо, придется отказаться
Посмотрел сегодня четыре вышедшие серии сериала "Актёрище". На мой взгляд сериал середнячковый. Кстати, одна моя знакомая начала его смотреть чисто из-за Нагиева.
Если коротко это комедия, где супер популярного актёра обстоятельства заставляют играть в пьесе провинциального театра. В целом сериал интересно досмотреть до конца, но без фанатизма!
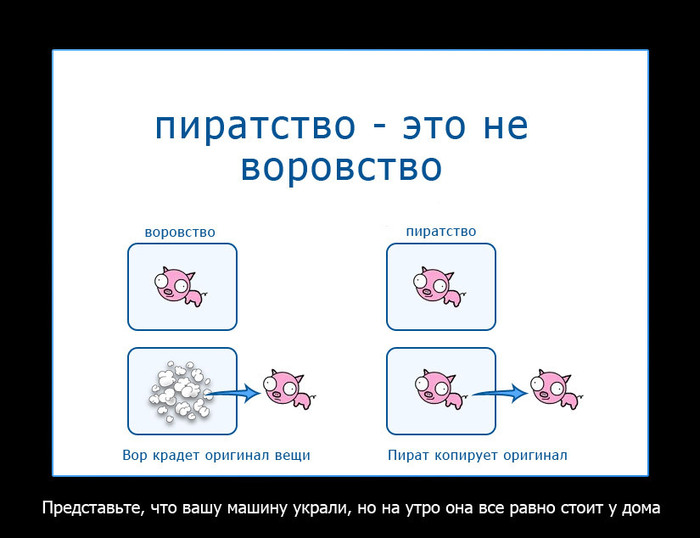
С каких это пор купленный билет или абонемент передаёт право собственности? Купив билет на киносеанс вы получаете лишь право просмотра, но никак не становитесь собственником фильма. Купив абонемент в бассейн, вы лишь можете его ограниченно использовать, но так же не становитесь его собственником. И это даже не гарантирует того, что вы воспользуетесь предоставленным правом в полном объёме. И в том и в другом случае, вам могут дать пинка под зад. Например, за неподобающее поведение. (Что там было недавно с волной фитнесов, где лишали абонементов, за то, что жене/подруге помогали тренироваться?)
Аналогично и всё купленное онлайн, что не возможно взять в руки - не является вашей собственностью. Это касается всей музыки, кино, игр и т.д. и т.п. Если вы не можете это забрать и/или разместить где-то у себя дома на полочке, в чулане - это не ваше.
Про продажу ноликов и единиц в интернете можно долго рассуждать, но действует только единственное правило - вы покупаете право пользования, а не право собственности. И, соответственно, у вас это право в любой момент могут отобрать. Или у того, кто вам это право предоставил могут так же отобрать право на предоставление доступа, а следовательно и у всех, кому он его передал. И да, имея право пользования, якобы купленного, вы не имеете право его никому передать, в том числе и по наследству.
Оооо вы реально существуете(я реально думал вы миф), люди которые покупают подписки на онлайн кинотеатры типа: кинопоиск, ivi и т.д. Блин видимо я олд скул, что плачу за пиратку 1000р в год.
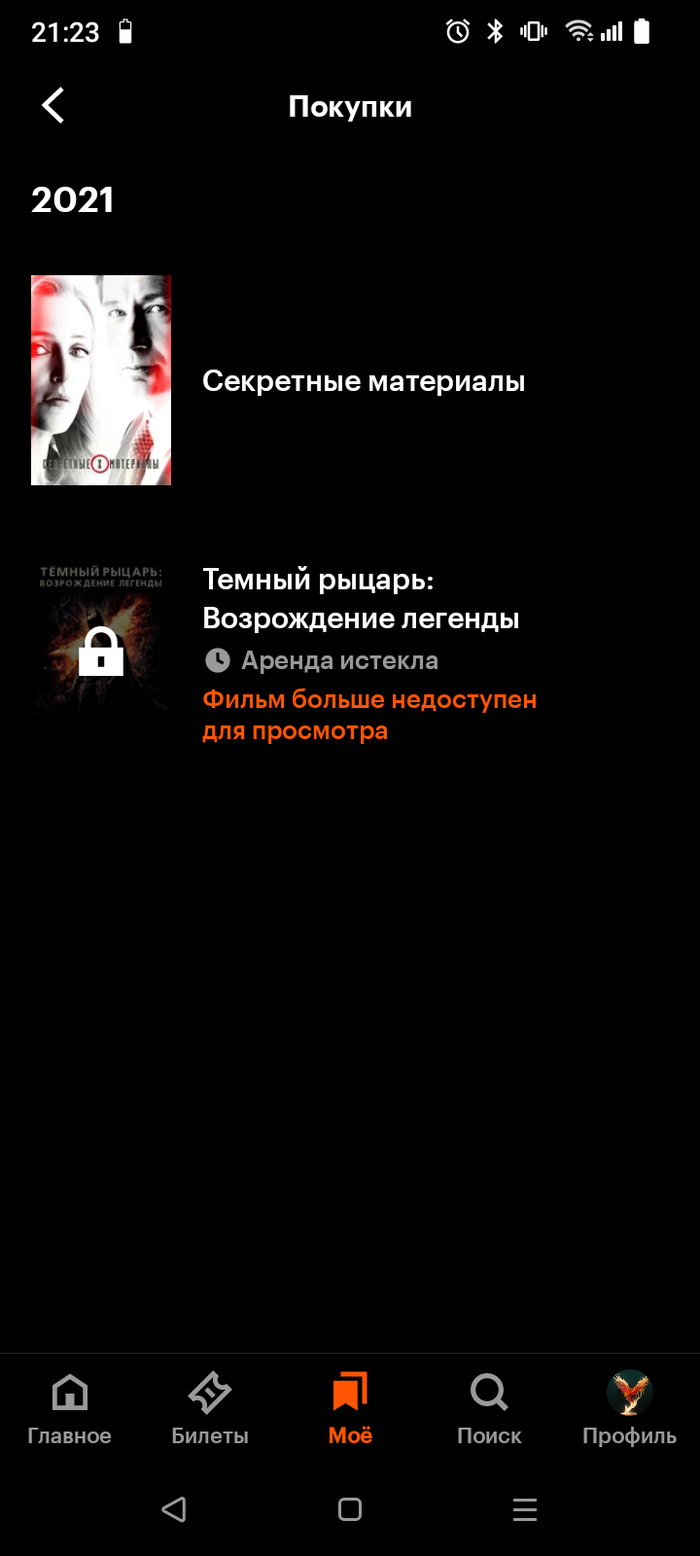
Оригинальный пост набрал 1300 плюсов, но имеет признаки наброса. Почему так думаю? Потому что у меня тоже есть покупки на Кинопоиске.
"Тёмный рыцарь: возрождение легенды" я, брал в аренду и, естественно, он сейчас недоступен.
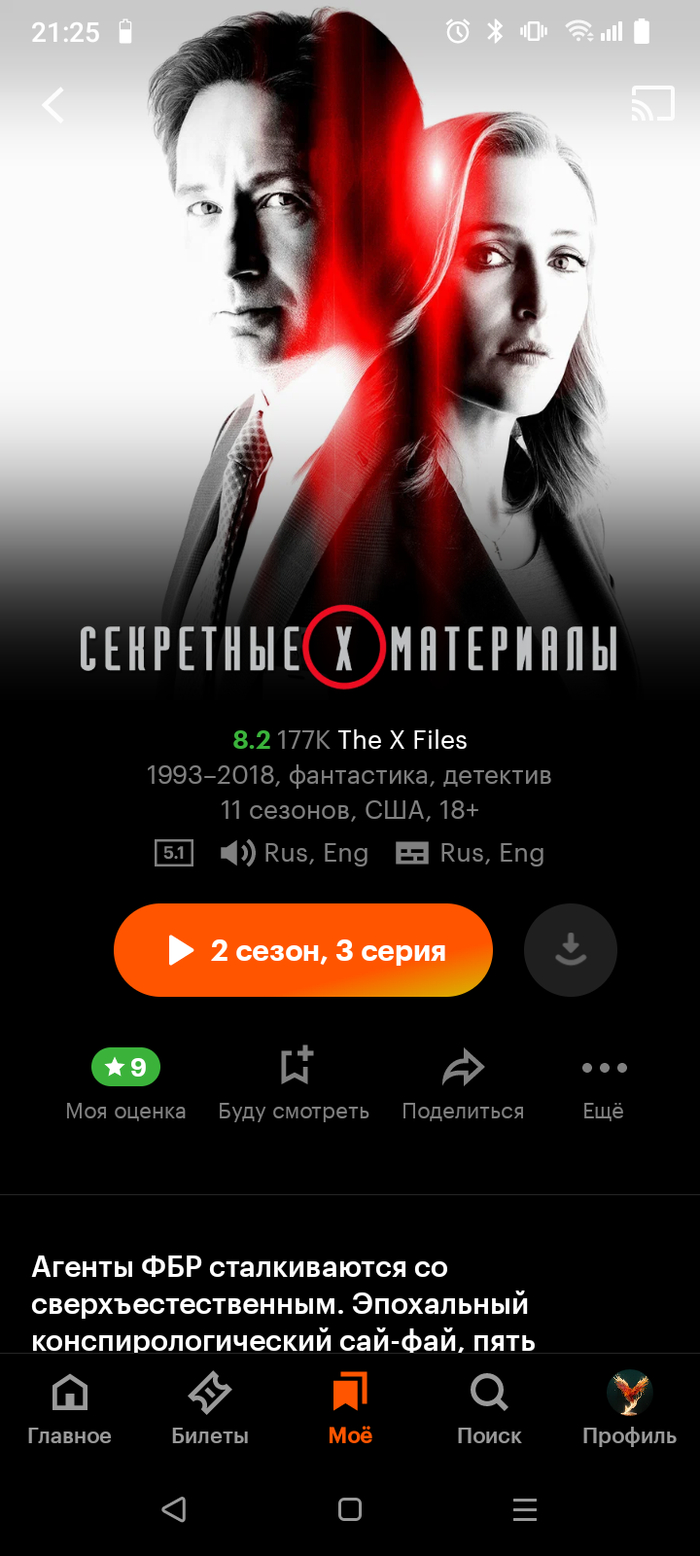
А вот "Секретные материалы" я могу смотреть до сих пор.
Кроме того, мне известно, что накануне истечения лицензии в прошлом году Яндекс продавал японские мультики за 1 руб. И.... Они доступны к просмотру на аккаунтах, с которых были покупки. В марте смотрел с другого аккаунта "Ходячий замок". Все отлично.
Так что или ТС просто заблуждается, или что-то недоговаривает.