Я считаю если и делать свое, то уже на открытой архитектуре. Лучший вариант на RISC -V, учитывая, что Байкал в основном для специальных задач, RISC -V процессоры можно модифицировать под любые нужды. К примеру для нейронных сетей можно добавить блок тензорный операций. RISC -V архитектура энергоэффективна и расширяема
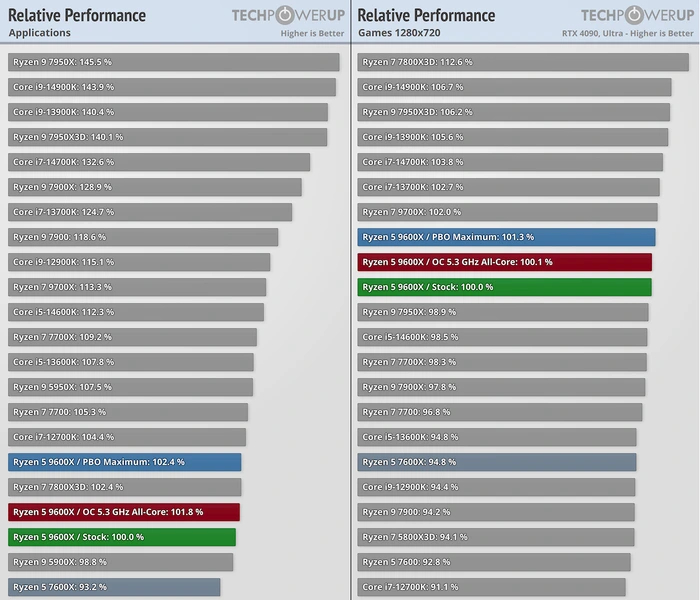
Российские процессоры «Байкал» оказались дороже Intel и AMD — и при этом уступают им в мощности. Одна из причин дороговизны российских процессоров - малый объем рынка.
Производство процессоров Baikal-M было начато на TSMC в 2019 году по топологии 28 Нм. Производство пришлось срочно переносить из-за международных санкций. Тайваньском TSMC отказался сотрудничать с россиянами по процессорам Baikal. Для сравнения, передовые процессоры AMD EPYC 9755 2024 года имеют технологический процесс 4 нм.
Производительность процессора Baikal-M можно сравнить с процессором Intel i3 седьмого поколения (выпущен в 2017 году), Baikal-L компаниями еще не тестировался.
«Байкал Электроникс» начал принимать заказы на процессоры Baikal-M и Baikal-L. Глава консорциума российских разработчиков систем хранения данных Изумрудов предполагает, что объем поставок Baikal-M и Baikal-L до конца 2025 года может составить несколько десятков тысяч штук.
Глава компании «Промобит» (бренд Bitblaze) Копосов дал комментарий о процессорах Baikal. В 2022 компания Bitblaze начала разработку ноутбука на процессоре Baikal-M.
Я не слышал о планах по возобновлению выпуска Baikal-M. В России нет площадок, которые могут произвести микросхемы такого уровня, поэтому, вероятно, процессоры производятся на одной из азиатских фабрик. перенос производства с одного завода на другой может стоить от 1 млрд руб. за один тип процессора, что сопоставимо со стоимостью разработки нового чипа.
Гендиректор «Байкал Электроникс» Евдокимов первоначально не стал комментировать начало производства процессоров и партнерства с российскими производителями вычислительной техники. Позже он дал комментарий СМИ.
C учетом недоступности из-за санкций TSMC, требуется поиск альтернативных производственных площадок. Поэтому на данный момент говорить о сроках выхода процессора не приходится.
Компания «Байкал Электроникс» планирует до конца 2025 года поставить российским заказчикам несколько десятков тысяч процессоров, а в 2026 году – 100 тысяч. Заказы от российских компаний уже есть. Baikal-M с 8 ядрами Cortex-A57 и графикой Mali-T628 на 28 нм техпроцессе выступает на уровне 2-ядерного i3-7100. Более новый Baikal-L имеет 4 ядра Cortex-A710, графику Mali-G52, производится по 12 нм и должен конкурировать с Core i5 10400T и Snapdragon 8cxG2. В любом случае «Байкалы» будут дороже иностранных конкурентов из-за мелкосерийного производства.
Экономический советник Белого дома Кевин Хассетт заявил, что 🇺🇸США не просто так разрешили Nvidia поставлять санкционные ИИ-чипы H20 в 🇨🇳Китай. Тут холодный расчет: «президент Трамп и его команда решили продолжить поставки чипов Nvidia, чтобы сохранить технологическое преимущество 🇺🇸Америки в области ИИ. Позволить 🇨🇳Китаю приобретать наши менее продвинутые чипы, оставляя у себя лучшие, я считаю мудрым решением». Хассет добавил, что «если Китай не покупает у нас чипы, значит, он разрабатывает и производит собственные чипы. И единственное, чего мы не хотим, – это чтобы они вырвались вперёд в гонке за чипы». Также известно, что 🇨🇳Китай получит Nvidia H20 в обмен на редкоземельные металлы.
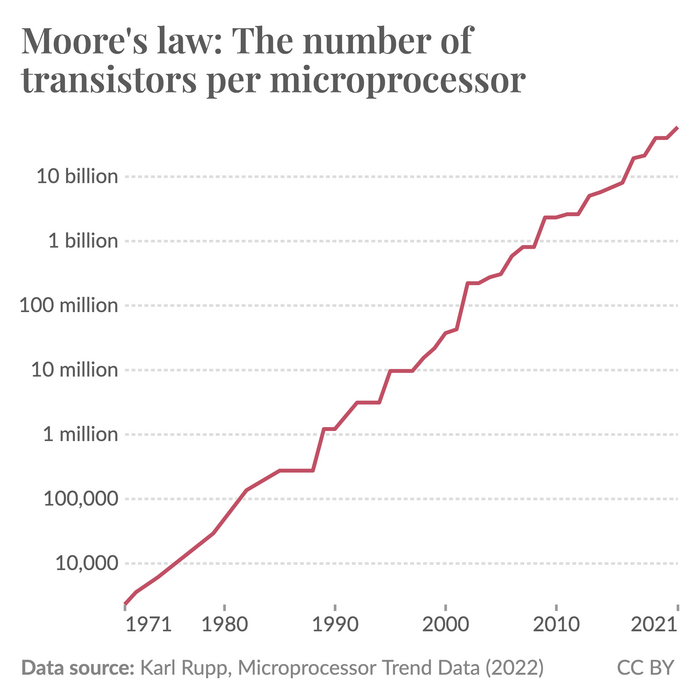
Закон Мура был сформулирован в 1965 году Гордоном Муром, одним из основателей компании Intel. Он обратил внимание на то, что число транзисторов в интегральных схемах увеличивается в два раза примерно каждые два года.
Эта закономерность наблюдалась на протяжении последних пяти десятилетий, и предсказания Мура оказались удивительно точными.
На графике, составленном исследователем Карлом Руппом, отображены данные о количестве транзисторов в микропроцессорах за последние 50 лет. Информация представлена в логарифмическом масштабе по вертикальной оси. Линия на графике идёт практически прямо, что свидетельствует о постоянном экспоненциальном росте.
В 1971 году среднее число транзисторов в микропроцессоре составляло 2308. К 2021 году этот показатель вырос до 58,2 миллиарда. Таким образом, средний период удвоения количества транзисторов составляет 2,03 года, что почти полностью соответствует закону Мура.
Рынок процессоров каждый год пополняется новыми моделями. Одни основаны на проверенных временем архитектурах. В основе других лежат совершенно новые разработки. К таким относятся чипы Arrow Lake, ставшие основой процессоров 15 поколения Core — Core Ultra 200.
Бренд Core от компании Intel — один из самых узнаваемых на компьютерном рынке. Процессоры на этой архитектуре появились еще в «нулевых», и с тех пор все время совершенствовались. Последнее крупное обновление продукты Intel получили в 2021 году. Тогда были представлены Core 12 поколения, получившие массу серьезных улучшений.
Core 13 и 14 поколения стали их логическим продолжением. Они отличались мелкими усовершенствованиями и наращиванием числа ядер. А недавно Intel выпустила 15 поколение — и это уже серьезный шаг вперед. Компания решилась на значительную переработку архитектуры Core. Рассмотрим ее ключевые изменения по порядку.
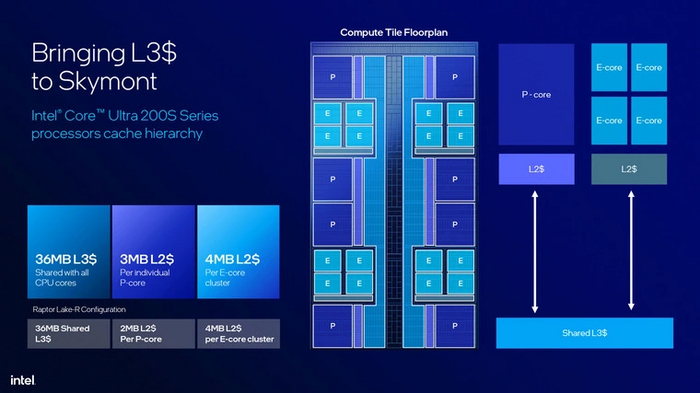
Внутреннее устройство Core Ultra 200
Современные центральные процессоры состоят из десятков миллиардов транзисторов. Производить такие чипы очень непросто. С 2019 года компания AMD нашла решение проблемы: она стала использовать чиплетный дизайн для десктопных ЦП. Процессоры стали делать из нескольких более мелких чипов, объединенных на одной подложке.
Десктопные процессоры Intel до сегодняшнего дня оставались монолитными чипами. Но теперь это изменилось — они тоже стали чиплетными. Притом устройство новых Core заметно сложнее, чем у конкурирующих Ryzen. У AMD все блоки вмещаются в вычислительные чиплеты и кристалл ввода-вывода. У Intel применяется более сложная компоновка Forevos 3D. В ней различных видов «плиток» шесть.
Вычислительная (Compute). Содержит в себе ядра процессора и их обвязку.
Графическая (GPU). В ней находится встроенное графическое ядро.
Система на чипе (SoC). В ее составе находится контроллер памяти DDR5, контроллер шины PCI-E, нейронный процессор (NPU), движки вывода и обработки видео.
Ввод-вывод (I/O). Микросхема, отвечающая за коммуникацию с внешними устройствами. Через нее из SoC выводятся линии PCI-E, порты Thunderbolt 4 и шина DMI0 (нужна для подключения к чипсету на материнской плате).
Наполнитель (Filler). Пустая плитка, служащая для придания прямоугольной формы итоговому кристаллу.
Базовая (Base). Располагается под остальными плитками и служит для их соединения. Такое решение вносит очень малые задержки в «общение» компонентов ЦП друг с другом. В отличие от процессоров Ryzen, чиплеты которых соединяются через подложку.
Каждую из плиток производят по собственному техпроцессу. Графическая производится по технологии 5 нм (TSMC N5P). I/O и SoC используют 6 нм (TSMC N6). А для процессорной используют наиболее современную 3 нм (TSMC N3B).
Вычислительная плитка
В состав вычислительного чипа вошли два новых вида ядер — производительные Lion Cove и энергоэффективные Skymont.
Архитектуру «больших» ядер Lion Cove заметно переработали. Декодер расширили с шести до восьми полос, а кэш микроопераций — c восьми до двенадцати. Исполнительных портов в целочисленной части теперь 14 вместо 12. Прибавилось по одному арифметико-логическому устройству (ALU) и блоку генерации адресов (AGU). Количество блоков хранения адресов (Store Data) осталось неизменным — их все так же два.
Блок вычислений с плавающей запятой (FPU) тоже расширили: теперь в нем четыре порта вместо трех. Два конвейера могут выполнять операции умножения, сложения и накопления (Multiply, Add, Accumulate — MAC). А еще два — только операции сложения (Add). А вот поддержки инструкций AVX-512 здесь нет. Кстати, они присутствовали в ядрах прошлого поколения — но вскоре после выхода были заблокированы.
Ядра Lion Cove отказались от поддержки технологии Hyper-Threading. Теперь они могут выполнять лишь один поток одновременно. Систему кэширования переработали. Теперь данные после вычислений на ядрах попадают сначала в L0D (бывший L1) размером 48 Кб, а затем — в 192 Кб кэша L1. Только после этого наступает очередь L2, объем которого вырос с двух до трех мегабайт.
Размер кэша инструкций (L0I) тоже увеличили. Перестановки в кэше были сделаны из-за заметной переработки ключевых элементов архитектуры. В их числе блоки выборки и декодирования. А также блок предсказания ветвлений, который стал в восемь раз шире.
Не менее сильно переработали и «малые» ядра Skymont. Они обзавелись тремя трехполосными декодерами (у их предшественников Gracemont таких декодеров было два).
Количество исполнительных портов увеличили с 12 до 18 штук. Теперь среди них целых восемь ALU — в два раза больше, чем ранее. Заметно подросло и количество AGU: с четырех до семи. Добавился и еще один порт для исполнения инструкции Jump. Как и в случае с большими ядрами, здесь усовершенствовали блок предсказаний ветвления. А заодно блоки выборки и декодирования.
FPU тоже стал «шире». Теперь в нем на один порт больше — шесть против пяти ранее. Новое место заняло еще одно ALU. Вычислительные конвейеры могут выполнять больше разных видов инструкций. Это было сделано для расширения поддержки и ускорения AVX2 VNNI — мультимедийных инструкций, необходимых для нейронных вычислений.
Четыре малых ядра объединены в один кластер с общим кэшем L2 объемом 4 Мб. Его объем остался прежним с прошлого поколения, но пропускная способность была удвоена. А вот общая компоновка ядер в чипе поменялась. Раньше производительные ядра располагались на одном конце кольцевой шины, а энергоэффективные — на другом. В новом поколении ЦП «большие» ядра чередуются с кластерами «малых».
Такое решение помогает снизить задержку при переключении потоков с одного вида ядер на другое. Заведует этим планировщик Thread Director третьего поколения. Он научился более точно и эффективно использовать аппаратные ресурсы разных ядер. Это стало доступным за счет расширенной системы обратной связи.
Графическая плитка
Новые процессоры обзавелись улучшенной «встройкой» Intel Graphics на базе архитектуры Xe-LPG. Теперь она относится к поколению Gen 12.7 — к нему же относятся и дискретные видеокарты Intel Arc. Главная «фишка» новинки — наличие блоков трассировки лучей. Они есть в каждом «кирпичике» ГП под названием ядро Xe.
В десктопных моделях таких ядер четыре. В каждом из них четыре растровых (ROP) и восемь текстурных (TMU) модулей, а также 128 шейдерных процессоров (SP). Вдобавок графическая плитка оснащена 4 Мб собственного кэша.
Всего у ГП 512 шейдерных блоков. Это вдвое больше, чем у прошлого поколения. Графика может работать на частотах вплоть до 2 ГГц – тут рост полуторакратный. Итог — более чем двукратный рост производительности. Это самый высокий показатель со времен Core пятого поколения. Но не обошлось и без некоторых упрощений. В ГП декстопных процессоров Arrow Lake-S отсутствуют блоки матричных вычислений XMX. Они нужны для ускорения работы нейросетей и фирменного сглаживания Intel XeSS. Подобные вычисления все равно могут выполняться, но с применением общих инструкций DP4a.
А вот в производительных мобильных чипах Arrow Lake-H используется другая графическая плитка. В ней и блоки XMX на месте, и ядер Xe вдвое больше — целых восемь. Удвоено и количество прочих блоков, в том числе SP: тут их 1024.
Система на чипе (SoС)
Часть графического процессора, отвечающую за вывод изображения, перенесли в плитку SoC. Здесь находятся Display Engine, Display I/O и Media Acceleration engine — новый движок кодирования/декодирования видео. Он поддерживает формат 8K с 10-битной глубиной цвета для кодеков AV1, VP9, HEVC и AVC.
ГП поддерживает современные разъемы HDMI 2.1 и DisplayPort 2.1. Они позволяют выводить изображение на панели Full HD или 2K с частотой до 360 Гц. Опционально доступен вывод HDR-изображения на одну панель 8К или сразу несколько экранов 4К. Но в этом случае частота обновления снизится до 60 Гц.
Но самый интересный компонент SoC — нейронный процессор (NPU) Intel третьего поколения. Он поддерживает вычисления в формате FP16 и INT8 (последние – в двойном темпе). Внутри скрываются два нейронных вычислительных движка (NCE). В совокупности они могут обеспечить производительность до 13 TOPS. NPU оснащен собственными кэшами и выделенным блоком памяти Scratchpad RAM (объем — 4 Мб).
Похожий нейронный процессор имелся в Meteor Lake — мобильных ЦП Core Ultra 100-й серии. В текущей серии мобильных Core Ultra 200V его заменил более производительный блок четвертого поколения. В пике он достигает целых 48 TOPS.
Но и такой NPU для десктопа – значительный шаг вперед. В конкурирующих Ryzen 9000 для реализации нейронного ускорения можно использовать лишь возможности FPU. Впрочем, для автономной работы Microsoft Copilot+ NPU в Arrow Lake не хватает: там требуется производительность от 40 TOPS.
В SoC также находится контроллер шины PCI-E и контроллер оперативной памяти. Последний лишился поддержки DDR4, сфокусировавшись на более современной памяти DDR5 и ее особенностях.
Раньше каждый из внутренних каналов DDR5 управлялся только одним контроллером памяти. Теперь в этом могут участвовать контроллеры обоих каналов. Такое решение нацелено на новые планки формата CUDIMM. С их помощью можно достигать частоты свыше 10000 МГц. При этом по умолчанию контроллер работает с гораздо более скромной DDR5-6400.
Плитка ввода-вывода
SoC осуществляет коммуникации с процессорной и графической плитками, а также с ОЗУ и слотом для дискретной графики. Остальные соединения с системой возложены на плитку ввода-вывода. Через нее выводятся линии PCI-E для накопителей и порты Thunderbolt 4. А еще шина DMI 4.0 x8, необходимая для соединения процессора с чипсетом на «материнке».
Заключение
Процессоры 15 поколения Core — техническая революция, которой не было в декстопных продуктах Intel много лет. Подготовка к ней началась еще в прошлом году, когда появились мобильные ЦП Meteor Lake. На них компания опробовала преимущества чиплетной компоновки Forevos 3D. Такое решение позволяет «собирать» кристалл из различных частей, словно конструктор. Это огромный задел для будущих поколений процессоров. Теперь можно дорабатывать и заменять отдельные плитки без необходимости перекраивать весь кристалл ЦП. Core 200 Ultra обзавелись куда более быстрой встроенной графикой и собственным NPU. Intel заявляет и об улучшенных возможностях контроля разгона. Хотя на практике они вряд ли дадут сильно поднять производительность. А вот новый контроллер памяти, разработанный с учетом высокочастотных CUDIMM, для тяжелых задач явно пригодится.
Главная цель нового поколения — не столько повышение производительности, сколько большая энергоэффективность. И это ему удалось. Arrow Lake потребляет заметно меньше энергии и остается куда более «холодным», чем его предшественники. Все это — при сравнимой производительности в большинстве задач.
Intel заявляет о немалом повышении IPC по сравнению с чипами Raptor Lake: для производительных ядер на 9%, а энергоэффективных — на целых 32%.
Однако некоторые задачи (в том числе игры) пока отдают предпочтение старым ядрам Intel. И лишь в рабочем окружении новые ядра оказываются немного быстрее прошлого поколения.
Почему ядра стали намного сложнее, но показывают большого прироста скорости? Причин несколько. Во-первых, современное ПО негативно реагирует на отсутствие многопоточности у «больших» ядер Lion Cove. Во-вторых, планировщик ОС Windows еще не полностью оптимизирован под особенности новых ЦП.
И, наконец, улучшения внутренних блоков процессора не всегда линейно влияют на производительность. На ум приходит аналогия с четвертым поколением Core (Haswell). На выходе его не ругал только ленивый — мол, прироста почти нет. Но уже через несколько лет Haswell по сравнению с предшественниками стал резко вырываться вперед. Как в играх, так и в рабочих программах.
Магия? Совсем нет. Просто с увеличением сложности кода вскрылись узкие места старой архитектуры, которых новая была лишена. Скорее всего, подобное ждет и 15-е поколение Core. Сейчас оно кажется неоднозначным, но через пару лет может заметно оторваться от предшественников. Учитывая оптимизацию программ под наиболее «свежие» процессоры Intel, шанс на это очень большой.
В 2017 году AMD выпустила процессоры на архитектуре Zen, которые впервые за долгое время вернули компании звание достойного конкурента Intel. С того момента прошло уже больше семи лет, и сегодня мы говорим уже о пятом поколении популярной архитектуры — Zen 5. Рассмотрим, какие улучшения она принесла с собой, и какого прироста производительности ждать от новых процессоров на ее базе. 3 июля 2024 года компания AMD представила новую линейку процессоров Ryzen 9000 для десктопных компьютеров, а также Ryzen AI 300 для ноутбуков. В их основу легла архитектура Zen 5, пришедшая на смену четвертому поколению Zen. Какие улучшения и изменения получили новинки? Много ли в них отличий от процессоров на прошлой версии архитектуры? Разбираем по порядку.
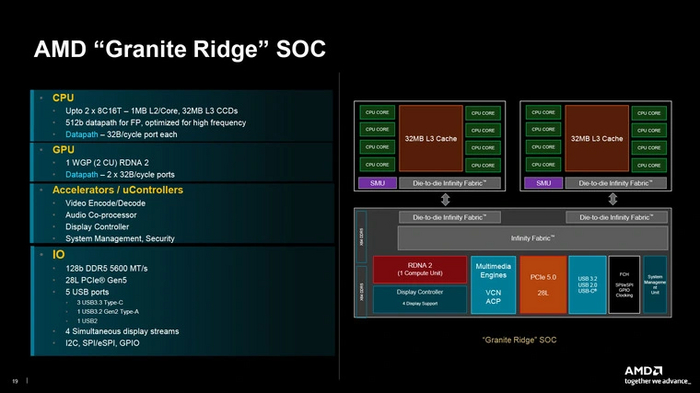
Внутреннее устройство Ryzen 9000
Ранее уже было рассказано про устройство платформы AMD AM5 и процессоров Ryzen 7000. В новых Ryzen 9000 чип ввода-вывода (IOD), производящийся по техпроцессу 6 нм, остался неизменным с прошлого поколения. Как и прежде, в его коммуникационные возможности входит 28 линий PCI-E 5.0: 16 — для графики, восемь — для двух NVMe-накопителей, и еще четыре — для связи с чипсетом на плате. Среди дополнительных соединений — четыре порта USB 3.2 Gen 2 10 Гбит/с, и еще один порт USB 2.0 для прошивки BIOS.
Никуда не делась и встроенная графика на базе архитектуры RDNA2 с двумя вычислительными блоками CU. Единственное изменение, относящееся к IOD, относится к режимам работы контроллера оперативной памяти. Для него были проведены оптимизации, расширяющие возможности работы в режиме делителя 1:2. К тому же, теперь по умолчанию поддерживается частота ОЗУ в 5600 МГц, тогда как в прошлом поколении она составляла 5200 МГц.
Процессоры обзавелись новыми вычислительными чиплетами (CCD). Как и прежде, в каждой модели их один или два. Внутри одного CCD находится шесть или восемь активных ядер. То есть, общее количество ядер по сравнению с прошлыми линейками Ryzen не возросло — их может быть 6, 8, 12 или 16.
Вычислительные чиплеты производятся по более тонкой технологии — 4 нм против 5 нм у предшественников. По заявлениям AMD, это позволило понизить энергопотребление на значение до 22%. Плотность транзисторов при этом увеличилась на 6%. Но главное в CCD не это, а новая архитектура вычислительных ядер — Zen 5.
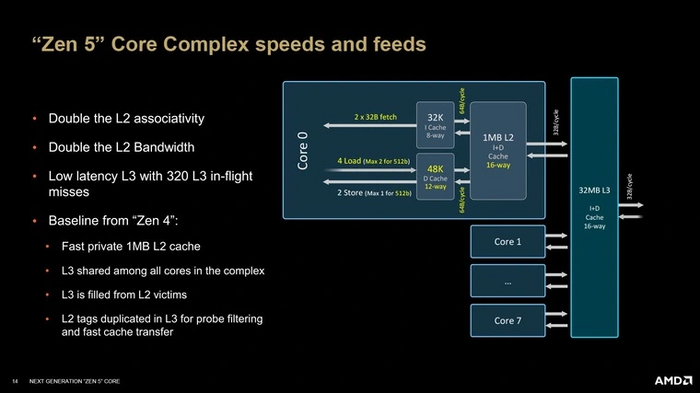
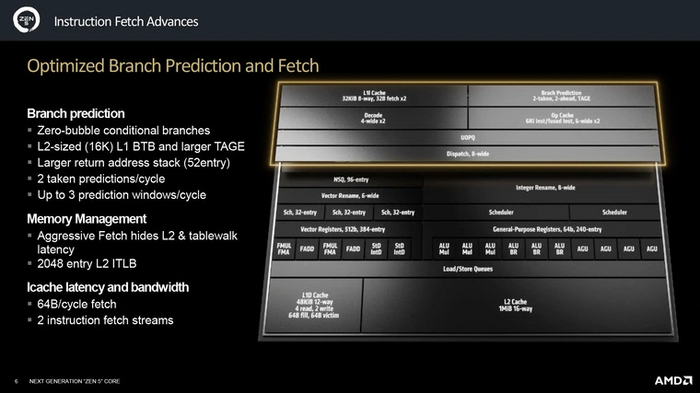
Системы выборки и кэширования
Самые заметные изменения получила подсистема выборки данных. В отличие от Intel, которая в 11 и 12 поколении Core расширила декодер сначала до пяти, а потом до шести полос, AMD пошла другим путем. В Zen 5 она впервые применила декодер с двумя четырехполосными конвейерами.
За счет такого решения появилась возможность заметно поднять эффективность предсказаний: заглянуть в предполагаемое будущее с двойными декодерами и предсказателями можно куда «глубже». Для этого эти блоки получили специальные оптимизации. В том числе новый механизм Zero-Bubble, предназначенный для минимизации потерь производительности при неверных предсказаниях.
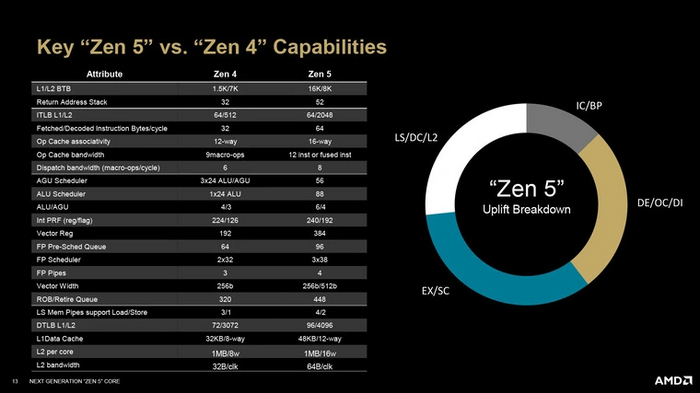
Для эффективной работы двойного декодера был значительно увеличен буфер целей ветвлений (BTB): с 1.5 до 16 Кб для первого уровня, с 7 до 8 Кб — для второго. Одновременно подрос буфер трансляции второго уровня (TLB) — с 512 до 2048 записей, а также стек адресов возврата — с 32 до 56 записей.
Кэш инструкций (L1I) составляют все те же 32 Кб, что и в прошлом поколении. Но теперь им могут пользоваться одновременно оба декодера, поэтому его скорость увеличили вдвое. Параллельно этому был усовершенствован кэш микроопераций (L0): его ассоциативность была увеличена с 12- до 16-канальной, а пропускная способность возросла на треть.
Не менее «прокачана» была и подсистема кэшей для данных. Кэш первого уровня (L1) был увеличен с 32 до 48 Кб, а его ассоциативность — с 8 каналов до 12. Кэш второго уровня остался прежнего размера, но его ассоциативность была увеличена вдвое — с 8 каналов до 16. Кратно ассоциативности возросла и пропускная способность обоих кэшей.
Кэш третьего уровня существенных изменений не претерпел: и размер, и ассоциативность остались такими же, как у Zen 4. Однако AMD поработала над его задержкой — теперь она немного меньше, чем поколением ранее.
Целочисленный конвейер
Усовершенствованная система выборки не будет иметь особого смысла без расширения целочисленного конвейера. Поэтому здесь AMD поступила схоже с Intel, и расширила конвейер с восьми исполнительных портов до десяти. Количество арифметико-логических устройств (ALU) в ядре было увеличено с четырех до шести. Теперь три из них умеют ускорять операции умножения (Multiply), а оставшиеся три — исполнять переходы (Branch). Для сравнения: в Zen 4 первой разновидности не было, а переходами могли заниматься только два блока, из которых лишь один совмещен с ALU.
Возросло и количество блоков генерации адресов (AGU) — с трех до четырех. Благодаря этому новое ядро производит на одну операцию загрузки/выгрузки в кэш больше, чем ранее. А блок переименования целочисленных регистров вместо шести операций за такт теперь умеет выполнять восемь.
Количество планировщиков было сокращено с четырех до двух. Но взамен они стали более чем в два раза производительнее. Вдобавок были расширены их возможности. Для ALU теперь поддерживается 88 записей, для AGU — 56. В Zen 4 они были куда скромнее: до 72 записей (3х24) для ALU вместе с AGU, плюс еще 24 записи только для ALU. Объем регистрового файла тоже вырос — с 224/126 до 240/192 записей, а буфер очереди — с 320 записей до 448.
Блок вычислений с плавающей запятой
Целочисленный конвейер получил немало новшеств. Но еще больше был усовершенствован блок вычислений с плавающей запятой (FPU).
Главное улучшение — новый единый блок 512-битных вычислений, тогда как в прошлом поколении такие вычисления выполняли два 256-битных блока. За счет этого инструкции AVX512 и VNNI выполняются заметно быстрее. И хотя отдельных ускорителей искусственного интеллекта в десктопных процессорах не появилось, новый FPU теперь подходит для них заметно лучше, чем решение прошлого поколения.
Как и у Zen 4, у FPU Zen 5 шесть исполнительных портов. Однако и они получили усовершенствования. Вычислительную часть представляют четыре конвейера, два из которых могут выполнять умножения, сложения и накопления (Multiply, Add, Accumulate — MAC), а еще два — только сложения (Add). Компанию им составляют два порта сдвига (Shift, ST). За один такт они могут произвести две 512-битные загрузки или одну такую же выгрузку данных в кэш-память. Количество планировщиков было увеличено с двух до трех, а блок переименования плавающих регистров научился выполнять шесть операций за такт вместо четырех. Объем регистрового файла возрос вдвое — со 192 до 384 записей.
Заключение
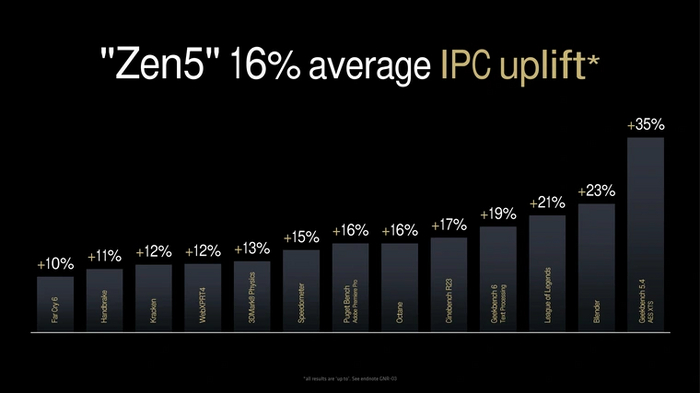
За счет совокупности всех улучшений, IPC новой архитектуры должен был вырасти достаточно заметно. По заявлениям компании AMD, преимущество Zen 5 достигает в среднем 16% по сравнению с Zen 4 при меньшем энергопотреблении.
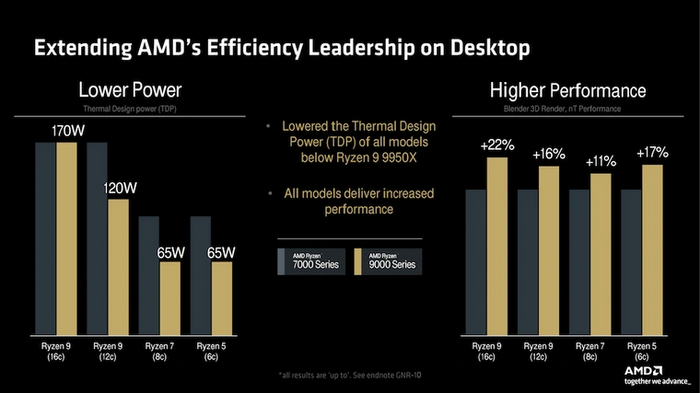
Первые тесты показывают, что новые процессоры действительно потребляют меньше. А вот рост производительности пока не всегда бывает таким высоким, как заявляет разработчик. Причина в том, что изменения в Zen 5 направлены не столько на увеличение производительности в уже имеющемся ПО, сколько на будущее. Хотя во многих играх они уже сейчас выступают заметно лучше своих предшественников.
Слабым местом архитектуры AMD Zen 4 по сравнению с конкурирующей Intel Golden Cove был четырехполосный декодер. У Zen 5 два таких декодера. Но это вовсе не означает, что новые ядра могут исполнять до восьми инструкций за такт. В некоторых случаях единственный шестиполосный декодер, как у Golden Cove, пока остается предпочтительнее. Ключевое слово — пока.
Если разработчики программного обеспечения подтянутся, и станут использовать особенности декодера Zen 5 и улучшения FPU, то у новой архитектуры есть шанс со временем заметно оторваться от предшественницы. Если же ПО будет продолжать создаваться с прицелом на Intel с его широким декодером и отсутствием спешки с AVX512, то высокий прирост в повседневных задачах новая архитектура по сравнению с Zen 4 вряд ли покажет.
Несмотря на малое потребление процессоров, в паре с ними использовались обычные чипсеты со встроенной графикой, что сводило на нет это преимущество — при процессоре с потреблением 2-3 Вт чипсет мог потреблять в 5-6 раз больше. В связи с этим было разработано второе поколение процессоров под названием Pineview, выпущенное в начале 2010 года. Его особенностью стали перенесенные внутрь чипа компоненты северного моста — встроенная графика и контроллер памяти. TDP новых чипов достиг 6.5 Вт, но он был куда ниже прошлой связки процессора и чипсета, потребляющей до 15-20 Вт.
Модели нового семейства N4x0 получили поддержку памяти DDR2-667. Двухъядерные модели серий D400 и D500 поддерживали память DDR2-800 и потребляли до 10 Вт. Они же стали первыми моделями в линейке с поддержкой 64-битных вычислений. Позже выпускаются усовершенствованные модели серии N4x5 и N500, обладающие одним и двумя ядрами соответственно. Их главным отличием от предшественников является поддержка памяти DDR3-667.
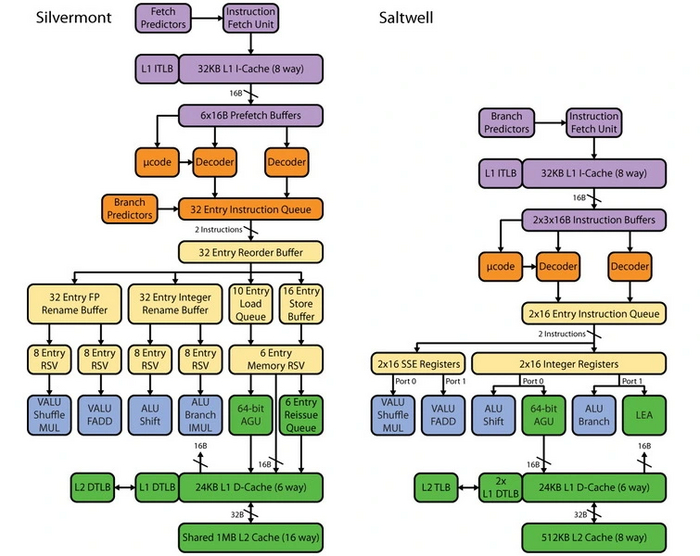
В 2011 году архитектура переносится на 32 нм техпроцесс и получает название Saltwell. Процессоры под кодовым названием Cedarview обзаводятся новым графическим ядром на базе PowerVR. Обновленный ассортимент содержит только двухъядерные модели. TDP снизился до 6.5 Вт. Улучшенный контроллер памяти получает поддержку более быстрого режима DDR3-1066.
Спустя два года Intel решает переработать Bonnell с целью повышения производительности и более высокого уровня интеграции чипов. Результатом становится архитектура Silvermont, главным улучшением которой стало возвращение поддержки внеочередного исполнения команд, позволившей добиться полуторакратного прироста производительности. Это потребовало усложнения вычислительного ядра, поэтому от технологии Hyper-Threading решено было отказаться.
Взамен процессоры обзавелись новыми инструкциями SSE 4.2, более производительной встроенной графикой поколения Ivy Bridge, а также двухканальным контроллером памяти DDR3L. Появилась и поддержка автоматического повышения частоты, по работе аналогичная технологии TurboBoost. Новые процессоры стали первыми системами на чипе компании — они не требовали внешних чипсетов для работы, все необходимое уже входило в состав кристалла ЦП. В соответствии с планами Intel, это расширяло сферу их применения: от мобильных телефонов до серверов, где не требуется высокая производительность на ядро.
Название Atom в этом поколении осталось только у смартфонных, планшетных, серверных и встраиваемых моделей. Процессоры для ноутбуков и десктопных компьютеров получили более привычные имена Celeron и Pentium, отличаясь между собой количеством ядер: два и четыре, соответственно. Процессоры вошли в семейство Bay Trail, поддерживают память частотой 1333 МГц и обладают пиковыми частотами до 2.66 ГГц. TDP составляет от 4 до 10 Вт.
В 2015 году второе поколение архитектуры Silvermont переносится на техпроцесс 14 нм и получает название Airmont. Ноутбучные и десктопные процессоры этого поколения входят в семейство Braswell. Основным улучшением является более производительная встроенная графика поколения Broadwell, а также снижение максимального энергопотребления до 6.5 Вт. Потолок тактовых частот процессоров остался неизменным, но стала поддерживаться более быстрая память DDR3L-1600.
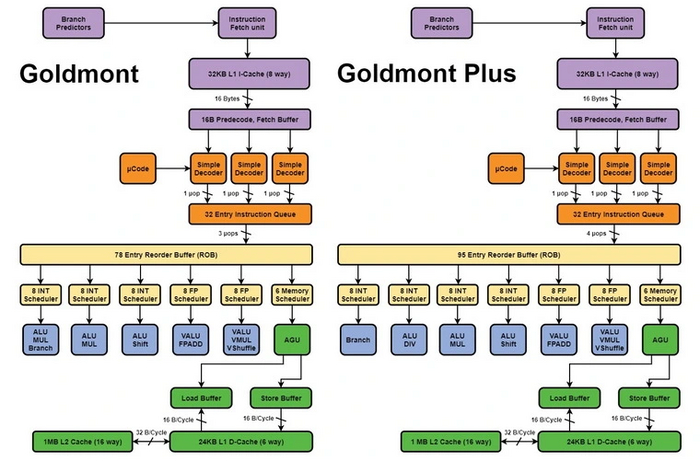
2016 год принес новое, третье поколение экономичной архитектуры — Goldmont, позаимствовавшей некоторые элементы дизайна Skylake. Процессоры получили возможность исполнения трех инструкций за такт. Был улучшен предсказатель переходов, а также увеличены буферы работы с инструкциями. Благодаря произведенным улучшениям производительность на такт возросла до полутора раз. Помимо этого, новые процессоры получили обновленную встроенную графику поколения Skylake и поддержку двух поколений оперативной памяти: DDR3L/LPDDR3-1866 и DDR4/LPDDR4-2400. Максимальный TDP составил 10 Вт.
Год спустя Intel представляет Goldmont Plus — улучшенную версию прошлой архитектуры. Ее главными новшествами стали усовершенствованный предсказатель переходов, восемь исполнительных портов против шести у предшественника, в очередной раз увеличенные буферы инструкций. Поддержку памяти DDR третьего поколения убрали, а максимальные частоты достигли 2.8 ГГц. В 2019 году линейка обновляется новыми моделями, достигающими в пике 3.2 ГГц.
В 2020 году Intel запускает следующее поколение архитектуры под названием Tremont, производимой по технологии 10 нм. Важным изменением является новый шестиполосный декодер инструкций, состоящий из двух половин. Количество исполнительных портов увеличено до десяти. Улучшения позволяют исполнять процессорам до четырех инструкций за такт. Кроме того, увеличены размеры кешей L1 и L2, а также добавлен кеш L3. Используется более производительная встроенная графика поколения Ice Lake. Поддерживается память DDR4 и LPDDR4X с частотой до 2933 МГц. Архитектура становится гораздо сложнее и все более приближенной к Core, чем прошлые Atom.
При организации ядер отныне используется модульная схема с кластерами по четыре ядра. В 2020 году, задолго до появления гибридных Alder Lake, Intel проводит эксперимент и сочетает один такой кластер с производительным ядром архитектуры Sunny Cove. Результатом становятся две модели мобильных процессоров i3 и i5, впервые содержащие пять ядер: одно производительное и четыре энергоэффективных. Прочие модели все также относятся к семействам Celeron и Pentium и не содержат производительных ядер.
Последним поколением «атомной» архитектуры является Gracemont, представленная в конце 2021 года. Увеличены размеры кешей, количество исполнительных портов возросло до 17, появилась поддержка инструкций AVX и AVX2. Новые ядра могут исполнять до пяти инструкций за такт, и по производительности близки к ядрам архитектуры Skylake.
В этой точке пути Core и Atom сходятся — как упоминалось ранее, процессоры двух последних поколений Alder Lake и Raptor Lake обладают ядрами, построенными на обеих архитектурах. Помимо роли малых ядер в упомянутых ЦП, на базе Gracemont выпускаются экономичные мобильные и встраиваемые процессоры Intel N-серии с количеством ядер от двух до восьми.