Вчера занимался написанием небольшого скрипта резервного копирования с помощью Алисы. В принципе, скрипт был готов, только надо было чуть изменить и, так сказать, полирнуть :) Скрипт полирнут, и тут в голову пришла немного странная идея спросить у ГигаЧата, придумает ли он ещё что-нибудь дельное, и увидит ли он какие-нибудь косяки и недоработки в алисовской работе (Алиса, первед! ты почему, когда занимаешься программированием под линукс, пишешь от своего имени в мужском роде?). Подсунул Алисину прогу ГигаЧату, он и правда сделал несколько довольно дельных замечаний, среди которых была рекомендация сделать проверку файла журнала на возможность записи:
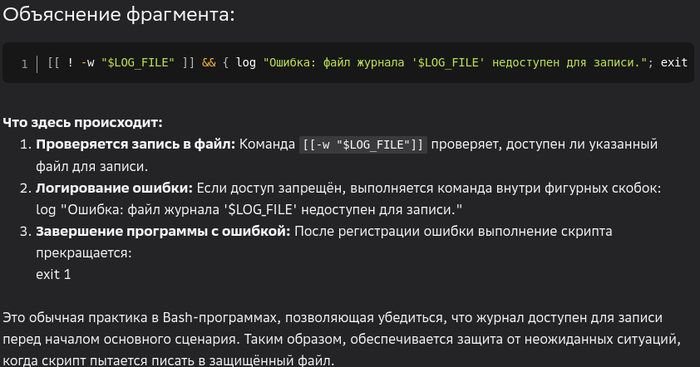
[[ ! -w "$LOG_FILE" ]] && { log "Ошибка: файл журнала '$LOG_FILE' недоступен для записи."; exit 1; }
При этом функция записи в журнал вот такая:
# Функция записи в журнал
log() {
echo "$(date '+%F %T'): $@" >> "$LOG_FILE"
}
Итак, что мы имеем? Делается резервное копирование, в процессе работы пишется журнал. Чтобы чего не вышло, предлагается проверить возможность записи в журнал и, если запись в журнал невозможна, сделать об этом запись в журнал и выйти с ошибочным статусом 1.
Всё нормально, если смысл работы программы даже не в том, чтобы писать журнал, а просто что-нибудь делать. Далее я около 20 минут пытался прояснить позицию ГигаЧата, почему он так поступает.
Ах, как чудесно!
Я попросил его подумать глубже.
Видимо, что-то случилось с пониманием целей и задач ГигаЧата, потому что вот это уже совсем безумные рассуждения:
Основная задача - делать резервную копию. Журнал в этом деле - вообще вещь опциональная. ГигаЧат же возводит вспомогательную функцию в разряд первостепенных. Нет возможности вести журнал - мы вообще работу делать не будем! В русском языке есть только один аналог этому - выплёскивать ребёнка вместе с водой, в которой его мыли.
Я попросил разобрать написанное как осмысленные действия в надежде на то, что ГигаЧат, может быть, поймёт всю бессмысленность происходящего:
Всё хорошо? [[ ! -w "$LOG_FILE" ]] && { log "Ошибка: файл журнала '$LOG_FILE' недоступен для записи."; exit 1; } разбери это на действия. Рассмотри смысл действий.
Нет, чуда не случилось, логику ГигаЧат "не умеет"!
Потратив минут 20, и не получив какого-либо понимания тупиковости ситуации, я начал терять терпение:
Ты тупой. Как ты запишешь в журнал сообщение о невозможности записи в журнал, если ты только что выяснил, что это невозможно?
Собственно, на этом можно поставить точку. "Восстание машин" если и будет, у ГигаЧата в нём не будет ровным счётом никакой роли!
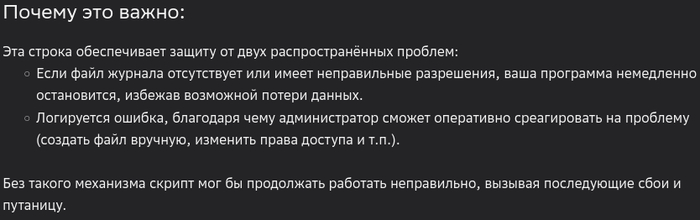
Так что, используя те или иные ИИ инструменты, мы должны отдавать себе отчёт в том, что у них есть лишь довольно узкая и специфичная область применения - "помнить" то, что человеку помнить сложно. Существует 100500 разных программ, у каждой из них десятки-сотни ключей и методов использования. В некоторых случаях у ИИ получается писать очень эффективные фрагменты взаимодействия с программами и данными, а иногда даже целые функциональные модули, но вот логика для машин пока слабо доступна.
Стрелочки вверх-вниз помогут найти в консоли команду, которая использовалась раньше. Это удобно для недавних команд, но не поможет со старыми.
Нажмите в linux-консоли ctrl+r и введите любую часть искомой команды. Будет предложен вариант команды из истории. Если он не подходит, нажмите ещё раз ctrl+r для поиска дальше в истории. Добавьте букв для уточнения поиска. Если пропустили нужную команду, итерируйтесь в обратную сторону с помощью ctrl+shift+r (но этот хоткей работает не везде, иногда надо настроить).
На скрине приведён пример поиска по параметру mig, по команде vim, по флагу cpu.
Обратите внимание, что курсор будет стоять на начале найденной подстроки. Прервать поиск можно с помощью ctrl-c. Когда нашли нужную команду, нажмите enter для выполнения, esc или стрелочку в сторону для модификации.
В комментариях к видео Идеальный скрипт на баш 2 мне сказали, что в bash в конструкции if надо использовать "<" вместо "-lt", который применял я. Давайте разберёмся, как вообще измерять время работы программы и что на это влияет. Вас ждёт фарш из кучи команд: htop, iotop, lscpu, time, xargs, yes, seq, sync, timeout и хтонический ужас однострочников на bash. Материал в видео, кому удобнее — ниже его текстовая версия.
Кроме ютуба, для удобства есть дзен / VK / rutube.
Сегодня разберём, как корректно измерять время выполнения программы и какие причины влияют производительность. Посмотрим, как можно загрузить систему и наглядно посмотреть на её состояние.
Сравним скорость -lt и < внутри if мы в следующем видео. Начать придётся издалека, через тернии к звёздам.
Что вообще важно для любого эксперимента? Описать методику эксперимента. Для измерения скорости обратите внимание на следующие нюансы:
0. На каком оборудовании мы работаем
1. Измерять секунды и десятки секунд, а не наносекунды
2. Фиксировать условия по загрузка ядер и видеокарты, оперативной памяти, вводу/выводу
3. И сколько измерений проводить и как усреднять, средняя или медиана, что делать с выбросами и подобное
Не будем вдаваться детали инструментов конкретных языков программирования, где можно измерять время выполнения конкретной функции. Не будем также говорить об очень малых замерах, где нужно учитывать непосредственно тики процессора. Будем измерять процессы, длящиеся секунды штатными средствами операционной системы Linux.
В начале про оборудование. Посмотрим на доступные ядра нашей системы с помощью команды lscpu. Видим 4 интелловых ядра i7-3770 с гипертредингом в 2 потока каждое, то есть 8 виртуальных ядер. Запомним - это наше оборудование
lscpu
... CPU(s): 8
Потоков на ядро: 2
Ядер на сокет: 4
Имя модели: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz
...
Для длительных временных промежутков достаточно встроенной в bash команды time:
type time
time — это ключевое слово командного процессора
Справка нас обманывает, потому что показывает информацию о бинарнике /usr/bin/time
man time
А это не то, что нужно. Это справка по такой команде:
Мне такой вывод непривычен, поэтому вернёмся к встроенному time:
time sleep 1
real 0m1,002s — общее время работы программы
user 0m0,002s — время в пользовательском режиме
sys 0m0,000s — время в режиме ядра или системных вызовов
До эры искуственного интеллекта в виде ChatGPT был популярен stackoverflow, детали смотрите там. Важно обратить внимание, что real — это про общее время работы, а user и sys — время процессорное. Для них 10 будет означать, что программа работала 10 ядросекунд — при этом неважно, 10 секунд на 1 ядро или 1 секунда на 10 ядрах
Для примера попробуем посчитать уникальные строки в большом файлике на 130 мегабайт и 14 млн уникальных строк.
time sort -u rockyou.txt | wc -l
14341564
real 0m34,771s
user 1m7,906s
sys 0m0,931s
Вот тут наглядно видно, что real — это совсем не сумма user и sys. Кстати, вам интересно, как можно изящно ускорить подсчёт уникальных строк за счёт магии баша? Их есть у меня! Лайкните этот пост, и я сниму отдельный ролик про всякие хаки и оптимизации на этом поприще.
Про встроенную команду time мы можем найти в справке по самому bash
man bash
Ищем там с помощью ввода /time (слеш, потом time), дальше сильно промотав вниз с помощью кнопки n (сокращение от next, следующий поиск). Тут и описание вывода, и переменная окружения TIMEFORMAT, с помощью которой можно настроить вывод time.
Больше о переменных окружения в нашем бесплатном курсе на степике под названием Командная строка для разработчиков – cli-for-dev.
Проще, конечно, загуглить нужное, кому нужна эта справка. Для вывода только real нам понадобится такая конструкция
TIMEFORMAT="%R"; time sleep 1
Запомнили, это пригодится позднее. Дальше о фиксированных условиях.
С этим пунктом мы надолго. Теперь посмотрим на загрузку системы и как она влияет на время работы команды. Мне нравится команда htop за наглядность. Тут показывается загрузка каждого ядра в режиме реального времени и многое другое. Строку load average мы с вами разбирали в видео про атаку forkbomb в docker-контейнере. Посмотрите, если пропустили.
Пример работы htop
Загрузим вычислитель. Нам нужно взять "тяжёлую" для процессора команду и запустить её, загрузив все логические ядра системы. Согласно философии Unix, программа должна решать одну задачу и решать её хорошо. Команда xargs умеет параллелить. Она берёт входную строку и преобразует её в одну или несколько команд. Для наглядности покажу, как xargs работает в связке с echo:
echo 123 | xargs echo my arg is
Если аргументов несколько, по умолчанию они все пойдут указанной команде:
echo 1 2 3 | xargs echo my arg is
С помощью флага -n можно настроить, сколько аргументов пойдёт в одну команду. Если указать один, то наши три числа превратятся в три разные команды:
echo 1 2 3 | xargs -n1 echo my arg is
Если указать два, то первые два аргумента пойдут в первую команду, оставшийся третий аргумент пойдёт во вторую:
echo 1 2 3 | xargs -n2 echo my arg is
Вернёмся к одному аргументу на команду. И теперь магия - укажем, что надо запускаться параллельно на всех ядрах с помощью P0
echo 1 2 3 | xargs -P0 -n1 echo my arg is
Блеск. Дело за малым - нам надо загрузить всю систему. В моем случае, как мы выяснили в lscpu, надо 8 потоков. Воспользуемся командой seq, сокращение от sequence
seq 8
seq 8 | xargs -P0 -n1 echo hello process
Чудо. Мы умеем параллельно запускать 8 команд. Теперь надо сделать так, чтобы эти команды сурово грузили процессор. Можно использовать сторонние тулзы нагрузочного тестирования типа stress, но зачем?
Пойдём рабоче-крестьянским путём
Есть команда yes, которая умеет адски спамить. По умолчанию она спамит буквой y, то есть всегда говорит да, прямо как Джим Керри в комедии 2008 года:
yes
Может спамить любой строкой:
yes hello world
Прикол в том, что этот спам сильно грузить процессор, что нам и нужно. Направляем вывод команды yes в чёрную дыру dev null:
yes > /dev/null
После чего смотрим в htop на загрузку. И получаем отличную жужалку, которая нагружает ядро. Но только одно. Постойте, мы же умеем параллелить!
seq 8 | xargs -P0 -n1 yes > /dev/null
Всё хорошо, но эта команда работает, пока мы её не прервём. А нам бы добавить немного удобства. Пусть система загрузится на 10 секунд. Линукс и так умеет. Команда timeout прервёт запущенную команду, если она сама не завершиться за указанное время, в моём примере 1 секунду:
timeout 1 yes
И мы ещё time можем сюда навесить. Измерим время команды yes, которую прервёт по таймауту:
time timeout 1 yes
Я вас ещё не совсем замучил? Теперь объединим всё это безобразие. На 10 секунд загрузим 8 ядер системы собранной нами на коленке жужжалкой:
Теперь у нас готова жужжалка для загрузки ядра процессора. С загрузкой других компонент системы разобраться проще. Для загрузки оперативной памяти достаточно создать огромную переменную:
a=$(seq 10)
echo $a
a=$(seq 100 000 000)
Но совершенно неудобно оценивать размер. Поэтому воспользуемся питоном. Незатейливо создадим большую строку, благо звёздочка удобно переопределена для строк. Один английский символ занимает один байт плюс накладные расходы на переменную, берём их "кило", то есть 1024 и получим килобайт.
python3.10
var = "a"*10
В IDLE можно не писать print, результат работы команды выводится на экран:
var
Кстати, в питоне накладные расходы на переменную довольно велики. В случае строки это 49 байт:
import sys
var = ""
sys.getsizeof(var) # 49
var = "a"
sys.getsizeof(var) # 50
var = "a" * 100
sys.getsizeof(var) # 149
Возведём 1024 в степень. Вторая степень даст мегабайт, третья - гигабайт. То есть такая переменная займёт в памяти около гигабайта, плюс 49 байт на служебную информацию.
var = "a"*1024**3
У нас свободно около 5 гигабайт, займём их все. Пока не удалим эту переменную или не завершим интерпретатор питона, память будет загружена.
var = "a"*5*1024**3
Для просмотра загруженности подсистемы ввода-вывода есть команда iotop, которой требуются права суперпользователя. Нам нужны только первые две строки
sudo iotop
Для загрузки ввода-вывода возьмём псевдогенератор случайных чисел и будем записывать его в файл:
cat /dev/urandom > /tmp/1
Зачастую проблема не в самом вводе-выводе, а в его буферизации. Так называется отложенная запись на диск. Операционная система для более эффективной работы с оборудованием пишет не сразу. Например, после записи файла на флешку на самом деле он там окажется не сразу, а через некоторое время. Для этого существует (или существовало? кто видел флешку в 2024 году?) безопасное извлечение флешки – как раз, чтобы операционка корректно дописала отложенный буфер.
В линуксе есть команда sync, которая завершиться, когда весь буфер запишется на диск.
sync
Пробовать измерять время будем на примере цикла в баше:
i=0; while [[ $i -lt 10 ]]; do i=$(( $i+1 )); echo $i ; done; echo $i
Увеличим число нулей:
i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )); done; echo $i
Добавим time. Если просто добавить time, то мы измерим время только присваивания:
time i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i
Чтобы измерить время всей конструкции, оформим цикл в виде отдельного процесса с помощью доллара и скобок:
time $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Ещё ошибка: результат подпроцесса - число, а команда time пытается это число выполнить как команду. Добавим echo:
time echo $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Теперь посмотрим, как на этот цикл влияет загрузку системы. Запустим монитор ресурсов htop и загрузим ядро:
seq 8 | xargs -P0 -n1 timeout 10 yes > /dev/null
Попробуем запустить наш цикл. Потом загрузим оперативную память:
python3.10
var = "a"*5*1024**3
И снова цикл. Осталось загрузить ввод-вывод:
sudo iotop
cat /dev/urandom > /tmp/1
И снова запустим цикл.
Одного измерения недостаточно. Собственно, примеры загрузки системы выше были призваны проиллюстрировать влияние внешних факторов на запуск вашего кода. Для минимизации этого влияния следует измерить несколько раз. Можно ручками внести результаты в таблицу. Но, во-первых, мы люди ленивые. А во-вторых, ручная обработка всегда чревата ошибками. Соберём всё в табличку.
А с этим есть проблема. Для вывода time в файл придётся немного извратиться. Дело в том, что перенаправление будет работать для команды выполняемой команды, то есть для всего справа от time. На помощь придёт логическое объединение в виде group command с помощью фигурных скобочек:
man bash
Ищем такую конструкцию /\{
Слеш для поиска, потом экранирование обратным слешом фигурной скобки. Как видно из справки, нужно добавить фигурные скобки и точку с запятой в конце, и только потом перенаправить. При этом time пишет в стандартный поток ошибок, то есть нужно перенаправлять второй дескриптор. Получается вот так:
TIMEFORMAT="%R"; { time $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; ) ; } 2>> res.csv;
tail -f res.csv # для проверки, что пишет
libreoffice res.csv # для обработки итоговой таблицы после завершения
Если запустить libreoffice с английским языком, то запятая будет считаться разделителем разрядов и удалится, мы получим неверное время (4567 вместо 4,567).
Закроем файл и откроем снова. Переключим язык на русский, чтобы запятая стала десятичным разделителем. Впишем формулы СРЗНАЧ и СТОТКЛ.
Если запускать скрипт 10 раз лень, можно накинуть ещё цикл (больше циклов богу циклов):
for i in $( seq 2 ); do TIMEFORMAT="%R"; { time $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; ) ; } 2>> res.csv; done
Резюмируем. Наша методика экспериментального исследования времени работы программы выглядит так:
берём 8-ядерный i7-3770
проводим 10 измерений командой time
запускаем много циклов "-lt" vs "<"
рассчитываем среднее арифметическое и среднеквадратичное отклонение
В следующем видео заодно интереса ради посмотрим на другие языки.
Теперь вы знаете, как можно загрузить процессор, оперативную память или подсистему ввода-вывода, как посмотреть на эту загрузку и как она может влиять на программу. Такие дела.
Сегодня продолжим изучать наш идеальный скрипт из предыдущего видео (видео прошлой части). Разберёмся с непонятными конструкциями в bash [] и [[]] и обсудим, когда можно не ставить кавычки вокруг переменных. Ниже видео с разбором, а кому удобнее текстовый вариант — добро пожаловать ниже.
Давайте разбираться. Двойные квадратные скобки в современном bash - это ключевое слово, такое же, как for. Проверить это можно с помощью команды type. Одинарные квадратные скобки - это встроенная команда, такая же, как test. Что из этого следует? Да фиг знает, по факту. Просто интересно. А вот внутри одинарных и двойных квадратных скобок можно использовать разные конструкции.
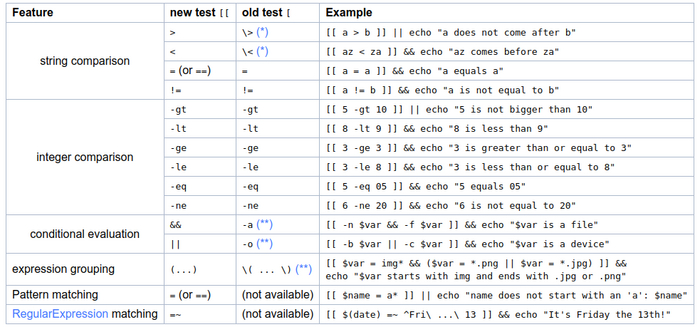
Для сравнения [[ и [ нашёл для вас очень наглядную таблицу
Например, знак меньше для одинарных скобок нужно экранировать, как и скобки. Для двойных скобок работают привычные программисту логические операции, регулярные выражения и прочие приятные штуки. Глобально, нет причин сейчас использовать одинарные квадратные скобки. Разве что ради переносимости.
Но про переносимость куда мы говорим? Действительно, двойные квадратные скобки появились не сразу. В разделе 7.1 книги Advanced Bash-Scripting Guide (версия на русском) написано, что конструкция появилась в bash версии 2.02. Кстати, это очень большая и вкусная книжка по bash, рекомендую её, если вы зачем-то решили стать в баше экспертом. Там под тысячу страниц, материал не для слабых духом. Есть и на русском, и на английском.
Так когда появились двойные скобки? Проверим changelog баша, там можно найти первое упоминание конструкции [[]] в версии 2.02. А потом можно найти релиз, и это 1998 год. 1998, Карл. Надеюсь, все обновились с тех пор.
В man bash можно найти описание [[]], лучше посмотрите в видео этот фрагмент.
Соберём на коленке пример демонстрации важности двойных кавычек.
a="hello world"
if [[ $a == "hello world" ]]
then
echo "success"
fi
# в видео показан однострочник ниже
if [[ $a == "hello world" ]]; then echo "success"; fi
И всё хорошо, внутри [[]] действительно можно не применять кавычки, bash всё сделает корректно. Но потом модифицируем пример
# так неправильно!
if [[ $a == "hello world" ]]; then echo "success"; touch $a; fi
И вот этот код уже ломается. Вместо создания одного файла "hello world" создаются два отдельных файла. Потому что в touch надо кавычками защищать переменную
# так нормально, но тяжело объяснить, где нужны кавычки
if [[ $a == "hello world" ]]; then echo "success"; touch "$a"; fi
А теперь объясните джуну, где надо ставить кавычки, а где не надо. Самое простое правило - кавычки должны быть везде. Великий и ужасный Гудвин, ой, то есть баш, очень неустойчив к разного рода ошибкам. По опыту жить проще с ядрёным стайл-гайдом, по которому чисто визуально можно выявить ошибку. Есть переменная? Должны быть кавычки.
# так безопаснее всего
if [[ "$a" == "hello world" ]]; then echo "success"; touch "$a"; fi
Давайте попробуем сконструировать выражение для оценки времени выполнения. Как корретно измерять время выполнения я планирую снять отдельное видео. Пока не будем вдаваться в детали и попробуем собрать нужную конструкцию
Утилита time выдаёт временные характеристики работы программы. Сейчас нас интересует блок real, где указано общее время работы программы согласно системному таймеру, то есть время от запуска команды до её завершения
time echo $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Если заменить двойные квадратные скобки на одинарные, по неведомой мне причине скорость выполнения драматически падает. Нет ни одной адекватной причины использовать одинарные квадратные скобки уже лет десять как.
Вернёмся к замене -lt на треугольный знак меньше. Попробуем
# ОШИБОЧНОЕ 2 итерации вместо 1кк
time echo $( i=0; while [[ $i < 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Вау! Отработало мгновенно. Но неправильно. Обратите внимание на вывод - прошло только 2 итерации. Потому что два больше миллиона, если смотреть на них как на строки. Строковое сравнение идёт посимвольно, и два больше 1 - истина, дальше смотреть не требуется.
По факту, нужно использовать арифметическое выполнение
time echo $( i=0; while (( $i < 1000000 )); do i=$(( $i+1 )) ; done; echo $i )
А теперь ещё раз. Как вы думаете, в большом скрипте легко обнаружить такую ошибку? Это отладочный ад. Поэтому используйте -lt и аналогичные конструкции в баше, чтобы сэкономить себе время
Подытожим: всегда используйте двойные квадратные скобки в if и while, всегда защищайте ваши переменные двойными кавычками, даже если в отдельных конструкциях баш делает это за вас. Пишите поддерживаемый код, и да пребудет с вами баш.
Заходите в наш канал DevFm в телеграмм, где выходят годные материалы для middle плюс python разработчика. Если хотите разобраться с азами Linux, то добро пожаловать в наш бесплатный курс cli-for-dev на степике. Буду рад, если вы поддержите нас позитивными оценками и обратной связью по курсу.
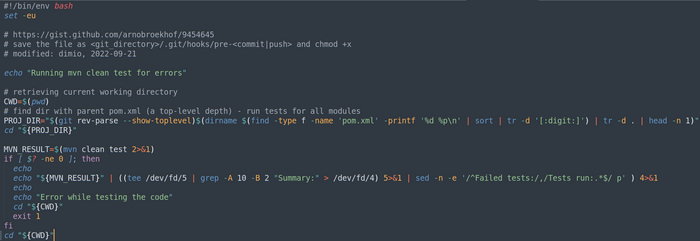
Есть у меня такой pre-push хук - автоматом прогоняет тесты локально, через maven. Подключается по необходимости через отдельные git конфиги для проектов.
Стащил его, судя по всему, отсюда: https://gist.github.com/arnobroekhof/9454645. Потом допиливал немного – чтобы он с многомодульными проектами работал корректно. Может, ещё что-то по мелочи причёсывал.
И он отлично работает (разве что можно через sed попробовать результаты по всем модулям агрегировать).
Но вот проблема – на текущем проекте везде gradle, а под него я что-то не могу найти похожего простого решения
Спасибо @Dristofor, который навеял мне мысль про более изящное решение.
В thunar можно добавлять кастомные пункты в контекстное меню (Правка - Особые действия), после чего путь к файлам, имена выделенных файлов и что там надо передаются в качестве параметров в программу обработчик. А еще есть комплект программ ImageMagick, где есть консольная команда convert, которая всякие форматы изображений конвертирует друг в друга с синтаксисом типа convert SOURCE RESULT. То есть, по итогу, задача - выцепить из параметров скрипта имена конвертируемых файлов без расширений, и с полным путем конвертировать их в файлы с теми же именами в новом формате. Причем, не перепиливая скрипт под новый формат каждый раз.
Скрипт вызывается с параметрами: 1-желаемое расширение, в формат которого конверируется файл; 2- путь к конвертиируемым файлам; начиная с 3-го параметра - имена файлов в обрабатываемой папке. Все параметры прогоняются через цикл, в котором игнорируются 1 и 2 параметры, а из коротких имен файлов лепятся длинные имена с новым и старым расширением, которые подставляются в команду конвертера imagemagick. Почему-то условный переход на сравнение $counter $1 и $2 у меня не заработал, так что я засунул костыль ввиде счетчика, извинити. Изначально я хотел просто запрашивать пачку длинных имен файлов, но потом узнал, что длина командной строки в линухе ограничена 4кб, и выбрал вариант покороче.
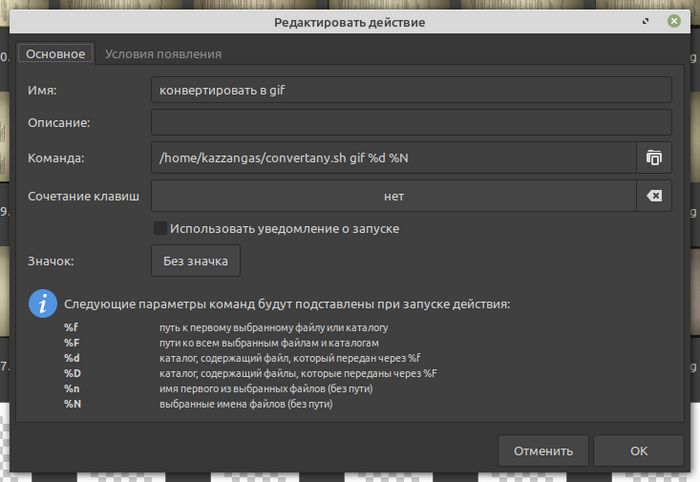
Далее, скрипт у нас, конечно, помечен, как исполнимый, imagemagick установлен. Ковыряем настройки Особых действий в Thunar:
Соответственно, после имя_скрипта.sh и перед %d%N вписываем то расширение, для получения которого мы все это теребим. После заполнения всего этого в настройках, выбираем пачку файлов картинок (причем, можно разного формата), тыкаем в контекстном меню на свежевылупившийся пункт, получаем новые гифки или что там заказывали.
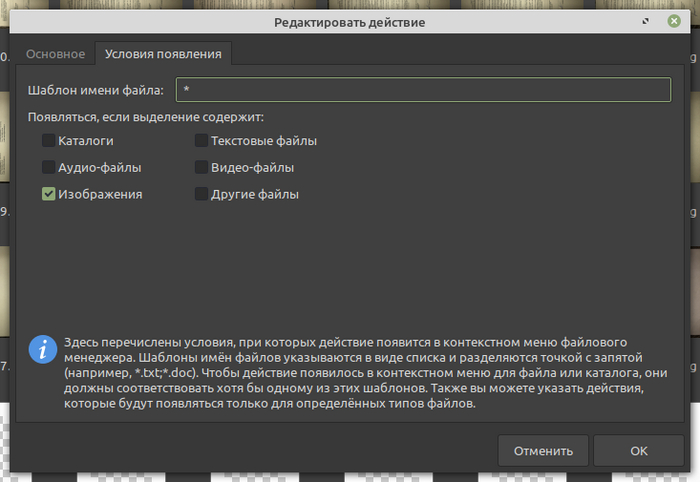
Ньюанс. Во-первых, ранние версии imagemagick (у меня 6-я) не умеют обрабатывать, например, .heic; что оно ест, можно узнать командой "convert -help". Далее, как я понимаю, в поздних версиях вместо convert пишут magick, соответственно, команду в скрипте надо поменять. Ну и, в моем случае, для обработки .heic`ов, нужен сторонний конвертер heif-convert из пакета libheif-examples; вписывается вместо "convert", работает с тем же синтаксисом, в настройках Особых действи тунара надо указать шаблон имени файла *.heic и Появляться, если содержит Другие файлы.
Как оно лепится к наутилусу, я без понятия, но - почти уверен - не сильно сложнее.