Пасхалка в Mr Robot S02E01.

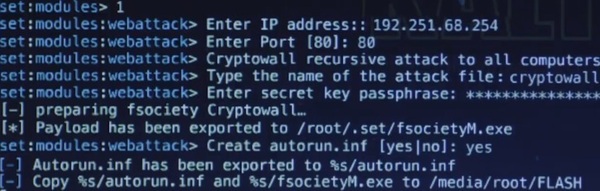
В конце первой серии второго сезона Mr Robot есть сцена, где Дарлин генерирует троян-вымогатель с помощью модифицированного фреймворка SET (Social Engineer Toolkit). Мои пальцы просто зудели, чтобы попробовать IP-адрес 192.251.68.254, где вроде как располагается управляющий сервер трояна. Неудивительно, что WHOIS показал на владельца NBC-UNIVERSAL. Посмотрим, насколько глубока кроличья нора.
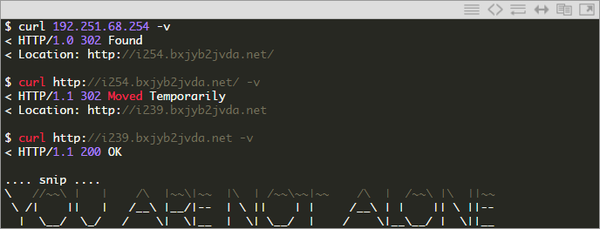
Последняя страница http://i239.bxjyb2jvda.net/ выводит сообщение «YOUR PERSONAL FILES ARE ENCRYPTED» и начинает обратный отсчёт. Вы можете подождать 24 часа или просто проверить javascript, который управляет таймером обратного отсчёта, где вы найдёте строку, закодированную в base64.
PGRpdiBjbGFzcz0ib3ZlciI+PGRpdj4iSSBzaW5jZXJlbHkg
YmVsaWV2ZSB0aGF0IGJhbmtpbmcgZXN0YWJsaXNobWVudHM
gYXJlIG1vcmUgZGFuZ2Vyb3VzIHRoYW4gc3RhbmRpbmcgYXJta
WVzLCBhbmQgdGhhdCB0aGUgcHJpbmNpcGxlIG9mIHNwZW5k
aW5nIG1vbmV5IHRvIGJlIHBhaWQgYnkgcG9zdGVyaXR5LCB1bm
RlciB0aGUgbmFtZSBvZiBmdW5kaW5nLCBpcyBidXQgc3dpbmRs
aW5nIGZ1dHVyaXR5IG9uIGEgbGFyZ2Ugc2NhbGUuIjwvZGl2Pjx
kaXYgY2xhc3M9ImF1dGhvciI+LSBUaG9tYXMgSmVmZmVyc29u
PC9zcGFuPjwvZGl2PjwvZGl2Pg==
После раскодирования выходит:
Я искренне полагаю, что банковские институты более опасны для свободы, нежели регулярные армии, и что принцип тратить деньги за счёт потомков, под названием «финансирование», ничто иное как жульничество за счёт будущего в крупном масштабе.
– Томас Джефферсон
Кстати, изучив SSL-сертификат веб-сервера NBC-UNIVERSAL, я обнаружил массу других доменов, которые имеют отношение к Mr Server., указанных в поле Subject Alternative Names.
DNS Name=www.racksure.com
DNS Name=racksure.com
DNS Name=*.serverfarm.evil-corp-usa.com
DNS Name=www.e-corp-usa.com
DNS Name=iammrrobot.com
DNS Name=www.conficturaindustries.com
DNS Name=www.iammrrobot.com
DNS Name=*.seeso.com
DNS Name=*.evil-corp-usa.com
DNS Name=e-corp-usa.com
DNS Name=*.bxjyb2jvda.net
DNS Name=whoismrrobot.com
DNS Name=seeso.com
DNS Name=fsoc.sh
DNS Name=www.fsoc.sh
DNS Name=conficturaindustries.com
DNS Name=whereismrrobot.com
DNS Name=www.whoismrrobot.com
DNS Name=www.whereismrrobot.com
DNS Name=evil-corp-usa.com
DNS Name=www.seeso.com
В начале первой серии второго сезона вы также заметите, как Эллиот логинится на bkuw300ps345672-cs30.serverfarm.evil-corp-usa.com по SSH.
Что касается задачки на https://fsoc.sh:
Если посмотрите на эту страничку, то заметите, что курсор мигает через разные интервалы.
На самом деле несложно понять, что это код Морзе, но я крайне плох в решении таких загадок вручную. Поэтому решил применить более техничный способ.
addHandlers: function() {
var t = this;
this.$(".eye__form").on("submit", this.handleSubmit), this.textView.on("typingEnded", function() {
t.appendEye(), t.startCursor("MzkzMzUzNTM5NTMzMzk1Mzc5OTUzNzMzMzM1MzUzOTM1Mw==")
})
},
startCursor: function(t) {
var e = this;
e.$(".eye__cursor").css("opacity", 0).removeClass("typing"), setTimeout(function() {
e.handleBlinkTime(window.atob(t), 0)
}, 500)
},
handleBlinkTime: function(t, e) {
var n = 300,
r = t.charAt(e),
i = 0,
o = n;
switch (r) {
case "9":
i = 3 * n;
break;
case "3":
i = n;
break;
case "5":
o = 3 * n;
break;
case "7":
o = 7 * n
}
var u = this;
i && u.$(".eye__cursor").css("opacity", 1), setTimeout(function() {
u.$(".eye__cursor").css("opacity", 0), setTimeout(function() {
t.length > e + 1 ? u.handleBlinkTime(t, e + 1) : setTimeout(function() {
u.handleBlinkTime(t, 0)
}, 4e3)
}, o)
}, i)
Собственно, скорость мерцания курсора контролирует t.startCursor("MzkzMzUzNTM5NTMzMzk1Mzc5OTUzNzMzMzM1MzUzOTM1Mw=="), и если конверитровать в ASCII, то получается 3933535395333953799537333353539353.
3 это точка "."
5 разделяет буквы " "
7 представляет собой разделитель "/" в коде Морзе
а 9 это тире "-"
3933535395333953799537333353539353
.-…. .- ...- ./-- ./…. .-.. == LEAVE ME HERE
Нужно добавить, что во втором сезоне сериал сохранил крайнюю реалистичность компьютерных сцен. Каждый взлом и операция выполняются в правильной последовательности и с использованием корректных инструментов. В первом сезоне мы видели операционку Kali Linux, использование уязвимости bashdoor (shellshock) для получения файла /etc/passwd, взлом автомобильной CAN-шины с использованием утилиты candump, сканирование окружающих устройство с активным Bluetooth утилитой btscanner из комплекта Kali Linux, использование снифера bluesniff для MiTM-атаки с последующим запуском оболочки Meterpreter.
В первой серии второго сезона все технические тонкости — фреймворк SET, ransomware, логи IRC, клиент BitchX и прочее — тоже показаны вполне достоверно.
Ремарка: В одном из кадров мелькает QR-код, который указывает на один из доменов списка, приведённого выше: http://www.conficturaindustries.com.

Код плохо распознаётся с кадра, вот чёткая копия:

Судя по всему, будущие серии Mr Robot тоже не останутся без пасхалок.
Технические консультанты Mr Robot из хакерского сообщества: @KorAdana, @ryankaz42, @AndreOnCyber, @MOBLAgentP, @IntelTechniques, @marcwrogers.