


Реставрация старой техники
13 постов
13 постов

4 поста

4 поста
Свой прошлый пост я сопроводил картинкой, нарисованной при помощи нейросети. Этот факт заинтересовал многих куда больше, чем локальный юмор научных сотрудников. Несколько человек под это дело на меня даже подписалось. Теперь уже не отвертеться, так что держите рассказ о том, что это за сетка такая и как ей пользоваться.

Да, это всё нарисовала она
Для начала небольшая справка. Нейросеть называется CLIP Guided Diffusion HQ. О чём это нам говорит? HQ — понятно, высокое качество. CLIP (Contrastive Language-Image Pre-Training) — это такой сравнительно новый метод обучения мультимодальных нейросетей. Мультимодальность в данном случае означает одновременную обработку разных типов данных — текста и изображения. Предыдущие сети, умевшие рисовать картинки, в основном относились к типу GAN (генеративно-состязательные). У этого подхода есть свои плюсы и минусы, ну да сейчас не о нём. Diffusion означает диффузионный метод формирования изображения, при котором из «затравочной» картинки поэтапно удаляется шум. Затравка может быть осмысленным изображением или случайным набором пикселей.

Типичная затравка. Когда б вы знали, из какого сора...
Примечательно, что CLIP Guided Diffusion HQ была обучена не на заранее размеченных наборах данных, а на 400 миллионах пар «картинка-текст», взятых просто из интернета. Да, мемы с котиками, рисунки фурей с Deviantart и предвыборные плакаты Трампа — всё это сеть впитала в себя, словно дух реки из «Унесённых призраками». Причём алгоритм сам определял, какой текст к какой картинке относится, что привело к некоторым любопытным особенностям. Чтобы хоть немножко «окультурить» нейронку, авторы вручную добавили в датасет ещё 500 тысяч изображений, которые ищутся по словам из заголовков статей английской Википедии.
Но довольно теории, ведь все понимают, ради чего мы тут собрались, — ради наркоманских картиночек, конечно же! Попробовать CLIP Guided Diffusion HQ можно много где. Естественно, все вычисления будут выполняться не на вашем компьютере, а на удалённой виртуальной машине. Код требует мощного графического ускорителя с кучей памяти. Нет, можно запускать и на CPU, но тогда результат работы увидят только ваши внуки.
Для начала предлагаю попробовать простой веб-интерфейс, позволяющий немного поиграть шрифтами параметрами.
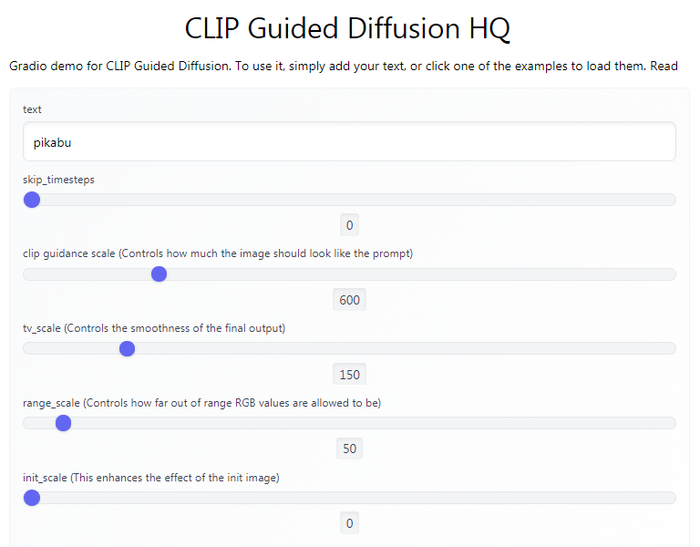
Запрос вводится в поле text, ползунок timestep respacing задаёт количество итераций (чем больше, тем проработаннее будет картинка), остальные параметры первое время можно не трогать. Нажимаем [Submit], ждём несколько минут и получаем свою дозу ЛСД размером 256 × 256 пикселей. Да, негусто, но таковы ограничения используемого датасета и доступной аппаратуры. О том, как можно поднять разрешение, мы ещё поговорим в конце поста.
Вот так, по мнению нейросети, выглядит «pikabu».

Не спрашивайте меня, почему он похож на чёрную дождевую лягушку с анальной пробкой!

Искусственный интеллект так видит. И вообще, сначала сочини симфонию и преврати кусок холста в шедевр искусства, а потом уже возмущайся!
Абстрактные пейзажи удаются CLIP Guided Diffusion HQ намного лучше. Например, вот эту иллюстрацию по запросу «Песнь льда и пламени» (естественно, по-английски) можно хоть сейчас ставить на обложку метал-альбома.

Кстати, насчёт перевода. Мне стало любопытно, не было ли в обучающей выборке текстов на кириллице. Я сформулировал максимально простой запрос, по которому было бы очевидно, поняла меня сеть или нет, — «синий треугольник». В общем, не повторяйте моих ошибок!

Теперь этот мужик будет являться ко мне во снах.
Если написать тот же текст латиницей, результат будет не лучше. Хоба!

В общем, про русский язык можно забыть.
По запросу «steampunk» удалось получить затейливые узоры из латунных трубок и клапанов, эдакий Царь-саксофон.

Но в целом с техникой нейросеть справляется плохо. Сколько раз я ни просил её нарисовать самолёт, паровоз или танк, получалась какая-то ерунда.
Не стоит ждать от неё и угадывания того, что именно вы имеете в виду. Скажем, вводя запрос «Heroes III», я был уверен, что получу какую-то вариацию на тему скриншотов из игры. А получил вот что:

Ну, тут отдалённо угадываются фигуры в доспехах и с оружием... Видимо, это герои. Три штуки!
Любопытные картинки получаются, когда сети попадаются слова с множественными значениями. Скажем, «Red Square» — и «Красная площадь», и «красный квадрат». Нейросеть не могла знать, что именно от неё хотят, поэтому на всякий случай сгенерировала картинку «и нашим, и вашим» — красный квадрат, но со структурой брусчатки.

Ещё немного крипоты по запросу The Hound of the Baskervilles.

«Это я, сэр Генри. Помоги выбраться из собаки!»
Понимания культурного контекста кремниевым мозгам, конечно, не хватает. Я предложил сетке сгенерировать обложку для книги «Снятся ли андроидам электроовцы?». В результате получилось изображение с двумя подключёнными к электросети смартфонами (видимо, на Android), на экране которых изображены овцы.

— Какие претензии? Андроиды есть? Есть. Овцы есть? Есть. Электрические? Ну так ясен хрен, что не живые! Иди отсюда, кожаный мешок, ты сам не знаешь, чего хочешь!
Впрочем, в чём слабость сети, в том и её сила (простите, что заговорил цитатами из пацанских пабликов). Она честно пытается интерпретировать все слова, которые вы включили в запрос, и если ей знакомо что-то похожее, может получиться очень интересный результат. Нет никаких формальных правил, просто вписывайте туда всё, что придёт в голову. Например, добавляя в конце by <имя_художника>, можно получать картины в его стиле.

Harry Potter by Wassily Kandinsky и Robinson Crusoe by Claude Monet
Если нужен конкретный цвет, это тоже можно добавить в запрос — скорее всего, сработает. Повторю фрагмент стартовой картинки:
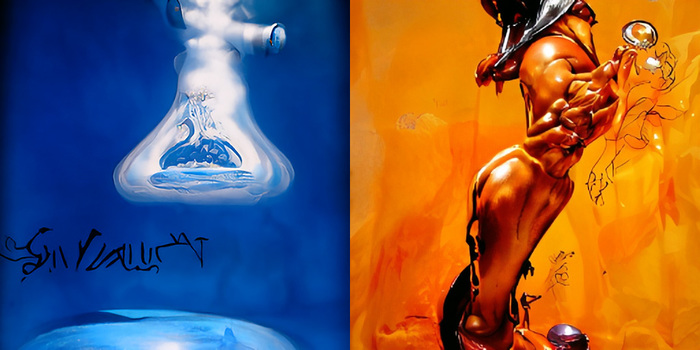
1. Scientific certainity by Salvador Dali in blue
2. Alchemist by Boris Vallejo in orange
Остальные две иллюстрации, если что, это The Picture of Dorian Gray by Giuseppe Arcimboldo и The Lord of the Rings by Arnold Böcklin.
Если требуется дорисовать (ну или сделать более наркоманской) существующую картинку, её нужно добавить в поле initial image. Параметр skip_timesteps влияет на то, на сколько итераций нейросеть может уйти в своих фантазиях от предложенного образа, а clip guidance scale определяет, насколько строго его нужно придерживаться.
Хороший результат получается не всегда. Скажем, попытка скрестить образы Бога-Императора и Владимира Путина лишь сделала Императора более недовольным.

Была и другая картинка по тому же тексту, но её я покажу, только если очень-очень попросите.
I need MOAR!
Если вам мало возможностей huggingface.co, советую обратиться к оригинальному коду авторства Katherine Crowson. Заходите сюда под гугл-аккаунтом, нажимайте «Подключиться» в правом верхнем углу и надейтесь, что вам не выпадет сообщение о том, что доступен только центральный процессор. Если же вам предоставили GPU, самое время заглянуть в зубы дарёному коню. Для этого поставьте курсор на первый блок кода и нажмите Ctrl+Enter, чтобы выполнить его. На экране появится информация о графическом ускорителе виртуальной машины.
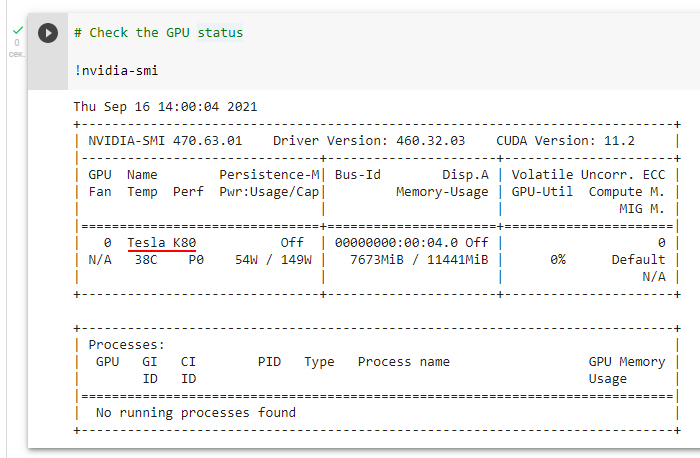
Скорее всего, вам достанется средней паршивости Tesla K80, на котором картинка в хорошем качестве считается полчаса–час. Но если повезёт (чаще всего это бывает ночью), можно заполучить и Tesla T4, а это уже означает ускорение почти на порядок плюс некоторые дополнительные возможности, о которых я скажу далее.
Чтобы шестерёнки завертелись, нажимайте Ctrl+F9 (ну или [Среда выполнения → Выполнить всё]). Потребуется время на установку необходимых пакетов и скачивание самой модели, обычно в пределах десяти минут. Изредка нужно проявлять активность в этой вкладке, иначе Google будет ругаться, что вы зря тратите его ресурсы.
Основные параметры задаются в блоке Settings for this run.
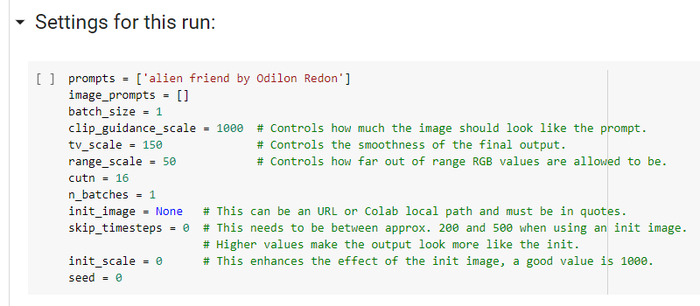
Если вы хотите работать только с текстом, ничего кроме prompts вам не нужно. Если же требуется стартовая картинка, вставьте её URL в одинарных кавычках вместо None вот сюда:
init_image = None. Также рекомендую для начала skip_timesteps = 300 и init_scale = 1000.
Количество итераций задаётся в блоке Model settings параметром timestep_respacing. Значение должно быть в одинарных кавычках.
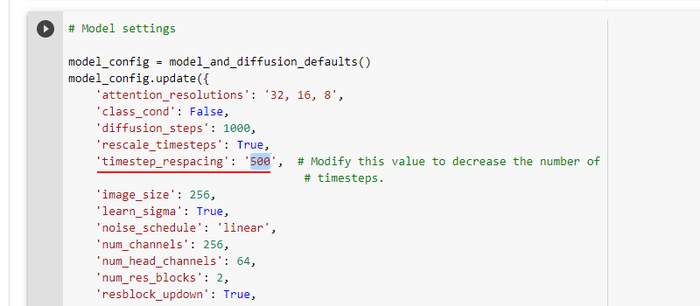
Я бы для начала ставил 500 или даже 250, особенно если вам достался слабый ускоритель. 1000 необходимо для максимальной проработки и звенящей чёткости деталей.
Кстати, о чёткости. Как я уже говорил, эта сеть умеет делать картинки размером только 256 × 256. Задача сгенерировать изображение по тексту очень сложна, так что даже на одну такую картинку уходит больше вычислений, чем в своё время потребовал весь атомный проект СССР. Но вот задача увеличить разрешение с сохранением чёткости куда проще, и её вполне можно перепоручить другой нейросети. Тут я уже не буду подробно расписывать, можно почитать обзор и выбрать понравившуюся. Есть полностью бесплатные, есть с триальным периодом. Некоторые иллюстрации прямо сильно выигрывают от апскейла.

«Квантовый портал в стиле Сталкера», увеличение 4x через deep-image.ai
Мой друг, который на досуге пишет фантастическую литературу, всерьёз задумался, не иллюстрировать ли ему свои книги при помощи нейросетей.
Ну и, наконец, о дополнительных возможностях, которые дарует ускоритель Tesla T4. У него 16 ГБ памяти, а это значит, что на нём можно запускать продвинутую версию той же нейросети, которая сразу генерирует картинки размером 512 × 512 пикселей. Доступна тут.
Вообще у нейросетей, основанных на методе CLIP, есть много вариаций. Я показал только три самые простые, с которыми можно быстро начать работу. Но если поискать, вы найдёте и другие.
Ещё раз основные ссылки для ЛЛ:
3. Если повезёт заполучить Tesla T4
Кидайте в комменты ту занятную дичь, что у вас получится!
Диалог на работе:
— От чего зависит скорость речи?
— От расстояния между говорящим и горизонтом событий чёрной дыры. Чем ближе, тем скорость речи меньше для стороннего наблюдателя.
— ...

Картинка к посту сгенерирована нейросетью по запросу «скорость речи вблизи горизонта событий чёрной дыры».

Мир живого и мир машин стали ещё немного ближе друг к другу. Коллектив учёных из университета Ньюкасла продемонстрировал прототип стековой памяти на базе ДНК. Само по себе использование ДНК для хранения цифровой информации — в научном мире уже не новость, но вот динамическая структура, которая позволяла бы стирать и записывать данные и выдавать их упорядоченно, создана впервые.
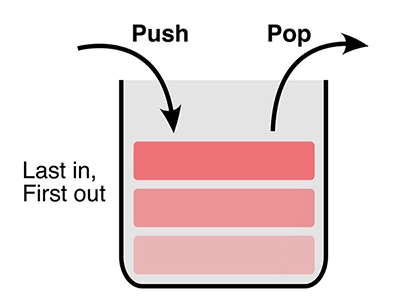
Так работает стек-память: последним пришёл — первым ушёл
Большинство ранее представленных разработок — это архивная память. На основе битовой последовательности химически синтезируется нужная цепочка ДНК, которую затем можно прочитать методом секвенирования или ПЦР. Это перспективное решение для долговременного хранения данных, которое способно обеспечить плотность записи на несколько порядков выше, чем лучшие из существующих «железных» систем. Но такой формат не предусматривает модификации данных.
Стековая память на ДНК организована иначе. Запись и чтение информации осуществляются путём построения и усечения полимеров из одноцепочечных нитей ДНК. Биты информации кодируются при помощи двух сигнальных цепочек ДНК, одна длиной 107, а другая — 137 нуклеотидов. Далее мы будем их называть «сигнал X» и «сигнал Y».
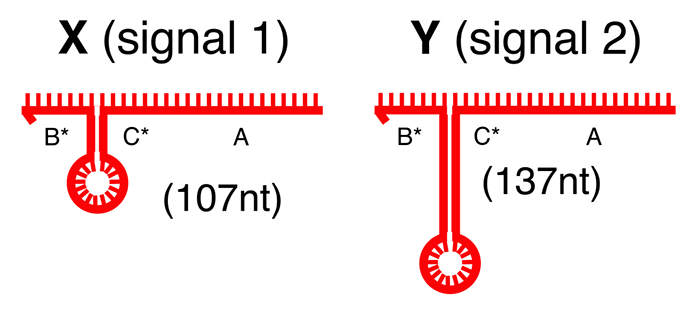
Нуклеотиды в этих сигналах подобраны так, чтобы у них были одинаковые домены гибридизации (точки, в которых они соединяются с другими цепочками ДНК), но при этом образовывались так называемые шпильки разной длины, по которым сигналы можно было бы легко различать.
Работает всё следующим образом. В начале в раствор помещается базовая цепочка (start). Затем туда добавляется вспомогательная цепочка push, которая гибридизуется (соединяется) с цепочкой start. Получается что-то типа застёжки-молнии со свободным концом. Это делает возможным дальнейшее присоединение сигнальных цепочек, то есть запись данных. Далее в раствор добавляется сигнал X или Y, который соединяется с комплексами start-push. Добавляя «связующие звенья» push и сигналы данных, можно формировать полимеры стека сколь угодно большой длины.
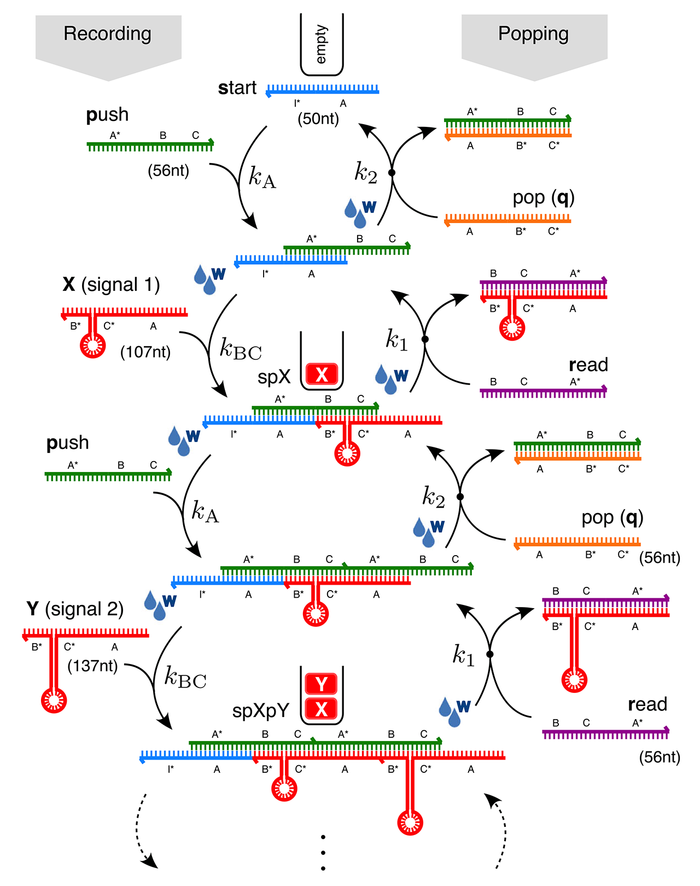
Когда же информацию нужно прочитать, в раствор добавляют цепочку типа read. Она соединяется с «выступом» последнего записанного сигнала и вызывает смещение нити действующей цепочки push, гибридизованной с сигналом. Цепочка read и сигнальная цепочка образуют продукт, который отсоединяется от конца стекового полимера и высвобождается в раствор, где его можно распознать. Это эквивалентно прочтению данных. Далее в раствор можно добавить цепочку pop, которая аналогичным образом удалит крайнюю цепочку push и тем самым переместит «указатель» стека. Операции read и pop можно чередовать так, чтобы в конечном счёте укоротить стек до исходной цепочки start.
Схема простая и даже изящная, но не стоит забывать, что это очень ранний прототип технологии. То, что красиво выглядит на бумаге, далеко не так быстро и эффективно работает в пробирке. Скажем, на уравновешивание реакции после добавления новой цепочки в нынешнем варианте уходит полчаса. Причём после каждой стадии необходима механическая промывка, от тщательности которой напрямую зависит надёжность работы всей системы — иначе на поведение стека станет влиять предшествующая последовательность операций. Также стоит понимать, что одна молекула ДНК на схеме дана лишь для иллюстрации. На самом деле даже в типичном объёме 20 микролитров такой стек присутствует в количестве не менее 10 млрд копий, и их идентичность не гарантируется. Есть и ограничение на количество операций, которые ДНК способна выполнить.

Так стековые цепочки выглядят под атомно-силовым микроскопом
В общем, учёным предстоит решить ещё немало проблем. Тем не менее, опытная демонстрация технологии имеет большое значение. То, что на базе цепочек нуклеиновых кислот удалось реализовать стандартные функции, пусть даже такие простые, как push и pop, открывает перспективы не только для хранения информации, но и для вычислений на ДНК. А это значит, что сделан ещё один шаг в сторону биокомпьютеров, давно предсказанных в научной фантастике. Wetware грядёт!
С полным текстом статьи можно ознакомиться в журнале Nature Communications.
Как вы знаете, моё хобби — это сохранение и восстановление старой техники. В этом смысле мне повезло с местом работы: я сотрудник Политехнического музея. Правда, там я занимаюсь другими вещами, не связанными напрямую с экспонатами из коллекции. Но так или иначе в наших фондах я бывал не раз — и по делу, и просто как посетитель. Наконец-то мне удалось найти время, чтобы подготовить серию постов о самом интересном из того, что мне удалось увидеть.

Пока музей на реконструкции, все его сокровища хранятся на территории технополиса «Москва» (это бывший завод АЗЛК). Технополис — не выставочная площадка, а именно музейное фондохранилище, святая святых. Тем не менее, попасть туда могут не только сотрудники: в рамках проекта «Открытая коллекция» экспонаты доступны для просмотра всем желающим. Разумеется, по предварительной записи и в сопровождении музейного хранителя, но хорошо, что в принципе есть такая возможность: в большинстве других музеев людей со стороны в запасники вообще не пускают.
В условиях пандемии посещение ограничено, да и не всем легко добраться до Москвы. Поэтому предлагаю отправиться вместе со мной в небольшое фотопутешествие. Снимков у меня получилось много, и в один пост они всё равно не влезут, так что сегодня у нас будет скорее знакомство с коллекцией. Итак, поехали!
Изнутри здание технополиса прежде всего поражает своими размерами. Внутри даже есть свои улицы и переулки, а работники перемещаются на электросамокатах.

Первое, что видит посетитель в фондах, это шкафы. Ранее они использовались просто как мебель для хранения и демонстрации экспонатов, но со временем уже сами превратились в экспонаты.

То же произошло с масштабными моделями, которые на момент создания отражали современное положение дел в промышленности, но с годами приобрели ещё и историческую ценность. Теперь они отвечают не на вопрос «как это есть», а на вопрос «как это было».

Большая часть экспонатов по-прежнему хранится в деревянных ящиках, что делает фондохранилище похожим на склад реликвий из «Индианы Джонса».

Фото с сайта музея
Но самые важные и любимые публикой артефакты извлечены из упаковок и выставлены на стеллажах.

Вы наверняка заметили, что к каждому экспонату прикреплена бирка. При переезде коллекции из исторического здания в 2013 году всё постарались максимально автоматизировать. Каждый экспонат получил этикетку с номером, описанием, штрих-кодом и QR-кодом, после чего был сфотографирован, бережно упакован, перевезён и посчитан по прибытии.

Ни одного экспоната при переезде не потеряли, зато нашли несколько ранее неучтённых. На 2019 год в фондах музея насчитывалось 235 174 предмета. Сейчас их уже больше, поскольку пополнение коллекций продолжается.

Часто спрашивают, какой экспонат Политехнического музея значится под номером 1. Ответ довольно неожиданный: это слиток чугуна. Первый экспонат — не значит важнейший или старейший: в 30-е годы коллекция музея была реорганизована по отраслевому принципу, и первые номера получили экспонаты, связанные с металлургией. Так что этой отливке нет и ста лет.

Если же смотреть по ценности и уникальности, то первый экспонат — пожалуй, знаменитый «Руссо-Балт», старейший из сохранившихся автомобилей российской постройки.

Машина с удивительной судьбой — свыше 30 лет была в эксплуатации, затем попала на Горьковскую киностудию, чудом не была уничтожена по время съёмок фильма о Гражданской войне, и наконец в весьма плачевном состоянии в 1966 году поступила в коллекцию музея.

Компиляция фотографий из книги Л. М. Шугурова «Погоня за Руссо-Балтом». Изображение с сайта www.drive2.ru
О «Русско-Балтийском» написано много хороших статей, и нет смысла здесь их пересказывать. Расскажу лишь об одной детали. Крышку радиатора украшает двуглавый орёл, но вы не встретите его на более ранних фотографиях автомобиля. Понятное дело, что в советское время (а машина была на ходу до 1942 года) никто бы не стал разъезжать с символом царской власти, так что оригинальный орёл был давно утерян. И только в 2016 году энтузиасты случайно нашли на аукционе такую же фигурку, которую нынешний владелец считал навершием для знамени или чем-то в этом роде. Так машина стала ещё немного ближе к оригиналу.
Если какого-то старинного автомобиля в Политехническом музее нет живьём, там наверняка отыщется его модель. Например, АМО-Ф15 — как считается, первый советский грузовик. С детства помню: «Полуторка АМО — всем машинам мама!».

Масштабных моделей в музее вообще очень много, и одна интереснее другой. Некоторые из них поступили в фонды ещё с Политехнической выставки 1872 года. Это было грандиозное событие, которое собрало свыше 12 тысяч участников из разных стран и почти 750 тысяч зрителей. Публике демонстрировалась готовая продукция, различные машины, а в тех случаях, когда объект экспонирования был слишком велик, — его точные уменьшенные копии.
Вот одна из них — действующая модель маслобойного завода с паровым приводом. Тогда это было последнее слово науки и техники, а сейчас — чистой воды стимпанк. Но как сделана, а?

Модель можно рассмотреть получше на профессиональном фото.
Конечно, я не мог пройти и мимо стеллажа со звуковой техникой. Бытовые модели мне хорошо знакомы, а некоторые даже есть в моей личной коллекции. А вот необычное устройство в сером корпусе, похожее на проигрыватель пластинок, — на самом деле магнитофон МАГ-Д1, не кассетный и не катушечный, а дисковый. Такие использовались для записи сигналов азбуки Морзе в служебных целях. Длительность записи не превышала 5 минут.

Рядом выставлены ещё более раритетные устройства для звукозаписи и воспроизведения — фонографы. Фонограф считается примером «запоздавшего изобретения»: принципиально ничто не мешало ему появиться ещё во времена расцвета античной цивилизации — конструктивно он точно не сложнее, чем знаменитый Антикитерский механизм.
Увы, эта идея не пришла в голову древним мастерам, так что мы никогда не услышим голосов Аристотеля и Александра Македонского. Кстати, «Разрушители легенд» проверяли гипотезу о том, не могло ли пение древних гончаров случайно записаться на горшках, которые они лепили на гончарном круге. Спойлер: гипотеза не подтвердилась.

А вот — один из ранних ламповых радиоприёмников, модель 1929 года. Он ещё не имеет собственного громкоговорителя и рассчитан на использование в паре с наушниками, как детекторные приёмники. Но благодаря лампам он отличается от них более высокой чувствительностью и избирательностью, да и звук на выходе получается заметно громче.

Вторая моя любовь, а заодно и специальность, — это вычислительная техника. Она в коллекции музея представлена очень широко, так что ей одной можно было бы посвятить десяток постов. Но кратко пробежимся по тому, что сейчас выставлено в Открытой коллекции.
Разнообразные ручные приспособления, в первую очередь для суммирования и вычитания. Деревянные русские счёты кое-где можно было застать в использовании даже в XXI веке.

Суммирующие машины первой половины XX века. Такие машины называют полноклавишными, поскольку в них на каждый разряд числа приходится полный набор клавиш со всеми возможными значениями. При определённом умении на них можно было набирать многозначные числа одним движением руки. Может, отсюда пошла распальцовка у некоторых коммерсантов? :)

Машины, в которых числа набирались последовательно (как на современных калькуляторах), называли десятиклавишными. Вот несколько таких машин, дополненных печатающим устройством. Это предшественники портативных терминалов с чековым принтером.

Арифмометр «Оригинал Динамо» — скорее всего, довоенного выпуска. По своим возможностям полностью идентичен более известному «Феликсу», но имеет отличия в дизайне. Вы только посмотрите на эту ручку в форме буквы μ!

Механических и электрических счётных машинок в музее ещё очень много, но все они выполняют одиночные арифметические действия. Давайте теперь взглянем на машины, с которых началась автоматизированная обработка данных. И нет — это ещё не компьютеры, как можно было бы подумать. Вот этот изящный деревянный шкаф со множеством циферблатов — табулятор Германа Холлерита, от которого в конечном счёте ведёт свою историю «голубой гигант» IBM. Хотя в 1889 году, когда появился первый подобный аппарат, этого названия ещё не существовало.

Машина из коллекции музея применялась в ходе всероссийской переписи населения 1897 года. Данные о жителях наносились на перфокарты при помощи ручного перфоратора, который виден на переднем плане. А вот подсчёт результатов производился уже автоматически благодаря системе контактов и электромагнитных реле. В итоге стало известно, что империю населяют 125 680 682 жителя, а городов-миллионников в ней всего два — Санкт-Петербург и Москва (именно в таком порядке).
В коллекции музея есть немало другой техники для работы с перфокартами.

Суммирующие, сортирующие, репродуцирующие и расшифровочные машины в 1920-е — 1950-е годы позволяли значительно ускорить обработку информации. В компьютерах перфокарты «прописались» уже позднее. Упоминания о перфорационной технике можно встретить даже в художественной литературе. Так, в романе «Уловка-22» рассказывается, что рядовому по имени Майор Майор (папа у него был тот ещё шутник) машина IBM по ошибке присвоила звание майора.
Ну и раз уж упомянули компьютеры, то мы просто обязаны увидеть хотя бы один из них. Встречайте «Урал-1» — первую из серийно выпускавшихся советских ЭВМ и одновременно старейшую из сохранившихся до наших дней. Конкретно этот экземпляр выпущен в 1959 году. Увы, от более ранних разработок — М-1, МЭСМ, БЭСМ — остались лишь небольшие фрагменты.

Несмотря на размеры, по меркам тех лет «Урал» относится к классу малых ЭВМ. Процессор машины содержит всего 838 радиоламп — в основном двойных триодов 6Н8С. Такие до сих пор применяются энтузиастами при конструировании ламповых усилителей звука.
Программы и данные для машины записывалась на перфорированную ленту, в качестве которой применялась обычная киноплёнка: практично и экономично. Лента прокручивалась со скоростью 1,4 м/с и позволяла считывать до 4500 чисел в минуту.

Любопытно, что к идее использовать киноплёнку в качестве перфоленты ещё за 15 лет до «Урала» пришёл Конрад Цузе — создатель одного из первых компьютеров, Z3.
Внизу (так и хочется сказать «у подножия», учитывая монументальность ЭВМ и её название) стоит запоминающее устройство на основе магнитного барабана. В каком-то смысле это дедушка современных жёстких дисков, только запись в нём ведётся не на плоскость, а на боковую поверхность.

Но если в современных компьютерах магнитные жёсткие диски используются для долговременного хранения данных, то в «Урале-1» магнитный барабан выступал в качестве оперативной памяти. Да, работало небыстро, но от малой ЭВМ вершин производительности и не требовалось. Даже 100 операций с фиксированной запятой в секунду позволяли одной такой машине заменять целый зал счетоводов с арифмометрами. Подробнее о разновидностях компьютерной памяти можно почитать в одном из моих старых постов.
Кстати, в СМИ можно встретить информацию, что «Урал-1» в Политехе восстановлен до рабочего состояния. Это не совсем так: ламповые «мозги» машины не запускали уже много десятилетий. Но в 2007 году студенты Дмитрий Соловьев и Михаил Гляненко разработали функциональный аналог процессора ЭВМ на основе современной микросхемы программируемой логики, а также необходимый набор средств сопряжения с периферией. Всё это они подключили к пульту ЭВМ, благодаря чему стало возможным демонстрировать её работу с использованием оригинальных кнопок управления и индикаторных лампочек.
На этом лимит фотографий подошёл к концу. Прошу не судить строго за качество снимков: для сохранности экспонатов в фондах поддерживается очень неяркое освещение, а фотографировать со штативом возможности не было.
Надеюсь, пост был вам интересен. В продолжении я готов показать другие редкие образцы вычислительной техники, а также мотоциклы, автомобили, макеты промышленных установок и многое другое. А ещё у меня есть кадры из Политехнической библиотеки и реставрационных мастерских музея — поверьте, там тоже есть на что посмотреть!
С уважением к вам и с любовью к старым железкам, Алексей Бутырин aka BootSector.
Читаю я тут, значит, статью про слухи о вакцинации...


Если что, изначально речь шла о тепловизоре, но в следующих версиях легенды он мутировал в некое устройство по выявлению микрочипов, а тяжёлые металлы — в загадочный светящийся люсифериан.
— Германия, какие танки мне строить?
— Финляндия, какую музыку мне слушать?
— Мавритания, на какой девушке мне жениться?
Германия, Финляндия, Мавритания:

Мудрость, высказанная Борисом Бритвой, была хорошо известна и ранее — вон, в 1940 году её даже вынесли на обложку каталога. И хотя в тексте речь идёт о тяжёлых условиях эксплуатации, любой, кто имел дело со старой техникой, понимает, что на самом деле имеется в виду)
— Здорово! Ты тут рекламу рисуешь? Я, короче, тачки ремонтирую. Нужна вывеска, крупными буквами — АВ-ТО-СЕР-ВИС. Только чтоб не как у всех! Ты ж это, дезигнер, придумай чего-нибудь!
— Ну смотрите, можно обыграть автомобильную тематику. Стилизовать отдельные буквы, скажем, под дорожные знаки...
— О, клёво!
— Ещё можно сделать надпись в таком механическом стиле, знаете, чтобы буквы собирались из разных деталей — гаек, винтиков...
— Отлично ваще!
— Если вы скорее ориентированы на молодёжную аудиторию, то у неё сейчас очень популярны комиксы. Можно взять шрифт в соответствующем стиле, а вместо некоторых букв изобразить атрибуты супергероев. Например, буква «Т» — это молот Тора...
— Ух ты! Зашибись!
— Или, если вас интересуют клиенты посолиднее, можно придать вывеске такой аристократический флёр. Строгий чёрный цвет, винтажный шрифт. Так вы покажете, что вы джентльмены, ведёте дела честно...
— Точно! У нас реально всё по чесноку, всё по понятиям!
— Ну раз по понятиям, то можно и «золотые купола, туз бубновый на спине»...
— Во! В точку прям! Слушай, ты в натуре крутой чувак, не зря я к тебе пришёл! Короче, всё устраивает, давай уже рисовать, по деньгам сколько?
— Подождите, так вы какой из вариантов выбрали?
— Чё? Каких ещё вариантов?

Я за свою жизнь много раз доказывал, что достоин членства в этой лиге. Вот один из случаев. Было мне лет 15, и меня пригласила к себе домой одна девочка, которая, скажем так, проявляла ко мне интерес. В прихожей я увидел рисунок из тех, что продают художники с Арбата. На рисунке была та самая девочка. В общем, для поддержания беседы я не придумал ничего лучше, чем спросить «А это портрет или шарж?».
Надо ли говорить, что потом с этой девочкой у нас ничего не было.

