Анимированные картинки - Первые пробы
Дополнение к посту Анимированные картинки
Картинки анимировал через KLINGAI. Пробовал на ранних своих картинках, вышло местами средне, видны огрехи.
Показать полностью
4
Дополнение к посту Анимированные картинки
Картинки анимировал через KLINGAI. Пробовал на ранних своих картинках, вышло местами средне, видны огрехи.
📌 Модель Qwen Edit очень круто обновилась до версии 2509 (это дата выхода модели) и стала значительно лучше.
👌 Вам эти изменения точно понравятся, так что посмотрите до конца:
☑️ Поддерживается от 1 до 3 реверенсных изображений
☑️ Поддерживаются подсказки со ссылкой на персонажа, объект и на номер изображения
☑️ Согласованность изображений улучшена
☑️ Модель более цепко держит референсы при генерации. Лучше сохраняются лица
☑️ В модель зашиты ControlNet: карта нормалей, карта глубины, canny, openpose и вы можете попросить сгенерировать эти карты из референсного изображения
☑️ Так же вы можете закинуть например позу из openpose и попросить поставить персонажа в эту позу
☑️ Улучшенная согласованность редактирования текста на английском и китайском
😱 Но и это еще не все.
Теперь мы можем работать в разрешении от 1 до 2 мегапикселей❗️ что улучшает детализацию, которая в первой Qwen Edit сильно хромала.
🚀Уже вышла Nunchaku.
🎦 СМОТРЕТЬ НА YOUTUBE (https://youtu.be/hJzjQ1XhAfw)
🎦 СМОТРЕТЬ НА RUTUBE (https://rutube.ru/video/97a51b1d0ae3eebc274fc05e76136872/)




Привет всем. Три дня пытаюсь поставить на ноут Стейбл. Одна маленькая победа у меня произошла: вчера он все-таки стал запускаться. Но при этом не могу разобраться с ошибками, которые постоянно выдает. Пожалуйста, помогите кто сталкивался.
P.S. Я самый древний чайник, пожалуйста помогите мне объяснив в примитивной форме, что от меня хотят :D и есть ли у меня надежда, что рано или поздно я смогу сгенерировать убогую картинку
Я установила Python 3.10 и Git
Далее по инструкции с Habr установила и извлекла сам Стейбл на диск Д.
В общем, запускаю.

ниже приведу в текстовом варианте
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: f2.0.1v1.10.1-previous-669-gdfdcbab6
Commit hash: dfdcbab685e57677014f05a3309b48cc87383167
Launching Web UI with arguments: --skip-torch-cuda-test --no-download-sd-model
D:\SD\system\python\lib\site-packages\torch\cuda\__init__.py:209: UserWarning:
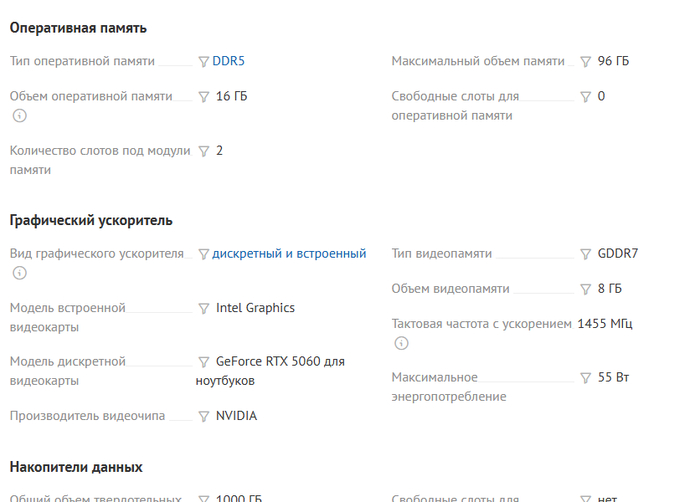
NVIDIA GeForce RTX 5060 Laptop GPU with CUDA capability sm_120 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_50 sm_60 sm_61 sm_70 sm_75 sm_80 sm_86 sm_90.
If you want to use the NVIDIA GeForce RTX 5060 Laptop GPU GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(
Total VRAM 8151 MB, total RAM 16084 MB
pytorch version: 2.3.1+cu121
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 5060 Laptop GPU : native
Hint: your device supports --cuda-malloc for potential speed improvements.
VAE dtype preferences: [torch.bfloat16, torch.float32] -> torch.bfloat16
CUDA Using Stream: False
D:\SD\system\python\lib\site-packages\transformers\utils\hub.py:128: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
Using pytorch cross attention
Using pytorch attention for VAE
ControlNet preprocessor location: D:\SD\webui\models\ControlNetPreprocessor
2025-09-28 09:52:00,089 - ControlNet - INFO - ControlNet UI callback registered.
Model selected: {'checkpoint_info': {'filename': 'D:\\SD\\webui\\models\\Stable-diffusion\\gonzalomoXLFluxPony_v40UnityXLDMD.safetensors', 'hash': 'd632a450'}, 'additional_modules': [], 'unet_storage_dtype': None}
Using online LoRAs in FP16: False
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 57.7s (prepare environment: 0.7s, launcher: 0.4s, import torch: 25.1s, initialize shared: 0.4s, other imports: 1.5s, load scripts: 8.5s, create ui: 13.8s, gradio launch: 7.3s).
Environment vars changed: {'stream': False, 'inference_memory': 1024.0, 'pin_shared_memory': False}
[GPU Setting] You will use 87.44% GPU memory (7126.00 MB) to load weights, and use 12.56% GPU memory (1024.00 MB) to do matrix computation.
Loading Model: {'checkpoint_info': {'filename': 'D:\\SD\\webui\\models\\Stable-diffusion\\gonzalomoXLFluxPony_v40UnityXLDMD.safetensors', 'hash': 'd632a450'}, 'additional_modules': [], 'unet_storage_dtype': None}
[Unload] Trying to free all memory for cuda:0 with 0 models keep loaded ... Done.
StateDict Keys: {'unet': 1680, 'vae': 248, 'text_encoder': 197, 'text_encoder_2': 518, 'ignore': 0}
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
K-Model Created: {'storage_dtype': torch.float16, 'computation_dtype': torch.float16}
Model loaded in 22.0s (unload existing model: 0.6s, forge model load: 21.5s).
Skipping unconditional conditioning when CFG = 1. Negative Prompts are ignored.
[Unload] Trying to free 3051.58 MB for cuda:0 with 0 models keep loaded ... Done.
[Memory Management] Target: JointTextEncoder, Free GPU: 1934.60 MB, Model Require: 1559.68 MB, Previously Loaded: 0.00 MB, Inference Require: 1024.00 MB, Remaining: -649.08 MB, CPU Swap Loaded (blocked method): 1056.00 MB, GPU Loaded: 696.68 MB
Moving model(s) has taken 3.21 seconds
Traceback (most recent call last):
File "D:\SD\webui\modules_forge\main_thread.py", line 30, in work
self.result = self.func(*self.args, **self.kwargs)
File "D:\SD\webui\modules\txt2img.py", line 131, in txt2img_function
processed = processing.process_images(p)
File "D:\SD\webui\modules\processing.py", line 842, in process_images
res = process_images_inner(p)
File "D:\SD\webui\modules\processing.py", line 962, in process_images_inner
p.setup_conds()
File "D:\SD\webui\modules\processing.py", line 1601, in setup_conds
super().setup_conds()
File "D:\SD\webui\modules\processing.py", line 505, in setup_conds
self.c = self.get_conds_with_caching(prompt_parser.get_multicond_learned_conditioning, prompts, total_steps, [self.cached_c], self.extra_network_data)
File "D:\SD\webui\modules\processing.py", line 474, in get_conds_with_caching
cache[1] = function(shared.sd_model, required_prompts, steps, hires_steps, shared.opts.use_old_scheduling)
File "D:\SD\webui\modules\prompt_parser.py", line 262, in get_multicond_learned_conditioning
learned_conditioning = get_learned_conditioning(model, prompt_flat_list, steps, hires_steps, use_old_scheduling)
File "D:\SD\webui\modules\prompt_parser.py", line 189, in get_learned_conditioning
conds = model.get_learned_conditioning(texts)
File "D:\SD\system\python\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "D:\SD\webui\backend\diffusion_engine\sdxl.py", line 89, in get_learned_conditioning
cond_l = self.text_processing_engine_l(prompt)
File "D:\SD\webui\backend\text_processing\classic_engine.py", line 272, in __call__
z = self.process_tokens(tokens, multipliers)
File "D:\SD\webui\backend\text_processing\classic_engine.py", line 305, in process_tokens
z = self.encode_with_transformers(tokens)
File "D:\SD\webui\backend\text_processing\classic_engine.py", line 128, in encode_with_transformers
self.text_encoder.transformer.text_model.embeddings.position_embedding = self.text_encoder.transformer.text_model.embeddings.p...(dtype=torch.float32)
File "D:\SD\system\python\lib\site-packages\torch\nn\modules\module.py", line 1173, in to
return self._apply(convert)
File "D:\SD\system\python\lib\site-packages\torch\nn\modules\module.py", line 804, in _apply
param_applied = fn(param)
File "D:\SD\system\python\lib\site-packages\torch\nn\modules\module.py", line 1159, in convert
return t.to(
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Я не научилась пользоваться Питоном сразу как это вошло в моду, но благо, научилась пользоваться переводчиком в далеком 2011.
Примерно понимаю, что какой-то CUDA (туда) несовместим с Пэйторч. (который, к слову, я через пип качала неоднократно зачем-то) Я вообще мало понимаю что и зачем я делала.
По ссылке я переходила и там качала пэйторч. Или что-то качала. В основном не интуитивно, а по каким-то там гайдам, на авось надеясь, что проблема решится.
В самой диффузии при генерации изображения:

RuntimeError: CUDA error: no kernel image is available for execution on the device CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Ниже приведу инфу по ноуту