Как ядро Linux управляет памятью приложений
Linux использует подсистему виртуальной памяти как логический слой между запросами приложений на память и физической памятью (RAM). Такая абстракция позволяет скрыть от приложения всю возню с тем, как именно устроена физическая память на конкретной платформе.
Когда приложение лезет по виртуальному адресу, который ему «выставила» подсистема виртуальной памяти Linux, аппаратный MMU поднимает событие — мол, тут попытались обратиться к области, за которой сейчас не закреплена никакая физическая память. Это приводит к исключению, которое называется «ошибка страницы» (Page Fault). Ядро Linux обрабатывает её, сопоставляя нужный виртуальный адрес с физической страницей памяти.
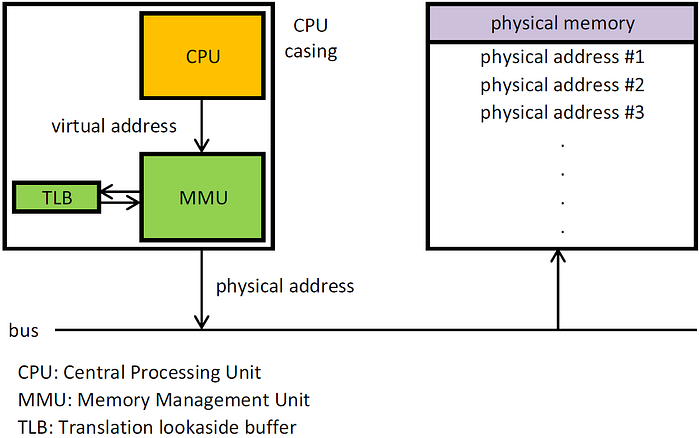
Виртуальные адреса незаметно для приложения сопоставляются с физической памятью за счёт совместной работы железа (MMU, Memory Management Unit) и софта (таблицы страниц, Page Tables). Информация об этих сопоставлениях ещё и кэшируется в самом железе — в TLB (Translation Lookaside Buffer), чтобы дальше быстро находить нужные физические адреса.
Страница — это просто группа подряд идущих линейных адресов в физической памяти. На x86 размер страницы — 4 КБ.
Абстракция виртуальной памяти даёт несколько плюсов:
Программисту не нужно понимать архитектуру физической памяти на платформе. VM скрывает детали и позволяет писать код, не завязываясь на конкретное железо.
Процесс всегда видит линейный непрерывный диапазон байт в своём адресном пространстве — даже если физическая память под ним фрагментирована.
Например: когда приложение просит 10 МБ памяти, ядро Linux просто резервирует 10 МБ непрерывного виртуального адресного диапазона. А вот физические страницы, куда этот диапазон будет отображён, могут лежать где угодно. Единственное, что гарантированно идёт подряд в физической памяти — это размер одной страницы (4 КБ).
Быстрый старт из-за частичной загрузки. Demand paging подгружает инструкции только в момент, когда они реально понадобились.
Общий доступ к памяти. Одна копия библиотеки или программы в физической памяти может быть отображена сразу в несколько процессов. Это экономит физическую память.
Команда pmap -X <pid> помогает посмотреть, какие области памяти процесса общие с другими, а какие — приватные.
Несколько программ, потребляющих в сумме больше физической памяти, могут спокойно работать одновременно. Ядро втихаря выталкивает давно неиспользуемые страницы на диск (swap).
Каждый процесс живёт в своём отдельном виртуальном адресном пространстве и не может вмешиваться в память других процессов.
Два процесса могут использовать одинаковые виртуальные адреса, но эти адреса будут отображены в разные места физической памяти. А вот процессы, которые подключаются к одному сегменту общей памяти (SHM), получат виртуальные адреса, указывающие на одни и те же физические страницы.
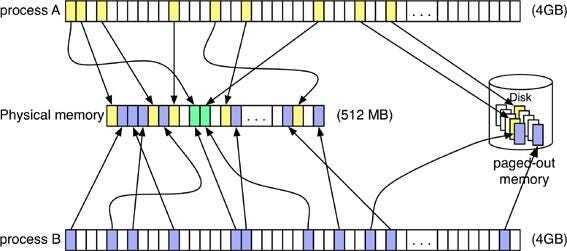
Виртуальное адресное пространство процесса состоит из сегментов разных типов: Text, Data, Heap, Stack, сегменты общей памяти (SHM) и области, созданные через mmap. Адресное пространство процесса — это диапазон виртуальных адресов, который ядро «выдаёт» процессу как его среду исполнения.
Каждый сегмент — это линейный диапазон виртуальных адресов с началом и концом, за которым стоит какой-то источник данных (backing store): файловая система или swap.
Ошибка страницы обрабатывается так: ядро поднимает физическую страницу, заполняя её данными из backing store. Когда памяти начинает не хватать, данные из физических страниц, используемых как кеш, сбрасываются обратно в свой backing store. Сегмент Text у процесса опирается на исполняемый файл в файловой системе. А вот стек, куча, страницы COW (Copy-on-Write) и shared memory — это анонимные (Anon) страницы, их хранилище — swap (дисковый раздел или файл).
Если swap не сконфигурирован, анонимные страницы невозможно выгрузить — им просто некуда уходить. В итоге они оказываются «прибиты» к физической памяти, потому что перенести данные с этих страниц во время нехватки памяти некуда.
Когда процесс вызывает malloc() или sbrk(), ядро создаёт новый сегмент кучи в адресном пространстве процесса и резервирует диапазон виртуальных адресов, по которому он теперь может легально ходить. Любое обращение к адресу за пределами этих границ приведёт к segmentation fault — и процесс отправится в небытие. Выделение физической памяти при этом отложено: она будет выделена только когда процесс реально обратится к этим виртуальным адресам.
Пример: приложение сделает malloc() на 50 ГБ, но реально коснётся (то есть вызовет page fault) только 10 МБ. Тогда физической памяти уйдёт всего 10 МБ.
Посмотреть виртуальное/физическое потребление памяти можно через “ps”, “pidstat” или “top”. Столбец SIZE показывает размер виртуального сегмента, а RSS — объём выделенной физической памяти.
Физические страницы, которые используются для сегмента Text или для файлового кеша (page cache), можно освобождать быстро — данные всегда можно снова получить из backing store (файловой системы). А вот для освобождения анонимных страниц сначала нужно записать их содержимое в swap, и только потом страница может быть освобождена.
Политика выделения памяти в Linux
Выделение памяти процессам регулируется политикой распределения памяти в Linux. В системе есть три режима, и выбираются они с помощью настройки vm.overcommit_memory.
1.Эвристический overcommit (vm.overcommit_memory=0)
Это режим по умолчанию. Ядро позволяет процессам «переборщить» с запросами памяти в разумных пределах — как решат внутренние эвристики. Они учитывают свободную память, свободный swap, а также память, которую можно быстро освободить, ужав файловый кеш или slab-кеши ядра.
Плюсы: учёт довольно мягкий; полезно для программ, которые обычно запрашивают больше памяти, чем реально используют. Пока хватает свободной памяти или swap, процесс продолжает работать.
Минусы: ядро не резервирует за процессом физическую память заранее. Пока процесс не потрогает (не обратится к) каждую страницу, никакой гарантии выделения нет.
(знаю, что нынче сравнения в формате плюсы/минусы в статье приравниваются к генерации нейросети, но пока это всё еще лучший вариант описания, так что...)
2.Всегда overcommit (vm.overcommit_memory=1)
С этим режимом процесс может запросить сколько угодно памяти, и запрос всегда будет успешным.
Плюсы: никаких ограничений — можно делать огромные выделения, даже если физической памяти и swap мало.
Минусы: те же, что и в эвристическом режиме. Приложение может сделать malloc() на терабайты при наличии нескольких гигабайт RAM. Пока оно не тронет все страницы, проблем нет — но как только тронет, может включиться OOM Killer.
3.Строгий overcommit (vm.overcommit_memory=2)
В этом режиме ядро запрещает overcommit и резервирует не только виртуальный диапазон, но и физическую память. Нет overcommit — нет и OOM Killer.
При Strict Overcommit ядро отслеживает, сколько физической памяти уже зарезервировано или закоммичено.
Поскольку Strict Overcommit не учитывает свободную память или swap, ориентироваться на free или vmstat бессмысленно. Чтобы понять, сколько памяти можно ещё выделить, смотрят в /proc/meminfo на поля CommitLimit и Committed_AS.
Текущую границу выделения считают так: CommitLimit − Committed_AS.
Настройка vm.overcommit_ratio задаёт предел overcommit’а для этого режима. Предел считается так: PhysicalMemory × overcommit_ratio + swap.
Значение можно поднять, увеличив vm.overcommit_ratio (по умолчанию — 50% от RAM).
Плюсы: OOM Killer не сработает. Лучше, чтобы приложение упало сразу при старте, чем посреди боевой нагрузки от OOM Killer. Solaris работает только так. Strict overcommit не использует free memory/swap для расчёта лимита.
Минусы: overcommit отсутствует полностью. Зарезервированная, но не используемая память простаивает — другие приложения её потрогать не могут. Новый процесс может не получить память, даже если система показывает много свободной RAM — потому что она уже «обещана» другим процессам.
Мониторинг свободной памяти становится хитрее. Многие приложения под Linux не умеют корректно обрабатывать ошибки выделения памяти — это может привести к повреждению данных и странным, трудно отлавливаемым сбоям.
Примечание: и в эвристическом, и в строгом режиме ядро резервирует часть памяти для root. В эвристике — 1/32 от свободной RAM. В строгом — 1/32 от процента реальной памяти, который вы задали. Это зашито в ядро и не настраивается. Например, на системе с 64 ГБ будет зарезервировано 2 ГБ для root.
OOM Killer
Когда система упирается в жёсткую нехватку памяти — файловый кеш уже ужат до минимума, все возможные страницы возвращены — но спрос на память не падает, рано или поздно заканчивается всё, что можно выделить. Чтобы не оставить систему полностью без возможности работать, ядро начинает выбирать процессы, которые можно убить, чтобы освободить память. Этот крайний шаг и называется OOM Killer.
Критерии выбора «жертвы» иногда приводят к тому, что убивается самый важный процесс. Есть несколько способов снизить риски:
Выключить OOM Killer, переключив систему на строгий overcommit:
sudo sysctl vm.overcommit_memory=2 sudo sysctl vm.overcommit_ratio=80
Исключить критический процесс из рассмотрения OOM Killer. Но даже это иногда не спасает: ядру всё равно нужно кого-то убить, чтобы освободить память. В некоторых ситуациях остаётся только автоматическая перезагрузка, чтобы восстановить работу системы.
sudo sysctl vm.panic_on_oom=1 sudo sysctl kernel.panic="number_of_seconds_to_wait_before_reboot"
Преимущества файлового кеша
Linux использует свободную память, которую сейчас не заняли приложения, для кеширования страниц и блоков файловой системы.
Память, занятую файловым кешем, Linux считает свободной — она доступна приложениям, как только им понадобится. Утилита free показывает эту память как свободную.
Наличие файлового кеша заметно ускоряет работу приложений с диском:
Чтение: когда приложение читает данные из файла, ядро делает физический IO и подтягивает блоки с диска. Прочитанные данные помещаются в файловый кеш, чтобы в следующий раз не ходить на диск. Повторное чтение того же блока — это уже логический IO (чтение из кеша), что резко снижает задержки. Кроме того, файловые системы выполняют упреждающее чтение (read-ahead): если замечают последовательный доступ, подгружают соседние блоки заранее, предполагая, что приложению они скоро понадобятся.
Запись: когда приложение пишет данные в файл, ядро кладёт их в page cache и сразу подтверждает запись (buffered write). Данные в кеше могут многократно обновляться (write cancelling), прежде чем ядро решит, что пора сбросить грязные страницы на диск.
Грязные страницы файлового кеша сбрасываются потоками flusher (раньше звали pdflush). Сброс происходит периодически, когда доля грязных буферов превышает пороговое значение — оно регулируется параметрами виртуальной памяти.
Файловый кеш улучшает производительность IO, скрывая задержки хранилища.
Преимущества HugeTLB и HugePages
Функция HugeTLB в Linux позволяет приложениям использовать большие страницы — 2 МБ или 1 ГБ вместо стандартных 4 КБ. TLB (Translation Lookaside Buffer) — это аппаратный кеш, который хранит отображения «виртуальный → физический» адрес. Когда нужной записи там нет (TLB miss), приходится идти в таблицы страниц в памяти, а это дорогая операция.
TLB-хиты становятся всё важнее из-за растущего разрыва между скорости CPU и памяти, а также из-за увеличения объёмов памяти. Частые TLB miss могут ощутимо просадить производительность.
TLB — ограниченный ресурс на чипе, и ядро Linux старается использовать его максимально эффективно. Каждый элемент TLB может быть настроен на работу со страницами разных размеров: 4 КБ, 2 МБ или 1 ГБ.
Если те же слоты TLB использовать под страницы покрупнее, можно покрывать куда большие области физической памяти:
4 KB pages: 64×4 KB + 1024×4 KB ≈ 4 MB
2 MB pages: 32×2 MB + 1024×2 MB ≈ 2 GB
1 GB pages: 4 GB
Плюсы:
Большие страницы уменьшают количество TLB miss, потому что один TLB-слот покрывает больше адресного пространства.
Требуется меньше записей в таблицах страниц, и уровней таблиц меньше. Это сокращает задержки на обход таблиц (2 уровня вместо 4) и уменьшает память, расходуемую на сами таблицы.
Large Pages фиксируются в памяти и не участвуют в выгрузке при нехватке RAM.
Снижается частота page fault: один fault может заполнить сразу 2 МБ или 1 ГБ, а не жалкие 4 КБ. Приложение «прогревается» заметно быстрее.
Если у приложения есть локальность данных, HugeTLB даст выигрыш. Но если оно читает байт там, байт здесь, или прыгает по огромной хеш-таблице, то обычные 4 КБ-страницы могут быть выгоднее.
Улучшается работа механизма prefetch: крупные страницы устраняют необходимость перезапуска чтения на границах 4K.
Минусы:
Большие страницы требуют предварительного резервирования. Администратор должен заранее выставить количество страниц: vm.nr_hugepages=<число>
(У Transparent Huge Pages предварительного шага нет.)
Приложение должно уметь работать с HugePages.
Например, JVM нужно запускать с флагом -XX:+UseLargePages, иначе большие страницы просто лежат без дела.
Посмотреть использование: cat /proc/meminfo | grep -E 'HugePages_|Hugepagesize'
Для HugePages нужны непрерывные физические участки памяти — 2 МБ или 1 ГБ. На системе, которая работает долго, большая часть RAM может быть уже разрезана на 4К страницы, и запрос на HugePage будет просто нечем удовлетворить.