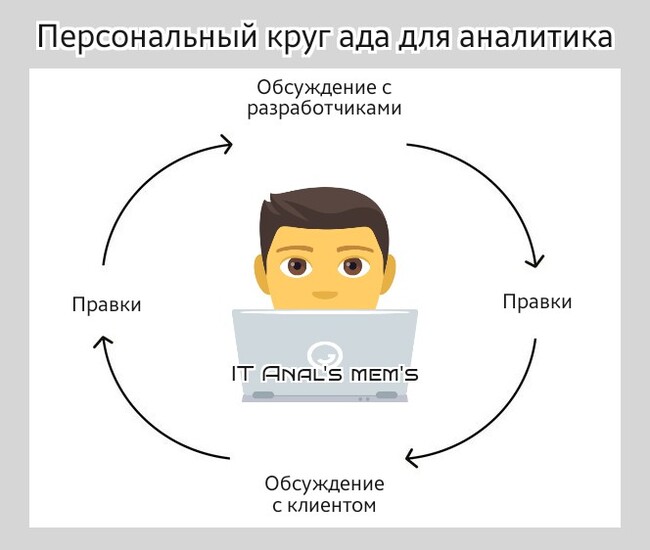


Проблема
Телеграм - Три мема внутривенно

Телеграм - Три мема внутривенно
Всем привет.
Небольшое предисловие. Я осознаю, что этим постом я вступаю на охрененно тонкий лёд. Если уж к моему предыдущему посту были претензии за то, что я посмел использовать HTTP 404, то уже интересно, какие комментарии последуют после выхода этого поста, в любом случае - you are welcome!
Но тут стоит уточнить, что все те подходы (разные), по которым мы проектируем сервисы - они разные как раз потому, что нет единых mandatory правил к архитектуре приложений, которым если не следуешь - твоя система ломается и больше никогда в жизни не заработает, даже если ты исправишь ее. Есть лишь РЕКОМЕНДАЦИИ, а их многие интерпретируют по-разному и это тоже нормально. Для кого-то свойственно не использовать коды ошибок вообще и передавать их в теле ответа с HTTP 200, для кого-то нет. Ни один из этих подходов не является не правильным.
И нет никаких технических ограничений в принципе. Ты можешь спокойно использовать метод GET для удаления объекта, если ты его так напишешь (не делайте так) или использовать метод PUT, вместо POST, для создания объекта (так уже можно, если понимаешь почему). Главное, чтобы ты понимал как эти тонкости реализации правильно применять. Если сомневаешься - используй методы по классике, хуже от этого он работать не будет.
Да, можно уже прям сейчас кидать тапками.
Теперь уже к основному телу сабжа. Сейчас расскажу про ряд лучших практик, которые можно применять. @VRock, ты как раз спрашивал по поводу конвенции о наименовании ресурсов, тут про это тоже будет.
1. Имя endpoint'а - это существительное, а не глагол. Это одна из самых распространенных ошибок, которые я когда либо встречал (и сам совершал, естественно). Например, было в моей практике и такое - POST /generateMultipleDocument.
Тут важно понимать, что метод - это уже глагол и еще раз дублировать его в наименовании эндпоинта не нужно.
В идеале, в данном варианте будет POST /documents
Не везде от этого можно избавиться, но в большинстве случаев всё-таки можно, если потратить время на придумыванием вариантов (опять же - по факту нейминг ни на что, кроме красоты и структурированности вашего проекта не влияет. А на сколько это важно - решать вам или вашей команде).
1.1. Используйте множественное число. В большинстве случаев, при проектировании методов, работающих с вашим ресурсом - эти методы будут работать не с единственный экземпляром этого ресурса, поэтому название эндпоинта должно быть во множественном числе.
Если же нужно указать, что из всего массива экземпляров ресурса вам нужно получить\обновить\удалить какой-то конкретный, то помещайте идентификатор этого ресурса в URL, передавая его в path.
Например, вот так:
/documents
/documents/{documentId}
Вместо:
/document
/document/{documentId}
1.2. Используйте "/" для обозначения иерархии и в принципе используйте вложенность ресурсов.
Например, если мы именуем наш ресурс, как users/{id}/playlists/{id}/songs - это значит у мы хотим работать со всеми песнями, конкретного плейлиста конкретного пользователя. И сразу понятна иерархичность этих ресурсов.
1.3. Не используйте "/" как закрывающий символ вашего URI.
Вариант users/{id}/playlists/{id}/songs сильно лучше, чем users/{id}/playlists/{id}/songs/
1.4. Используйте "-" для разделения составных слов.
Заглавные буквы использовать нельзя, поэтому привычный lowCamelCase нам не подойдет. Если писать всё слитно - очень не читабельно.
Поэтому вместо /applications/{id}/creditcardhistory, куда лучше использовать /applications/{id}/credit-card-history.
2. Не забывайте про версионирование микросервиса. Почти любой сервис с течением времени развивается и обрастает все большим количеством функций. Если сервис при создании получил версию 1.0.0, то при добавлении какой-нибудь логики в него, добавлении нового метода или полного рефакторинга - версия должна измениться.
Например:
host/v2/documents вместо host/v1/documents после внесения мажорной доработки.
Основные правила версионирования - в случае, если меняется логика незначительно, не добавляется/изменяется обязательность атрибутов, то инкрементируется минорная версия.
В случае если был полный или частичный рефакторинг, менялись обязательные параметры (например, добавлен новый атрибут, который является обязательным), возможно при добавлении нового метода (тут вопрос к разработчикам, в этом случае тоже мажорная версия повышается или т.к. это не влияет на работу подписантов то пофиг?) - инкрементируется мажорная версия.
В этом случае, все подписанты (системы, использующие ваш сервис) вашего микросервиса должны в обязательном порядке переехать на новую версию вашего микросервиса, иначе они не смогут взаимодействовать с ним. Например, если вы добавили обязательный атрибут, то они будут получать в ответ на каждый запрос ошибку, если не доработаются и не начнут его передавать, что приведет к полной поломке этого процесса.
Однако, это не всегда обязательно - в случае, если появляется такая мажорная доработка, но ваши подписанты не готовы дорабатываться одновременно с вами (причин этому может быть множество) - вы можете выкатить одновременно две версии микросервиса, v1 и v2 и поддерживать их обе. Те, кто доработался будут использовать v2, остальные предыдущую версию. Это несет неудобства и затраты, но в любом случае лучше, чем допускать неработоспособность интеграции. В дальнейшем, когда все ваши подписанты доработаются - поддержку предыдущей версии можно остановить.
Примечание: структура версионирования такова: первая цифра - это мажор, вторая цифра - это минор, третья цифра - это патч. Про первые две я уже сказал, а последняя используется только разработчиками. Насколько я понимаю, она повышается вообще каждый раз когда вносят изменения в сервис, но тут могу быть не прав.
3. Используйте пагинацию.
Отправка большого объема данных на фронт, в ответ на его запрос о получении информации по массиву каких-либо объектов, не самая лучшая идея. Как минимум, если вернуть ему тысячи объектов, лежащих в базе и попадающих под выборку - он столько все равно не отобразит, но очень задумается.
Поэтому принято выполнять пагинацию таких данных (от слова page - страница), т.е. возвращать ему часть всей коллекции в каждом запросе. Например - 15, 30, 50 элементов + информацию о текущем положении полученной информации в общей выборке. Почитать про это можно более подробно где-нибудь тут (первая попавшаяся ссылка, я не вчитывался, не реклама).
4. Используйте коды ответов HTTP правильно и эффективно.
Их достаточно много (https://developer.mozilla.org/ru/docs/Web/HTTP/Status) и их можно использовать по назначению. Все знать и использовать не обязательно, но вот примеры их использования
Использовать 201 "Created", вместо 200 "OK", в случае если вы в POST действительно создаете какой-то ресурс. Используется только в POST (ну и в PUT, в ряде частных случаев).
Использовать 204 "No Content", вместо 200 "OK" для DELETE. Это ответ на успешный запрос и он не будет возвращать тело, что и не нужно для данного метода.
Не забывайте использовать 401 "Unauthorized", 403 "Forbidden" и 404 "Not found" вместо безликого 400 "Bad Request", когда это уместно. Как правило 400 кодом пользуются когда нужно ответить на какую-то ошибку валидации или в случае возникновения бизнесовой ошибки, которую вы заранее можете предсказать (очень настоятельно рекомендую хотя бы дополнять код ответа еще и кодом бизнесовой ошибки в этом случае и желательно ее текстом (error.code и error.message соответственно).
Для валидации желательно тоже).
А для всего остального можно и специальные коды использовать.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.


Всем привет.
UPD. Опять получился длиннопост с большим количеством текста в формате моих пояснений - простите, но не представляю как по-другому можно что-то объяснить, вроде стараюсь не графоманить.
В этом посте, наконец, приведу один из примеров того, как может быть написано техническое задание (кто-то может придраться, что это не ТЗ, а какой-то другой вид документа - да, возможно, но как-то сформировалась привычка для упрощения, что ТЗ - это любой документ, в котором описывается техническая постановка задачи, которую разработчик должен реализовать), в котором описываются требования к методу получения информации по конкретному объекту.
Шаблонов, на самом деле много и от команды к команде отличаются. Где-то СА просто пишут, что "метод должен получать объект User из базы Users и дальше отдавать его вызывающей стороне" - и это вся постановка. В каких-то командах упарываются и пишут ТЗ на микросервис целиком, в связке статьи в git в формате asciidoc + swagger (yes, I like it и отдельно про это тоже расскажу).
Но в большинстве случаев принято что-то среднее между этими крайностями - системному аналитику важно описать следующее:
То, какие данные метод получит на вход и правила валидации для них;
То, что метод должен сделать с этими данными, т.е. какую бизнес-логику выполнить;
То, что метод должен вернуть в ответ вызывающей стороне.
Допустим, нам нужно описать какой-нибудь метод, который получает любую бизнес-сущность по ее идентификатору.
Один из шаблонов, позволяющий это описать выглядит так (к сожалению, приходится скриншотом, потому что пикабу не умеет в таблицы (или я не умею в таблицы на пикабу)):
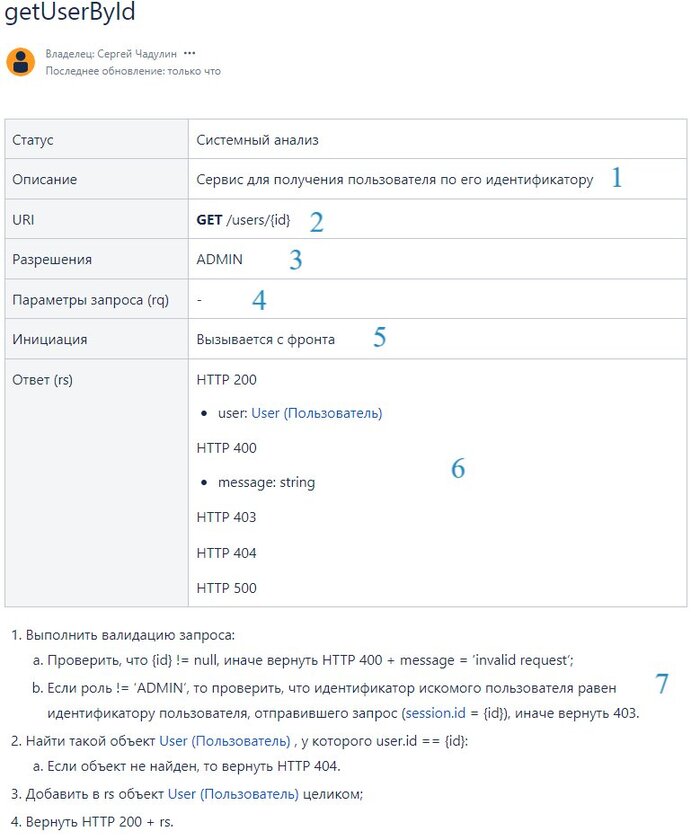
Если кто хочет посмотреть "вживую" или попользовать шаблон - вот ссылка на страницу моего конфлю (вроде должна работать).
Теперь по шагам:
Описание метода. Что он делает, для чего предназначен. Можно описать что-то конкретное, если сервис работает как-то специфично, такую краткую выжимку, что сторонним людям не приходилось анализировать его целиком;
URI или URL метода. Состоит из одного из типовых глаголов плюс сам путь, по которому данный метод будет доступен. Про всякие best practices нейминга расскажу отдельно, в комментариях под предыдущим постом спрашивали;
Разрешения или Permissions. Если у вас есть ролевая модель и вам нужно разграничить доступ к каким-либо ресурсам среди пользователей с разными ролями - то вступает в дело данная строка таблицы. В ней нужно перечислить те роли, у которых есть доступ до данного метода;
Параметры запроса, который должны (или могут) быть переданы на вход данного метода. Т.к. у нас очень простой метод, то у нас их нет. Единственный атрибут в виде идентификатора пользователя ( {id} ) передается напрямую в ссылке. Т.е. пример запроса будет просто выглядеть вот так: GET /users/22 - дай мне пользователя с идентификатором 22.
Пункт больше для удобства, в случае, если у вас большая система и много взаимодействующих компонентов. Описываете, кто будет дергать ваши метод. Как минимум это нужно для того, чтобы потом, когда вы будете дорабатывать их - было понятно влияние. В данном случае, если вдруг метод поменяется мажорным образом, добавится какой-нибудь новый обязательный параметр - вы не забудете доработать еще и фронт.
Параметры ответа. Все варианты того, что ваш метод вернет вызывающей стороне после выполнения своей внутренней логики. Перечисляем как успешные коды ответа и всё их содержимое, так и ошибочные.
Непосредственно описание бизнес-логики метода. Т.е. что метод должен сделать с атрибутами, переданными на вход, и что должен вернуть.
Теперь немного про описание самой логики работы любого сервиса. Кому-то может показаться это сложным, но на самом деле все немного проще. Вам просто логически нужно представить у себя в голове, что должен вообще в принципе сделать ваш метод и попытаться придумать - как он должен это сделать.
На этом примере - у вас стоит бизнесовая задача (например): есть админка со списком пользователей, администратор нажимает на какую-то конкретную карточку пользователя, с целью просмотреть всю информацию по нему - в этот момент, как раз фронт откроет отдельную экранную форму и вызывает наш метод, передавая туда идентификатор искомого пользователя (который он ранее получил из другого метода, который получает массив пользователей, что-то вроде GET /users), чтобы получить всю нужную информацию для отображения.
Далее представляем что наш метод должен сделать, чтобы вернуть информацию по этому пользователю. Самое логичное - надо сначала найти его. Для этого нужно залезть в таблицу с пользователями и найти такого пользователя, у которого идентификатор будет совпадать с тем, что нам передали в запросе. Нашли - круто, не усложняем и возвращаем успешный успех фронт с передачей в теле ответа всей необходимой информации.
А что делать если не нашли? Вообще, технически такого быть не должно, потому что это значит, что у фронта устаревшая или недостоверная информация и нужно с этим разбираться - откуда он взял идентификатор, которого не существует? Но представим, что после того как админ открыл страницу со списком пользователей и до того, как перешел в карточку конкретного - другой админ удалил ее. В этом случае надо вернуть ошибку, что такой объект не найден.
Ну и всегда (по моему мнению), во всех методах нам нужно валидировать входящий запрос до того, как начать основную бизнес логику. Потому что зачем нам это делать и тратить драгоценное время и ресурсы, если мы заранее знаем, что запрос не валиден? Т.е. как минимум нам нужно проверить rq на соответствие контракту, что все обязательные атрибуты пришли и пришли в корректном формате. Как максимум выполнить еще всякие кастомные валидации, по типу тех же проверок на роли.
Также заранее поясняю, что в ответе ссылка на объект User (пользователь) ведет на описание атрибутивного состава объекта (в моем примере в конфлю нет, потому что я этого не сделал, но на боевых задачах - да), поэтому не нужно расписывать и дублировать этот объект еще и тут. Однако, если вам нужно передать не весь объект, а только его часть, например, не возвращать на фронт какие-то пароли пользователей или другие конфиденциальные данные, чтобы их не "схачили" - то нужно отдельно это указывать.
И еще поясню немного про пункт 1.b - особенно внимательные наверняка про него что-нибудь скажут. Пока писал, подумал, что можно использовать этот метод не только для админа, но и переиспользовать его на случай, когда обычный пользователь хочет получить информацию по себе же, например, когда открывает свой профиль. Вместо того, чтобы делать отдельный метод - просто разграничиваем права. Если он захочет запросить информацию о ком-то другом (если фронт подведет), то ему вернется болт.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Здравствуйте. Лет 10 (а может, и больше) назад попадалась ссылка на сайт, где программист (или дизайнер) сделал сайт точно по ТЗ. Кажется, сайт был детского магазина. Прикол именно в том, что было сделано все максимально по ТЗ. Из того, что помню - танцующие под веселую музыку единороги (кажется гифка), куча блесток. Ссылка быстро стала вирусной, была на Хабре и т.д. А сейчас как сквозь землю провалилась. Возможно, сайт уже не живой, но, может быть, сохранился на архив.орг. Вдруг кто вспомнит
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509