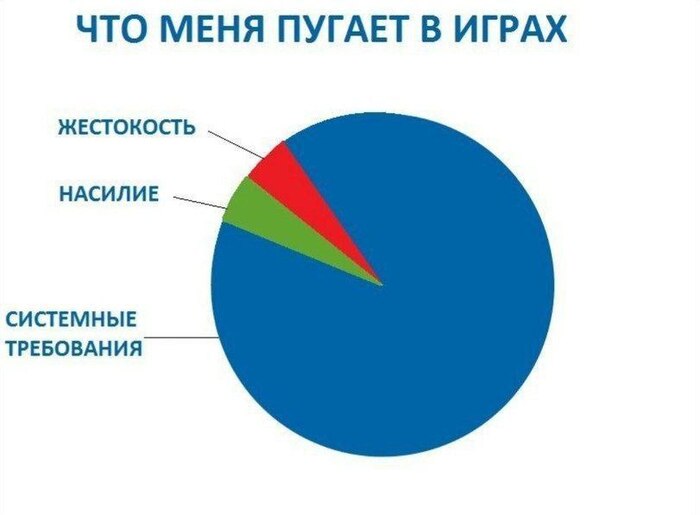
Обнови свой пк, нищеброд!


Показать полностью
2

Недавно завирусилась история о том, как кандидат вписал себе в резюме фиктивных два года опыта и прошел интервью на позицию в ИТ-компанию. Правда потом об этом узнали, и его вроде как уволили. Я не придал этому значения, пока мне не рассказали, что в одной онлайн-школе этому прям учат студентов, такая вот "гарантия трудоустройства". А на днях в одном из hr-чатов выложили фейковое резюме тестировщицы с 2 годами опыта, которая не смогла ответить ни на один технический вопрос.
В общем, весь этот треш оказался ближе, чем кажется. Не буду рассказывать, что обманывать нехорошо. Но я обратился за рекомендациями к Оле - HR в ИТ, карьерному консультанту и автору канала про карьеру, с которой мы трудоустроили уже ни один поток моих учеников.
Далее от ее лица.
Итак, последствия таких обманов могут быть разными:
(1) резюме могут закинуть по разным чатам и потом, чтобы найти работу, придется менять еще и фамилию (внутри одной сферы обычно тесно общаются и репутация дорога)
(2) в крупных компаниях есть службы безопасности, которые проверяют биографию еще до трудоустройства.
(у меня, кстати, был случай, когда клиентке отказали на последнем этапе из-за того, что данные из анкеты не совпали с реальностью)
(3) даже если все получилось, но в процессе работы информация вскрылась, могут и скорее всего уволят.
!(4) и что-то новенькое: hh.ru, на котором размещаются резюме, начал проверять точность информации и связываться с работодателями.
Поэтому поговорим о том, как можно привлечь внимание к себе, чтобы потом не уволили, как в этом случае:
(1) Начинать искать как можно раньше (когда изучена уже какая-то база), потому что то, что дают на курсах не всегда равно требованиям компаний. Чем больше смотрите вакансии и общаетесь, тем лучше понимаете, что нужно рынку.
(2) Использовать нетворкинг - знакомиться с людьми, которые работают в тех компаниях, куда вы хотите. Даже просто написать и попросить зарефералить. Теория с рукопожатиями тоже работает (у меня так много клиентов и знакомых нашли работу)
*кстати, консультант тут тоже обычно помогает и закидывает резюме по своим каналам (это, конечно, не гарантия успеха, но повышает конверсию)
(3) Резюме должно быть продумано до мелочей, из самого базового:
➡️ название должности должно соответствовать названиям вакансий, т.е не "специалист", а максимально конкретно;
➡️на первом месте должен быть опыт по той вакансии, на которую вы хотите, даже если это учебный опыт;
➡️ расписать подробно навыки, которые вы получили на обучении, лучше сразу с примерами из практики.
(4) Брать из предыдущего опыта все навыки, которые могут быть полезны. Смена направления — это не начинать с нуля, всегда есть переносимые навыки. Например, опыт ведения коммуникации и работа в команде, который есть у всех, и другие soft skills. Успех поиска 50/50 зависит от hard и soft skills.
(5) Использовать сопроводительные письма и писать вдумчивые отклики на позиции (спам-рассылка скорее всего не даст результата). А вот резюме + нормальное сопроводительное можно отправлять не только на hh, но и напрямую в компании, даже если вакансии нет, вас могут добавить в базу и написать позже.
*я всегда читаю, когда вижу, что человек постарался, а иногда даже даю обратную связь и помогаю скорректировать.
(6) Использовать разные источники поиска, в том числе рассматривать стажировки, после которых можно трудоустроиться (иногда это быстрее, чем искать вакансии).
Да, рынок очень поменялся за последние несколько лет, и все эти шаги объединяет активность и инициативность. Пробуйте разные гипотезы, потому что если не делать, то точно не получится. И пишите в комментариях, если нужен подробный разбор того, как правильно составлять резюме.
❕Сегодня хочу поговорить на очень спорную тему, я бы даже сказал философскую. Отчасти из-за нее, возникает очень много непонимания между коллегами, работающими в одном и том же (казалось бы) "АйТи", но почему-то имеющих очень разное представление о процессах разработки и о том, что каждая роль команды должна выполнять. Особенно это часто всплывает в моих постах на этом ресурсе, в комментариях - это такой хороший срез из разных уголков нашего отечественного IT.
И это большая тема для постов и для рассуждений. Но сегодня сосредоточимся на небольшой части этой темы, касающейся непосредственно системных аналитиков.
Давайте поговорим о том, какие есть подходы к написанию ТЗ и степени его проработки на примере описания тех же микросервисов\их методов.
❕Представим, что мы является системным аналитиком в команде и нам поставили задачу - реализовать личный кабинет пользователя.
Т.е. когда пользователь нажимает на какую-нибудь иконку профиля в приложении или там на кнопку "Профиль" - ему должна открываться экранная форма, в которой ему отрисовывается определенный набор полей и эти поля заполняются информацией. Также допустим, что у нас сам объект "Пользователь" уже есть в системе, атрибутивный состав понятен и нужно только реализовать процесс получения данных о пользователе на фронт по его идентификатору (ТЗ на фронт, на экранную форму и на интеграцию его с бэком опустим).
Какие есть варианты написания ТЗ для данной задачи?
1️⃣Самый минимальный уровень детализации. Это когда системный аналитик просто ставит задачу на разработку Джире (ну или в рамках небольшой страничке в конфлю\ворде, в зависимости от того, как принято) и в постановке этой задачи пишет что-то вроде "Требуется реализовать процесс получения данных о пользователе и передачу ее с бэка на фронт по REST-запросу. Со стороны фронта требуется создать новую экранную форму приложения - "Личный кабинет" или "Профиль пользователя". Со стороны бэка требуется реализовать новый метод, который будет использовать фронт для запроса информацию по пользователю (и, скорее всего, перечисляет набор полей, которые должны передаваться на фронт в формате "Фамилия", "Имя" и т.д.)". Усё
Я не утрирую - это один из вариантов реального "ТЗ" на эту задачу. Плюсом к этому может быть описан пользовательский сценарий в вольном формате или в формате UC (и то это будет в лучшем случае). Т.е. по сути в рамках такого процесса разработчик получает из полезной информации - только состав полей, передачу которых ему нужно реализовать по запросу с фронта, и то только их наименования.
2️⃣Вариант с немного лучшей детализацией. В этом формате системный аналитик уже пишет ТЗ в каком-либо формате, в рамках которого указывает, что: "Требуется реализовать новый метод GET /users/{id}, указывает полноценно параметры, которые данный метод должен потреблять на вход и параметры, которые он должен отдавать на выходе." Плюс может описать, также как в предыдущем пункте, верхнеуровневый сценарий взаимодействия с этим методом.
Уже чуть лучше и чуть больше полезной информации для разработчика, правда?
3️⃣Вариант с достойной реализацией. Этот вариант обычно используется на большинстве проектов ФинТеховских и я считаю его достаточным для того, чтобы написать хорошее, качественное ТЗ и разгрузить разработчика так, чтобы он не думал о деталях реализации, хотя бы алгоритмических и системных (то, к чему нужно стремиться со стороны СА, имхо).
В рамках этого варианта будет всё из предыдущих + будет полностью описана логика работы данного метода, как бизнесовая, так и техническая. Будут описаны все корнер-кейсы, правила обработки ошибок, варианты того, что может вернуться в ответе (кроме успешного ответа, еще и все варианты негативных). Логика может быть описана или на уровне псевдокода или просто словами - конкретно это уже не имеет значимой роли, главное то - что эта логика пошагово и подробно описана.
Пример подобного описания я приводил ранее в своих постах. Я топлю всегда как минимум за этот вариант описания любых задач - что бэковых, что фронтовых, любых. Избавить разработчиков от лишней работы с точки зрения проработки алгоритмов и логики, если мы вполне это можем сделать сами - у них хватает работы и так, можете поверить.
4️⃣Более полноценный вариант придумать не могу =)
Плюсом к 3 пункту дополнительно описывается еще и swagger-спецификация микросервиса в целом и конкретных эндпоинтов в частности. Кроме того, что это просто удобно, наглядно и очень детально - эту спецификацию разработчики могут использовать, чтобы сконвертировать ее напрямую в готовый код с расписанными классами и эндпоинтами, останется "только" докрутить бизнес-логику и метод готов (Тут просьба поправить меня коллегам, которые более глубоко погружены в разработку - так ли это или есть еще какие-то бенефиты для разработчиков. Могу в этом предложении быть не прав, пишу исходя из того, как мне это объясняли).
Кроме этого, такой подход хорошо использовать в парадигме swagger-first, особенно когда у вас есть насыщенный и активный процесс кросс-командной разработки. Отдать другой команде сваггер аналитику куда проще и быстрее, чем отдать полноценное ТЗ на сервис - хотя бы просто по времени. А большего им и не нужно (потому что им пофиг на то, как работает ваш сервис внутри, главное понять, как вас вызывать и что вы вернете в ответе).
А если это все еще и использовать в связке с asciidoc-документацией, выкладывании ее в git- ммм, сказка просто. Как вспоминаю об этих процессах, наворачивается скупая слеза ностальгии - как же это было здорово! Жаль, что я встретил это ровно в одном проекте, а во всех последующих так и не смог продавить внедрение чего-то похожего.
И я вполне понимаю почему (например, очень удобно когда ты почти не тратишь время и ресурсы на написание глубокого ТЗ - достаточно пары фраз, а дальше нехай разработчик разбирается. И чем дольше пишешь в таком режиме, тем больше он тебя поглощает). Но кроме этого есть и множество других, о чем поговорим в следующий раз.
А с какими процессами и подходами работаете вы?
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-, хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
Я раскрыл смысл смены процессора 12-го и 13-го поколения на 14-ое, что есть только одни смысл-это поддержка и возможность обновления с Windows 10/11 до будущей Windows 12 в 2024 году (у нас разве-что неофициально привезут с других стран лицензию 12-ки).
В новые процессоры Intel добавили компонент «Microsoft Pluton», что без него 12-ка работать не будет.
А в 13-ом поколений и старее просто не будет обновления, вот я и выяснил смысл покупать и замены процессоров Intel на 14-ое поколение.
Из-за него меняют процессор на 14-ое поколение.
Я просто читал много комментариев на подобную тему, что «нет смысл менять процессор на новый» и «пока игры хорошо тянут», поэтому я и написал пост не просто так.
С Ixbt-источника о новой ОС Windows:
В данном случае всё просто: с выходом новой версии Windows немало пользователей решает обновлять свои ПК, а для Intel это означает дополнительные продажи процессоров (и не только).
Ранее, напомним, Intel заявляла, что выпускает свои мобильные CPU Meteor Lake в том числе для следующего поколения Windows. Судя по имеющимся утечкам, называться система будет Windows 12.
Meteor Lake, напомним, будут представлены в декабре, а первые ноутбуки на их основе, видимо, появятся в начале 2024 года. Эти процессоры, кроме прочего, впервые для Intel будут иметь аппаратный блок для работы с ИИ, а в Windows 12, как ожидается, также будет сделан большой упор на искусственный интеллект.

А вот те же Intel Core i5 14500, Core i7 14700, Core i9 14900 (но на фото 13-го поколения для илюстраций).
Продолжаем список тем и вопросов, ответы на которые нужно знать, чтобы пройти собеседование на позицию джуниора.
Еще небольшое предисловие - судя по комментариям к предыдущему посту, не все понимают, что не обязательно, что ВСЕ эти вопросы попадутся вам одновременно. Это наиболее вероятные вопросы, которые вам зададут ( по крайней мере актуально для ФинТех сферы). Ну и опять же, всё очень зависит от интервьюера, его опыта и тех целей, которые ему поставило руководство компании\проекта, на интервью.
Есть еще очень хороший подход к интервью, когда ты задаешь вопросы по каждой теме, и чем больше правильных ответов дает соискатель - тем глубже ты копаешь в эту тему, пока его знания по вопросу не иссякнут. Это позволяет не просто прогнать человека по заданным темам, которые нужны компании, но и в целом представить его уровень более детально (плюс так куда интересней для всех участников собеса).
Более техническая часть собеса:
Архитектурно-интеграционные вопросы:
Что такое клиент-серверная архитектура? Что такое тонкий и толстый клиент, чем они отличаются? (Тут никто не ждет прям уверенных технических знаний и деталей реализации того или иного подхода, но в общих чертах знать нужно).
Что такое HTTP? Какие основные методы HTTP вы знаете? Какие функции они выполняют? Расскажите про структуру HTTP-сообщений. (Если вы перечислите основные методы и скажете, что у сообщения есть заголовок, строка и тело - это уже, в целом, неплохо. Если знаете больше этого, вообще замечательно).
Что такое REST? Какие основные принципы у него есть? Какие методы есть в REST? В чем разница между GET и POST запросом?
В каких местах (четырех) мы можем передать атрибуты в запросе? (Path, Body, Query, Header).
Что вы знаете про концепцию CRUD?
Что такое идемпотентность? Какие методы являются идемпотентными?
Что такое синхронные и асинхронные интеграции? В чем между ними разницы? С помощью чего можно их реализовать?
Можно ли реализовать асинхронную интеграцию через REST? (Вряд ли этот вопрос будут задавать, если вы не ответите на предыдущие. Это скорее со звездочкой и не обязательный)
Что такое очередь сообщений? Как передаются сообщения через очередь? Какие очереди сообщений есть и в чем между ними разница? (Если расскажете про PUSH/PULL-стратегии - плюсик в карму обеспечен)
Что такое гарантированная доставка сообщений и какими механизмами ее можно обеспечить?
Какие вообще способы интеграции существуют? С какими из них приходилось работать? В чем их преимущества и недостатки? (Интеграция через обмен файлами, через общую БД, через веб-сервисы и обмен сообщениями)
Базы данных:
Что такое базы данных? Какими они бывают? С каким БД приходилось работать?
Что такое ER-диаграммы? Приходилось ли их проектировать?
На какой уровень оцениваете свой уровень владения SQL? С какими инструментами по работе с БД знакомы?
Ну тут могут конечно и про формы нормализации спросить, но уже лишнее, как по мне. Я обычно спрашиваю больше про опыт проектирования БД в целом. Приходилось ли проектировать базу в целом и под конкретные задачи в частности, каким образом это было сделано.
Различные задачки:
Тут вообще кто во что горазд в плане придумывания задач. В среднем, вам дадут умозрительное задание на проектирование какой-либо системы и попросят выделить основные классы этой системы (возможно, предварительно нужно будет собрать требования с интервьюера), спроектировать интеграцию между частями этой системы/интеграцию с внешними системами (плюс объяснить выбор технологии интеграции). Основной упор на ваши размышления, в основном именно в подобных вопросах можно понять уровень соискателя, потому что все остальные можно заучить. А тут проверяется именно понимание того, о чем вы рассказывали предыдущую часть собеседования.
Небольшие оффтопные вопросы:
Расскажите, что такое авторизация, аутентификация и идентификация? Чем они отличаются друг от друга? (почему-то один из самых любимых вопросов некоторых людей)
Чем верификация отличается от валидации?
Приходилось ли работать с JIRA\Confluence?
Конечно, так получается, что если вы знаете ответы на все эти вопросы, или больше 80-90%, то как будто бы вы уже не джун. Но чем лучше вы отвечаете, чем лучше вы соответственно подготовились - тем больше вам зададут вопросов (в нормальном интервью, а не шаблонном). Что очень сильно повысит ваши шансы получить оффер и выделиться среди других кандидатов.
Поэтому, конечно, можно, и зачастую нужно, пробовать собеседоваться, при наличии знаний, которые позволят ответить вам на половину из этих вопросов - шансы всё еще будут, плюс вы получите опыт прохождения собеседований (что само по себе очень важно) и определите те темы, про которые часто спрашивают, но в которых вы пока еще не сильны.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-,хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
Я как сраный старпер тупо в ит (22 года стаж, но нихера не знаю). Забейте на языки. Думайте о предоставлении данных. Язык программирования - херня, инструмент типа отвёртки. А от структуры данных зависит и платформа, и архитектура, и язык.Я что ща модно? Питон? Душите его. почитайте, бля, программной с дипломом.