

Почему английская орфография такая странная-4: love
Продолжаю цикл об истории английской орфографии. Под одним из предыдущих постов @RobbinBobbin задал следующий вопрос:

На вторую его часть я уже подробно отвечал раньше, а сегодня мы поговорим о том, почему по-английски пишет London, love и come, а не Lunden, luve и cume.
В XII-XV веках в Западной Европе господствовало готическое письмо. Оно отличается характерными угловатыми ломаными начертаниями, и читается довольно легко. Однако буквы i, u, n и m состояли из одинаковых вертикальных черт (такая черта называется minim), и, если две-три буквы из этого набора шли одна за другой, всё это сливалось в сплошной штакетник.
Чтобы не быть голословным, вот пример из чешской Оломоуцкой библии (1417 г.):

Здесь написано: Na pocżatcie stworzil boh nebe y zemi. Ale zemie była neużitecżna. a prazdna. a tmy
Видно, что при таком начертании zemi и zenn выглядят одинаково. Поскольку слова zenn в чешском нет, читатель вряд ли ошибётся в этом месте. Но всё же некоторые неудобства это создаёт. Например, попробуйте записать так слово minimum.
Скорее всего, ошибка такого рода частично ответственна за трансформацию арабского слова samt «направление» на европейской почве. Форма semt была неверно прочитана как senit, и со временем трансформировалась в привычный нам зенит. Кстати, множественное число от samt звучит как sumūt. С определённым артиклем – as-sumūt, что дало нам ещё один термин.
Именно эта особенность готического письма привела к тому, что над i стали ставить точки, древние римляне этого не делали. Также у римлян не было букв j и u. Они возникли как графические варианты i и v в средневековой Европе. Так, в средневековых английских манускриптах чаще всего v писалось в начале слова (vp = up), а u в середине (haue = have). Статуса отдельных букв j и u добились далеко не сразу. В Англии это произошло лишь в середине XVII века (а в случае заглавного J даже позже).
Чтобы избежать «штакетников» в XIV веке вместо u перед m, n и u, хоть и не вполне последовательно, начали писать o. То есть, luue «любовь» стало записываться как loue, а cume «приходить» как come.
Эпоха Возрождения принесла ориентацию на античные образцы в том числе в начертании букв. В книгопечатании антиква, появившаяся в конце XV века, постепенно вытеснила готический шрифт, окончательно и повсеместно победив лишь в середине XX. Кстати, к готам готическое письмо не имеет никакого отношения, так его обозвали итальянские гуманисты, под «готическим» подразумевая варварский, противопоставленный античному.
К тому времени, когда в Англии перешли на новый шрифт, где смешения букв возникнуть не могло, орфография уже достаточно консервировалась, и написания типа love так и сохранили o вместо u.
В XVII в южных английских диалектах краткий u (ʊ) в части позиций стал изменять звучание и понижаться. Другими словами, love стало произноситься как лав, а не лув (на севере, впрочем, сохранилось старое произношение).
Вот несколько слов, в чьём написании на месте этимологического u было введено o:
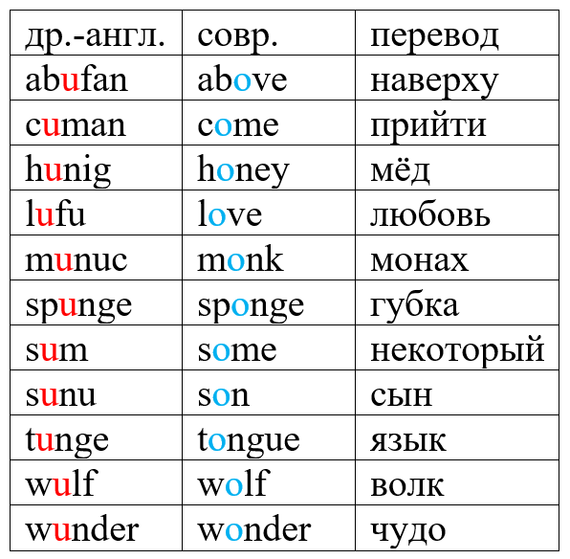
Лондон до определённого момента тоже преимущественно писался как Lunden или Lundene, Lundenne. В XIV веке начинают преобладать написания вида London, Londone, Londun, Londoun и так далее. В конечном итоге побеждает современное London ['lɐndən].
Изменения в орфографии были непоследовательными, в большом количестве слов -o- на месте -u- не закрепилось (хотя в части рукописей встречается). Например, hunt, thumb, run, under и так далее.
В нескольких примерах написание -o- и -u- стало использоваться для различения омонимов (в этом случае омонимы становятся омофонами, то есть словами, которые произносятся одинаково, но пишутся по-разному): son «сын» – sun «солнце», some «некоторый» – sum «сумма».
Отмечу также, что есть ряд слов, в которых пишется -o-, произносящееся как а (ɐ), но -o- в них не орфографическое, а восходящее к древнеанглийскому долгому ō. Это, например, mother, brother, other. В них звук ō перешёл в ʊ, а затем в ɐ, но орфография осталась прежней.
В завершение забавная иллюстрация из Оломоуцкой библии. Попробуйте догадаться, что за сюжет на ней изображён.

Предыдущие посты по теме:
Почему английская орфография такая странная: gh
Почему английская орфография такая странная-2: island
Почему английская орфография такая странная-3: -tion
Источники:
Crystal D. The Cambridge Encyclopedia of the English Language. Cambridge, 1995. Pp. 260-261, 263.
Cummings D.W. American English Spelling: An Informal Description. Baltimore – London, 1988. Pp. 245-247.
The Cambridge History of the English Language, Vol. 2. 1066-1476. Cambridge, 2006. Pp. 36, 38.



















Наука | Научпоп
9.2K поста82.7K подписчика
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.