Где взять бесплатный англо-русский словарь для использования в своем приложении?
Понадобился мне простой англо-русский словарь для кое-каких личных говнокодерских нужд. На первый взгляд проблема не большая - сейчас огромное количество не то что там словарей - полноценных переводчиков. Google, Yandex, Abby и другие предлагают свои решения, да еще и бесплатные до определенного количества запросов в сутки.
Казалось бы, бери любой и радуйся, за пределы бесплатного лимита вряд ли выйдешь. Но есть одно НО. Вот пункт из условий использования словаря яндекса:

А это именно то, что я хотел делать. Обрабатывать, сохранять и видоизменять полученные через севис данные. И такой пункт, практически слово в слово встречается во всех популярных словарях и переводчиках. Пичалька. Поэтому вариант со словарями от больших парней отпал.

Пошерстив форумы, я во-первых, понял что я не один такой, кто ищет бесплатный словарик и во-вторых наткнулся на несколько словарей, которые распростаняются либо под лицензией GNU GPL, либо вообще без упоминания каких-либо лицензий.
Проблема всех найденных словарей для меня заключалась в том, что все они были отфортматированны в стиле "кто во что горазд" и мне не удалось найти ни одного словаря в удобном формате, где бы слово, часть речи, транскрипция и варианты перевода были бы четко отделены друг от друга. В идеале я бы хотел иметь под рукой sql дамп с таблицей слов, которую можно использовать по своему усмотрению.
Из всех найденных словарей я выбрал словарь Мюллера 7 редакции. Выбор пал на него, потому что на сайте я обнаружил информацию о том, что прав на ограничение распространения этой версии словаря ни у кого нет.
Я скачал исходники электронной версии словаря и взял за основу для своей работы базовую версию, не обработанную скриптами.
Выглядит это так:

Или так:

С этим и начал работать.
Итак, что я хочу получить?
1. Нужен ресурс, api, куда я смогу отправить запрос с указанием слова целиком или его части, и получить ответ со всеми словами начинающимися на эту строку + переводы.
2. SQL дамп таблички с данными всех слов с переводами, чтобы можно было залить его в нужный прокет.
3. Табличка должна быть определена следующим образом:
source - исходное слова на английском
pos - part of speech - часть речи
transcription - транскрипция
translations - массив переводов для одного значения текущей части речи.
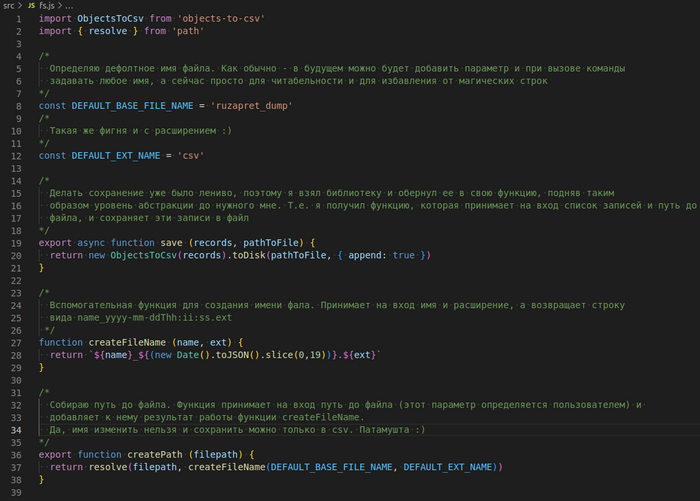
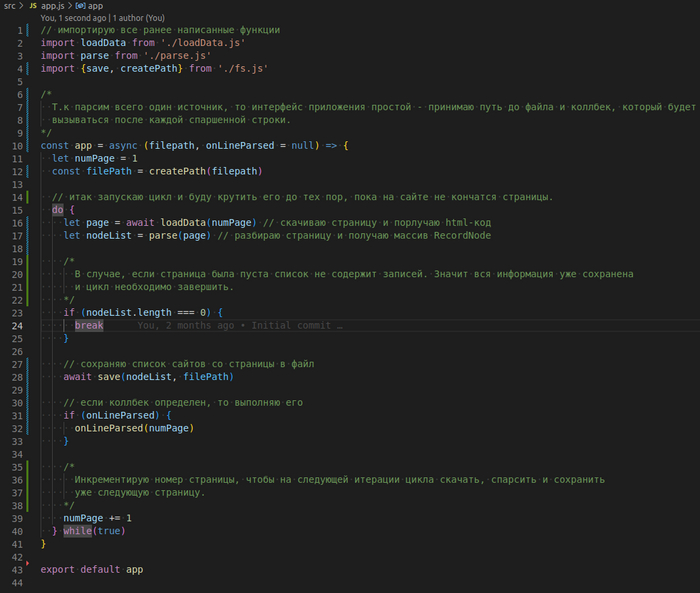
Заабегая вперед покажу, что вышло в итоге вышло и как выглядит.
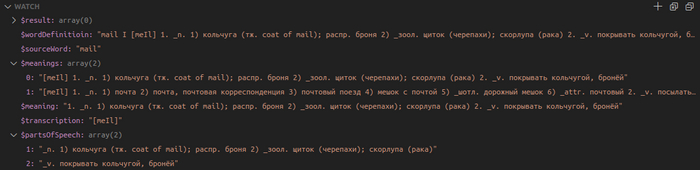
Вот, например, слово mail.
Табличное представление:

API отдает так:

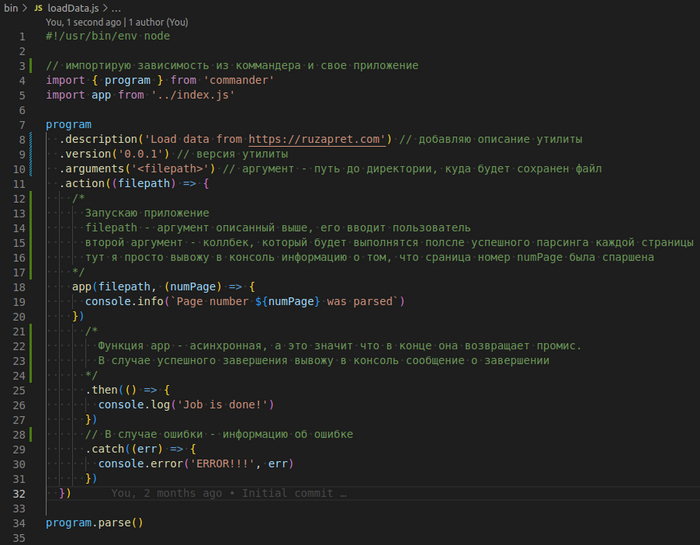
Стэк: php 8.1 + symfony 6.1 + api platform + postgres 13.3 + docker
Теперь опишу самое интересное - процесс парсинга словаря.
Из приведенных выше примеров исходного словаря видно, что разные слова могут иметь разный набор элементов: разное количество значений, разное количество частей речи и разное количество вариантов перевода.
Причем наличие всех элементов не обязательно.
Слово mail, например, содержит все возможные элементы, а слово password содержит минимально возможный набор элементов для определяния слова и его перевода. А слово passport содержит 2 варианта перевода, но одно значение и одну часть речи.
Вобщем на этом этапе становится понятно, что с одной стороны количество элементов от случая к случаю разное, но с другой стороны (кто бы мог подумать) есть закономерности.
Чтобы разбить слова на составные части, нужно сначала четко их определить.
1. Исходное слово (source) - слово которое и переводится. Во всех случаях стоит в самом начале. Может содержать несколько слов.
2. Значения - разные значения одного слова. Например mail может иметь значение кольчуга, а может почта. Если значений у слова несколько, то они обозначены римскими цифрами.
Значения всегда идет сразу после итсходного слова
3. Транскрипция (transcription). Идет либо после исходного слова, либо, если значений больше одного, после римской цифры. Определяется внутри значения.
4. арабская цифра с точкой - обозначает разные части речи внутри одного значения. Например слово mail в рамках значения "почта" может быть существительным и иметь значение собственно "почта", а может быть глаголом и иметь значение "посылать по почте".
Не обязательный элемент. Если присутвствует, то идет после транскрипции.
5. Часть речи - part of speech (pos) - части речи внутри одного значения. Например слово mail в рамках значения "почта" может быть существительным и иметь значение собственно "почта", а может быть глаголом и иметь значение "посылать по почте".
Если частей речи больше одной, то обозначаются они арабской цифрой с точкой. Идут после транскрипции.
6. Переводы (translations) - варианты перевода слова в рамках одного значения и одной части речи. Например слово mail, как существительное может иметь переводы "почта, корреспонденция, мешок с почтой" в рамках одного значения и "кольчуга, скорлупа" в другом.
Варианты перевода могут быть разделены арабскими цифрами со скобкой, запятыми или точками с запятой. В моей табличке все эти значения попадают в один массив.
Если наложить объяснения выше на пример слова mail из словаря, то полчим следующее:

Кроме описанных выше базовых принципов есть еще несколько вещей, на которые стоит обратить внимание.
Изначально исходный словарь создавался, чтобы печататься в книге, соответствено и верстался он так, чтобы хорошо выглядеть на странице. В электронном виде, судя по всему, верстка сохранилась и слишком длинные строки просто переносятся на следующую. В каком конкретно месте строки будет перенос пердсказать невозможно.

При переводе словаря в электронный вид пострадала транскрипция. Вот, что по этому поводу написано на сайте:
В словаре, для правильного отображения фонетической транскрипции на текстовых терминалах, символы IPA, не имеющие аналогов в стандартном 8-битовом кириллическом шрифте, заменены на другие, близкие по звучанию, либо начертанию. Полная таблица перекодировки приведена ниже.
И последнее на что я обратил внимание перед парсингом: части речи обозначенны как _n., _v., _a. и т.д. Это не очень информативно для человека, поэтому подобное обозначение нужно будет заменить на понятные noun, verb и тд.
Это все особенности на которые нужно обратить внимание и проблемы, которые нужно решить, чтобы перевести этот словарь в формат, который я описал выше.
Естественно, есть еще некоторые вещи, которые могут броситься в глаза: пометки в переводах вроде _зоол., _шотл. и так далее, некоторые примеры использования слов внутри массива translations будут разбиты по запятой и др. Все это я решил пока оставить как есть и подумать об этом позже.
Задачи поставлены, проблемы обозначены. Далее - решение.
Такую комплексную задачу решить сходу не так-то просто. По крайней мере для меня.

Поэтому одну большую и сложную задачу необходимо свести к набору маленьких и простых, каждая из которых решается во-первых легко, а во-вторых независимо от других задач.
1. Чтение из файла.
Читать файл построчно и извлекать слова из него в массив. Слова сверху и сниху ограничены строкой "_____". Результат - массив с набором необработанных слов-строк выглядит примерно так:

Как видно в процессе чтения из исходных определений слов в словаре убраны все переносы строк. Сделано это для того, чтобы при дальнейшем анализе слова не думать о том зачем тут стоит перенос строки - для отделения одного элемента от другого или просто для красоты.
Далее работаем с каждым словом из массива, который получился в предыдущем пункте. Рассматриваем процесс на примере слова mail. Перед началом работы память скрипта выглядит так:

2. Определение source - исходного слова
Слово, которое переводится. Начинается с начала строки и заканчивается там, где начинается описание значений. Описание значений начинается либо с транскрипции, если значение одно, либо с римской цифры I, если значений много. Т.е. исходное слово длится до последовательности символов " [" либо " I [".
После выполнения этого шага в памяти появляется переменная $sourceWord.

2.1. Удаление уже определенной части из строки
После определоение каждого элемента его нужно удалять из сходной строки, чтоб в дальнейшем он не мешал работе.
На этом этапе получаем строку со значениями $meaningString.Далее будем работать с ней.

2.2. Разбитие строки на значения
Как было объяснено выше - слово может иметь несколько значений. Описание значений, если их несколько, начинается с римской цифры I, II, III, IV и тд.
На этом этапе нужно получить массив значиений, поэтому разбиваем $meaningString на части по римским цифрам. В итоге содержимое памяти после этого шага выглядит так:

3. Определение значений
Значений может быть разное количество, но не меньше одного, поэтому $meanings всегда массив. А это значит, что перебираем его в цикле. Все значения $meanings обрабатываются по одному алгоритму.
Содержимое памяти на первой итерации цикла по массиву значений выглядит так:

3.1. Определение транскрипции
Транскрипция с точки зрения парсера - часть с начала строки, заключенаая в квадратные скобки. На этом этапе нахоидим транскрипцию и откусываем ее от строки $meaning.Содержимое памяти после этого шага. Обратите внимание на переменную $meaning. В отличнии от предыдущего шага - траскрипции там уже нет.

4. Определение частей речи
С частями речи тот же принцип, что и с значениями - их может быть несколько, но не меньше одной. Обозначаются части речи арабской цифрой с точкой, если их несколько и не обозначаются цифрой никак, если часть речи одна.
Итак, для работы с частями речи опять разбиваем строки на массив по арабским цифрам с точкой. Если цифр нет, то просто добавляем строку в массив.
Получается следующее:
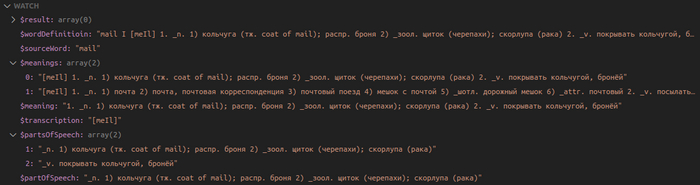
2 части речи (_n. - noun - существительное и _v. - verb - глагол) - 2 элемента в массиве $partsOfSpeech.
4.1. Прасинг части речи
Запускаем цикл по массиву частей речи и на каждой итерации работаем с одной частью речи за раз.На первой итерации память выглядит так:
4.2. Определение названия части речи
Тут все уже знакомо по предыдущим пунктам. Часть речи - это подстрока с начала строки, которая начинается на нижнее подчеркивание (_) и заканчивается точкой (.). Так же после определения названия откусываем результат от исходной строки.
Память выглядит так:

Наканец-то подошли к кульминации - определению переводов слова. Переводы могут иметь несколько значений внутри одной части речи + несколько синонимов.
Значения отделены друг от друга арабской цифрой со скобкой. Синонимы отделяются друг от друга запятой или точкой с запятой. Какой семантический смысл в отделении запятой и точкой с запятой - я не разобрался. Но это и не важно в моем случае, потому что строку переводов я разбиваю на значения и сохраняю в один массив внутри одной части речи.
Выглядит это следующим образом:
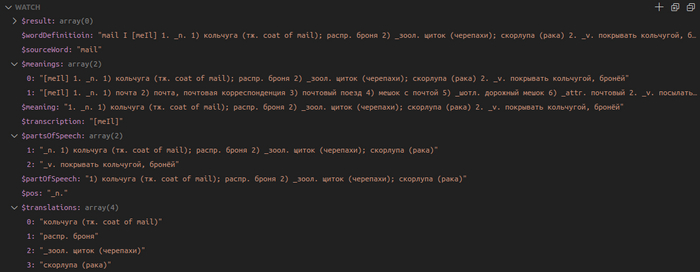
6. Сохранение результата
Если взглянуть на содержимое памяти в данный момента, то станет понятно, что сейчас там хранится все необходимая информация для получения первого слова. А точнее первого значения, части речи "существительное" слова mail. У нас есть $source, $transcription, $pos, $translations. Осталось сохранить эти значения в структуру данных и добавить ее в $result.
После всех описанных манипуляций массив $result содержит одно значение:
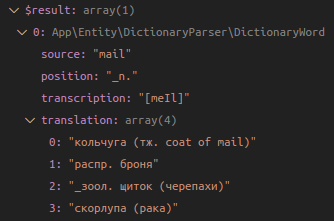
Одно значение - неплохо, но у слова mail есть еще значения и части речи. Что с ними? Прелесть в том, что описанный процесс одинаков для парсинга любого слова из исходного словаря. Все итерации повторяются для каждого из элементов массивов $partsOfSpeech и $meanings.
После разбора всех значений и частей речи результат будет следующий:

Как видим, в нашем варианте слово mail содержит 4 варианта перевода с рзаными частями речи + синонимы.
На этом парсинг слова именно как строки закончен.
На примере видно, что результат не идеален и требует доработки. Например название части речи все еще нечеловекопонятно, некоторые переводы так же содержат не всегда понятные префиксы, разбивка переводов по запятой тоже дает сбой, как например вот в этом случае

Некоторые из описанных проблем уже решены, некоторые пока еще нет.
Тем не менее считаю, что определенный результат достигнут .

Пример того, как в конечном результате выглядит слово mail можно было видеть в этом посте выше (там где показываю табличное представление слова и ответ от API в формате json)
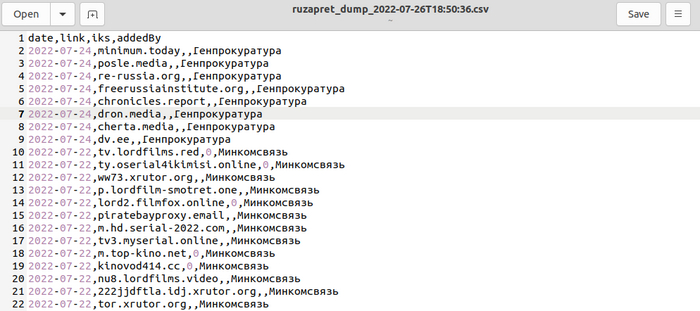
Желающие могут скачать словарь в формате csv и sql
Совсем отчаянные могут посмотреть исходный код парсера + поднять свое API словаря. Репозиторий тут.
Спасибо за внимание!