
Как сохранить список запрещенных в России в файл?1
ПРЕДЫСТОРИЯ
Однажды вечером, в конце рабочего дня, я получил в телеге от своего друга сообщения следующего содержания:
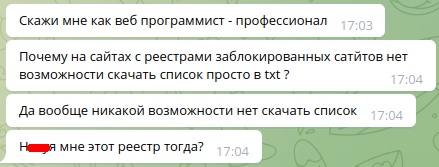
Что ответить на такой вопрос я не нашелся, но поинтересовался, а что, собственно случилось и зачем ем список этих сайтов вообще нужен?
Оказалось, что файл с этими данными нужен для того, чтобы по нему блочить сайты, на которые нельзя ходить студентам одного из наших учебных заведений, в котором мой друг имеет удовольствие трудиться. А тут выясняется, что он проверил 10 подобных сайтов и ни на одном не нашел возможности сохранить данные в файл.
Далее я опрометчиво предложил все нужные данные спарсить, а он возьми и согласись.
Мне была предоставленна следующая ссылка https://ruzapret.com. Тут оговорюсь, что другие сайты я не проверял и возможность скачать нужный файл лично не искал. Да и не в этом дело. Главное, что появился повод блеснуть выдающимися программерскими скилами.

Короче говоря, появилась задача - сделать простой инструмент для скачивания в файл всех запрещенных в России сайтов. Инструмент должен иметь минимум зависимостей и чтобы им мог воспользоваться человек, который работает с компьютерами, но не связан с программированием напрямую.
Поэтому я принял решение написать простенькую консольную утилиту на nodejs, чтобы можно было скопипастив одну строчку установить ее на компьютер, а скопипастив вторую - скачать себе весь реестр запрещенных сайтов.
Перейдя по полученной ссылке https://ruzapret.com я сразу же увидел кнопку API в верхнем меню и обрадовался - раз есть api, значит наверняка есть метод для получения списка сайтов! И это была ошибка. Изучая докумментацию апи я наткнулся на множество неработающих методов и страниц, которые никуда не ведут. Кроме того сама страница сайта рендерилась на сервере и ни к какому апи запросов не отправляла. Поэтому я решил побороть проблему лобовым методом. То есть написать классический парсер - качаем страницу, находим нужные места в html-коде, выдираем их и сохраняем в файл. И так 3573 раза - именно столько страниц на сайте.
Итого:
- В качестве ЯП был выбран JS, а точнее nodejs, потому что его леко установить и использовать даже не программирующему человеку. Кроме того, имеется обширная библиотека пакетов среди которых есть те, которые мне понадобятся.
- Сама программа должны быть консольной утилитой, которую можно просто скопипастить в консоль и скачать список файлов. В то же время, можно предусмотреть список параметров, если вдруг понадобиться как-то влиять на ход выполнения программы, ее вывод и т.д.
- В меру возможностей код попытаться сделать на спагетти, чтобы при необходимости иметь возможность дописать какие-нибудь нужные функции. Например сохранение в разные форматы файлов, парсинг только части реестра, парсинг только недостоющей в файле информации и т.д.
ПРОГРАММИРОВАНИЕ
После инициализации проекта и создания скелета получается такая вот файловая структура
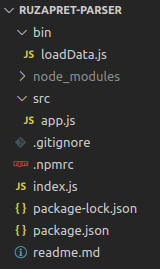
Утилита довольно простая и я решил разделить ее на три абстракции:
1) cкачивание страницы / работа с сетью
2) парсинг страницы / получение структуры данных пригодной для дальнейшей обработки
3) сохранение / работа с файловой системой
Так же будет нужна абстракция самого приложения, которая свяжет воедино все три перечисленных выше функции и точка входа.
Приступим. Начнем со скачивания страницы.
Даплее добавил файл src/loadData.js со следующим содержимым
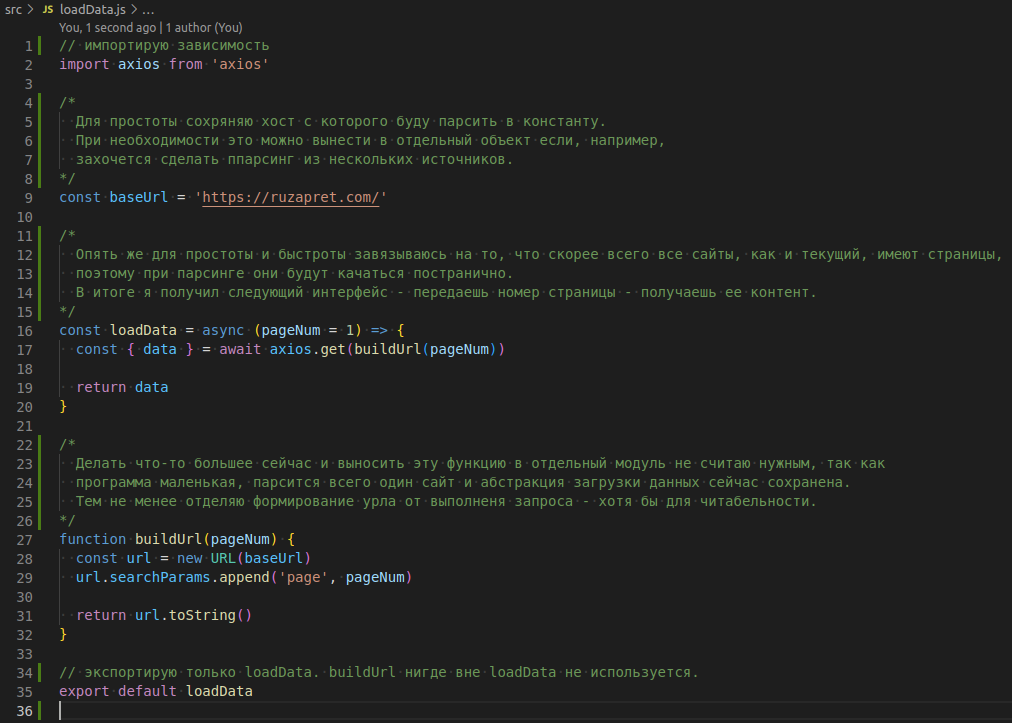
Когда страница скачана - самое время вынуть из нее нужные нам данные.
Но перед этим нужно решить в какой форме их возвращать. Для этих целей я решил добавить класс RecordNode, в который буду сохранять одну запись, хранящую в себе данные об одном сайте. Для парсинга одного источника это, конечно, немного лишнее, но если возникнет желание сохранять данные в разные форматы, то гораздо удобнее работать с унифицированным объектом. Вобщем класс RecordNode
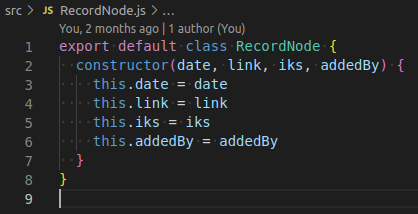
И еще один момент перед парсингом. Добавляю к проекту новую зависимосмть - cheerio. Эта библиотека позволяет работать на сервере с html-кодом в стиле старушки jquery. Получилось следующее
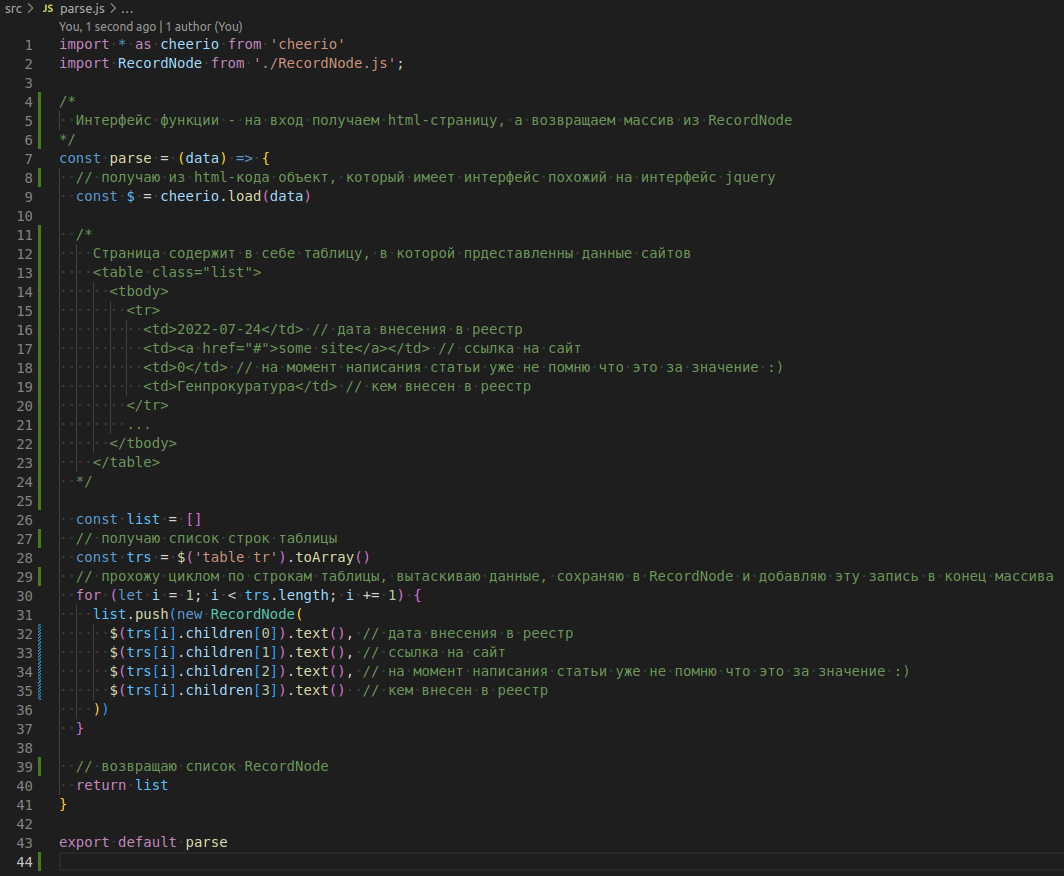
Отлично, теперь у меня есть структура данных, которая содержит в себе данные сайта, это значит, что можно приступить к сохранению в файл.
К этому моменту мне уже поднадоело заниматься утилитой, но бросать на пол пути не по-пацански :) Поэтому я быстренько нашел библиотеку для сохранения объекта в csv файл и добавил её в проеккт objects-to-csv.
Так же в этот модуль я добавил функцию для сборки пути до файла. В данном виде абстракция пока не протекает, все функции служат одной цели - сохранению в файл.
Получилось следующее
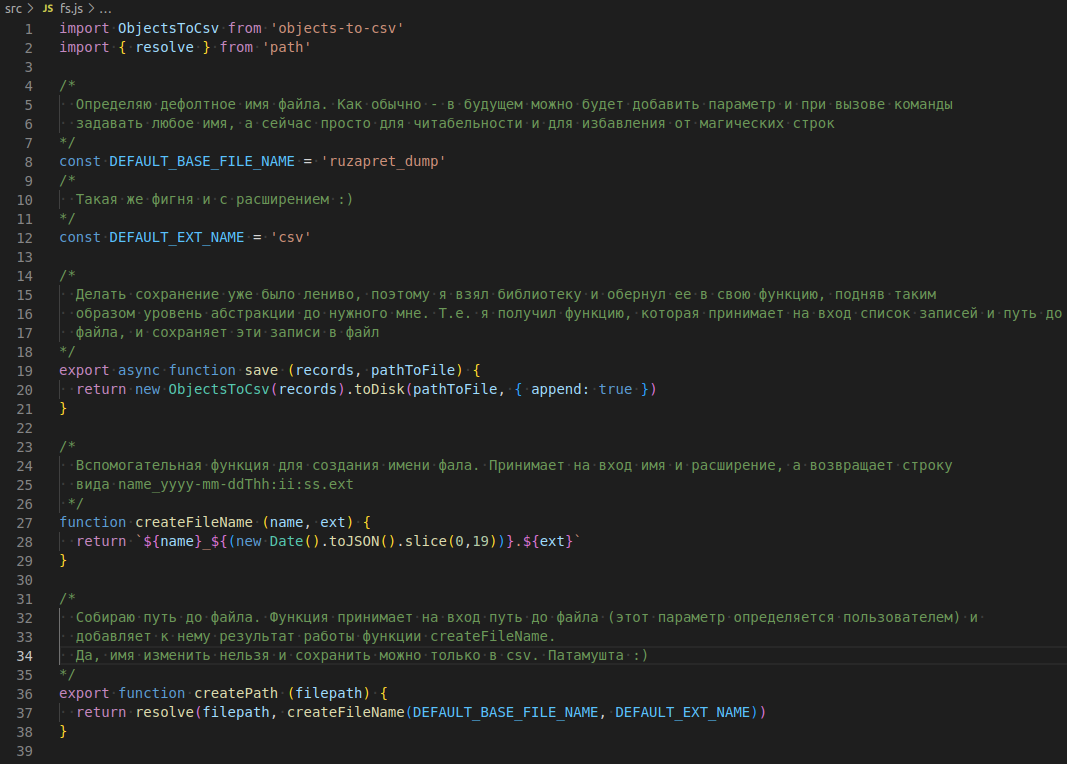
Уфф, практически все готово. Осталось объеденить три разрозненные функции в единое приложение. Добавляю фавйд src/app.js
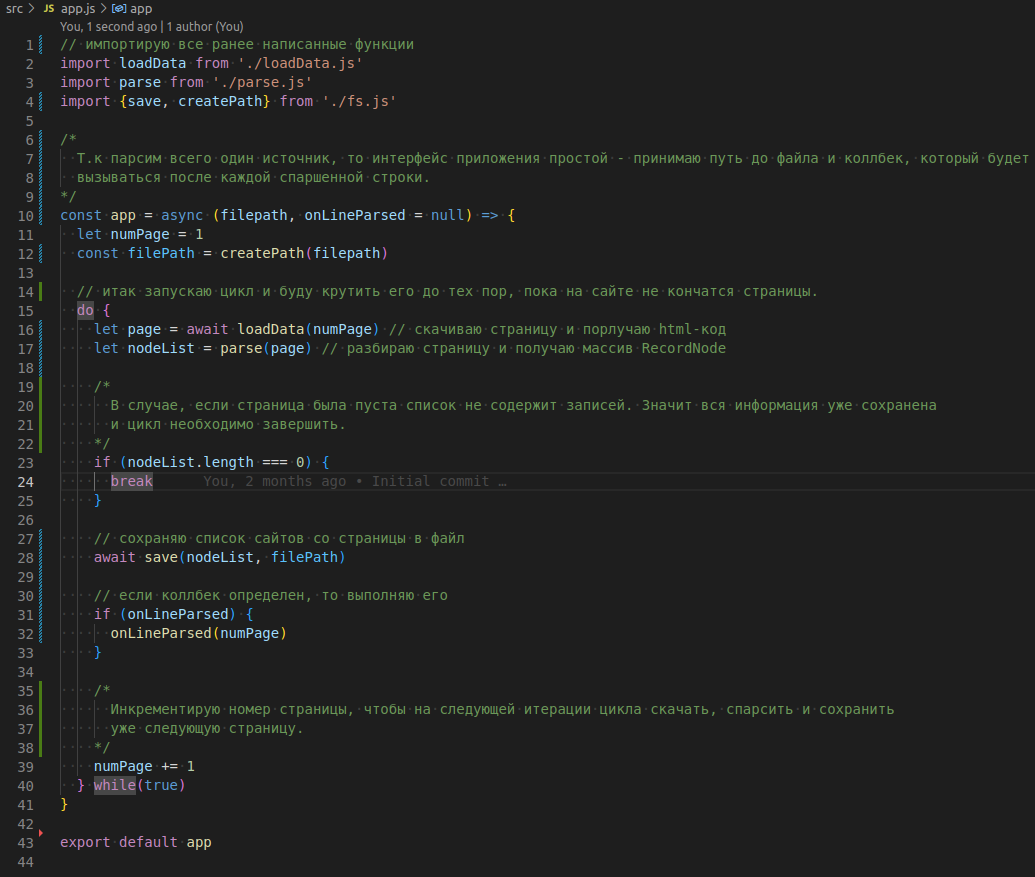
Финишная прямая. Осталось описать запуск этого приложения.
Для начала добавляю в корень приложения index.js
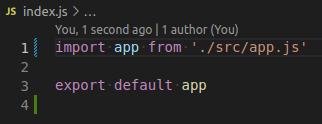
Теперь приложение инкапсулирует в себе все абстракции описанные выше и экспортирует наружу только главную функцию предоставляющую возможность спарсить данные.
Нужен только способор запустить приложение. Для этого я взял библиотеку commander,которая позволяет легко создавать cli утилиты.
Дело за малым. Я добавил файл bin/loadData.js который и станет точкой входа.
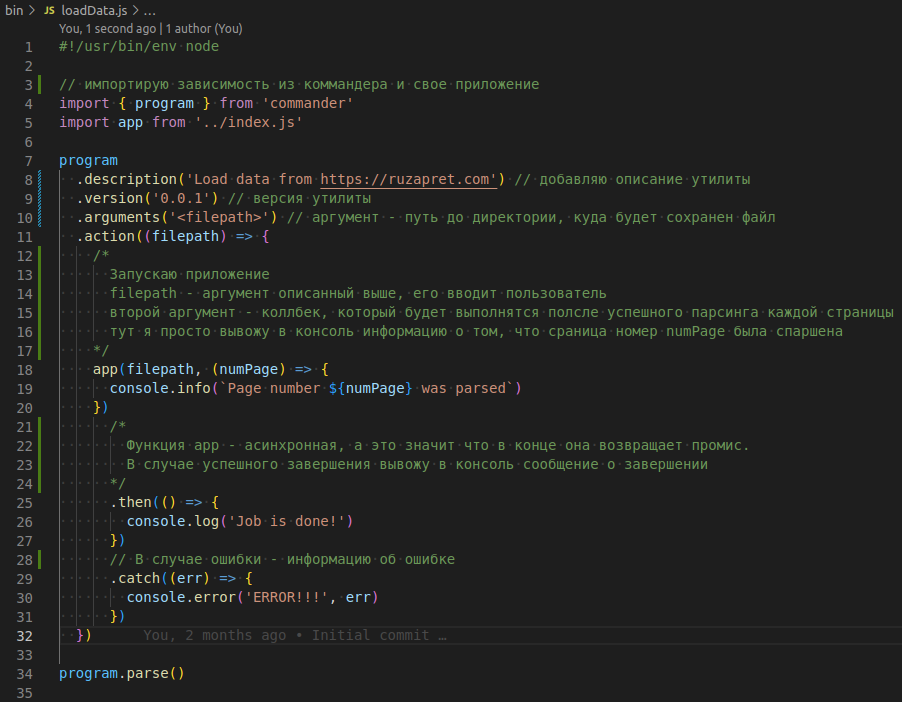
Так же в файле package.json необходимо описать запуск команды как исполняемый файл

Теперь просто выполняю npm link и вуаля: утилитой можно пользоваться
Выглядит работа утилиты примерно так:
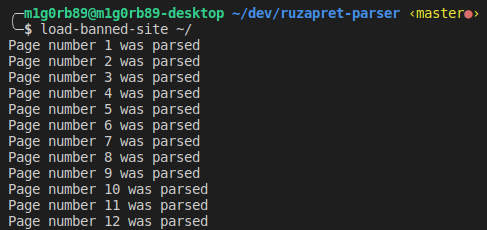
~/ - это тот самый параметр filepath, путь до места на диске, куда будет сохранен файл.
Результат работы выглядит так
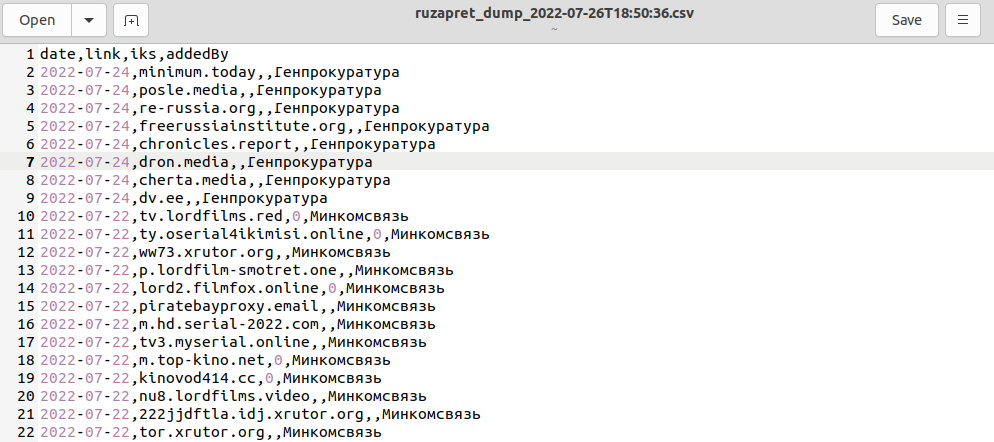
ЭПИЛОГ
На написание утилиты потратил где-то часа 2, парсинг всех 3573 страниц занял минут 50, что весьма небыстро. И это неудивительно. Ведь операции выполняются последовательно, т.е. страница сначала качается, потом парсится, потом сохраняется и только потом начинается тот же процесс для следующей страницы. А это означает, что с каждой страницей процесс сохранения растягивается во времени, т.к. файл становится больше и больше.
Вобщем улучшать есть что. Распараллелить сохранение и скачивание, одновременно скачивать несколько страний, сохранять в файл пачками по несколько страниц, добавить больше параметров для влияния на утилиту, добавить возможность скачивать только определенные типы сайтов и тд, но это уже совсем другая история.

В любом случае утилита выполнила свое предназначение, т.к. мой друг, с которого эта история и началась, получил свой файл и инструмент, чтобы файл актуализировать.
P.S.
Если вдруг кому-то захочется ознакомится с кодом, то сделать это можно тут
Лига программистов
2.2K постов11.9K подписчиков
Правила сообщества
- Будьте взаимовежливы, аргументируйте критику
- Приветствуются любые посты по тематике программирования
- Если ваш пост содержит ссылки на внешние ресурсы - он должен быть самодостаточным. Вариации на тему "далее читайте в моей телеге" будут удаляться из сообщества