Не баг, а фича



Показать полностью
3
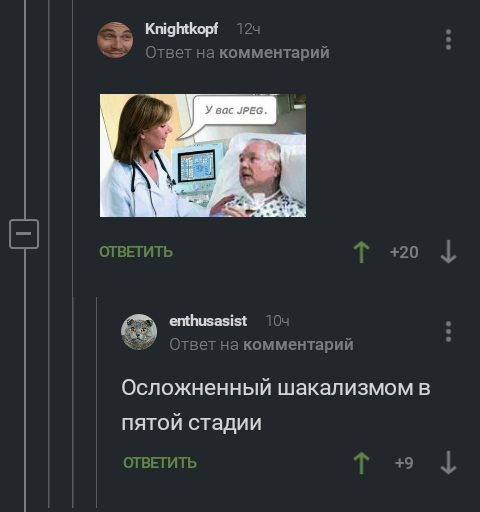
Сегодня ночью вспомнил о том, что когда-то давным давно увидел пост о группе в вк, в которой "одна и та же фотография каждый день вручную сохраняется на компьютер и снова заливается, постепенно теряя в качестве."

Вот как это всё выглядит через призму лет.
Первая фотография залита 7 июня 2012 года

7 июня 2013 года она уже выглядела вот так

7 июня 2014

7 июня 2015

7 июня 2016

7 июня 2017

7 июня 2018

7 июня 2019

Пост не несёт никакой смысловой и политической нагрузки.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509
Друзья пикабушники, написал на днях оболочку для жутко полезной софтинки по автоматическому сжатию фотографий формата jpg без видимой потери качества. В среднем экономия в 5 раз на обычных фото. Если у вас тоже накопилось под сотню гиг домашних фоток - вэлкам тестировать! Софтинка раздается бесплатно с моего сайта. P.S. Мой первый пост на Пикабу. Ссылка на сайт для скачки https://hiki-soft.ru/jpeg
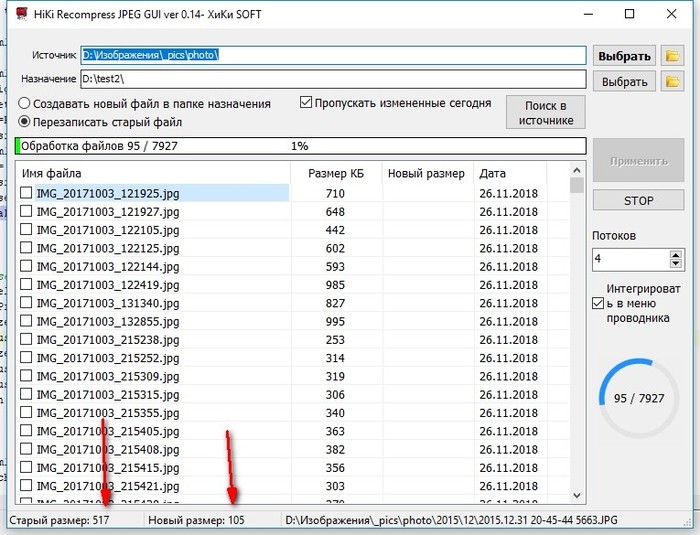



5 августа 2018 г., воскресенье, 18:00, Ново-Переделкино. Это одна и та же фотография с разным вырезанным фрагментом (средствами Пикабу).
Согласно http://exif.regex.info/exif.cgi — фотка сокращается движком Пикабу до 700 пикселей по горизонтали (вместо исходных 5312) и имеет размер 70 Кб вместо исходных 5,1 Мб. Движок также вырезает EXIF-метаданные.
Увеличенная картинка после щелчка имеет разрешение 1600 × 900 JPEG (1.4 мегапикселей, 334 килобайт).
Степень сжатия в шакалах, которую вносит движок, в тегах не отображается, но если кому-то это интересно, я могу экспериментально проверить степень сжатия и наличие пережатия, если подготовить фотографию строго под нужный размер.
Всем привет! Недавно записал видео о том, как устроен формат mp3. Делаю для Ютюба, но еще выложил на Пикабу. Самый первый комментарий был - зачем делать видео, где достаточно текста и картинок.
Справедливое замечание, поэтому отныне, специально для Пикабу, буду делать текстовые версии выпусков. Информация абсолютно та же, но вид другой. Думаю многим так будет удобнее. Итак, ниже видеоверсия, а еще ниже - текст с картинками.
JPEG - это формат сжатия изображений, который позволяет уменьшить размер файла в 20, 30, 100 раз! В посте НЕ будет описана история создания формата, его плюсы и минусы и самые тонкие технические детали. Это обзорное повествование о том, как происходит сжатие (в очень упрощенном, и от этого более понятном виде) и как работает технология. Пикабушников не удивить шакалами, но здесь как раз объясняется, откуда они берутся.
Вообще, если бы не джипег, то интернет сейчас был бы совсем другим. Думаю, внешне он напоминал бы сайты 90-х. И мы бы не смогли запросто инстаграммить все подряд и смотреть фотки котиков на телефоне) К тому же, этот алгоритм лежит в основе сжатия видео! Так что без него не было бы ни этого ролика, ни ютюба, ни даже фильмов онлайн без регистрации и смс!
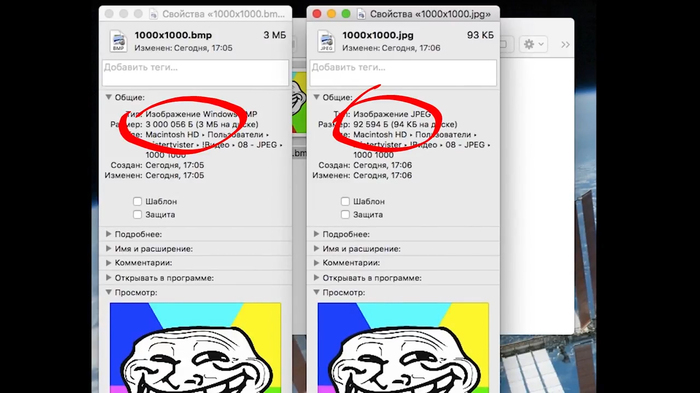
Но чтобы понять, насколько гениальная штука Джипег, нужно разобраться, как кодируются изображения без сжатия. Возьмем картинку 1000 на 1000 точек. Каждый пиксель – это смесь трех составляющих, трех цветов – красного, зеленого и синего. Одна составляющая кодируется, как правило, 8 битным числом.
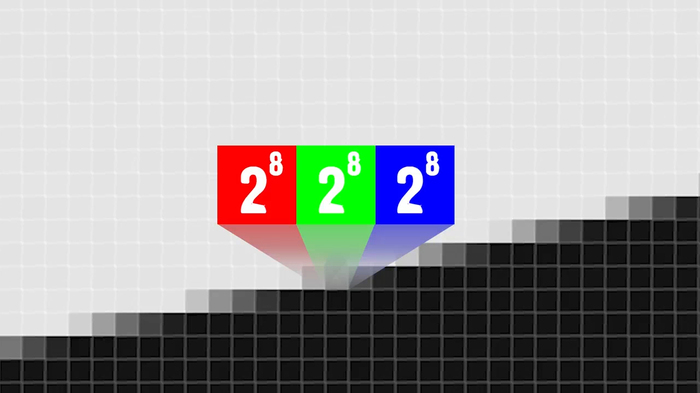
Нетрудно посчитать, что такая картинка без сжатия будет весить:
8 х 3 х 1000 х 1000 = 24 000 000 бит, то есть 3 мегабайта.
Но если сохранить ее в джипеге, она может занимать, например, 90 килобайт. То есть в 33 раза меньше! Да, качество чуть-чуть теряется, но не в 30 раз ведь! Как же это работает?
Итак. Алгоритм сжатия джипега можно разбить на несколько основных этапов
1 - Цветовое пространство
Этап первый – перевод в другое цветовое пространство, в котором разделены яркостная и цветовая составляющие. На этом шаге потерь не происходит, ведь каждый пиксель по-прежнему состоит из трех компонентов. Только теперь это яркостная компонента и две цветовых. Короче, если упростить, происходит следующее: создается Ч/Б изображение и цветовая маска к нему, вот и все!

2 - Ресемплинг
Возникает вопрос, зачем? А все дело в нашем зрении! Человеческий глаз менее чувствителен к изменениям цвета, чем к изменениям яркости. И такое предварительное разделение нужно, чтобы в цветовых каналах можно было убрать часть деталей.
Это и происходит на втором этапе – ресэмплинге. Каждые 4 цветовых пикселя объединяются в один. Да, происходит потеря некоторых деталей, но… это практически незаметно! И на таком приеме уже удается сжать файл в 2 раза!

3 - Блоки 8х8
На следующем шаге картинка разбивается на блоки 8 на 8 пикселей. Кстати, шакалы от этого становятся видны, если очень сильно сжать изображение, например, так:

4 - Дискретное косинусное преобразование
Это, пожалуй, самый важный этап. Алгоритм должен каким-то образом понять, насколько много деталей в каждом блоке. Например, если это монотонный кусок неба, его можно закодировать чуть ли не 1 байтом) А если это ваша невероятная прическа, там много переходов яркости и цвета, на это нужно потратить больше бит.
Делается такой анализ с помощью дискретного косинусного преобразования. Это разновидность преобразования Фурье, которое, кстати, и в mp3 применяется. Сложная, но очень интересная штука!
Итак, рассмотрим блок 8 на 8 пикселей. Напоминаю, что он уже разбит на яркостный и цветовые каналы, и преобразование проводится над каждым отдельно. Иными словами мы работаем уже с монохромными блоками.
Дискретное косинусное преобразование производит разложение по спектру пространственных волн. Что же это такое? Любую монохромное изображение 8 на 8 пикселей можно представить как смесь из 64 картинок, на которых посмотрите что изображено:

Вот такие вот периодические плавные переходы! Это и есть пространственные волны разной длины (по горизонтали и вертикали). Есть другая версия отображения этих пространственных волн, трехмерная. Кому как удобнее для понимания:

Если накладывать такие базовые картинки друг на друга, а точнее прибавлять или вычитать с определенным коэффициентом каждую, то мы сможем получить что угодно! Вот как это выглядит, например, для буквы А. Посмотрите, с каждым следующим наложением, шаг за шагом, добавляется все больше и больше деталей и получается реально буква А:

Дискретное косинусное преобразование (DCT) как раз вычисляет коэффициенты для наложения каждой такой базовой картинки. Всего 64 числа:
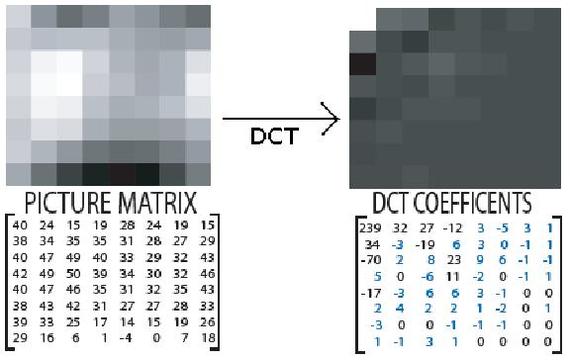
И обратите внимание! Коэффициент это вес, важность этой составляющей. Здесь есть те, которые отвечают за плавные переходы. И те, которые отвечают за более частые.
Как раз, если деталей мало, то коэффициенты у последних будут практически нулевыми, ведь зачем добавлять такую рябь, если блок почти монотонный? И вот тут и начинается по-настоящему мощное сжатие!

5 - Квантование
Начинается этап квантования! Матрица коэффициентов делится на матрицу квантования, которая зависит от настроек сжатия. Например, если вы сохраняете JPEG со 100% сжатием, каждый коэффициент делится на 1 (то есть остается таким же). Если вы сохраняете с меньшим качеством, то каждый коэффициент делится на определенное число (опять же в зависимости от выбранного качества).
Далее производится округление поделенных коэффициентов до целого значения. И при сильном сжатии многие из них округляются до нуля:
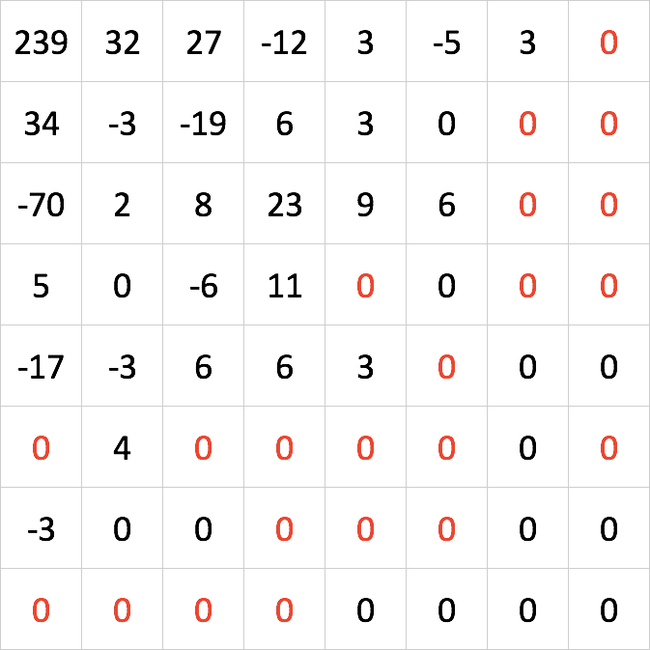
Да, на этом шаге теряется много информации. Да, из-за этих округлений, при прочтении файла и вылезает куча шакалов, артефактов и прочего. Но! Основная суть остается! Ну, а дальше сжать файл, напичканный нулями – дело техники!
6 - Сжатие
Сначала матрица коэффициентов сканируется зиг-загом:
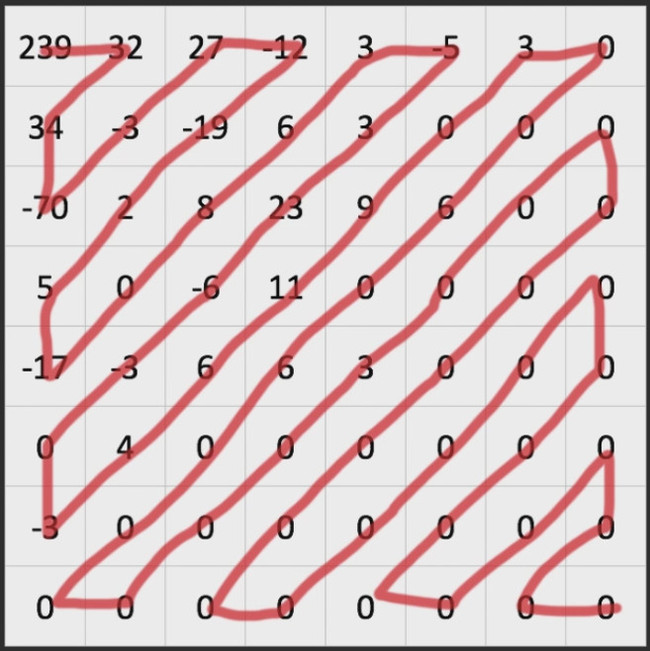
Получается последовательность чисел в конце которой зачастую одни нули:

Затем последовательность пакуется хитрым способом. Если в ней есть длинная череда нулей, НЕ кодируется каждый из них. Вместо этого просто указывается одно число, обозначающее сколько их. Это очень сильно сжимает размер файла! Довольно упрощенно это может выглядеть так:

Ну и в конце сжатая последовательность кодируется кодом Хаффмана.
Каждому символу приваивается определенный код. Например, (опять же упрощенно) так:
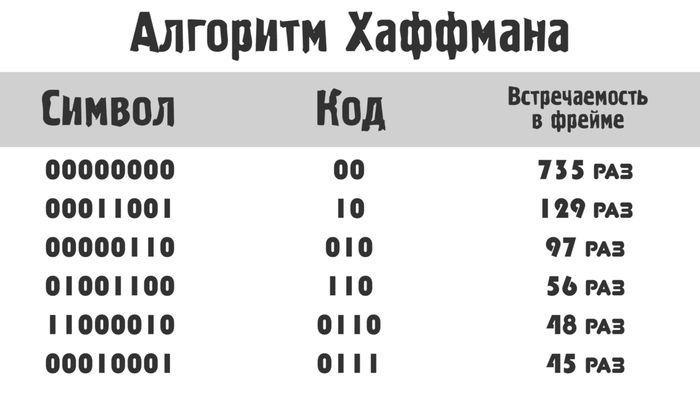
Обратите внимание, код присваивается не абы как, а по степени встречаемости в файле. Чем чаще появляется символ, тем короче у него код.
Получается, что нули и другие символы, которых очень много кодируются малым количеством бит, а остальные символы, которые реже встречаются, бОльшим количеством бит. Об этом алгоритме я подробнее рассказываю в видео про mp3, можете там посмотреть:

Затем все блоки 8 на 8 склеиваются в один файл и получается красивенький, маленький джипег!) Вот кстати портрет шведской модели Лены Сёдерберг из журнала Playboy. Так сложилось исторически, что с 1973 года это изображение используется для проверки практически всех алгоритмов обработки изображений. В то числе и JPEG. Поговаривают даже, что JPEG был оптимизирован как раз для того, чтобы как можно лучше сжать эту картинку)

Как видите, в джипеге используется много тонкостей – это и особенности нашего цветового восприятия, и хитрейшее разбиение картинки на детали, и математические методы сжатия. Но несмотря на это джипег уже устаревает, ему в спину дышат новые форматы, основанные на тех же принципах, но еще лучше сжимающие изображения. Хотя что-то мне подсказывает, что старичок джипег будет еще долго жить!)
Спасибо всем, кто дочитал до конца! Это мой первый длинопост, не судите строго) Баянометр ругался только на Лену, но это культовое фото!
Полезные ссылки:
Как устроен формат mp3: https://youtu.be/z2EUT4gwkr4
Подробнее о JPEG: https://habrahabr.ru/post/206264/
Доброго времени суток, друзья!
Представляю Вам третью и последнюю часть статей по JPEG2000.
Предыдущие части:
1) Вейвлеты
После разбора вейвлетов и арифметического кодера можно посмотреть на схему кодирования и оценить достоинства и недостатки данного формата. Схема кодирования:
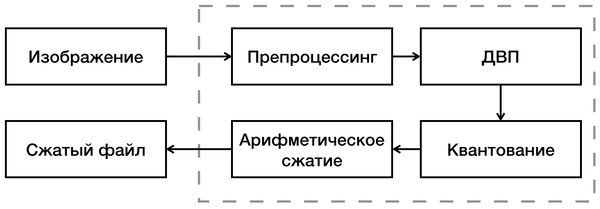
Сначала во входном изображении выравнивается динамический диапазон, что увеличивает степень сжатия. А затем производится преобразование из цветового пространства RGB в YCbCr (подробнее об этом в статье). Эти операции называются “препроцессингом”.
После преобразования производится ДВП. На этом шаге изображение разбивается на квадратные блоки — тайлы. Размер тайла не ограничен, тем не менее, чем больше сторона блока, тем больше памяти и времени требуется для его обработки. Поэтому размер тайла ограничивают сверху, как правило, величинами, кратными степени двойки.
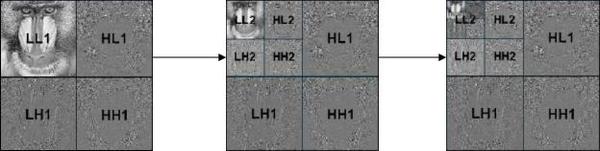
Как было описано в статье про вейвлеты, после ДВП у нас имеется два набора данных, т.е. на выходе объем информации увеличивается в два раза. Поэтому после каждого раунда изображение уменьшается в 2 раза. Раунд — это проход отдельно по столбцам и строкам. После каждого раунда мы имеем 4 части:
1) LL – низкие частоты по строкам и столбцам
2) HL – высокие частоты по строкам и низкие по столбцам
3) LH – низкие частоты по строкам и высокие по столбцам
4) HH – высокие частоты по строкам и столбцам
В следующем раунде будет обрабатываться только область LL (уменьшенная в 2 раза) из предыдущего раунда, так как является наиболее значимой. Об этом подробнее написано в статье про вейвлеты. Раундов может быть до 32-х. Тем не менее, чаще всего их не проводят более 8-ми раз, т.к. вейвлетное преобразование является вычислительно сложным.
Это проиллюстрировано на рисунке ниже:
После некоторого числа раундов производится квантование. Причем коэффициент квантования постоянный, в отличии от JPEG. На этом этапе теряется некоторая часть данных изображения. Чем выше коэффициент квантования, тем большую степень сжатия можно получить на выходе. Тем не менее, большие коэффициенты квантования вносят видимые артефакты.
После квантования все данные разбиваются на блоки и сжимаются арифметическим кодером. Процесс сжатия описан в части про арифметическое сжатие. Единственное, что нужно знать – арифметический кодер эффективнее кодов Хаффмана.
Теперь подведем итоги, действительно ли данный формат лучше, чем JPEG, почему он не “выстрелил” и т.д.
В JPEG2000 поддерживается прозрачность на уровне формата. Для этого используется отдельный альфа-канал. Тем не менее, эффективность сжатия в этом случае будет ниже.
Заявлено, что формат поддерживает кодирование отдельных областей с лучшим качеством (меньшими потерями). Однако, в свое время это не было реализовано должным образом. Сейчас это имеется в некоторых форматах, в основном, сжатия видео.
Поддержка кодирования тайлов (блоков) разных размеров — это действительно хорошо, если блок одноцветный. Но разбиение на блоки перед сжатием все портит.
Ну и напоследок, скорость кодирования/декодирования в сравнении с JPEG куда ниже, т.к. косинус-преобразование менее затратно, чем вейвлет. Это и было основной причиной непопулярности этого формата.
Не смотря на эти недостатки, JPEG2000 сжимает одни и те же изображения эффективнее, чем JPEG. В среднем, выигрыш 15-20%.
На этом с темой JPEG2000 можно закончить. Надеюсь, что это было познавательно. До скорого!
Конкурс мемов объявляется открытым!
Выкручивайте остроумие на максимум и придумайте надпись для стикера из шаблонов ниже. Лучшие идеи войдут в стикерпак, а их авторы получат полугодовую подписку на сервис «Пакет».
Кто сделал и отправил мемас на конкурс — молодец! Результаты конкурса мы объявим уже 3 мая, поделимся лучшими шутками по мнению жюри и ссылкой на стикерпак в телеграме. Полные правила конкурса.
А пока предлагаем посмотреть видео, из которых мы сделали шаблоны для мемов. В главной роли Валентин Выгодный и «Пакет» от Х5 — сервис для выгодных покупок в «Пятёрочке» и «Перекрёстке».
Реклама ООО «Корпоративный центр ИКС 5», ИНН: 7728632689