


Random pics by Stable Diffusion





Показать полностью
5
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
Сегодня покажу как установить, настроить и начать пользоваться одним из самых лучших расширений для стабильной диффузии. Способов его применения огромное множество, но все по порядку.

Для начала становим расширение. Запустите автоматик, зайдите Extensions - Available - Нажмите кнопку Load from. Загрузятся расширения доступные к установке, найдите sd-webui-controlnet и нажмите Install. С расширением всё.
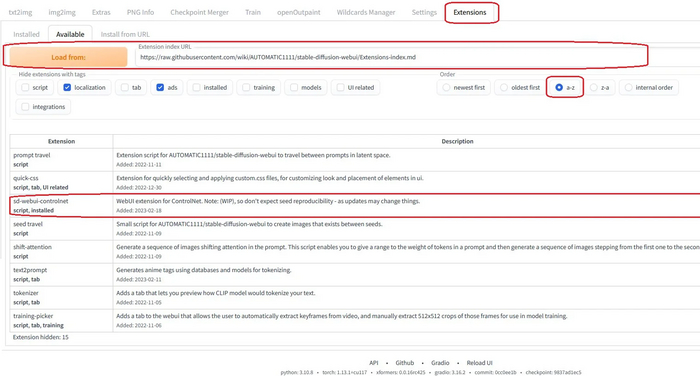
Теперь нужно скачать модели и я походу объясню какая и зачем.
Модели. Есть полные версии, а так же их уменьшенные версии, заметной разницы в качестве я не обнаружил и пользуюсь уменьшенными так как SSD не резиновый.
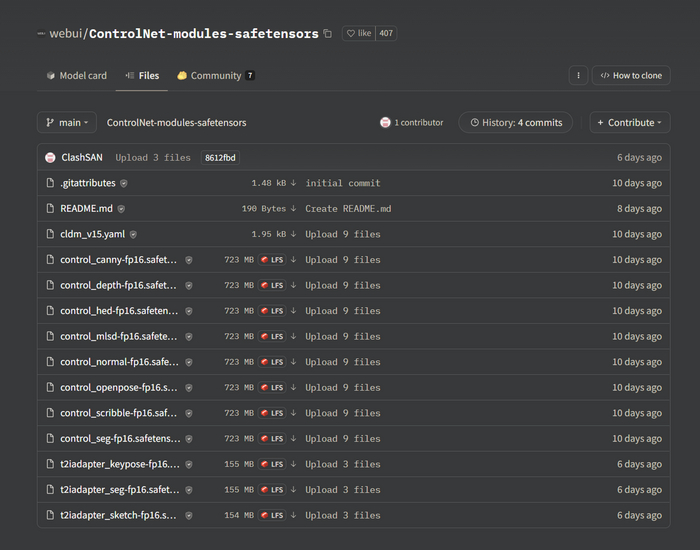
Можете скачать все со словом control в начале. Я в основном использую 3, это depth, openpose, hed, но так как весят не много и удобно иметь под рукой, имею все.
Препроцессоры:
У всех у них одна задача, получить тот или иной контур объекта, поза, линии, силуэт чтобы затем вы могли изменить картинку не отходя от этого самого контура, позы, силуэта. Так вот теперь вы можете забрать с нее только композицию и нарисовать по ней все что угодно. В разумных пределах конечно.
canny - обводит края тонкой линией, подходит для изображений с резкими краями, например аниме

hed - толстой размазанной, смягчая края

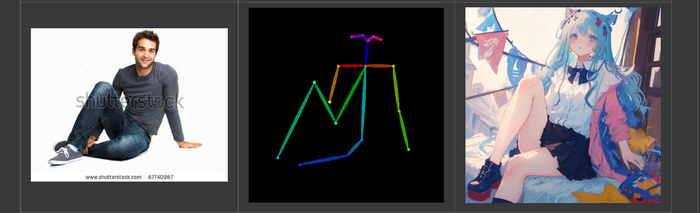
openpose - берет только позу людей кадре, никаких краёв, а значит можно менять например фигуру. Для всего
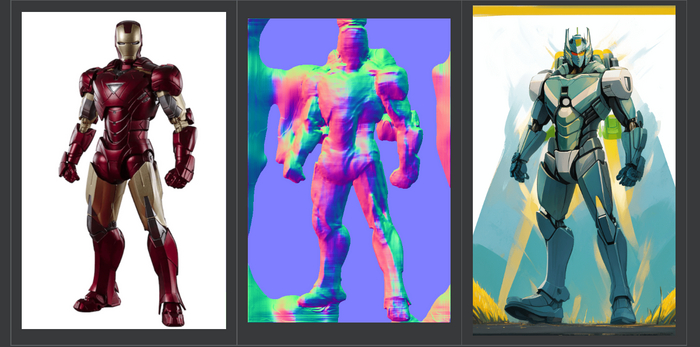
depth - маска глубины чем ближе к камере тем белее, для всего когда нужно получить объем сцены чтобы его сохранить

normal - карта объёма
scribble - создает каракули и может создавать что-то из каракуль

mlsd - работает с ровными прямыми линиями, хорош с помещениями, чтобы передать их геометрию ну и потом перерисовать конечно.

seg- делит картинку на сегменты, затем пытается в тех же сегментах нарисовать те же объекты которые могут относиться к этому сегменту. Использовал я его примерно 0 раз, но кто знает…

После скачивания моделей поместите их по пути: ваша_папка_с_автоматиком\extensions\sd-webui-controlnet\models
После того как все сделали, полностью перезапустите стабильную диффузию.
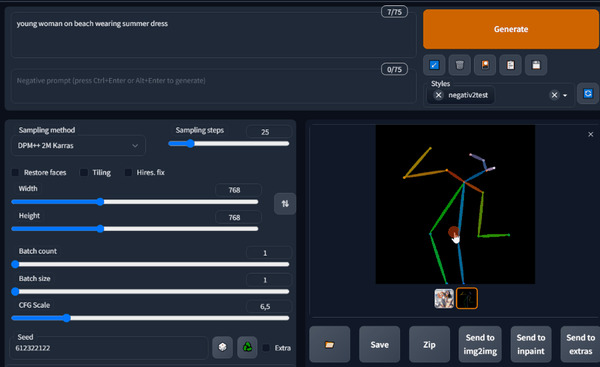
Запускаем снова и смотрим вниз. Появилась вкладка ControlNet. Давайте сгенерируем что нибудь и сразу возьмем его позу для генерации чего-то другого.
Конечно же не обязательно генерировать. Вы можете поместить в окно контролнета любую фотографию которую хотите взять за основу.
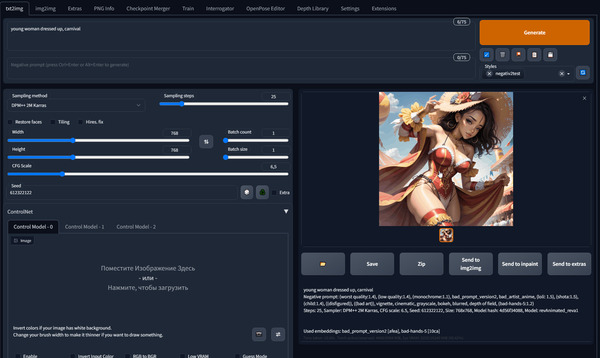
Ставлю галку на Enable, чтобы активировать расширение. Выбираю препроцесср Openpose модель тоже openpose.
Еще пример изображения в той же позе:

А теперь давайте разберемся с настройками. По крайней мере на дату выхода статьи , в мире нейросетей все очень быстро меняется.
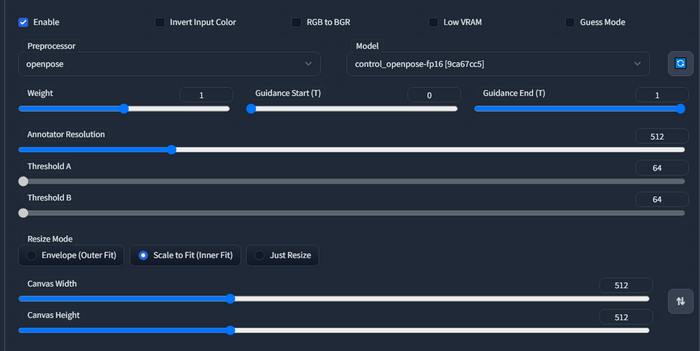
Enable - включить
Invert Input Color - инвертировать изображение. Бывает что вам понадобится черный контур на белом фоне, а ваша картинка имеет обратные цвета. Галка поможет
RGB to BGR - сменить компоновку пикселей. Видимо на матрицах BGR даст результат лучше, но я с такими дело не имел
Low VRAM - уменьшает требование к видеопамяти
Guess Mode - удалите промпт, контрол сам попробует понять что на картинке и повторить по своему. По мне фигня какая-то (на текущую дату)
Preprocessor - обработчик изображения которое вы скормили расширению. То есть openpose превращает изображение в позу. Из примера выше она выглядит вот так
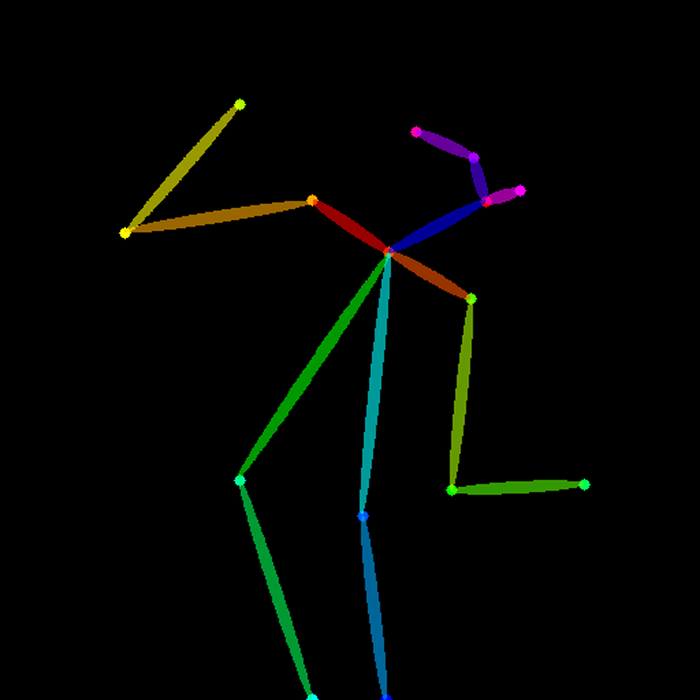
Model - берет то что получила от препроцессора и обрабатывает.
Weight - как сильно контролнет будет влиять на композицию
Guidance Start (T) - когда вмешаться
Guidance End (T) - когда перестать
Диффузия получает изображение из шума, делает она это степами\шагами. Вы можете выбрать когда контрол нету влиять на очистку шума, а когда нет. Это уже чуть более продвинутая техника. Расскажу о ней в другой раз. В вкратце, если поставить 0 и 0.5 контрол будет контролировать общий силуэт до половины генераций, а дальше полностью отпустит вожжи и в дело вступит только диффузия.
Annotator Resolution - разрешение считывания, ставьте по самой короткой стороне вашей картинки, качество работы препроцессора должно стать лучше.
Threshold A\B - предназначены для очистки “мусора” на таких препроцессорах как canny например. Если у вас считывает что что вы не хотели бы или наоборот, поиграйте этими ползунками.
Оба максимум \ Оба минимум

С позами понятно. А остальные что?
Теперь вам не нужно долго добиваться от диффузии нужной вам композиции. Вы можете использовать любую уже созданную, хоть вами хоть кем то другим. Это только часть возможностей данного расширения, об остальных расскажу в других статьях.
Выбирайте препроцессор при принципу что вам важно взять с изображения? Только позу? Openpose. Силуэт? Depth. Нужно сохранить практически все грани, но переделать в другой стиль? Canny, hed.
На прощание нарисуем кролика:
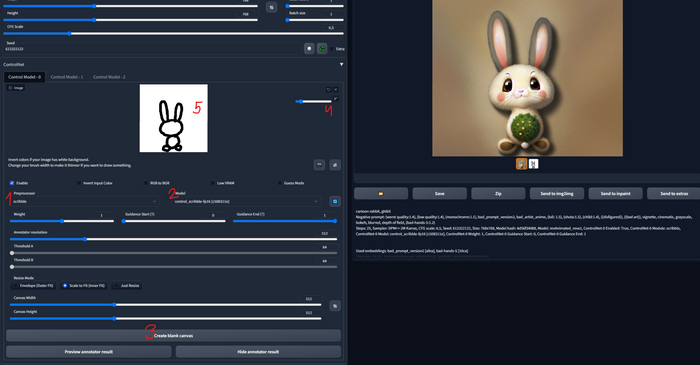
мой промпт: cartoon rabbit, ghibli
Поделиться результатом или задать вопрос вы можете в нашем комьюнити нейроэнтузиастов.
Больше гайдов на моем канале, подписывайтесь чтобы не пропустить. Так же вы можете заказать у меня работу если не может что-то сделать сами, ну или не хотите)




















Изучая нейросети я продолжил дорабатывать иллюстрацию с медведями. Сейчас крайний вариант выглядит так:

Этот вариант уже выглядит гораздо чище и прилизанной, почти полностью изменил детали велосипеда. Так как для нейросети это очень сложный объект.
Процесс:
Чтобы убрать лишнюю грязь я вырезал все объекты по отдельности в Photoshop, наложил градиент и шум на фон. А затем каждый элемент по одному загрузил в нейросеть StableDiffusion, сгенерировал и еще раз вырезал в Photoshop.

Все мелкие элементы велосипеда пришлось делать по отдельности.

Спицы рисовал отдельно

Цепь, педали и звездочки нейронка вообще отказывалась нормально делать, по этому их пришлось вырезать отдельно со стоковых фотографий

Проще всего было с шариками котом и медведями.

Но анатомию лап медведей нейросети по прежнему не могут передать нормально.
И так как элементы я генерировал по отдельности, потерялись тени которые теперь у каждого медведя свои.
Ниже весь список элементов которые я делал отдельно.

Как видно из примеров, работа еще не окочена, нужно решить проблемы анатомии, и распределение света и теней на общей композиции, но это должно быть автоматически, так как если делать это вручную, то работа больше становится рисованной, чем генерированной.
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi

TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронкам. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
В прошлый раз я делал что-то вроде этого:

Это расширение уже имеющейся статьи по обучению Лоры в гугл колабе. Я периодически буду ссылаться на нее. Полезно прочитать обе статьи. Все на примере Kohya ss.
Сегодня я научу вас тренировать модель на лицах, причем я буду использовать синтетический датасет, чтобы показать что это можно делать так же как и с фото людей.
Если в ходе установки или работы у вас возникнут какие-то проблемы вы можете обратиться за помощью в наш чат.
Зависимости:
Установите Python 3.10 Убедитесь что при установке поставили галочку add Python to the 'PATH'
Установите Git
Установите Visual Studio 2015, 2017, 2019, and 2022 redistributable
Предоставляем доступ для оболочки PowerShell, чтобы она могла работать со скриптами:
Запустите PowerShell от имени администратора (ПКМ по значку Windows - Windows PowerShell administrator)
Запустите команду Set-ExecutionPolicy Unrestricted ответьте 'A'
Закройте PowerShell
Если в ходе выдачи доступа возникает ошибка в предоставлении этого самого доступа. Что-то вроде этого:
Оболочка Windows PowerShell успешно обновила вашу политику выполнения, но данный параметр переопределяется политикой, определенной в более конкретной области. В связи с переопределением оболочка сохранит текущую политику выполнения "Unrestricted". Для просмотра параметров политики выполнения введите "Get-ExecutionPolicy -List". Для получения дополнительных сведений введите "Get-Help Set-ExecutionPolicy".
Нажмите Win + R. Введите gpedit.msc. Энтер. Пройдите по пути как на скрине, дважды нажмите на “Включить выполнение сценариев”:

Далее. Ставим включить. В политике выполнения выбираем “Разрешить все сценарии”.

Закройте PowerShell.
Перейдите в папку где вы хотели бы хранить файлы скрипта. Нажмите на путь и введите вместо него PowerShell. Энтер. Так мы будем выполнять скрипты из этой папки.

Скопируйте скрипт ниже и вставьте в ваш PowerShell. Энтер.
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/rel...
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
Ждем пока не появится вот такая строка

Нажмите энтер, начнется настройка. Что вам нужно выбирать написано на скрине ниже.


Выбираем цифрами. 0 - это первый пункт, 1 - второй и т.д. Либо будет предложено ввести yes или no.
Скачайте архив. Поместите папку из него (cudnn_windows) в корневую папку куда вы устанавливаете скрипты в данный момент. В командной строке, из корневой папки со скриптами выполните данные команды. По информации с гитхаба может дать значительный прирост скорости обучения.
.\venv\Scripts\activate
python .\tools\cudann_1.8_install.py
На этом установка и настройка завершены. Если вы хотите обновить скрипты. То опять же. Запуск командной строки из папки со скриптами. Вставить. Энтер
git pull
.\venv\Scripts\activate
pip install --use-pep517 --upgrade -r requirements.txt
На этом вообще можно было бы и закончить и отправить вас читать версию для коллаба, но я продолжу
Запустите оболочку через gui.bat

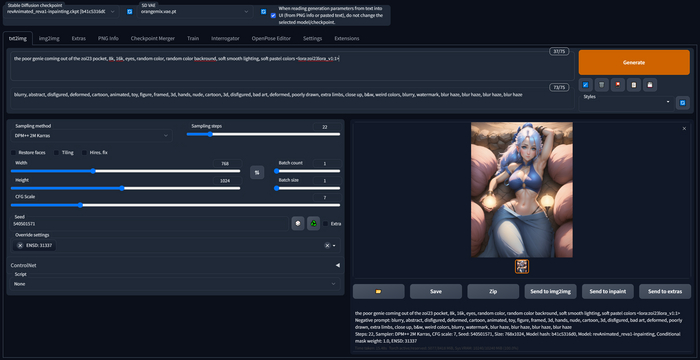
После запуска переходим на http://127.0.0.1:7860/?__theme=dark (ну или http://127.0.0.1:7861/?__theme=dark если был запущен автоматик)
Сразу переходим во вкладку Dreamboot LoRA. Тут нужно либо выбрать модель на вашем ПК нажав на белый листик и указав путь. Либо модель из списка. Она будет скачана скриптом.

v2 - Ставите галку если тренируете на второй версии диффузии
v_parameterization - если на версии 2.1 с параметризацией то и эту
Save trained model as - в каком формате будет сохранена ваша модель. Для автоматика, на текущую дату, оставляйте safetensors.
После выбора модели идем на вкладку Folders. Я буду пробовать тренировать на Deliberate 2. Хотя обычно делаю это на SD 1.5.

Image folder - Тут указываем папку на ваш датасет, не прямо на картинки с описанием, а на папку, где эта самая папка лежит.

Как подготовить дата сет я писал в гайде по коллабу, так как эта инфа верна на 101% и для этого способа, чтобы не раздувать статью просто прочитайте часть про датасет в статье про колаб.
Output folder - папка куда будет сохранен файл модели
Regularisation folder - папка в регуляризационными фотографиями. Если кратко нужны, чтобы избавиться от стиля. Туда кладутся фотки без какой-то стилизации напоминающие то на что вы тренируете. Я ни разу не использовал. По идее если хотите натренировать на стилизованного персонажа можно выбрать туже папку с датасетом. Видел как так делают. Работает ли? Не знаю
Logging folder - укажите куда будут сохраняться логи.
Model output name - имя итогового файла модели. Только файла. К ключевому слову тригеру отношения не имеет. Тригер задается в датасете.
Training comment - просто комментарий который будет добавлен в метедату файла модели.
Идём на Training parameters:

Lora type - что-то новенькое. Судя по репозиторию LoCon должен обучать модель более эффективно. Но сегодня без экспериментов. (Для меня. Вы конечно попробуйте и поделитесь результатом)
LoRA network weights - указать путь к уже существующей Лора, чтобы продолжить тренировку.
Caption extension - расширение файлов подсказки. Те самые которые должны лежать у вас рядом с картинками вашем датасете. у меня это “.txt”.
Train batch size - Оставляю 1. Эта настройка может ускорить обучение, но в тоже время это происходит из за того что сеть берет сразу несколько картинок и берет как бы среднее значение между ними. Логично что жрет VRAM так что у кого мало много не выкрутить.
Epoch - сколько эпох. Если просто это кол-во проходов по вашему датасету. Например, у вас два варианта. Оставить тут 1, а папку с датасетом назвать 100_keyword, тогда сеть пройдет по картинкам 100 раз. А можно назвать папку 10_keyword. Поставить 10 эпох. Значит сеть пройдет 10 раз по 10 в итоге снова 100. Но эпохи можно сохранять в разделе Save every N epochs. Поставив например 2. У вас в итоге получится 5 файлов Лора каждый из которых натренирован на разном количестве проходов. Это удобный способ избежать недотренированности\перетренированности, вы просто проверяете все файлы и оставляете лучший.
Mixed precision и Save_precision - точность. Все ставят fp16 и я ставлю. Хотя моя карта поддерживает bf16 и она вроде как точнее и потребляет меньше памяти, но я что-то меняю когда что-то не получается. А тут все получается.
Number of CPU threads per core - количество потоков на ядро. У меня два. У вас гуглите.
Learning rate scheduler - кривая обучения. Не уверен, что вы захотите это читать. Кратко, по какой кривой менять скорость обучения. Мне нравится constant. То есть, не меняется.
seed - хорошая идея его фиксировать для обучения. Потому что например вы сделали Лору, а она не ок. Как можно быть уверенным что просто не повезло с сидом? Такое бывает. Сид не лег на тренировку. Поэтому можно оставить тот же сид, но поменять параметры. Или наоборот, поменять сид не меняя параметры.
Learning rate - он перекрывается Юнит леарнинг рейтом. Не трогаю.
LR warmup (% of steps) - разминочные проходы на низкой скорости. Для константы ставлю 0
Cache latent - кэширует некоторые файлы, что ускоряет обучение
Text Encoder learning rate - управляет тем как ИИ понимает текстовые подсказки. Если ваша модель выдает слишком много нежелательных объектов(могла нахвататься с вашего дата сета) уменьшите это значение. Если наоборот объекты плохо проявляются. Увеличьте или вместо этого увеличьте количество шагов обучения. Стандартное значение 5e-5 что равно 0.00005. Его и оставлю.
Unet learning rate - что-то вроде памяти, имеет информацию о том как элементы взаимодействуют друг с другом. Первое куда стоит смотреть если обучение не получилось. Сначала рекомендую пройтись со стандартными параметрами и что-то крутить только когда вроде все должно было получиться, но не получилось. Если итоговая модель выдает визуальный шум вместо нормального изображения то значение слишком высокое. попробуйте слегка уменьшить и повторить. Тоже не трогаю
Network Rank (Dimension) - ****во первых это повлияет на итоговый размер вашего файла Лора, примерно 1 за 1 мегабайт. Во вторых чем выше значение тем выше выразительность вашего обучения. 128 как по мне является хорошим соотношением. Его оставляем, но если вашей итоговой модели этой самой выразительности не хватает попробуйте увеличить. Быстрая скорость обучения развязывает руки для экспериментов.
Network Alpha - во первых это значение должно быть ниже либо равным network_dim и нужно для предотвращения ошибок точности. Чем ниже значение тем сильнее замедляет обучение. Зачем замедлять обучение? Это точно в другой раз, иначе эта статья не кончится 😅. Я ставлю равным Network Rank (Dimension).
Max resolution - Максимальное разрешение
Stop text encoder training - когда остановить кодер. Никогда не использовал и не видел чтобы кто-то как-то применял.
Enable buckets - даст возможность использовать изображения не квадратным соотношением сторон, обрезав их. Но лучше готовить датасет нормально.
Дополнительные настройки:
Flip augmentation - Если набор совсем маленький можно попробовать включить. Дополнительно создаст отраженные версии картинок
Clip skip - Нейросеть работает слоями. Эта цифра означает сколько последних слоев мы хотим пропустить, обычно она выбирает в зависимости от модели. Тут стоит два так как колаб был рассчитан на аниме модель. Чем раньше остановились тем меньше слоев нейросети обработали подсказку. Комментарий с вики: Некоторые модели были обучены с использованием такого рода настроек, поэтому установка этого значения помогает добиться лучших результатов на этих моделях. Я поставлю 1. Я не тренил на делиберейт и не знаю что тут на самом деле лучше.
Memory efficient attention - если не хватает памяти
Noise offset - Если коротко дает диффузии больше простора для внесения изменений. В основном влияет на яркость\затемненность картинки. Длинно тут. В прошлом гайде ставил 0, с того момента кое-что почитал, ставлю 0.1. Сможем делать более темные и светлые картинки чем по дефолту.
Resume from saved training state - если тренировка по какой-то причине была прервана тут вы можете ее продолжить. Чтобы такая возможность была, поставьте галку на Save training state.
Optimizer - В подробном объяснение будут такие слова как квантование, стохастические градиенты и так далее. Оставляем по умолчанию. Я видел тесты людей, и этот показывал себя хорошо. Думаю ничего не изменилось.
Все настройки можно сохранить чтобы не вбивать заново. В самом верху раскройте меню. Укажите папку куда хотите сохранить, имя файла и расширение json. Save

Итоговые настройки у меня будут такие(дополнительные по умолчанию):


Они зависят от того на чем и что тренируете, если что-то сработает для меня не значит что так же сработает и у вас.
Мой датасет выглядит вот так(выложил на своем бусти, 768х768). Он синтетический, то есть сгенерирован, я натренирую так чтобы бы это лицо я мог вызывать по желанию на разных моделях. Рекомендуется использовать 25-30 фотографий если речь о лице. Для стиля можно и 100, но их можно и не описывать. Посмотрим чего можно добиться с 8ю и с неидеально совпадающей внешностью.
Как видите моя версия файла настройки и название будущего файла Лора совпадает, рекомендую делать так же.

Колличество проходов по папке установлено в 20*5 эпох 100 проходов. Это по каждой картинке, а картинок у нас 8 итого получим 800 проходов. Для лица это нормальная цифра.
Процесс пошел:

Через несколько минут наши лора готовы. У меня они сразу лежат где надо так как я указал сохранять их в папку с лора.
Генерируем:
Rev Animated

Я слишком долго его писал чтобы угодить в клубничку из за пары картинок 😅. Так парюсь будто этот пост соберет больш 20 плюсов 🤔
Deliberate:

Модели разные, а лицо одинаковое. Чтд. Идеальны ли они? Конечно нет. Перечислю ошибки которые вам лучше не допускать чтобы результаты были лучше.
Подход к датасету. У меня он синтетический(это не плохо, просто я не готовил его специально, а взял первое попавшееся), они не супер похожи, он очень маленький и так же важно то что разрешение было 512, а лица на фото мелкие, для лица лучше тренировать на фотографиях примерно от верхней части груди это самое близкое и по пояс самое далекое. (Примерно!).
Тренировка на разрешении 768 чуть улучшило бы ситуацию. Но я этого делать не буду. Это был урок, о том как тренировать на ПК, так как многим не удобно пользоваться коллабом. Как это делать хорошо и на разных вещах таких как предметы, персонажи целиком, стили и тд. В следующих гайдах. Подписывайтесь 🙄.
Поделиться результатом или задать вопрос вы можете в нашем комьюнити.
Больше гайдов на моем канале, подписывайтесь чтобы не пропустить.
На моем бусти вы сможете найти датасеты для обучения, доп материалы к гайдам.



