



Как воссоздать изображение всего по нескольким пикселям
Эта статья дает возможность познакомиться с такой методикой получения и восстановления сигнала, как Compressive Sensing.

Множество всех возможных изображений 2 на 2 с цветами, закодированными одним битом
Пространство изображений огромно, невероятно огромно, но при этом очень мало. Задумайтесь об этом на минуту. Из сетки размером всего 8 на 8 пикселей можно создать 18 446 744 073 709 551 616 различных чёрно-белых изображений. Однако из этих 18 квинтиллионов изображений очень немногие покажутся осмысленными человеческому взгляду. Большинство изображений, по сути, выглядит как QR-коды. Те, которые покажутся человеку осмысленными, принадлежат к тому множеству, которое я называю естественными изображениями. Они представляют крошечную долю пространства изображений 8 на 8. Если мы рассмотрим мегапиксельные изображения, то доля естественных изображений становится ещё меньше, почти ничтожной, однако содержит любое изображение, которое можно придумать. Так чем же эти естественные изображения так уникальны? И можем ли мы использовать эту фундаментальную разницу в собственных интересах?
Спектральное пространство
Рассмотрим два представленных ниже изображения. Оба изображения имеют размер 512 на 512 пикселя. Если вычислить гистограмму значений пикселей, то можно понять, что эти распределения идентичны. И это на самом деле так. Левое изображение такое же, как правое, только пиксели перемешаны случайным образом. Тем не менее между ними есть фундаментальное отличие. Одно выглядит как «снег» на экране старого телевизора, а другое — это лицо человека.

Слева: случайное изображение. Справа: классическое тестовое изображение женщины с тёмными волосами. Оба изображения принадлежат к пространству изображений 512 на 512
Чтобы понять фундаментальную разницу между этими изображениями, нам нужно покинуть пространство пикселей и войти в мир частотного диапазона. С точки зрения математики, преобразование Фурье — это линейное сопоставление пиксельного описания изображения с описанием в виде суммы синусов и косинусов, колеблющихся в двух измерениях. Вместо задания изображения значениями, принимаемыми каждым пикселем, мы задаём его по амплитудам каждого из составляющих его двухмерных синусов и косинусов.
Описание этих двух изображений в пространстве Фурье представлено ниже. Для отображения величины коэффициента Фурье использована логарифмическая шкала. Разница между двумя изображениями теперь очевидна. Одно имеет гораздо больше ненулевых коэффициентов Фурье, чем другое. На языке математики говорится, что естественное изображение является разреженным по базису Фурье. Именно разреженность отличает естественные изображения от случайных. Давайте же используем эту разницу с пользой для себя!
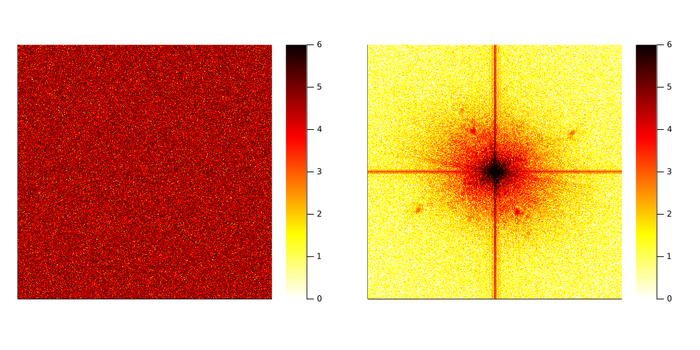
Амплитуда преобразований Фурье обоих изображений. Использована логарифмическая шкала
Воссоздание изображений по нескольким пикселям, задача с высокой степенью неопределённости

Записано всего 10% пикселей
Рассмотрим следующую ситуацию: по какой-то неизвестной причине большинство фотодатчиков камеры оказалось неисправным. Скопировав на компьютер только что сделанную фотографию своей жены (или матери, или друга), вы обнаружили, что изображение получилось таким, как показано выше. Можно ли как-то восстановить изображение?
Допустим, что мы точно знаем, какие фотодатчики исправны. Обозначив как x ∊ ℝⁿ неизвестное изображение (где n — общее количество пикселей, и мы считаем, что оно представлено в виде вектора), а как y ∊ ℝᵐ ненулевые яркости пикселей, зафиксированные датчиками, мы можем записать
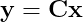
Здесь C — это разреженная матрица измерений m × n. Все элементы, соответствующие неисправным фотодатчикам, равны нулю, и она содержит только m ненулевых элементов, соответствующих исправным датчикам. Следовательно, наша задача — выяснить, каким был x исходного изображения, учитывая, что мы наблюдаем только несколько его пикселей.
С точки зрения математики, это задача с высокой степенью неопределённости. У нас гораздо больше неизвестных, чем уравнений. Эта задача имеет бесконечное количество решений. Значит, вопрос сводится к тому, какое решение из бесконечного множества является тем, которое мы ищем. Естественным способом решения такой задачи было бы принятие того, что решение имеет наименьшую норму ℓ₂. Это можно формализовать как следующую задачу оптимизации:
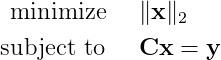
решение которой задаётся так:
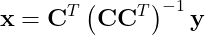
Матрица C соответствует измерениям единичных пикселей, её строки получены из единичной матрицы n × n. В такой ситуации решение задачи оптимизации не особо нам поможет, поскольку оно вернёт только повреждённое изображение (произведение матриц справа сводится к Cᵀ). Очевидно, что это нам не подходит. Но можно ли найти решение получше?
Используем разреженность в спектральном пространстве
При обсуждении уникальных особенностей естественных изображений мы увидели, что они являются разреженными в пространстве Фурье, поэтому давайте этим воспользуемся. Обозначив как Ψ отображение матрицы n × n из пространства Фурье в пространство пикселей, мы получим следующий вид уравнения измерений:
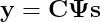
где s — преобразование Фурье x (т. е. x = Ψs). Это по-прежнему задача с высокой степенью неопределённости, но теперь у нас есть дополнительная информация о решении, которое мы ищем. Мы знаем, что оно должно быть разреженным. Введя псевдонорму ℓ₀ для s (т. е. его число ненулевых элементов), мы сможем сформулировать следующую задачу оптимизации:
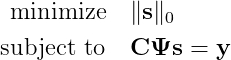
К сожалению, это задача комбинаторики, очень быстро становящаяся нерешаемой. Чтобы найти её решение, потребуется проверить все возможные сочетания. К счастью в своей революционной работе 2006 года Канде et al. [1, 2] показал, что при условии разумных допущений решение изложенной выше задачи можно получить (с высокой вероятностью) при помощи решения более простой задачи:
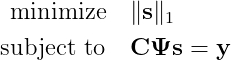
Здесь норма ℓ₁ — это сумма абсолютных значений вектора s. Сегодня хорошо известно, что использование нормы ℓ₁ кроме превращения задачи оптимизации в выпуклую, склонно отдавать предпочтение разреженным решениям. Несмотря на свою выпуклость, эту задачу всё равно может быть достаточно сложно решить на стандартном компьютере. В дальнейшем мы используем более ослабленную версию, задаваемую следующим образом:
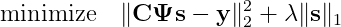
где λ — это задаваемый пользователем параметр, управляющий равновесием между соответствием ограничениям и необходимой разреженностью решения. Эту задачу оптимизации называют Basis Pursuit Denoising. При помощи проксимальных операторов она решается чрезвычайно быстро. Ниже представлена реализация на Julia с использованием StructuredOptimization.jl.
using StructuredOptimization
" " "
Simple implementation of basis pursuit denoising using StructuredOptimization.jl
INPUT
- - - - -
C : The measurement matrix.
Ψ : Basis in which x is assumed to be sparse.
y : Pixel measurements.
λ : (Optional) Sparsity knob.
OUTPUT
- - - - - -
x : Estimated image.
" " "
function bpdn(C, Ψ, y ; λ=0.1)
# - - > Initialize variable.
x = Variable(eltype(y), size(Ψ, 2))
# - - > Solve the compressed sensing problem.
@minimize ls(C * Ψ * x - y) + λ*norm(x, 1)
return ~x
end
Кроме того, мы можем воспользоваться тем фактом, что для спектральных преобразований произведение матрицы и вектора Ψs при помощи алгоритма быстрого преобразования Фурье можно вычислить за O(n log n) операций вместо O(n²).
using StructuredOptimization
" " "
Simple implementation of basis pursuit denoising using StructuredOptimization.jl
INPUT
- - - - -
m, n : Size of the image in both direction.
idx : Linear indices of the measured pixels.
y : Pixel measurements.
λ : (Optional) Sparsity knob.
OUTPUT
- - - - - -
x : Estimated image.
" " "
function bpdn(m, n, idx, y ; λ=0.1)
# - - > Initialize variable.
x = Variable(eltype(y), m, n)
# - - > Solve the compressed sensing problem.
@minimize ls(idct(x)[idx] - y) + λ*norm(x, 1)
return ~x
end
Хотя до сих пор мы предполагали, что Ψ является преобразованием Фурье, в этом фрагменте кода мы использовали косинусное преобразование, являющееся более эффективным преобразованием для изображений. Теперь у нас есть всё необходимое, поэтому давайте вернёмся к исходной задаче. На изображении ниже сравнивается истинное изображение с его реконструкцией при помощи ℓ₁.

Слева: оригинал изображения. Справа: изображение, воссозданное при помощи compressive sensing на основании данных всего 10% пикселей
Даже несмотря на то, что исправно работало всего 10% фотодатчиков камеры, формулировка этой задачи восстановления изображения в рамках Compressed Sensing позволяет нам воссоздать достаточно точное приближение к тому, каким было исходное изображение! Очевидно, что оно всё равно неидеально, однако учитывая обширность пространства изображений и бесконечное количество решений нашей задачи, нужно признать, что результат довольно хорош!
Заключение
Методика Compressed Sensing совершила революцию в сфере обработки сигналов. Если мы заранее знаем, что сигнал, с которым работаем, разрежен по указанному базису, то compressed sensing позволяет восстановить его по гораздо меньшему количеству сэмплов, чем предполагается по теореме выборки Найквиста-Шеннона. Кроме того, она позволяет значительно сжимать данные непосредственно на этапе получения, уменьшая таким образом необходимый объём хранилища данных. Также Compressed Sensing привела к возникновению неожиданных новых технологий, например, однопиксельной камеры, разработанной Университетом Райса, или новых техник обработки для создания визуализаций МРТ в медицине. Я не сомневаюсь, что в ближайшие несколько лет мы станем свидетелями множества новых способов применения этой методики.
Compressed sensing — это гораздо более глубокая область математики, чем можно судить по этому ознакомительному посту. Существует ещё множество не рассмотренных нами вопросов, например:
- Каково наименьшее количество необходимых измерений?
- Могут ли некоторые измерения быть информативнее других?
- Как выбирать эти измерения, имея базис Ψ?
- Существуют ли другие нормы, лучше подходящие для изображений?
Для ответа на эти вопросы потребуется гораздо больше математики, чем можно представить в посте. Если вы хотите знать больше, то крайне рекомендую изучить оригиналы статей, ссылки на которые я указал в конце. Также стоит изучить потрясающий веб-сайт Numerical Tours Габриеля Пейре или последнюю книгу Брантона и Кутца [3], а также соответствующий канал на YouTube (здесь и здесь).
Ссылки на научные работы
[1] Candès E., Romberg J., Tao T. Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied mathematics. 58(8): 1207–1223. 2006.
[2] Candès E. Compressed sensing. IEEE Transactions on Information Theory. 52(4): 1289–1306. 2006.
[3] Brunton S. L. and Kutz J. N. Data-driven science and engineering: machine learning, dynamical systems, and control. Cambridge University Press, 2019.
Показать полностью
12
Урок по Машинному обучению

Показать полностью
1
Ответ на пост «Войти в IT или не знаю чо хочу, хочу всё другое»
Попытаюсь разложить вопрос "Хочу в IT, но не знаю кем и как "
В принципе, много толковых комментов, но чаще они довольно узкие, каждый кричит из своего болота.
Самый толковый коммент: "Ты хочешь не в IT, а денег"
Читать, что люди пишут про популярные языки программирования, необходимость изучать теорию графов и дискретную математику и тому подобное, мало чем поможет в выборе, это бесконечные холивары.
Вместо это нужно понять маленькую вещь, что каждому - свое и ты не поймешь, пока не попробуешь.
ВАЖНЫЙ МОМЕНТ:
Надо возвыситься на холиварами типа "c# vs java" и "python - зло" и взглянуть шире, что оказывается, IT - это не только программисты, но еще и менеджеры, дизайнеры, аналитики, маркетологи.
И все они тоже зарабатывают довольно прилично и в их профессиях есть творческая составляющая.
Я работаю интернет-маркетологом и вижу, что мало кто представляет что может делать маркетолог.
Причем, внутри самой профессии тоже есть развитие.
Лично мне интересна автоматизация, я пишу скрипты и программы для повышения продуктивности на JS и Python, аналитика - изучаю Google Analytics, базу Data Science для анализа данных, более продвинутые инструменты для самой рекламы, типа Ad Manager и CM360.
Зарплата при этом не уступает программистам.
Так что если ты хочешь "войти в IT", то сначала окинь его широким взглядом и подумай, может тебе будет ближе что-то другое, нежели software engineering, который зачем-то отождествили с понятием IT.
Показать полностью
Войти в IT или не знаю чо хочу, хочу всё другое

Всем привет, буду рад, если люди с опытом пробегутся по моему очерку хотя бы наискосок и что-то напишут в комментах дельное.
Жил я себе жил до 35 лет, работал с людьми в прямом смысле - реабилитационный фитнес, ЛФК, всякие постуральные гимнастики, пилатесы итд. Прошёл путь от простого фитнес-тренера, до управляющего большого тренажерного зала и полного фриланса с работой исключительно на себя любимого - самый безгеморный вариант в сфере, если есть соответствующие скилы.
И вот с годами, работа с людьми стала откровенно напрягать, вернее ее издержки - то есть для роста заработка мне уже надо не идти на какой-нибудь специфический семинар по работе с дистазом после беременности например, а тупо упарываться в поиск клиентов с дефолтными проблемами: "болят колени, сутулюсь, хочу ж0пу итд итп", потому что это 99% запросов людей.
Посему я понимаю, что как специалист я стагнирую - я могу пойти на учёбу, но какой толк, если применение на практике будет крайне редким.
Параллельно с этими мыслями, около полугода назад, я стал пробовать немного программировать. Естественно по запросу: "ЯП для новичка" мне вывалило Пайтон в избытке с вкраплениями JS. Сел я в итоге за питон, прошел пару курсов для начинающих, пописал всякие крестики-нолики, попробовал что-то попарсить, поковырял ТГ ботов, немного покурил литературу по ООП и ФП, но не стал ни во что углубляться серьёзно. Но в целом меня затягивало и я получал удовольствие от процесса.
Далее начал смотреть, а где вообще этот питон применяется. Ну и конечно самой хайповой темой был DataScience. Потекло на меня мульён предложений от всякого рода цыгнан скилбоксовых и тому подобных, о том как меня сделают адептом топ профессии 21 века. Ну я пошёл на курсеру, помедитировал над циферками в комбинаторике, линейной алгебре, матане и теорвере со статистикой. Понял, что это всё же больше про математику чем про программирование, хоть в целом нишевые библиотеки питона эту математику и сильно облегчают.
В итоге вернулся к тому, что всё же хочу больше программировать, только вот не знаю что и на чём и куда податься. Естественно начал смотреть контент на эту тему, там естественно каждый кулик своё болото хвалит в историях вроде "стал фронтэнд разрабом в 40 в Канаде".
Столкнулся также с парадоксом, что тот же питон весьма популярен, но адекватной для новичка работы на нём, что на фрилансе, что на галере почти нет и порог вхождения в любую сферу, где главенствует питон очень высок. С другой стороны есть JS со своим реактом в связке с CSS и html и обещаниями авторов, что любой бомж с этими навыками однажды что-то найдёт. С третьей стороны утверждают, мол не сцыте посоны, пропарите C++ познаете дзен, а не пропарите, значит программирование - не ваше.
Далее идут зазывалы на всякого рода DevOps направления. Но насколько я понял, это на редкость УГ, в котором творческая составляющая - написать небольшой скриптик на том же питоне в лучшем случае (поправьте, если там весело :-/).
Долго я всё это смотрел и анализировал, поглядывая на вакансии. Понял, что нужен некоторый джентельменский набор, с которым можно хоть где-то вклиниться стажером:
1. Базовый уровень пары высокоуровневых ЯП с пониманием основных фреймворков: JS (react), Python (Django), чтобы при необходимости быстро углубиться в более подробное изучение.
2. Умение работать под Linux
3. Понимание git и docker технологий.
4. дальше особо не придумал -) может это php или какой-нибудь Go или Ruby. Или что-то низкоуровневое, хотя сомневаюсь.
Буду признателен, если кто-то что-то добавит к ложившейся у меня картинке или подскажет какой-то алгоритм со своей колокольни с опытом наступания на соответствующие грабли.
Показать полностью
1
Данные для датасета
Всем привет! Я студент, работаю ML инженером в компании уже 1.5 года. На данный момент меня направили заниматься проектом по распознаванию лиц. И тут я заинтересовался: а как можно собрать специфичный датасет, который не найти в открытом доступе? Я слышал, что если кому то недостаточно данных, то можно обратиться в специальные компании, которые сами сделают подходящий размеченный датасет. Также я нашел такой инструмент как Яндекс Толока, но кажется она не совсем тривиальная в сборе данных. Кто сталкивался с такой проблемой? Что вы делаете, когда не хватает бесплатных датасетов? И часто ли у вас происходят такие трудности, или Яндекс толока и бесплатных решений хватает?

Паша Технарь

P.S. Я понимаю, что может быть специфичненько, но почему бы нет
Показать полностью
1

Сможете найти на картинке цифру среди букв?
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi

Программа обучения Data science для самостоятельного изучения
Я решил собрать некоторые материалы в одном месте для всех тех, кто хочет войти в науку о данных.
Некоторые курсы я считаю обязательными (их я выделил жирным), некоторые желательными для более глубокого понимания области. Я считаю, что прохождение «жирных» курсов позволит вам приобрести некое понимание о data science, пройдя же все курсы, вы сможете претендовать на начальную позицию.Этот текст - моё видение, некоторые дополнительные ссылки я приложу в конце поста. Буду рад любой конструктивной критике.
1. Основы программирования
Введение в python (обязательно):
https://stepik.org/course/67 — введение в Питон
https://stepik.org/course/512 — введение в Питон чуть более глубокое.
Без программирования аналитику данных представить сложно.
2. Основы математики и статистики
Высшая математика и теория вероятности (желательны для глубокого понимания):
https://stepik.org/course/95/promo — введение в матанализ
https://stepik.org/course/716/promo — матанализ 1
https://stepik.org/course/711/promo — матанализ 2
https://stepik.org/course/2461/promo — курс по линейной алгебре
https://stepik.org/course/3089 — теория вероятности
Подготовительный курс по R (язык программирования для работы с данными):
https://stepik.org/course/497/promo — курс по языку программирования R
Высшая математика позволит вам понимать, что вообще происходит. Без высшей математики вы будете в науке о данных как разнорабочий на стройке — положить кирпичи можете, положить цемент можете, а вот построить крепкую стену/дом без прораба уже не сможете. Так и в науке о данных — будете знать, что такое классификатор, что такое регрессия, алгоритм k-соседей, а вот построить хорошую предсказывающую модель не сможете.
Статистика (обязательно):
https://stepik.org/course/2152
Статистика нужна. Статистика позволяет понять, как работать с данными в первом приближении.
Курсы по алгоритмам и технологиям (не обязательно, но желательно для понимания):
https://stepik.org/course/2614 — базы данных
https://stepik.org/course/217— алгоритмы
https://stepik.org/course/1547 — алгоритмы 2
Последние три курса нужны для лучшего вхождения в сферу и понимания того, что вы делаете. Так, к примеру, знание базовой алгоритмистики позволит вам избежать очень большого количества глупых ошибок.
3. Машинное обучение
Введение в машинное обучение и искусственный интеллект (обязательно):
https://stepik.org/course/4852 — введение в машинное обучение
https://stepik.org/course/401 — машинное обучение
https://stepik.org/course/8057 — машинное обучение
Тут без пояснений — если вы учите data science, то сам data science учить придется.
4. Специализация
Специализация (крайне желательно):
https://stepik.org/course/54098 — обработка текста
http://web.stanford.edu/class/cs224n/ — обработка текста
http://cs231n.stanford.edu/ — обработка изображений
https://stepik.org/course/50352 — компьютерное зрение
Специализация позволит вам применить полученные ранее навыки. Список курсов приведен крайне короткий, и вам придется самим выбирать в каком направлении двигаться дальше.
Полезные материалы
Полезности:
https://vk.com/mlcourse - классная группа, где собрано много полезной информации.
https://habr.com/ru/company/ods/blog/322626/ — курс по data science.
Источники:
Мой путь в data science — история успеха.
https://habr.com/ru/company/plarium/blog/505458/ — история успеха 2.
https://docs.google.com/document/d/1TbMBahh6PNz-qK5hCojfrTJj... (сравнительная таблица).
https://youtu.be/w-IdSp_mQuM — ещё один план-трек.
Показать полностью