


Люди знающие AutoHotKey помогите!
Суть в том, что я очень люблю музыку. Вероятно, больше каждого здесь. Неважно.
Мне нужно сделать скрипт под .ахк на переключение музыки в вк плеере, в свёрнутом окне. То есть, чтобы определённой клавишной, я имел возможность скипать музыку, играя в ЛОТР, допустим.

Лень - лучший мотиватор
История простая, офисная, про заказную разработку и лучший мотиватор.
Попал как-то коллеге небольшой, но нудный заказик - написать скрипт для передачи данных в систему. Скрипт простой, но нужно продублировать десять раз и каждый раз со своими настройками (простой копипаст не катит). Цена скрипта - кусок (хотя это столько не стоит, просто коллега наглеет), а за десять дублей соответственно десять кусков. Ну там ещё скидочка за оптовый заказ - 9 500.
Оплатили, сделал, сдал - все счастливы.
Месяц спустя заказ уже для меня - сделать всё то же самое, но до восьмидесяти дублей. Коллега задачу на меня всю повесил (мол, занят), говорит "не думай, просто дублируй скрипт, меняй тут, тут, тут, тут и тут, а ещё тут, тут, тут и тут, а потом проверяй так и так, а ещё так и эдак, но всё это в количестве восьмидесяти штук". Я не стал брать восемьдесят тысяч, взял семьдесят, сел делать в ожидании уныло просрать две недели. И чё-то так лениво было начинать, что я первый день всё откладывал, второй день всё откладывал, а потом и третий как-то утратил, занимаясь другими задачами. В итоге сел на четвёртый, посмотрел, подумал, понял, что не хочу я так две недели тратить и оптимизировал скрипт (или автоматизировал?) таким образом, чтобы его действительно можно было внедрять копипастом.
За два вечера растиражировал нужным образом и думаю, как же здорово, что стало лень.
Показать полностью

Возвращаем панель смайлов ВК

Собственно, просто скрипт, который возвращает на место панель последних использованных смайлов в диалогах ВК. Писал для себя, но, надеюсь, кому-то еще будет полезен :)
Установить: https://greasyfork.org/en/scripts/25351-vk-recent-smiles-pan...
(требуется установленный Greasemonkey для Firefox или Tampermonkey для Google Chrome).

Разбор скрипта для командной строки Linux. Часть 2
В прошлой части разбора нам удалось сократить и сделать код более читабельным. В этой части, мы попробуем изучить используемые в скрипте инструменты и сделать код ещё лучше.
Хоть скрипт теоретически был рассчитан на любые доменные имена. На деле, проверка на доменной имя pikabu.ru, дала следующий результат:
91.228.152.0 - 91.228.155.255
MNT-FIRSTCOLO
91.228.152.0/22
Как видим, 2-я строчка тут явно лишняя. Из этого делаем вывод, что скрипт не работает правильно для всех доменов. В вопросе нахождения сетей, которые принадлежат домену, я увы недостаточно компетентен. Поэтому моей целью будет лишь добиться схожего результата и разобрать общие проблемы, которые актуальны для большинства скриптов.
И так, код который мы получили в конце первой части:
#!/bin/bash
####PART 1####
if [[ -z "$1" ]]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
####PART 2####
echo "*********************************************"
echo "Get A records from DNS:"
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
####PART 3####
echo "*********************************************"
echo "Get NS records from DNS:"
dig $1 NS | grep "^$1" | awk {'print $NF}' | while read nsserv
do
nsname=${nsserv:0:${#nsserv}-1}
echo "=================================="
echo "NS: $nsname"
dig @$nsname $1 A | grep "^$1" | grep -o -E "$ip_re" | tee -a $f_out
done
####PART 4####
echo "*********************************************"
echo "Resolve ip range from whois service:"
sort -h $f_out | uniq > $f_tmp
rm $f_out
cat $f_tmp | while read ip
do
echo "Get ip range for $ip"
whois $ip | grep -E -i "inetnum|route|netrange|cidr" >> $f_out
done
####PART 5####
echo "*********************************************"
echo "Result"
echo "*********************************************"
sort $f_out | uniq | while read range
do
echo "${range:16}"
done
Плюс ко всему, код был разделён на 5 частей, для лучшей навигации.
Для начала, вернемся ко 2-ой части кода. А конкретно к этим строкам:
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
Лишь на данном моменте тут была замечена ошибка. Предположительно, автор хотел получить данные как по доменному имени vk.com, так и www.vk.com, однако забыл дописать это программе dig. Внесем правки:
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig www.$1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
Далее было замечено, что программа dig умеет принимать множество доменных имен, воспользуемся этим:
dig {www.,}$1 A | grep -E "^(www.|)$1" | grep -o -E "$ip_re" | tee "$f_out"
Уже лучше, вместо 2-ух строк, теперь лишь одна.
Программа dig выписывает множество лишней информации:
; <<>> DiG 9.9.5-9+deb8u6-Debian <<>> vk.com A
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10732
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1280
;; QUESTION SECTION:
;vk.com. IN A
;; ANSWER SECTION:
vk.com. 33 IN A 87.240.131.118
vk.com. 33 IN A 87.240.131.117
vk.com. 33 IN A 87.240.131.120
;; Query time: 0 msec
;; SERVER: 192.168.3.1#53(192.168.3.1)
;; WHEN: Fri Jun 24 16:27:13 CEST 2016
;; MSG SIZE rcvd: 83
Автор дальнейшими действиями извлекает из этого вывода ip адреса. Но если посмотреть мануал к программе dig, то мы увидим что есть опция +short, которая выписывает лишь ip адреса, без лишней информации. Так, мы можем сократить команду, всего до:
dig +short {www.,}$1 A | tee "$f_out"
И как следствие, мы получаем нужный нам результат, без лишних команд и регулярных выражений. Поэтому обычно советую, перед тем как писать сложные конструкции, сначала изучите инструмент с которым вы работаете.
Теперь можем перейти к 3-ей части, начнем с первых команд:
dig $1 NS | grep "^$1" | awk {'print $NF}'
Снова используя параметр +short, получится:
dig +short $1 NS
Далее, результат с этой команды посылается в цикл while:
dig +short $1 NS | while read nsserv
do
nsname=${nsserv:0:${#nsserv}-1}
echo "=================================="
echo "NS: $nsname"
dig @$nsname $1 A | grep "^$1" | grep -o -E "$ip_re" | tee -a $f_out
done
Думаю сразу видно, что к последней команде в цикле можно применить опцию +short:
dig +short @$nsname $1 A | tee -a $f_out
Так мы опять избавились от лишних действий.
Но вернемся к перемененной nsname, тут автор хочет удалить точку на конце переменной. В коде это было сделано без внешних программ(sed,awk,...), что очень хорошо, но можно ещё проще:
nsname=${nsserv:0:-1}
Подробнее о всех возможностях работы со значениями переменных, можете прочитать на bash-hackers.org.
В 4-ой части кода, есть не очень красивые решения, которые связаны с временными файлами, мы исправим это во время избавления от временных файлов. Так же не понятно, зачем в sort был использован параметр -h(human-numeric-sort). Т.к. sort использован только для дальнейшего uniq, то можно использовать sort без параметров. Но мы будем использовать более правильную сортировку ip адресов:
sort -n -t . -k 1,1 -k 2,2 -k 3,3 -k 4,4 $f_out | uniq > $f_tmp
В данном случае, ip адреса будут отсортированы по числовым значениям каждого столбца.
5-я часть кода, это только вывод результата, возможно я бы по другому выписал сети, т.к. выписывание после 16 символа, это не самый лучший вариант, но это не столь важно.
Переменные o_re и ip_re, нам уже ни к чему, поэтому можем их удалить.
После всех правок код выглядит следующим образом:
#!/bin/bash
####PART 1####
if [[ -z "$1" ]]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
####PART 2####
echo "*********************************************"
echo "Get A records from DNS:"
dig +short {www.,}$1 A | tee "$f_out"
####PART 3####
echo "*********************************************"
echo "Get NS records from DNS:"
dig +short $1 NS | while read nsserv
do
nsname=${nsserv:0:-1}
echo "=================================="
echo "NS: $nsname"
dig +short @$nsname $1 A | tee -a $f_out
done
####PART 4####
echo "*********************************************"
echo "Resolve ip range from whois service:"
sort -n -t . -k 1,1 -k 2,2 -k 3,3 -k 4,4 $f_out | uniq > $f_tmp
rm $f_out
cat $f_tmp | while read ip
do
echo "Get ip range for $ip"
whois $ip | grep -E -i "inetnum|route|netrange|cidr" >> $f_out
done
####PART 5####
echo "*********************************************"
echo "Result"
echo "*********************************************"
sort $f_out | uniq | while read range
do
echo "${range:16}"
done
В следующей(заключительной) части, мы избавимся от временных файлов и немного поработаем с выводом. А пока подумайте, почему лучше не использовать echo в скриптах? И ради примера, есть задачка на echo в комментариях.
Спасибо за внимание, надеюсь данный пост окажется для вас полезным.
P.s. если был непонятен как-то шаг или конструкция в коде, то жду ваших вопросов в комментариях.
Показать полностью
Разбор скрипта для командной строки Linux. Часть 1
Недавно в сообществе GNU/Linux появился пост с программой для Shell-а от PetRiot. В комментариях началось обсуждение целесообразности самой программы, но этот вопрос мне не интересен в полной мере, а вот качество самого кода хотелось бы улучшить. Поэтому я решил проанализировать код скрипта и дать пару советов как можно улучшить и сократить код. Надеюсь данный разбор будет полезен как для автора скрипта, так и для остальных читателей.
Начнем с первой строчки:
#!/bin/sh
Shell(sh) - самый старый интерпретатор командной строки, увы у него отсутствует множество возможностей, поэтому лучше использовать /bin/bash.
Данный код работает и в sh, но в дальнейшем мы будем использовать bash:
#!/bin/bash
Далее идет создание(запись названия файлов в переменные) временных файлов:
f_out=.get_ip_ranges
f_tmp=.ips
О том, что эти файлы временные, нам говорит то, что в конце их удаляют:
rm $f_out
rm $f_tmp
Тут сразу бы хотелось отметить несколько вещей:
1) создание временных файлов не всегда хорошо само по себе
2) названия могут конфликтовать с другими файлами, так мы можем случайно затереть важный файл с таким же названием
3) удаление временных файлов в конце кода. В случае ошибки удаление может не сработать(для данного случая маловероятно, но мы же стремимся к хорошему коду)
Первый пункт слишком спорный, поэтому я его проигнорирую.
Но всегда можно обсудить вопрос целесообразности временных файлов, в комментариях к посту.
Для решения второго пункта, я бы посоветовал использовать команду mktemp:
f_out="$(mktemp)"
f_tmp="$(mktemp)"
Теперь временные файлы однозначно уникальные, но нужно обеспечить их удаление в конце работы программы(в конце работы программы != в конце кода программы).
Для решения 3 пункта, используем команду trap:
trap "rm -f $f_out $f_tmp" EXIT
Команда trap запустит посланный ей код сразу после завершения программы, тем самым мы можем быть уверенны что файлы будут удалены. Также мы добавили параметр -f команде rm, который нужен для игнорирования ошибок и убирает вопросы о удалении.
Перед тем как перейти к следующей части, хотелось бы добавить ещё одну важную деталь в скрипт - проверку входных параметров.
Автор забыл упомянуть, что для запуска скрипта нужно обязательно послать один аргумент - название сайта. Если этого не сделать, то работа программы будет не очевидна. Добавим в начало проверку:
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
Если первый аргумент пустой, то выписывается текст ошибки на stderr и программа завершается. В дальнейшем данное решение можно улучшить, создав функцию для ошибок.
Теперь начало кода выглядит так:
#!/bin/bash
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
Идем дальше:
dig $1 A | grep "^$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
dig $1 A | grep "^$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" > $f_out
dig $1 A | grep "^www.$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
dig $1 A | grep "^www.$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" >> $f_out
Тут начинаются любимые всеми регексы. Увы читабильность кода плохая, поэтому попробуем это исправить:
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" > $f_out
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" >> $f_out
Мы создали переменную o_re где находится повторяющая часть ip_re регекса и саму переменную ip_re.
Теперь код короче, но можно сократить ещё:
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
Используя команду tee мы выписали результат команды в командную строку и одновременно в файл $f_out.
Исправив с учетом этого остальную часть кода и получим:
#!/bin/bash
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
echo "*********************************************"
echo "Get A records from DNS:"
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
echo "*********************************************"
echo "Get NS records from DNS:"
dig $1 NS | grep "^$1" | awk {'print $NF}' | while read nsserv
do
nsname=${nsserv:0:${#nsserv}-1}
echo "=================================="
echo "NS: $nsname"
dig @$nsname $1 A | grep "^$1" | grep -o -E "$ip_re" | tee -a $f_out
done
echo "*********************************************"
echo "Resolve ip range from whois service:"
sort -h $f_out | uniq > $f_tmp
rm $f_out
cat $f_tmp | while read ip
do
echo "Get ip range for $ip"
whois $ip | grep -E -i "inetnum|route|netrange|cidr" >> $f_out
done
echo "*********************************************"
echo "Result"
echo "*********************************************"
sort $f_out | uniq | while read range
do
echo "${range:16}"
done
Так код выглядит уже лучше. Для дальнейших исправлений надо углубиться в работу программы, поэтому это будет в следующей части разбора.
Спасибо за внимание, надеюсь данный пост окажется для вас полезным.
P.s. прошу прощение за орфографические ошибки, мне бы точно не помешал разбор моего текста с орфографической точки зрения :)
Показать полностью

Как гарантийно и без труда победить в конкурсе комментариев
В одном из пабликов ВК был конкурс репостов: Комментарий, продержавшийся 30 минут последним, побеждает. Призом в конкурсе был сладкий приз из местной кофейни.
Когда начался конкурс, я немного подумал и придумал, как можно автоматизировать мою победу в конкурсе.
Я использовал свой давно и горячолюбимый AutoHotkey script. Да, я знаю, что есть десяток более удобных и простых способов автоматизации, но уж сделал что сделал.
Для начала я написал бесконечный цикл, который раз в 25 минут сделает 10-секундное звуковое предупреждение, а затем откроет браузер с ссылкой на пост, определит, открылась ли страница, напишет туда "Хочу победить!" и закроет вкладку, после чего развернёт ранее открытое окно.
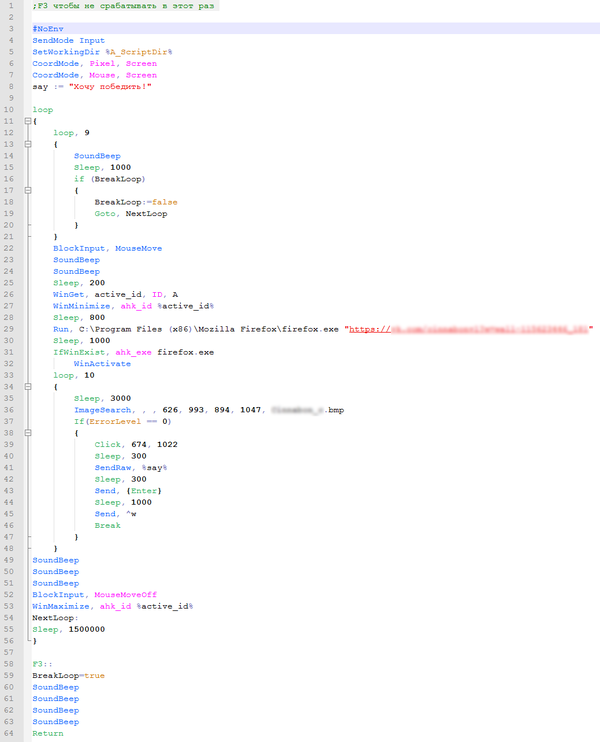
Далее построчно:
1-5 стандартные настройки скрипта
6-7 установил определение координат (мне так удобнее(см. документацию по imagesearch))
8 текст для вставки
12-21 десятисекундное предупреждение о начале работы кода (подразумевается, что нажатие клавиши F3 в это время прервёт цикл на эти 25 минут)
22 блокировка мыши, чтобы ничего случайно не испортить
26 получение ID активного окна, чтобы развернуть его назад после работы цикла
27 свернуть активное окно
29 открытие поста в нужном мне браузере
31-32 активация браузера
36 поиск поля для ввода комментария (сохранил скриншот поля для ввода в .bmp)
37 блок инструкций, если изображение (поле ввода) найдено на экране => страница открылась корректно
39 нажать на поле для ввода
41 вписать текст комментария
43 отправить
45 закрыть вкладку браузера (ALT+W)
49-51 звук об успешном написании комментария
52 разблокировка мыши
53 восстановление свёрнутого ранее окна
54 точка входа, если был нажат F3
58 блок инструкций при нажатии F3
По началу всё было замечательно, но со временем, другие начали замечать, что я пишу ровно один и тот же текст и ровно в одно и то же время, от чего начали задавать вопросы и устраивать "проверки". В итоге я немного модифицировал код, я сделал из переменной say массив фраз для вставки и время цикла сделал случайным в диапазоне от 15 до 25 минут. Плюс, я сделал определение, что мой пост последний ((15to25)*2 > 30min => победа), и если это так, то будет сделан скриншот страницы, затем открывается вкладка браузера с написанием сообщения самому себе (сижу с телефона) и я пишу себе уведомление о победе.
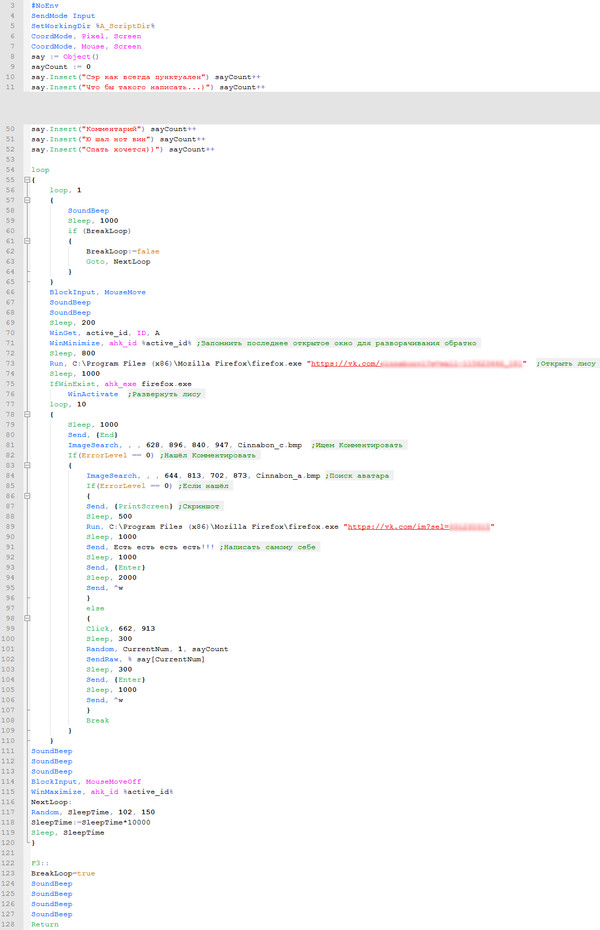
Построчно:
8 определение переменной массива
9 число индекса переменной (будет случайным для случайной фразы)
10-52 ввод значений в массив и подсчёт индекса массива (не уверен, что этот способ самый правильный, но придумал только так)
84 поиск моего аватара в месте последнего комментария
85-96 скриншот, открытие вкладки сообщения, написание сообщения себе же и закрытие вкладки
97-107 написание комментария
101 генерация случайного числа для выборки элемента массива (от 1 до "кол-во эл-тов")
117 рандом времени в диапазоне 15-25 минут (SleepTime указывается в милисекундах, в секунде 1000мс, поэтому я округлил рандом.
В итоге программа сама за меня писала разные комментарии в разном временном периоде. Так же, я иногда заходил на пост самостоятельно и от себя писал другие комментарии, отвечал на комментарии других людей в мой адрес, что в итоге убрало все подозрения. Меня проклинали, ругали, что если бы не я, то уже победили бы, и вот, на третий день розыгрыша мне удалось в районе 5 утра победить. Проснувшись, я увидел скриншот экрана и сообщение самому себе. Победа. :)
Я успешно забрал свой приз и по просьбе администратора прислал ему отчётное фото. Я нарочно сделал очень сонное лицо, будто не спал три дня.
Показать полностью
2

"Программирование" светового шоу на Novation LaunchPad
Здравствуйте, товарищи!
В недавнем посте от @giepol промелькнула просьба рассказать о том, как вообще все это делается. Были озвучены две догадки:
1) Нажимание на кнопочки с эффектами под музыку
2) Собственно, сэмплы и мастерство.
Ну, про второй способ товарищ @giepol думаю, расскажет сам - там необходимо работать с программой Ableton Live, насколько мне известно. Я же, будучи "веганом" (пользуюсь FLStudio) коснусь больше теоретической части.
У серии Launch от Novation (сейчас мы говорим про до-rgb эпоху) есть два типа подсветки кнопок - только красным диодом или двумя диодами - красным и зеленым. То есть возможен любой цвет, который можно получить смешением различной яркости этих двух диодов рассеивающим пластиком кнопки.
У меня получались оттенки зеленого (вплоть до оливкового и хаки), оттенки желтого (от красного до оранжевого).
Как контрол понимает, каким цветом какую кнопку зажечь?
Все просто. Цвет кодируется численным значением от 0 (выключен/черный) до 127 (максимальная яркость двух диодов, на выходе имеем зеленовато-желтый). Кнопки определяются номером CC.
В нашем примере используем Launch Control. С помощью редактора изменим раскладку кнопок - все будут у нас CC, то есть контролы. Так то весь нижний ряд - это ноты, но в программировании их будет трудно запоминать:

Для подачи на него команд будем использовать скриптовый программер игровых контроллеров GlovePIE с костылем из Midi-OX. Я пробовал настроить без мидиокса, но походу гловпай не умеет одновременно принимать и передавать комманды на одно и то же устройство. В итоге имеем такую схему:
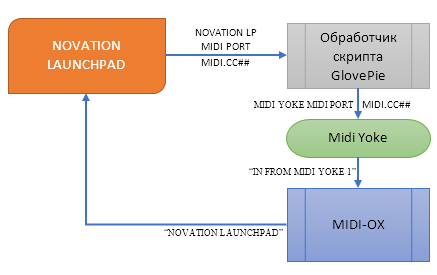
То есть все что делает MIDI-OX в данном случае - тупо переадресует приходящие команды с интерфейса Midi Yoke (виртуального, к слову) на "железный" ланчпад/ланч контрол.
Самый простой скрипт в этом случае будет звучать так:

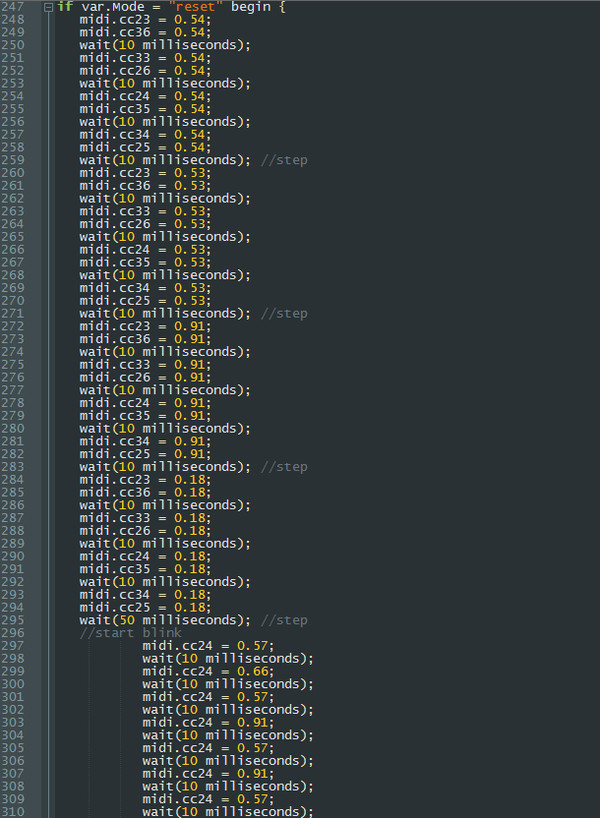
Анимацию же можно делать через процедуры. И тут у нас образовывается косячок. Дело в том, что сам скрипт гловпая - не линеен, в нем, допустим, не работают циклы. Потомы что сам скрипт есть по сути цикл, который выполняется каждую 1 миллисекунду (или даже чаще) пока не будет команды exitprogram;
Управлять этим хаосом можно только с помощью стандартных if {} конструкций, операторов wait; и переменных var.ИмяПеременной в качестве переключателей. К примеру:
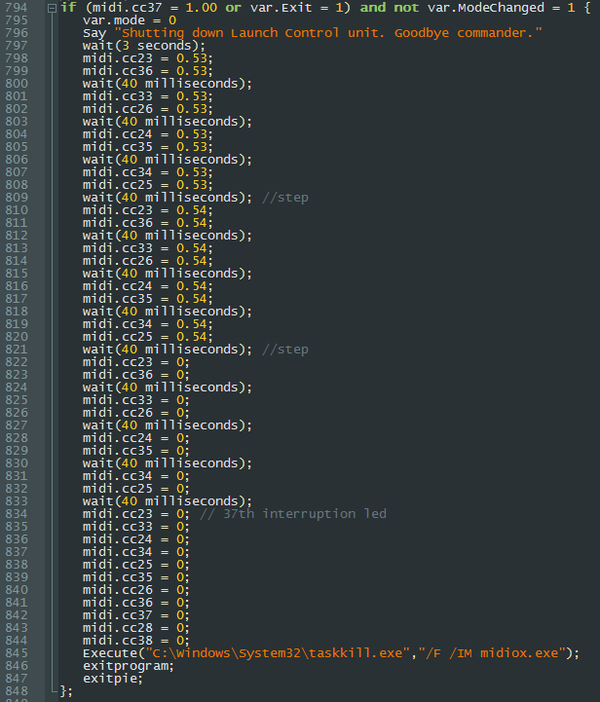
То есть при нажатии на кнопку cc37 (угловая кнопка справа) и если при этом режим контроллера не изменен - ланчконтролл перемигивается красным цветом и потухает.
Покажу наглядно. Вот на этом видео:
С 1:40 обрабатывается этот код:
Надеюсь, все было достаточно информативно, лаконично и не скучно.
Если пожелаете - могу подробно рассказать, для чего все это было задумано.
Я бы не советовал владельцам ланч-контрола извращаться анимацией песен на одной линии но - у меня ж отпуск впереди, черт возьми! Наберет пост много рейтинга - запилю "виджеинг" на этой доске на какую-нибудь песню.
Показать полностью
5
1