

"SZHATIE" POWER SUPREME!

и бонус:
Работа установки 1К17 «Сжатие» в режиме "ЖМЫХ"

Показать полностью
2
и бонус:
Работа установки 1К17 «Сжатие» в режиме "ЖМЫХ"
Мало того что реклама игнорирует то что это тебя не интересует , она ещё и вырвиглазная.
Без боли на это не взглянешь.
Видимо денег не хватило на нормальную рекламу (
7 шакалов из 10

Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509

Всем привет! Недавно записал видео о том, как устроен формат mp3. Делаю для Ютюба, но еще выложил на Пикабу. Самый первый комментарий был - зачем делать видео, где достаточно текста и картинок.
Справедливое замечание, поэтому отныне, специально для Пикабу, буду делать текстовые версии выпусков. Информация абсолютно та же, но вид другой. Думаю многим так будет удобнее. Итак, ниже видеоверсия, а еще ниже - текст с картинками.
JPEG - это формат сжатия изображений, который позволяет уменьшить размер файла в 20, 30, 100 раз! В посте НЕ будет описана история создания формата, его плюсы и минусы и самые тонкие технические детали. Это обзорное повествование о том, как происходит сжатие (в очень упрощенном, и от этого более понятном виде) и как работает технология. Пикабушников не удивить шакалами, но здесь как раз объясняется, откуда они берутся.
Вообще, если бы не джипег, то интернет сейчас был бы совсем другим. Думаю, внешне он напоминал бы сайты 90-х. И мы бы не смогли запросто инстаграммить все подряд и смотреть фотки котиков на телефоне) К тому же, этот алгоритм лежит в основе сжатия видео! Так что без него не было бы ни этого ролика, ни ютюба, ни даже фильмов онлайн без регистрации и смс!
Но чтобы понять, насколько гениальная штука Джипег, нужно разобраться, как кодируются изображения без сжатия. Возьмем картинку 1000 на 1000 точек. Каждый пиксель – это смесь трех составляющих, трех цветов – красного, зеленого и синего. Одна составляющая кодируется, как правило, 8 битным числом.
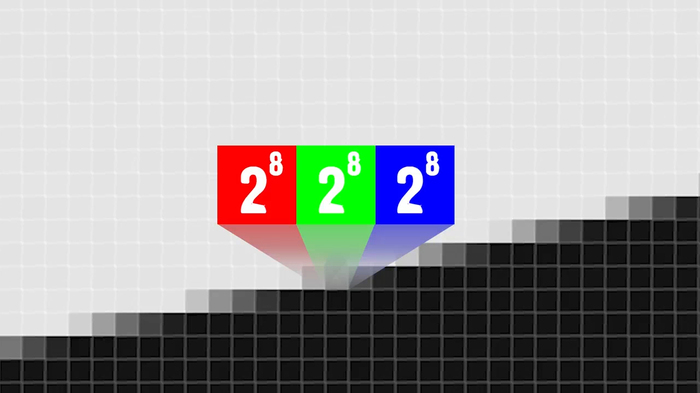
Нетрудно посчитать, что такая картинка без сжатия будет весить:
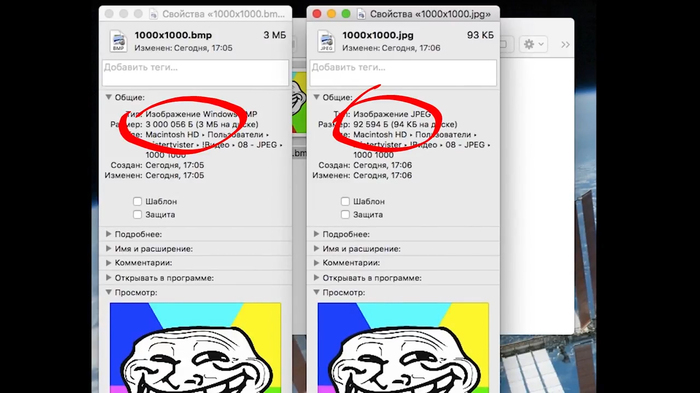
8 х 3 х 1000 х 1000 = 24 000 000 бит, то есть 3 мегабайта.
Но если сохранить ее в джипеге, она может занимать, например, 90 килобайт. То есть в 33 раза меньше! Да, качество чуть-чуть теряется, но не в 30 раз ведь! Как же это работает?
Итак. Алгоритм сжатия джипега можно разбить на несколько основных этапов
1 - Цветовое пространство
Этап первый – перевод в другое цветовое пространство, в котором разделены яркостная и цветовая составляющие. На этом шаге потерь не происходит, ведь каждый пиксель по-прежнему состоит из трех компонентов. Только теперь это яркостная компонента и две цветовых. Короче, если упростить, происходит следующее: создается Ч/Б изображение и цветовая маска к нему, вот и все!

2 - Ресемплинг
Возникает вопрос, зачем? А все дело в нашем зрении! Человеческий глаз менее чувствителен к изменениям цвета, чем к изменениям яркости. И такое предварительное разделение нужно, чтобы в цветовых каналах можно было убрать часть деталей.
Это и происходит на втором этапе – ресэмплинге. Каждые 4 цветовых пикселя объединяются в один. Да, происходит потеря некоторых деталей, но… это практически незаметно! И на таком приеме уже удается сжать файл в 2 раза!

3 - Блоки 8х8
На следующем шаге картинка разбивается на блоки 8 на 8 пикселей. Кстати, шакалы от этого становятся видны, если очень сильно сжать изображение, например, так:

4 - Дискретное косинусное преобразование
Это, пожалуй, самый важный этап. Алгоритм должен каким-то образом понять, насколько много деталей в каждом блоке. Например, если это монотонный кусок неба, его можно закодировать чуть ли не 1 байтом) А если это ваша невероятная прическа, там много переходов яркости и цвета, на это нужно потратить больше бит.
Делается такой анализ с помощью дискретного косинусного преобразования. Это разновидность преобразования Фурье, которое, кстати, и в mp3 применяется. Сложная, но очень интересная штука!
Итак, рассмотрим блок 8 на 8 пикселей. Напоминаю, что он уже разбит на яркостный и цветовые каналы, и преобразование проводится над каждым отдельно. Иными словами мы работаем уже с монохромными блоками.
Дискретное косинусное преобразование производит разложение по спектру пространственных волн. Что же это такое? Любую монохромное изображение 8 на 8 пикселей можно представить как смесь из 64 картинок, на которых посмотрите что изображено:

Вот такие вот периодические плавные переходы! Это и есть пространственные волны разной длины (по горизонтали и вертикали). Есть другая версия отображения этих пространственных волн, трехмерная. Кому как удобнее для понимания:

Если накладывать такие базовые картинки друг на друга, а точнее прибавлять или вычитать с определенным коэффициентом каждую, то мы сможем получить что угодно! Вот как это выглядит, например, для буквы А. Посмотрите, с каждым следующим наложением, шаг за шагом, добавляется все больше и больше деталей и получается реально буква А:

Дискретное косинусное преобразование (DCT) как раз вычисляет коэффициенты для наложения каждой такой базовой картинки. Всего 64 числа:
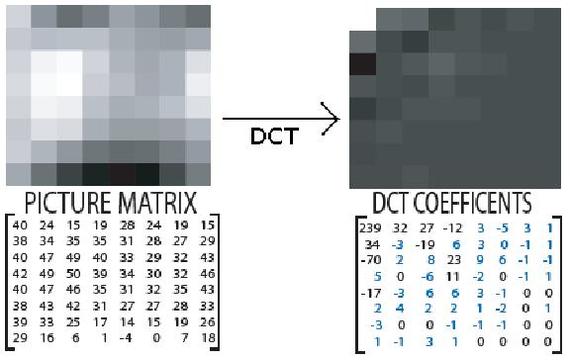
И обратите внимание! Коэффициент это вес, важность этой составляющей. Здесь есть те, которые отвечают за плавные переходы. И те, которые отвечают за более частые.
Как раз, если деталей мало, то коэффициенты у последних будут практически нулевыми, ведь зачем добавлять такую рябь, если блок почти монотонный? И вот тут и начинается по-настоящему мощное сжатие!

5 - Квантование
Начинается этап квантования! Матрица коэффициентов делится на матрицу квантования, которая зависит от настроек сжатия. Например, если вы сохраняете JPEG со 100% сжатием, каждый коэффициент делится на 1 (то есть остается таким же). Если вы сохраняете с меньшим качеством, то каждый коэффициент делится на определенное число (опять же в зависимости от выбранного качества).
Далее производится округление поделенных коэффициентов до целого значения. И при сильном сжатии многие из них округляются до нуля:
Да, на этом шаге теряется много информации. Да, из-за этих округлений, при прочтении файла и вылезает куча шакалов, артефактов и прочего. Но! Основная суть остается! Ну, а дальше сжать файл, напичканный нулями – дело техники!
6 - Сжатие
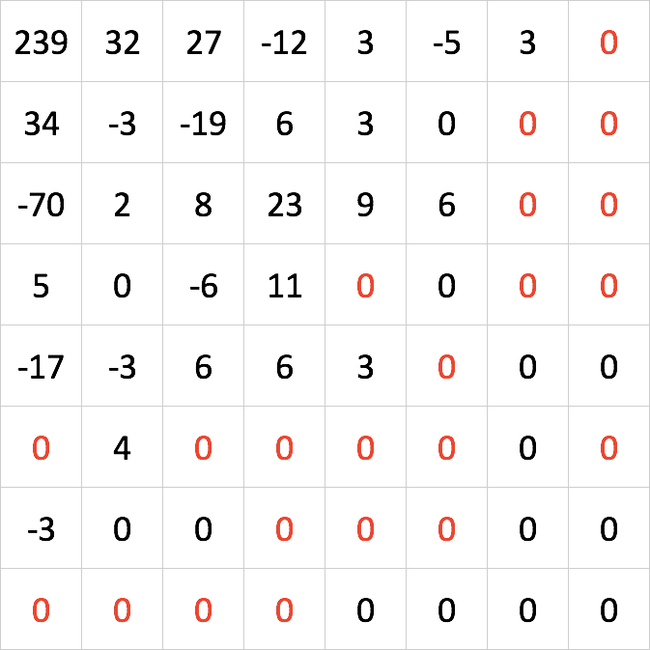
Сначала матрица коэффициентов сканируется зиг-загом:
Получается последовательность чисел в конце которой зачастую одни нули:

Затем последовательность пакуется хитрым способом. Если в ней есть длинная череда нулей, НЕ кодируется каждый из них. Вместо этого просто указывается одно число, обозначающее сколько их. Это очень сильно сжимает размер файла! Довольно упрощенно это может выглядеть так:

Ну и в конце сжатая последовательность кодируется кодом Хаффмана.
Каждому символу приваивается определенный код. Например, (опять же упрощенно) так:
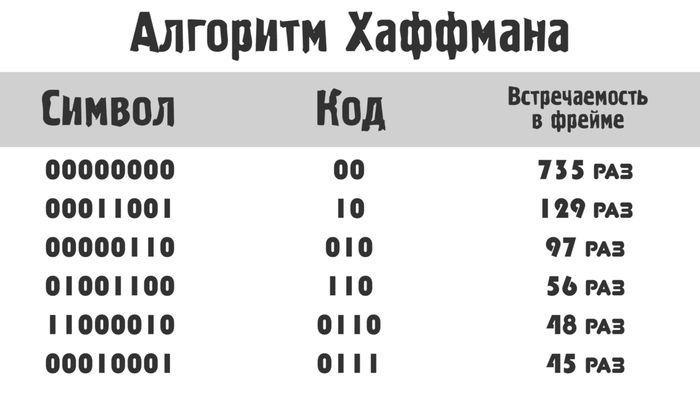
Обратите внимание, код присваивается не абы как, а по степени встречаемости в файле. Чем чаще появляется символ, тем короче у него код.
Получается, что нули и другие символы, которых очень много кодируются малым количеством бит, а остальные символы, которые реже встречаются, бОльшим количеством бит. Об этом алгоритме я подробнее рассказываю в видео про mp3, можете там посмотреть:

Затем все блоки 8 на 8 склеиваются в один файл и получается красивенький, маленький джипег!) Вот кстати портрет шведской модели Лены Сёдерберг из журнала Playboy. Так сложилось исторически, что с 1973 года это изображение используется для проверки практически всех алгоритмов обработки изображений. В то числе и JPEG. Поговаривают даже, что JPEG был оптимизирован как раз для того, чтобы как можно лучше сжать эту картинку)

Как видите, в джипеге используется много тонкостей – это и особенности нашего цветового восприятия, и хитрейшее разбиение картинки на детали, и математические методы сжатия. Но несмотря на это джипег уже устаревает, ему в спину дышат новые форматы, основанные на тех же принципах, но еще лучше сжимающие изображения. Хотя что-то мне подсказывает, что старичок джипег будет еще долго жить!)
Спасибо всем, кто дочитал до конца! Это мой первый длинопост, не судите строго) Баянометр ругался только на Лену, но это культовое фото!
Полезные ссылки:
Как устроен формат mp3: https://youtu.be/z2EUT4gwkr4
Подробнее о JPEG: https://habrahabr.ru/post/206264/
Доброй ночи, пикабушники!
Продолжаю серию статей про JPEG2000
Прошлый пост был про вейвлеты: http://pikabu.ru/story/jpeg2000_na_paltsakh_chast_1_veyvlety...
В этой статье будет описан алгоритм арифметического кодирования. В JPEG2000 вместо Хаффмана используется более эффективное арифметическое сжатие. Алгоритм Хаффмана хорошо сжимает, если частоты появления символов пропорциональны степени двойки. В реальности такая ситуация не всегда возможна — символы встречаются в различных пропорциях. Арифметическое кодирование решает эту проблему, так как коды присваиваются не символам, а их последовательностям.
Теперь немного о том, как это работает.
Есть строка: Пикабу—лучший_ресурс
(Пробел заменен на подчеркивание)
Подсчитаем количество букв и выделим частотные интервалы для них на промежутке [0;1].
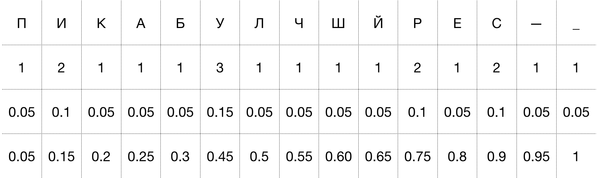
Пояснение: первая строка — буква, вторая — частота символа, третья — вероятность возникновения (частота / количество символов в строке), четвертая — граница интервала справа.
Попробуем закодировать слово “ПИКАБУ”. Возьмем первый символ “П” и принимаем его границы [0;0.05) за начало отсчета. Для кодирования следующего символа “И” нужно пересчитать границы по формулам:
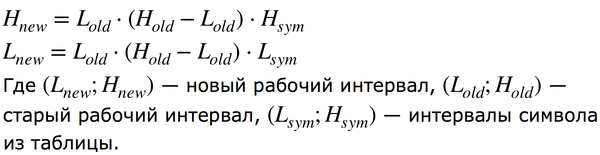
Для слова “ПИКАБУ” получаем следующие результаты:
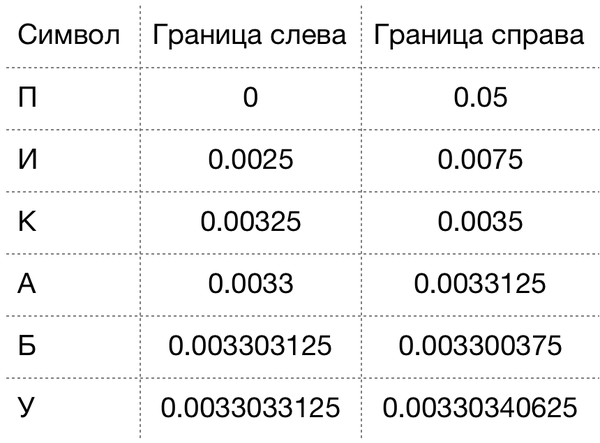
Теперь попробуем декодировать этот результат. Для этого будем использовать левую границу последнего символа — 0.0033033125. Обращаемся к исходной таблице и видим, что это число лежит в диапазоне [0;0.05), а значит это “П”.
Теперь попробуем получить следующий символ. Мы уже знаем, что первый символ — “П”, а значит знаем и его границы. Если подставить известные данные в формулу ниже, то будет известен новый интервал:

Новый интервал 0.06606625 лежит в пределах [0.05;0.15), что соответствует символу “И”. В таблице ниже результат для всего слова.
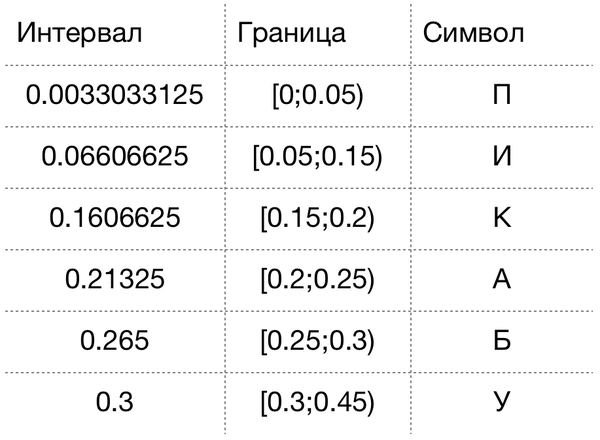
Теперь Вы владеете основами арифметического кодирования :)
За кадром, как всегда, осталась масса различных математических нюансов. Надеюсь, что Вам было интересно и Вы узнали что-то новое.
Добрый день, пикабушники! По просьбе @SimplyFree, делаю серию постов про JPEG2000.
Для начала, поговорим об основных преимуществах этого формата сжатия
изображений в сравнении с JPEG:
1. Большая степень сжатия при том же качестве
2. Поддержка кодирования отдельных областей с лучшим качеством
3. Основной алгоритм сжатия заменен на вейвлет
4. Для повышения степени сжатия в алгоритме используется арифметическое сжатие
5. На уровне формата поддерживается прозрачность

Описание начну с отдельных частей алгоритма, а потом уже приведу схему.
В данном посте будет рассказано о вейвлетах. Вейвлет — это
преобразование, которое позволяет разделить сигнал на высокие и низкие
частоты.
“Стоп. Что еще за сигнал?“ — возможно, спросите Вы.
Изображение, как и звук, является сигналом. Вообще, любая
информация может быть представлена сигналами, но об этом как-нибудь в
другой раз.
Алгоритмы сжатия любят длинные последовательности одинаковых чисел.
Почему? Их легко можно представить в виде последовательности нулей,
которые можно эффективно сжать.
Пример: 155, 155, 155, 155, 155, 155, 155, 155
При использовании дельта-кодирования: 154, 0, 0, 0, 0, 0, 0, 0
(дельта-кодирование — разность между соседними элементами)
Но в реальных изображениях (фотореалистичных) соседние пиксели
отличаются на небольшие значения, которые человеческий глаз уловить не в
силах, а вот эффективность алгоритма они снижают.
Пример: 154, 155, 156, 157, 157, 157, 158, 156
При использовании дельта-кодирования: 154, 1, 1, 1, 0, 0, 1, -2
Напрашивается вопрос, а почему бы не сгладить эти неровности? Для начала, разобьем все числа на пары:
(154, 155), (156, 157), (157, 157), (158, 156)
И вычислим полусуммы и полуразности:
(154.5, 0.5), (156.5, 0.5), (157, 0.0), (157, -1.0)
Из них с помощью простых операций можно вычислить оба значения в паре.
Как можно увидеть, второе число в новой паре маленькое, а значит, его можно сжать эффективнее.
Описанный метод называется преобразованием Хаара. Это преобразование как раз и разделяет сигнал на низкочастотную и высокочастотную части.
Эффективности сжатия при использовании вейвлетов добиваются при небольших потерях на высокочастотных составляющих (квантование), т.к. их человеческий глаз не способен определить.
Такой трюк с разделением на высокие и низкие частоты может повторяться много раз. В JPEG2000 он может проделываться до 32 раз.
Вообще, в самом алгоритме используется Преобразование Добеши, которое позволяет сжать изображение еще сильнее, при этом без видимых шакалов артефактов. Принцип его схож с преобразованием Хаара, только коэффициенты другие.
Конечно, в этой статье не были рассмотрены многие математические детали. Но нельзя объять необъятное. Да и многое сложно объяснить не повышая градус матана. Надеюсь, что и написанное оказалось кому-то полезным.
Спасибо за внимание!
На фото: наркоман, для поимки которого вызвали скорую и полицию.
Конкурс мемов объявляется открытым!
Выкручивайте остроумие на максимум и придумайте надпись для стикера из шаблонов ниже. Лучшие идеи войдут в стикерпак, а их авторы получат полугодовую подписку на сервис «Пакет».
Кто сделал и отправил мемас на конкурс — молодец! Результаты конкурса мы объявим уже 3 мая, поделимся лучшими шутками по мнению жюри и ссылкой на стикерпак в телеграме. Полные правила конкурса.
А пока предлагаем посмотреть видео, из которых мы сделали шаблоны для мемов. В главной роли Валентин Выгодный и «Пакет» от Х5 — сервис для выгодных покупок в «Пятёрочке» и «Перекрёстке».
Реклама ООО «Корпоративный центр ИКС 5», ИНН: 7728632689





