Параллельные процессы в n8n: как обрабатывать сотни задач, не дожидаясь Timeout

Ваш сценарий в n8n отлично работал на 10 задачах, но «завис» на 1000? Если процесс выполняется часами, а в логах маячит ошибка Timeout, виноват, скорее всего, стандартный узел Loop Over Items.
Этот узел надёжен, но работает последовательно: берёт один элемент, прогоняет по всей цепочке, ждёт — и только потом берёт следующий. Если каждая итерация из-за медленного API занимает 5–10 секунд, обработка 1000 элементов растянется на несколько часов.
Проблема в цифрах: почему последовательный цикл – это медленно
Представим три задачи разной длительности:
Задача 1: 5 секунд.
Задача 2: 7 секунд.
Задача 3: 6 секунд.
Loop Over Items выполнит их одну за другой.
Общее время: 5 + 7 + 6 = 18 секунд.
Для трёх задач это не страшно. Для трёхсот, ну почти полтора часа.
Быстрое, но плохое решение: асинхронный вызов
Что если использовать узел Execute Workflow для вызова дочернего сценария и отключить опцию Wait for Subworkflow? Тогда основной процесс не будет ждать и сразу перейдёт к следующей задаче.
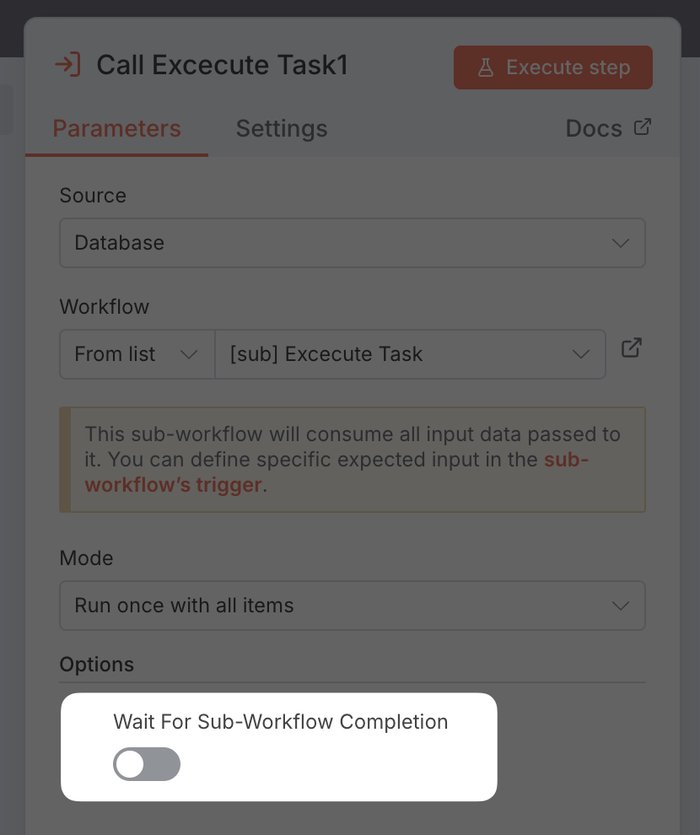
Проблема: главный сценарий завершится за пару секунд, но мы потеряем контроль. Непонятно, когда задачи будут выполнены, как собрать результаты и были ли ошибки. Это не автоматизация, а запуск процессов «вслепую».
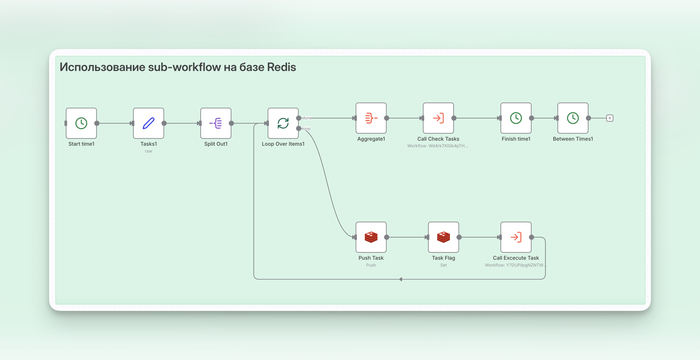
Redis как диспетчер задач
Чтобы управлять параллельными процессами, нужен внешний координатор. С этой ролью отлично справляется Redis. Мы будем использовать его для двух вещей:
Очередь задач: список ID всех задач.
Флаги состояния: ключи для отслеживания статуса каждой задачи ( false, true).
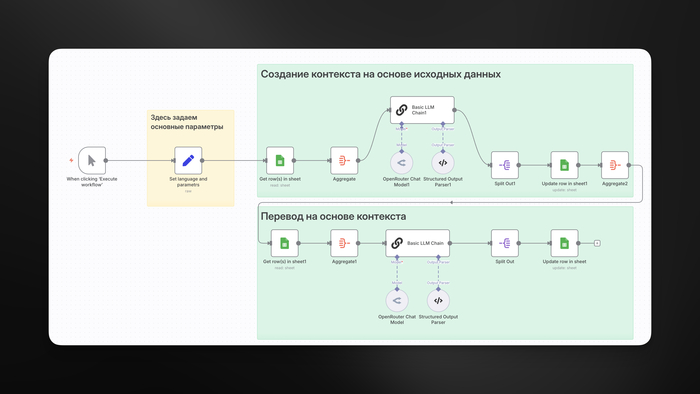
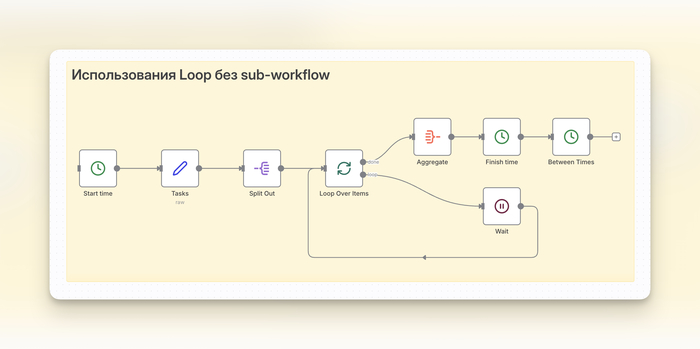
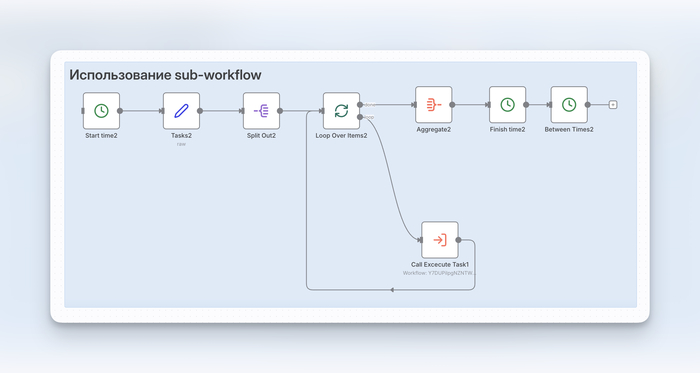
Архитектура состоит из трёх сценариев: Оркестратор, Воркер и Наблюдатель.
Оркестратор (главный сценарий)
Не выполняет работу сам, а только раздаёт её:
Получает список задач.
Для каждой задачи создаёт запись в Redis: добавляет ID в очередь и ставит статус false. Нижняя ветка на скриншоте выше.
Вызывает дочерний сценарий-воркер (асинхронно, без ожидания).
Когда все задачи розданы, вызывает Наблюдателя и ждёт его завершения.
Как быстро установить Redis в ваш n8n через Coolify можете почитать у меня тут. Сам процесс установки займёт не более 5 минут. Про сам Coolify и почему он отлично сочетается с n8n писал ранее отдельный лонг.
Воркер (дочерний сценарий)
Рабочая лошадка. Его логика проста:
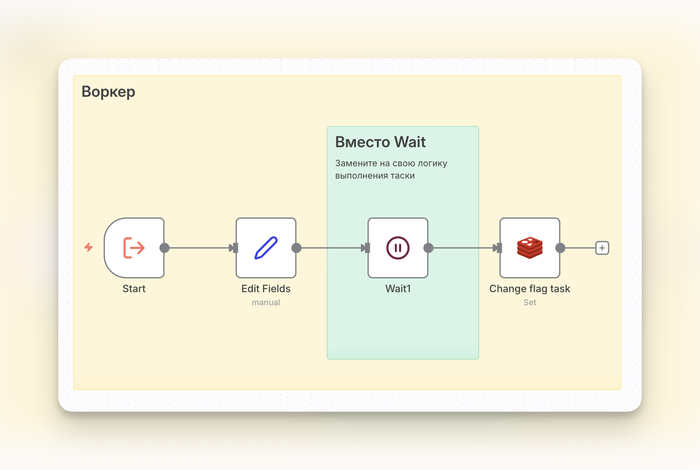
Получает на вход ID задачи.
Выполняет тяжёлую работу: запрашивает API, обрабатывает файлы.
После завершения обновляет статус задачи в Redis на done.
Наблюдатель (дочерний сценарий)
Контролёр. Его задача — дождаться завершения всех работ:
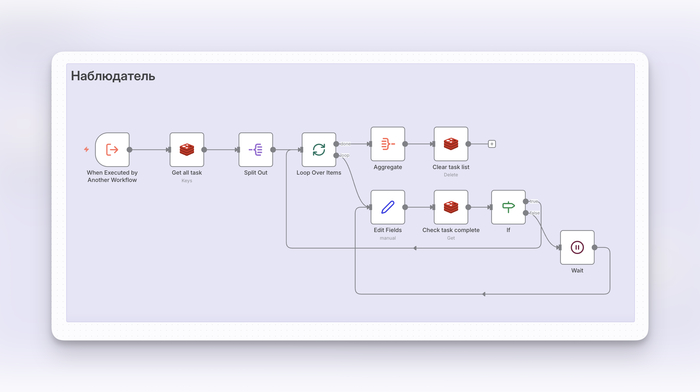
Получает из Redis полный список ID задач.
Запускает цикл проверки статусов.
Если хотя бы одна задача ещё в статусе false, ждёт 0,1 секунд и проверяет снова.
Как только все статусы – true, Наблюдатель завершает работу, а вместе с ним и Оркестратор.
Теперь мы точно знаем, когда вся партия задач обработана. Общее время выполнения равно времени самой долгой задачи, а не их сумме. Наши три задачи выполнятся примерно за 7–8 секунд вместо 18.
Скачать получившееся workflow можно здесь.
Подводные камни
Псевдопараллельность. В стандартном режиме main n8n выполняет задачи в одном потоке. Выигрыш достигается за счёт асинхронных операций, например, ожидания ответа от API. Для реальной параллельности на уровне CPU нужен режим queue с несколькими воркерами.
Внешняя зависимость. Redis нужно развернуть и поддерживать.
Обработка ошибок. Если воркер упадёт, его статус останется false. Наблюдатель зациклится. Нужен механизм таймаутов или статус failed.
Нагрузка. Не запускайте 10 000 воркеров одновременно. Группируйте задачи в пакеты по 10 - 50 штук, чтобы не исчерпать лимиты памяти сервера.
Автор, ты не пробовал подключить RabbitMQ?
Полостью согласен, всё что выше – не самый идеальный вариант реализации) Решил попробовать, такой подход, так как нагрузка на CPU не более 5% и не более 10 мб по RAM (в простое вообще по 0 в CPU/RAM). Если смотреть в сторону RabbitMQ, то там чисто на простое уже от 100 мб и какая никакая нагрузка на CPU. По сути там уже полноценный переход на event-систему контроля.
Обязательно в дальнейшем рассмотрим вариант с использованием RabbitMQ!
Вывод
Стандартный цикл хорош для небольшого числа быстрых операций. Как только задачи становятся долгими, а их количество растёт, переходите на асинхронную модель с внешним координатором вроде Redis. Это сократит время выполнения с часов до минут.