

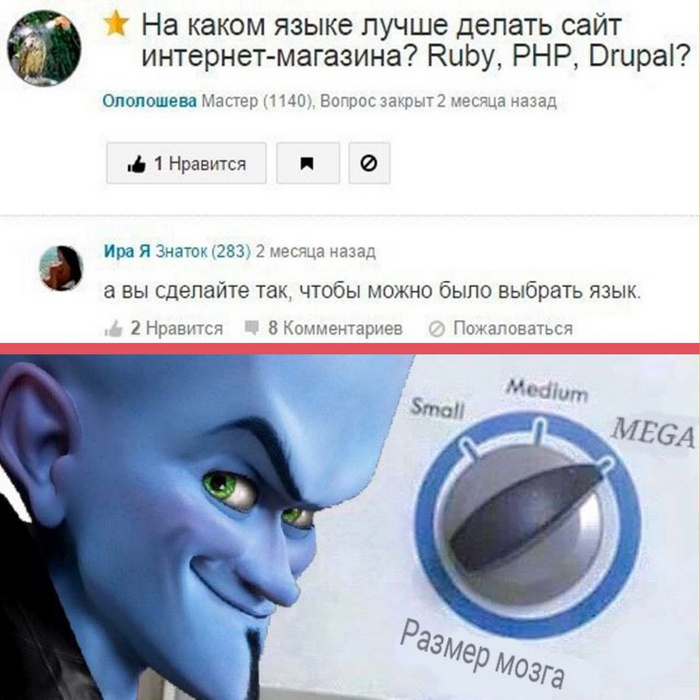
Она, наверное, сениор
Показать полностью
1
Пост для тех, кто читает вакансии в ИТ-компаниях и думает, что там всё классно.
Иногда уже по тексту вакансии можно понять, что работать в компании будет сложно. Мы просмотрели разные вакансии в ИТ и собрали 9 признаков того, что в реальности всё окажется хуже, чем в объявлении.

Читайте нас в телеге, ибо там выходит контент ежедневно (не как тут) и вы сможете устроиться на вакансию мечты, обретя силу фронтенда.
А теперь к делу
1. Слишком странный набор навыков
В компанию требуется JavaScript-разработчик со следующими навыками:
• JavaScript + HTML;
• знание Microsoft Excel;
• составление отчётов в 1С;
• уверенное владение системой автоматизации СДЖУ-85.
Что здесь не так: кажется, что эта вакансия составлена под конкретного человека, чтобы он прошёл, а остальные — нет. В жизни у обычных разработчиков не встречается такой каши из специфичных навыков из разных областей.
Ещё есть поверие: если в вакансии написано «1С», то это будет то, с чем вы будете возиться 90% времени.
Как норм: скучный, понятный, пусть даже модный стек технологий, который кочует из одной вакансии в другую. Ну вот надо людям в каком-то году React, а в другом — Vue. Окей, но пусть это будет стандартный стек этого года, а не безумный микс.
2. Участие в техподдержке
Ваши рабочие задачи:
• написание и отладка кода;
• разработка новых систем;
• помощь при работе с клиентами, иногда — ответы на вопросы пользователей.
Что здесь не так: чаще всего за этой строкой скрывается дополнительная обязанность по техподдержке продукта, за которую не будут дополнительно платить. Это значит, что вам нужно будет успевать и писать код, и разгребать тикеты в техподдержку. Если это не позиция сотрудника техподдержки — стоит насторожиться.
Как норм: поддержкой занимается поддержка.
3. Высокий темп разработки
Мы заботимся о скорости обновлений, поэтому ваш код сразу будет уходить в новую версию продукта каждую неделю.
Что здесь не так: высокий темп означает, что в компании, скорее всего, не налажено тестирование и оформление документации. С этим просто некогда разбираться, а все проблемы решаются выпуском нового кода. В итоге всё превращается в спагетти-код и падает из-за отсутствия документации.
Как норм: у компании должен быть этап тестирования, обязательные требования по документированию своего софта, а в идеале ещё и код-ревью — когда старшие товарищи проверяют ваш код.
4. Десятилетний стартап
Мы — стартап, который образовался 10 лет назад, и у нас до сих пор сохранилась та атмосфера свободного общения и отношения к продукту.
Что здесь не так: если стартапу больше трёх лет и он всё ещё стартап, то с продуктом явно что-то не то: либо нет клиентов, либо нет квалифицированных разработчиков, либо ребята не знают значения слова «стартап». В любом случае за это время там накопится технический долг, на разгребание которого понадобится ещё 10 лет. Хотите ли вы в таком участвовать — хорошо бы решить заранее.
Как норм: компания, которая работает уже 10 лет, скорее всего, уже имеет штат HR-специалистов, которые будут обрабатывать входящие вакансии. Это признак, что хотя бы процесс найма у компании поставлен.
5. Обязательное участие в корпоративных мероприятиях
Наша компания — как семья. У нас высокая культура внутри компании, поэтому мы ожидаем от каждого кандидата, что он будет принимать участие во всех корпоративных мероприятиях и будет активно вовлечён в профильные активности.
Что здесь не так: ну как можно навязывать работникам досуговые мероприятия? Это просто неприлично.
6. Горизонтальное управление, никакой иерархии, решает команда
У нас нет привычного руководства, а все вопросы мы решаем вместе. Каждая идея обсуждается коллективом разработчиков — благодаря этому у всех в работе только важные и интересные задачи.
Что здесь не так: в коллективе всё равно будут лидеры и руководители, только они будут неформальные и в случае чего смогут откреститься от любой ответственности. Вам придётся помимо работы участвовать в беспощадной внутриполитической борьбе.
Как норм: в вакансии этого не напишут, но вообще должны быть чёткие должностные обязанности, назначения в команды, чёткие руководители и понятные сферы ответственности.
7. Руководитель лично вовлечён
Вы будете работать непосредственно с Иваном Петровым, который лично курирует эту работу.Что здесь не так: вероятно, вы получите босса, который стоит над душой, двигает пиксели и меняет задачу по семь раз на дню. Неприятно работать персональным кодером с голосовым управлением.
Как норм: «вы будете работать в команде такой-то над такими-то задачами».
8. Оперативные ответы в любое время
Будущий сотрудник должен:
• быть на связи и сразу реагировать на входящие задачи;
• вовремя проверять электронную почту;
• иметь возможность оперативно подключиться к решению первоочередных задач.
Что здесь не так: подобное описание означает, что вас будут дёргать днём и ночью по любому поводу. Ночные переработки, работа в выходные и на праздники, внезапно закончившийся отпуск — всё это скрывается за простыми словами «нам важно, чтобы сотрудник был всегда на связи».
Как норм: обычно, если работа действительно требует мгновенной реакции в любое время, это обосновано спецификой. Так могут эксплуатировать персональных ассистентов или, например, дежурных сисадминов.
9. Несоответствие опыта и развития отрасли
Мы — стартап в области нейрогенеративного искусства, занимаемся созданием видеороликов на основе нейросетей по текстовому описанию. Нам нужен Python-разработчик с пятилетним опытом работы в этой теме.
Что здесь не так: пять лет назад не было популярных разработок в области генерации видео из текста, поэтому у любого разработчика просто не будет такого опыта. Судя по описанию, компания не разбирается в технологиях и им нужен тот, кто всё объяснит либо сделает за них с нуля всю работу.
Это не панацея
К сожалению, нет идеальных компаний: везде есть какие-нибудь трудности, загоны и отдельные вонючки, которые будут всё портить.
Часто нормальные внешне вакансии ведут в проклятые компании, и никак, кроме как по отзывам, ты это не узнаешь (или на личном опыте).
Наконец, бывают просто некомпетентные эйчары, которые составляют вакансии так, что от компании хочется бежать. Хотя внутри там норм.
Как это всё научиться отлавливать? Достоверно не знаем. Но с опытом становится легче.
В CSS с недавних пор было анонсировано новое свойство accent-color, и сегодня мы как раз хотим про него вам рассказать.
Что оно делает: позволяет легко обозначить цвета нашего бренда для полей ввода данных в формах. Вспомните о всех тех чекбоксах, радио-кнопках и прочих элементах, которые сложно стилизовать, да и все браузеры отображают их по-разному. В качестве выхода обычно скрывали дефолтное поле и создавали новое кастомное с помощью псевдоэлементов. Свойство accent-color позволяет нам сохранить вид элементов форм браузера по умолчанию, но применить к ним цвет, соответствующий цветовой гамме нашего сайта.
Поскольку свойство наследуемое, его можно применить на корневом уровне:
Пример:
:root {
accent-color: chocolate;
}
Так же можем применить к конкретному элементу:
.submit-form {
accent-color: purple;
}
input[type="checkbox"] {
accent-color: #6ad3ff;
}
❗️ Ну и вишенка на торт. Согласно ресурсу caniuse свойство уже поддерживается всеми основными браузерами.
Наш канал, с полезными мануалами и статьями, мастхэв сервисами и готовыми решения на CSS, Javascript
Собственно, это плагины для VS Code, без которых техническим писателям и разработчикам документации жить можно, но сложно. В подборке — линтеры, форматирование, работа с git, проектирование API, подготовка схем и милота для удобной разработки.

Здесь мы вам даем еще больше полезностей: полезные сервисы и фишки, мануалы и статьи готовые решения на CSS, Javascript и не только
Линтеры
Markdownlint

Самый популярный линтер для разметки Markdown. Подсвечивает распространенные проблемы.
Markdown All in One

Поддержка разметки Markdown в Visual Studio Code. Форматирование таблиц, оглавление, рендеринг в HTML.
LTeX – LanguageTool grammar/spell checking

Проверка орфографии и стилистики английского и русского языка по правилам LanguageTool.
Code Spell Checker + Russian - Code Spell Checker

Проверка опечаток в английском и русском тексте и коде. Находит опечатки даже в названиях переменных в коде. Можно использовать расширение совместно с LTeX.
Proselint
Расширение линтера англоязычной прозы Proselint. Создатели сервиса вдохновлялись Чаком Палаником, Марком Твеном, Джоржем Оруэллом и другими писателями.
Textlint


Семантический линтер с возможностью задавать свои правила, настройки и конфигурации проверок на то, что вам нужно.
Форматирование и форматы
Prettier - Code formatter

Расширение помогает так хорошо отформатировать текст в Markdown, что на него не ругается линтер.
OpenAPI (Swagger) Editor

Расширение для редактирования, форматирования спецификации OpenAPI (Swagger) в YAML или JSON.
MdTableEditor

Расширение исключительно для таблиц Markdown. Подсвечивает строки, столбцы и добавляет кнопки для операций с таблицами на командную панель.
GitHub Markdown Preview

Предварительный просмотр файлов Markdown в формате и стилистике GitHub.
Markdown Checkboxes

Расширение добавляет поддержку флажков и списков задач с предварительным просмотром.
PlantUML


Расширение поддерживает предварительный просмотр в реальном времени, подсветку синтаксиса и cниппеты для формата AsciiDoc.
reStructuredText Language

Расширение для полноценной работы с языком разметки reStructuredText.
Работа с системой контроля версий
GitLens

GitLens поддерживает операции с git и визуализирует всю историю кода — когда была изменена строка или блок кода, как код менялся. Можно проследить эволюцию кодовой базы.
Git Graph

Визуализирует весь таймлайн с коммитами и ветками. Позволяет работать с git через интерфейс.
Git Project Manager

Расширение позволяет открывать новое окно с репозиторием git из окна VS Code и быстро переключаться между репозиториями.
Удобство и милота
Markdown Emoji



Синхронизирует настройки и конфигурации VSCode. Для синхронизации используется Github Gist.




Добавляет закрывающий тег.
Rainbow bracket
Каждой паре всех видов скобок расширение дает свой цвет радуги. Красным цветом подсвечены незакрытые скобки.
Live Server
Локальный сервер разработки с функцией перезагрузки в реальном времени для статических и динамических страниц. Рендеринг по кнопке.
Material Theme Icons
Иконки к файлам и папкам.
В вебе есть стандартный язык разметки — HTML. Его понимают браузеры, но человеку читать чистый HTML-код тяжело — мешают теги и обилие служебной информации. Например, наша главная страница в HTML выглядит как-то так:
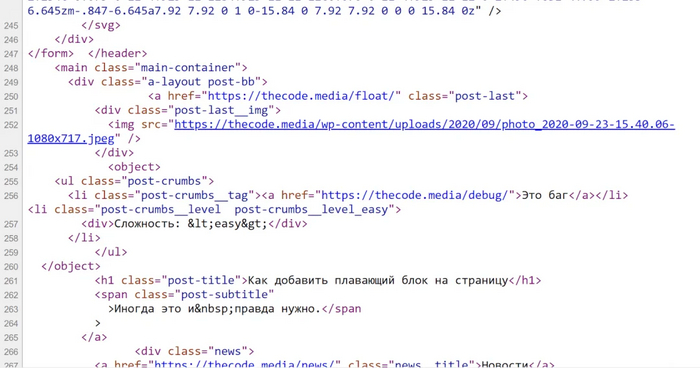
Чтобы понять, почему так, нужно вспомнить истоки HTML. Когда его только создавали, у него была задача описывать гипертекстовые документы: то есть документы, в которых будет текст и гиперссылки. При этом передаваться он должен был по очень медленным каналам. Первые HTML-страницы были минималистичными: только текст, заголовки, таблицы и редкие ссылки.
Постепенно веб развивался, сайты становились всё сложнее: появлялся дизайн, меню, навигация, картинки, табличная вёрстка. Но всё это по-прежнему выражалось языком простых текстовых документов. В него добавлялись новые теги, он усложнялся, и вот дорос до тех джунглей, в которых нам приходится работать сейчас.
Весь веб, который вы сейчас видите, сделан на «костылях» от простого языка для разметки текста.

Кто этот ваш Markdown
Markdown — это язык текстовой разметки документов. Его придумали в 2004 году блогер Джон Грубер и интернет-активист Аарон Шварц, чтобы быстро форматировать статьи. Требования к языку у них были такие:
2. Документы с этой разметкой можно перевести в красиво отформатированный вид, как на веб-странице.
3. Исходный текст материала должен оставаться читаемым даже без преобразования в веб-страницу.
В результате у них получился простой язык, который активно используется до сих пор.
Смысл маркдауна в том, что вы делаете разметку своего документа минимальными усилиями, а уже какой-то другой плагин или программа превращает вашу разметку в итоговый документ — например в HTML. Но можно и не в HTML, а в PDF или что-нибудь ещё. Маркдаун — это как бы язык для других программ, чтобы они формировали документы на основе вашего текста.
Единственное, что вам может понадобиться, — настроить в этом плагине шрифты, отступы и цвета, чтобы результат выглядел красиво. Один раз настраиваете, а потом быстро пишете много материалов, которые на выходе превратятся в готовые статьи с хорошей разметкой.


Синтаксис
Для оформления заголовков используют решётку. Одна решётка — заголовок первого уровня, две — заголовок второго уровня, и так до пятого. Посмотрите на скриншотах выше, как это работает.
## Это будет заголовком второго уровня (как Синтаксис в этом разделе)
Чтобы выделить слово или абзац, используют одну звёздочку в начале и в конце:
*вот так* → вот так
Если нужно выделить сильнее, берут две звёздочки:
**выделяем текст сильнее** → выделяем текст сильнее
Зачёркивают двумя тильдами:
~~зачеркнули и всё~~ → зачеркнули и всё
Для оформления кода используют обратный апостроф: `.
`Пример кода` → Пример кода (в Пикабу нет такой разметки😢)
Если нужно оформить много строк кода, тогда перед каждой из них ставят 4 пробела или один таб. Ещё можно взять такой блок в три обратных апострофа подряд — в начале и конце кода (представьте тут форматирование кода):
<! doctype html>
<html>
<head>
</head>
<body>
</body>
</html>
Чтобы сделать ненумерованный список, каждый элемент начинают с символов *, - или +.
Нумерованные списки делаются из цифры с точкой, причём цифры могут быть любыми и идти не по порядку. Смотрите:
1. Один
3. Три10. Десять
превращается в
2. Три
3. Десять
Ссылка состоит из текста ссылки и адреса. Текст пишется в квадратных скобках, а адрес — в круглых. То, что в кавычках, можно не писать и оставить в скобках только адрес:
[Текст ссылки](https://thecode.media/ «Необязательный заголовок ссылки»)
Картинки вставляются точно так же, только добавляется восклицательный знак в самом начале:

Как работает эта магия
Если мы просто напишем текст и разметим его с помощью Markdown, то он так и останется текстом с разными спецсимволами. Чтобы результат выглядел как на скриншоте выше, используют специальные редакторы, плагины или программы, которые поддерживают этот язык разметки.
Работает это так:
2. Если есть — применяет нужное правило оформления к нужному фрагменту текста и выводит его красиво. Если нужно — подставит картинку, сделает ссылку и сама оформит список.
3. Если разметки нет — выводит содержимое просто как текст.
Такое работает не в каждом редакторе — если в Word выделить текст звёздочками, то это так и останется текстом со звёздочками, без курсива или жирного оформления. Но почти все редакторы понимают, когда в них вставляют текст, размеченный маркдауном. Они тогда сразу выделяют нужные фрагменты, делают заголовки и вставляют картинки.
Зачем использовать Markdown
Причин несколько.
2. Если вы делаете блог или другой статичный сайт, на котором хотите размещать свои тексты с лаконичным дизайном.
3. Вы хотите писать красивые сообщения в WhatsApp или Telegram.
4. Вы программист и пишете документацию к своему проекту на GitHub
Но во всех этих случаях вам нужно одно — сделать минимальную вёрстку текста так, чтобы он выглядел опрятно и чтобы его можно было прочитать и без специальных программ.
Скоро покажем, как запустить свой блог, используя Markdown и плагин для быстрого преобразования HTML-файлов. А там уже и до своего языка разметки недалеко.
Объект Promise (промис) используется для отложенных и асинхронных вычислений.
Синтаксис
new Promise(executor);
new Promise(function(resolve, reject) { ... });
Параметры
executor
Объект функции с двумя аргументами resolve и reject. Функция executor получает оба аргумента и выполняется сразу, еще до того как конструктор вернет созданный объект. Первый аргумент (resolve) вызывает успешное исполнение промиса, второй (reject) отклоняет его. Обычно функция executor описывает выполнение какой-то асинхронной работы, по завершении которой необходимо вызвать функцию resolve или reject. Обратите внимание, что возвращаемое значение функции executor игнорируется.
Так как тема прошлого поста про рекурсию был сложноватой для новичков, я решил залупить цикл публикаций о самой алгоритмизации. При этом попытаюсь разжевать все понятнейшим языком, чтобы джун смог с нуля всё понять.

И кстати, мы здесь рассказываем не только про алгоритмы и банально, там нас будет удобнее читать
Зачем мне алгоритмы? Я фронтендер!
Вы наверняка задумались: «А зачем мне нужно тратить своё время на изучение этих сложных алгоритмов, если я работаю с фронтендом? Как знание графов и бинарных деревьев поможет мне лучше отцентровать одну div-ку внутри другой div-ки?»
Многие веб-разработчики на таких форумах, как Reddit и Stack Overflow, отмечали, что, освоив даже на базовом уровне эти фундаментальные основы программирования, чувствовали себя увереннее, профессиональнее и писали более чистый и структурированный код.
Также это помогло им прокачать главный скилл разработчика – умение логически думать и решать сложные технические задачи.
Кстати, именно по этой причине многие крупные IT-компании требуют от своих потенциальных сотрудников знания фундаментальных основ computer science, к которым как раз относятся алгоримты и структуры данных, и с пристрастием спрашивают их на собеседованиях (даже на позицию фронтенд-разработчика!).
Что такое алгоритмы и структуры данных
Алгоритм — это совокупность последовательных операций, направленных на решение определенной задачи.
Структуры данных — это особый способ организации и хранения данных в компьютере, который обеспечивает эффективный доступ к этим данным и их изменение. Для оценки сложности и скорости работы алгоритма используют так называемую «О-нотацию» или «О-большое».
Эта запись имеет вид O(n), где n – это количество операций, которое предстоит выполнить алгоритму. Важное замечание: O(n) всегда описывает худший возможный случай выполнения алгоритма. Это дает нам гарантию, что наш алгоритм никогда не будет работать медленнее O(n).
Скорость работы алгоритмов измеряется не в секундах, а в темпе роста количества операций. Т.е. нас интересует, насколько быстро возрастает время выполнения алгоритма с увеличением размера входных данных.
Вот так выглядит время работы некоторых алгоритмов:
O(1) – константное время. Например, чтение данных из ячейки в массиве.
O(log n) – логарифмическое время. Например, бинарный поиск.
O(n) – линейное время. Например, поиск наименьшего или наибольшего элемента в неотсортированном массиве.
O(n * log n) – линейно-логарифмическое время. Например, быстрая сортировка.
O(n2) – квадратичное время. Например, сортировка пузырьком.
O(n!) – факториальное время. Например, решение задачи коммивояжера полным перебором.
Давайте для начала рассмотрим такой простейший алгоритм, как линейный поиск элемента в массиве, и реализуем его на JavaScript.
Итак, есть массив чисел, и нам нужно найти в нем конкретное число.

Создадим функцию линейного поиска и назовем ее linearSearch. Эта функция будет принимать в себя два параметра: array (т.е. сам массив элементов, в котором ведется поиск) и item (элемент, который мы ищем в этом массиве).
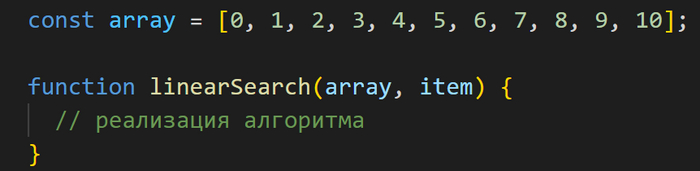
Линейный поиск происходит достаточно предсказуемо: мы используем цикл for, в котором пробегаемся по элементам массива и сравниваем каждый элемент с искомым.
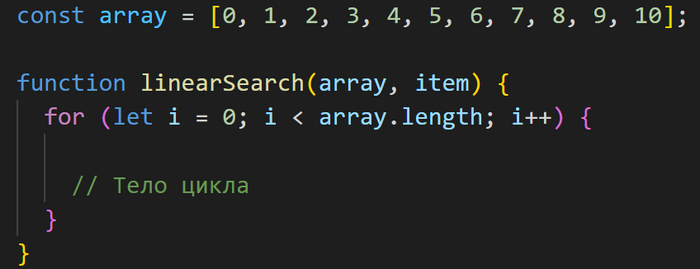
Далее инициализируем счётчик и установим его исходное значение, которое будет равно нулю, так как мы собираемся проверять массив с самого первого элемента.
let i = 0;Наш цикл будет выполняться до тех пор, пока не пройдет по всем элементам массива. В качестве конечной точки мы используем значение array.length, которое возвращает количество элементов в массиве. Так как массив array начинается с нулевого индекса, то мы используем при сравнении знак «<».
i < array.length;
После каждой итерации цикла увеличиваем значение переменной i на единицу.
i++
Далее с помощью условной конструкции if будем проверять на истинность одно условие. Данная проверка будет выполняться при каждой итерации цикла, но код внутри нее сработает только один раз, после чего функция завершится.
Здесь мы сравниваем каждый элемент массива (array[i]) c искомым элементом (item) и, если эти элементы совпадают, то возвращаем i (индекс массива, по которому находится этот искомый элемент item).
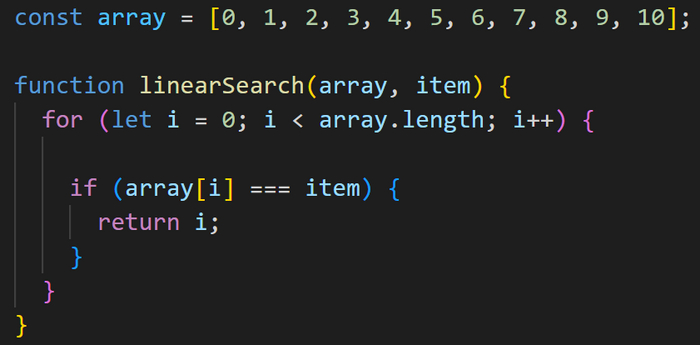
Если же искомый элемент не был найден, то по завершении работы цикла мы возвращаем -1.

Дальше нам остается только вызвать функцию linearSearch, первым параметром передать в нее массив элементов, а вторым параметром — искомое число.
Затем, с помощью функции console.log, выводим результат в консоль.
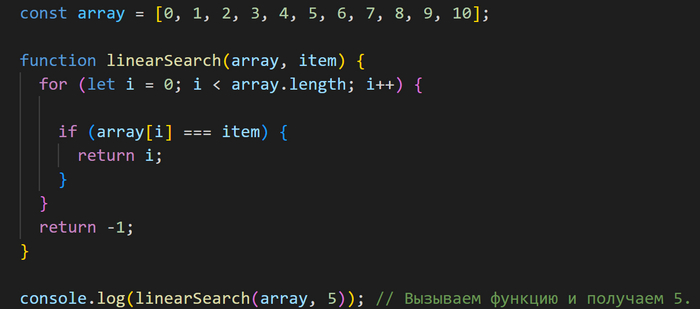
Как видите, алгоритм линейного поиска довольно прост в реализации. Сложность данного алгоритма: линейное время или O(n).
Давайте теперь рассмотрим более сложный и интересный алгоритм, который еще называют алгоритмом бинарного поиска.
Алгоритм бинарного поиска
Бинарный (или двоичный) поиск — это алгоритм, при котором массив данных будет последовательно делиться пополам до тех пор, пока не будет обнаружен искомый элемент.
Важное замечание: данный алгоритм будет работать только для отсортированного массива.
Бинарный поиск может быть реализован следующим образом:
0. Берём исходный массив отсортированных данных (например, по возрастанию).
1. Делим его на две части и находим середину.
2. Сравниваем элемент в середине с искомым элементом.
3. Если искомое число меньше этого центрального элемента — продолжаем искать элемент в левой части массива. Для этого мы делим левую часть массива на 2 части. Если искомый элемент больше центрального элемента, то мы отбрасываем левую часть массива и продолжаем поиск в правой.
И повторяем данную процедуру до тех пор, пока не найдем искомый элемент. Как только мы его нашли, то возвращаем индекс в массиве, по которому он находится. Если же данный элемент не будет найден, то возвращаем -1.
Давайте сначала взглянем на реализацию данного алгоритма, а потом разберем ее детально.
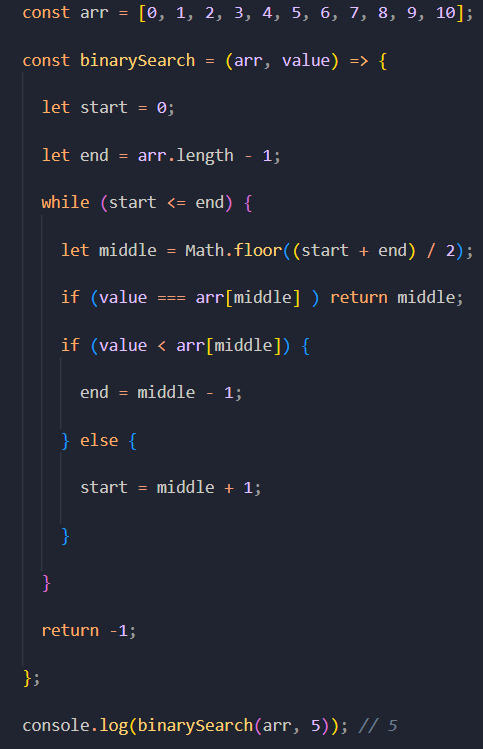
Итак, у нас есть массив чисел arr, отсортированный по возрастанию. Как вы помните, если заранее не отсортировать массив, то бинарный поиск не будет работать.

Создаем функцию binarySearch и передаем в нее два параметра: отсортированный массив arr и искомый элемент value.
Затем определяем следующие переменные:
let start = 0;
Так как мы должны найти центральный элемент, то сначала необходимо определить начальный и конечный элементы.
Задаем таким образом начальный элемент и устанавливаем его значение равным нулю, так как наш массив начинается с нулевого индекса.
let end = arr.length - 1;
Затем определяем конечный элемент. Его позиция будет вычисляться по длине массива arr.length - 1.
Далее мы создадим цикл while, который будет работать до тех пор, пока начальная и конечная позиция массива не сравняются (start <= end).
let middle;
Внутри цикла мы будем высчитывать позицию центрального элемента в массиве и сохранять ее в переменную middle. Для этого мы складываем начальную позицию с конечной и делим результат на две части.
Результат обернем в функцию Math.floor(), так как в результате деления у нас может получиться дробное число. С помощью данной функции мы округляем полученное число до нижней границы.
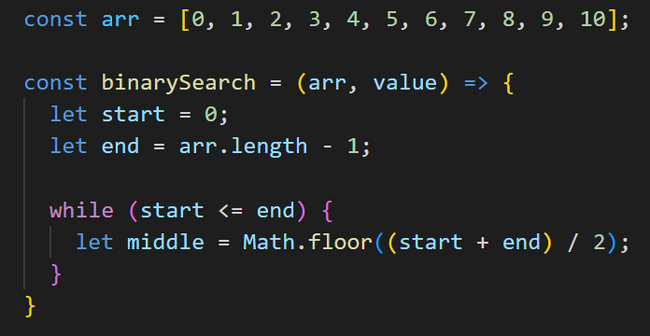
Далее с помощью условной конструкции if создаем проверку: если центральный элемент в массиве по индексу middle равен искомому элементу, то мы возвращаем индекс найденного элемента, сохраненный в переменной middle. И на этом наша функция завершает свою работу.
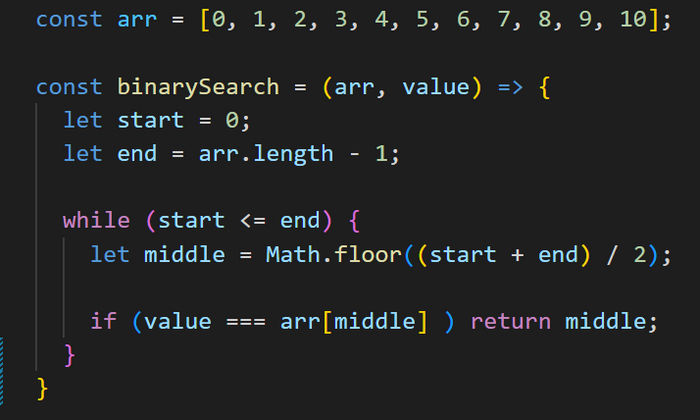
Если на данной итерации цикла мы не нашли искомый элемент, то необходимо выполнить еще одну проверку с помощью условной конструкции if. Если искомый элемент меньше, чем элемент, находящийся в середине, то это значит, что нам нужно продолжить поиск в левой части массива, а правую можно отбросить.
Для этого нам нужно изменить значение переменной end. В итоге мы получим end = middle + 1. А в блоке else мы прописываем такое же условие, только для случая, если искомый элемент будет больше, чем элемент, находящийся в середине. Тогда мы отбрасываем левую часть массива и продолжаем поиск в правой.
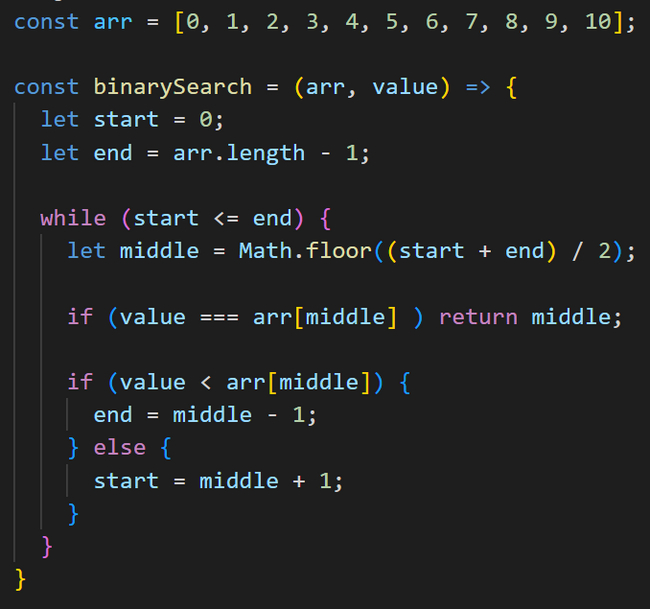
После завершения цикла while возвращаем -1 на случай, если искомое число не будет найдено в массиве. Далее вызываем функцию binarySearch и передаем в нее два параметра: массив элементов и искомое число.
И выводим результат в консоль.
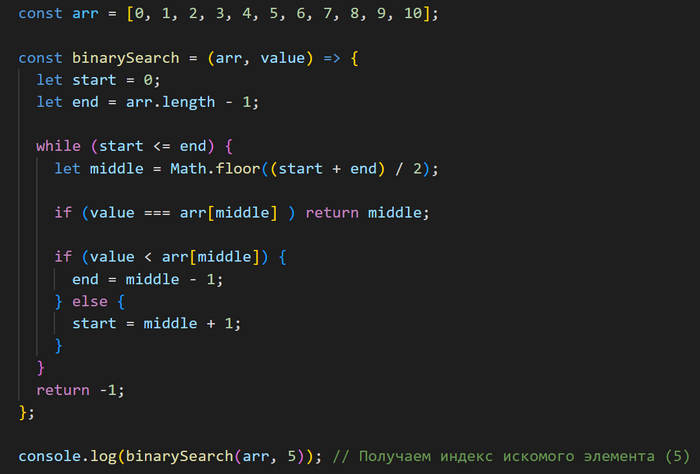
Что касается оценки сложности приведенных алгоритмов: бинарный поиск эффективнее линейного, поскольку массив данных на каждом шаге разделяется надвое и одна половина сразу отбрасывается.
Последовательная сложность бинарного поиска в худшем и среднем случаях равна O(log n), в лучшем — O(1) (если обнаруживаем искомый элемент на первой итерации). Для сравнения: вычислительная сложность линейного поиска, как вы помните, равна O(n).
На этом мы закончили вторую статью из нашего цикла статей по алгоритмам. Спасибо за внимание.
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi

Для многих разработчиков рекурсия кажется чем-то очень сложным и непонятным, но это только на первый взгляд. В этой статье мы разложим все по полочкам, чтобы вы в следующий раз не боялись этого страшного слова "рекурсия".
Мы узнаем, как устроена рекурсия, а также разберем алгоритм сортировки массива под названием Quick Sort или, как еще его называют, быстрая сортировка Хоара. Как вы уже догадались, этот алгоритм рекурсивный.

Читайте нас в телеграме, там мы каждый день выкладываем полезные материалы из вселенной Front-end
Перейдем к статье
Рекурсия
Рекурсия, если максимально упростить, это вызов функцией самой себя. Этот приём программирования можно использовать, когда есть возможность разбить задачу на несколько более простых подзадач. И, написав решение этой подзадачи в функции и вызывая такую функцию рекурсивно, мы можем все эти подзадачи итеративно решить.
Давайте взглянем на простой пример.
У нас есть простая функция обратного отсчёта:
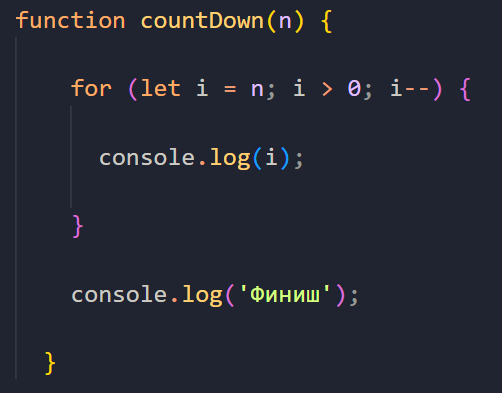
Данная функция принимает аргументом число n и выводит на экран числовую последовательность от n до 1 включительно, а в конце, после завершения работы цикла, выводит на экран слово «Финиш».
Давайте вызовем эту функцию, передав в нее число 3. В консоли мы получим следующий результат: «3 2 1 Финиш».

Теперь перепишем эту функцию на рекурсивный манер:
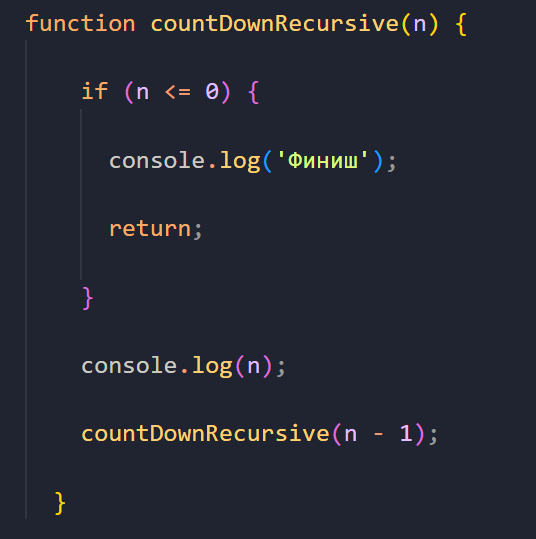
Разберемся, как эта функция работает. Первым делом, чтобы не получить бесконечный цикл вызовов функции и как результат ошибку «stack overflow», которая говорит нам о превышении лимита вызовов для функции в стеке, нужно определить так называемый базовый случай.
Базовый случай — это условие, при котором наша функция должна перестать вызывать саму себя рекурсивно.
Так как наш цикл работал до тех пор, пока i > 0, то здесь условие для прерывания цикла должно быть следующим:
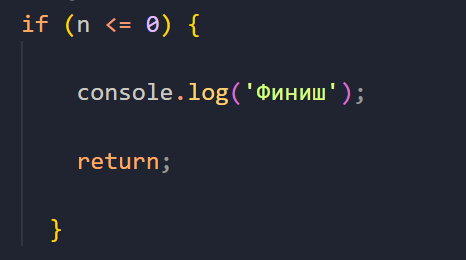
То есть, как только n будет меньше или равно нулю, мы перестаем рекурсивно вызывать функцию и выходим из нее. Перед выполнением оператора return необходимо будет вызвать наш console.log('Финиш'), потому что именно это действие и будет последним в работе функции.
По сути, базовый случай работает как оператор break в циклах, то есть прерывает вызов функцией самой себя, чтобы мы могли вернуть результат ее выполнения.
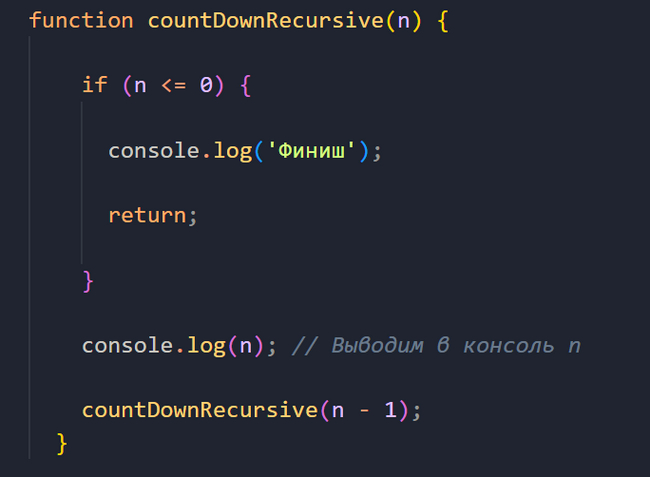
Дальше мы выводим в консоль текущее значение числа n. И, следующим шагом, снова вызываем нашу функцию countDownRecursive() и передаем в нее n - 1.
Как вы помните, в примере с циклом for, на каждой итерации цикла мы уменьшали число i на единицу (i--), поэтому здесь, по аналогии, передаем n - 1.
Запустим функцию и получим в консоли следующий результат:

Результат, как вы видите, аналогичен результату работы простой функции countDown.
Давайте теперь чуть подробнее разберём, как работает рекурсивная функция.
Как работает рекурсивная функция
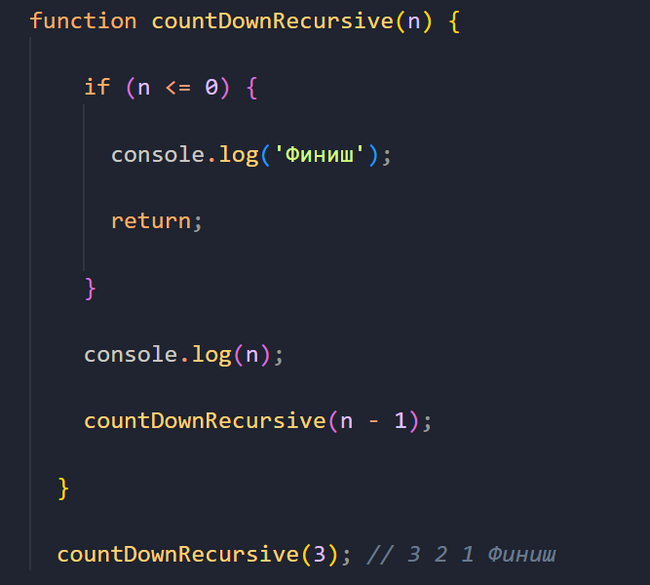
Итак, сначала мы вызываем функцию countDownRecursive со значением 3.

Базовый случай не отрабатывает, потому что n > 0. Мы выводим число 3 в консоль и дальше снова вызываем функцию, передав в нее n - 1, то есть 3 - 1 или просто число 2.
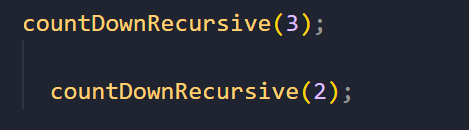
Повторяем эту процедуру, пока не дойдем до нуля:

И вот здесь уже срабатывает базовый случай. Так как 0 === 0, выводим в консоль слово «Финиш» и дальше срабатывает оператор return.
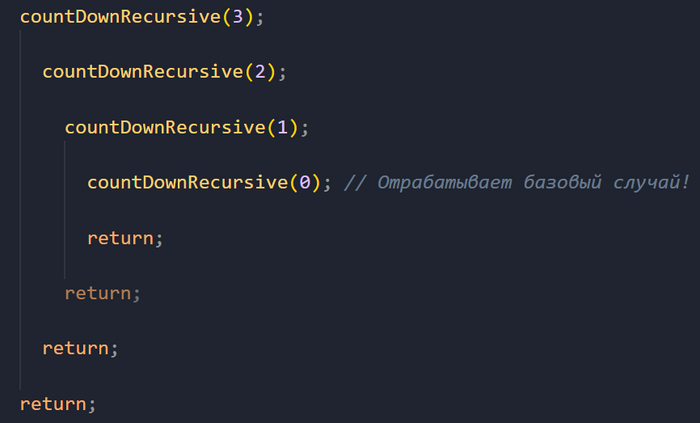
Дальше происходит завершение работы всех предыдущих функций (потому что неявно завершенная функция возвращает undefined, то есть как только выполнение нашей функции доходит до закрывающей фигурной скобки, происходит return undefined).
Здесь вы можете подумать, что это всё очень сложно, и почему бы не использовать такой понятный и простой цикл for?
Важно отметить, что, действительно, не везде нужно применять рекурсию. Но бывают задачи, где рекурсивное решение выглядет очень элегантно и занимает гораздо меньше строчек кода, чем с использованием традиционных циклов.
Давайте разберем один из таких примеров.
Числа Фибоначчи
Как вы знаете, ряд Фибоначчи — это числовая последовательность, первые два числа которой являются единицами, а каждое последующее за ними число является суммой двух предыдущих.
Автором данной числовой последовательности был Леонардо Пизанский (более известный под прозвищем Фибоначчи) из итальянского города Пизы — один из крупнейших математиков средневековой Европы.
Вот так ряд Фибоначчи выглядит на практике:

Иногда перед первой единицей добавляют еще и ноль, но мы не будем рассматривать данный случай, а рассмотрим классический ряд Фибоначчи, как в средневековых книгах (но только без кроликов).
Наша задача — написать функцию, которой можно передать номер элемента ряда Фибоначчи, и на выходе из функции получить значение этого элемента.
Допустим, мы ищем 10-ый элемент в последовательности. Значением этого элемента будет 55. Для 12-го элемента значением будет 144 и так далее.
Вот так будет выглядеть эта функция, написанная с применением рекурсии:

В результате работы функции в консоли мы получим число 8. Можете это проверить: если вы посмотрите на ряд Фибоначчи выше, то увидите, что значением 6-го элемента в ряду будет число 8.
Давайте разберём, как работает данная функция.
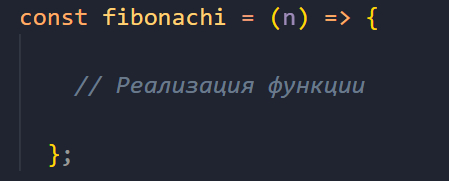
Объявляем стрелочную функцию fibonachi, которая принимает аргументом число искомого элемента в ряду — n.
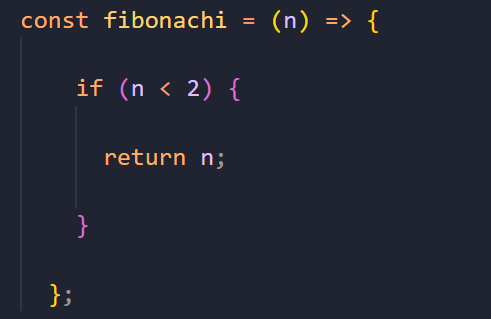
Далее определяем базовый случай, т.е. условие, при котором выходим из рекурсии.
Так как мы будем последовательно уменьшать число n (об этом ниже), то нет смысла делать это бесконечно.
Как только n оказывается меньше 2, то это значит, что мы достигли начала ряда Фибоначчи, а значит дальше нам двигаться не нужно и можно возвращать n обратно вызывающему коду.

Если же базовый случай не отработал, то снова вызываем функцию, передав в ее аргументы n - 1 и n - 2 соответственно, и складываем результат этих функций между собой по следующей формуле: F(n) = F(n - 1) + F(n - 2). Эта формула позволяет нам найти число из ряда Фибоначчи. Так как каждое число равно сумме двух предыдущих чисел в цепочке, то именно эту формулу мы реализовали в нашей функции.
Если вам до конца не понятно объяснение данного алгоритма, то, во-первых, это абсолютно нормально, а во-вторых, можете посмотреть подробное видео, объясняющее работу данной функции здесь.
Быстрая сортировка Хоара
А теперь рассмотрим более сложный алгоритм. Он называется быстрая сортировка (Quick Sort) или сортировка Хоара.
Данный алгоритм был разработан английским информатиком Тони Хоаром во время работы в МГУ в 1960 году.
И вот здесь как раз будет применяться рекурсия.
Как вы помните, в предыдущей статье мы с вами разбирали широко известный в узких кругах алгоритм — пузырьковую сортировку. Ее единственный недостаток — это крайне низкая эффективность. Быстрая же сортировка является улучшенной версией подобных алгоритмов сортировки с помощью прямого обмена.
Итак, в чем суть. Имеется неотсортированный массив чисел arr.

Наша задача написать функцию, которая будет принимать в себя аргументом этот массив и возвращать его полностью отсортированным по возрастанию.
Быстрая сортировка относится к алгоритмам из серии «разделяй и властвуй».
Небольшое отступление. Алгоритмы типа «разделяй и властвуй» (англ. divide and conquer) — это парадигма разработки алгоритмов, заключающаяся в рекурсивном разбиении решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче. Разбиения выполняются до тех пор, пока все подзадачи не окажутся элементарными.
Наш алгоритм будет сводиться к следующим шагам:
1. Выбираем элемент из массива и считаем его опорным (в англоязычной литературе его называют pivot).
2. Сортируем элементы в массиве таким образом, чтобы элементы меньше опорного размещались в подмассиве перед ним, а большие или равные — в подмассиве после.
3. Рекурсивно применяем первые два шага к двум подмассивам слева и справа от опорного элемента. Т.е. дробим наш массив на подмассивы и сортируем их относительно опорного элемента, пока в этих подмассивах не останется по одному элементу или меньше. Рекурсия не применяется к массиву, в котором только один элемент или отсутствуют элементы. Это как раз и будет базовым условием, при котором мы прервем рекурсию.
Вот здесь вы можете увидеть визуализацию работы быстрой сортировки (а также многих других алгоритмов).
А вот так выглядит реализация сортировки Хоара на JavaScript:
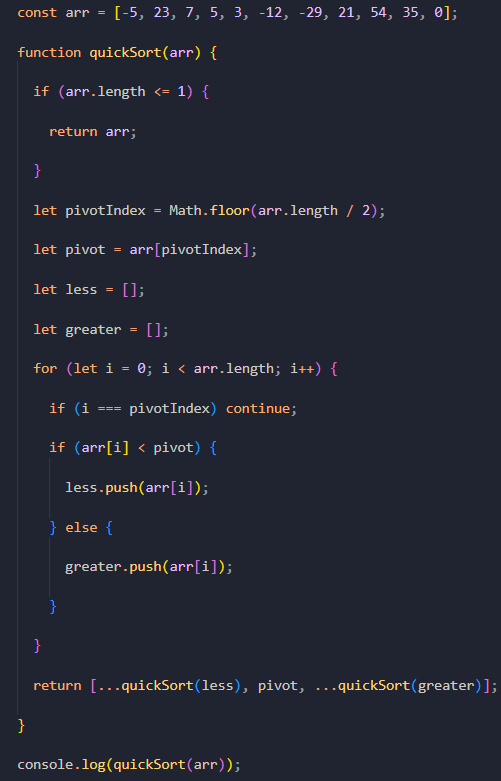
Подробный разбор алгоритма сортировки Хоара
Давайте подробно разберём, как работает данная сортировка.
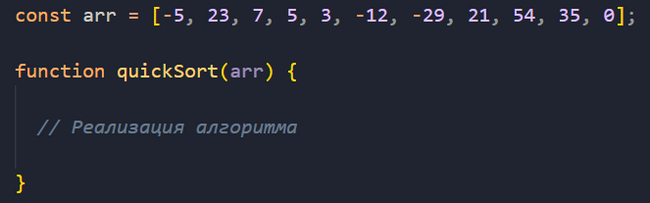
Создаем функцию quickSort() и передаем аргументом неотсортированный массив.
Дальше, как вы помните, необходимо определить базовый случай выхода из рекурсии.
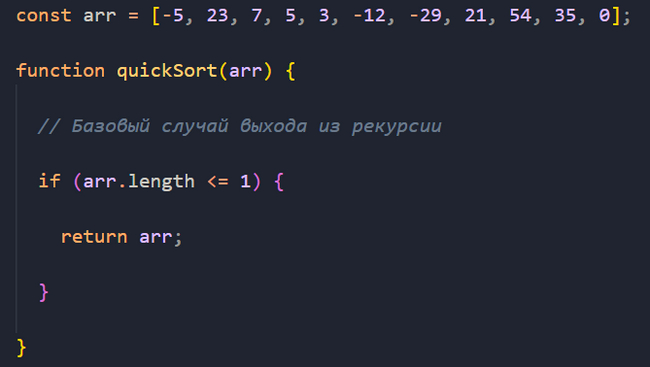
Так как нам предстоит дробить основной массив на подмассивы и сортировать элементы в этих подмассивах относительно опорного элемента (об этом ниже), то как только такие подмассивы будут содержать по одному элементу или будут пустыми, нам нет смысла дальше продолжать разбивать их на более мелкие части, поэтому здесь мы выйдем из рекурсии.
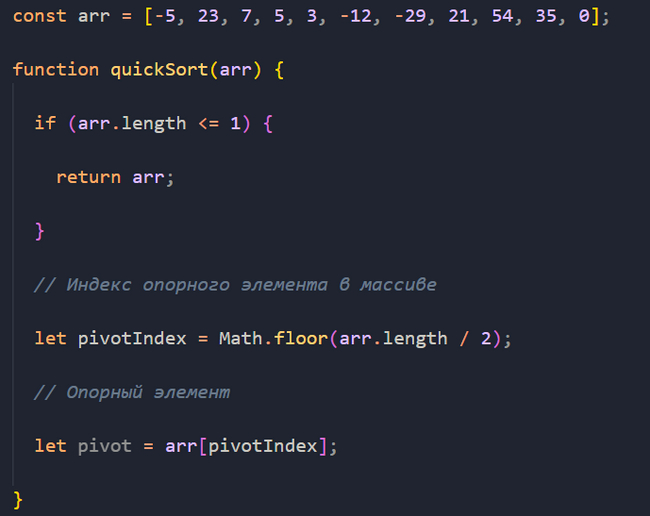
Теперь определим индекс в массиве так называемого опорного элемента. Для этого создадим переменную pivotIndex, передадим в функцию Math.floor длину массива, поделим результат на 2 и получившееся число присвоим переменной pivotIndex. Функция Math.floor, как вы знаете, округляет результат в меньшую сторону:
Math.floor(5.5); // 5
Затем определим сам опорный элемент. Для этого кладем в переменную pivot значение массива по индексу pivotIndex. В массиве arr значением pivotIndex будет 5 (длина массива — 11. 11 делим на 2 и округляем в меньшую сторону, получаем 5). Значением pivot будет -12.
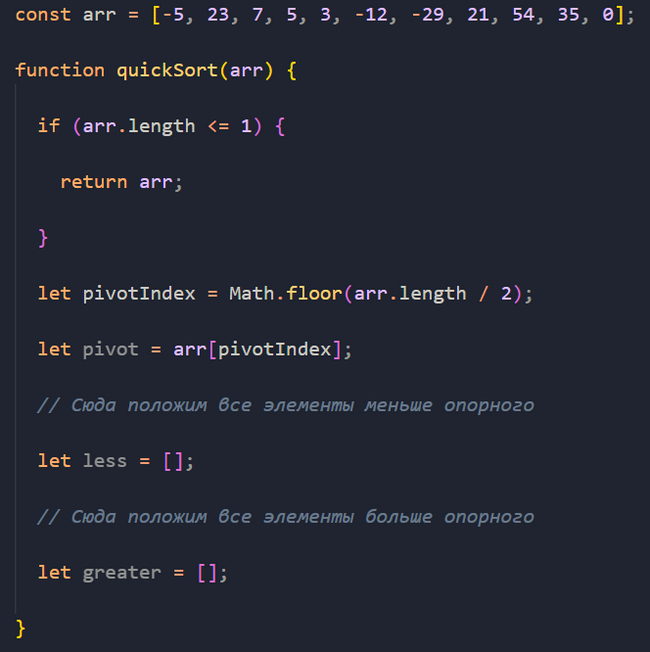
Дальше нужно объявить два пустых подмассива less и greater. В массив less будем сохранять все элементы, которые меньше опорного, а в greater все элементы, которые больше опорного.
Дальше в цикле for мы пробегаем по всем элементам массива и сравниваем каждый элемент с опорным.
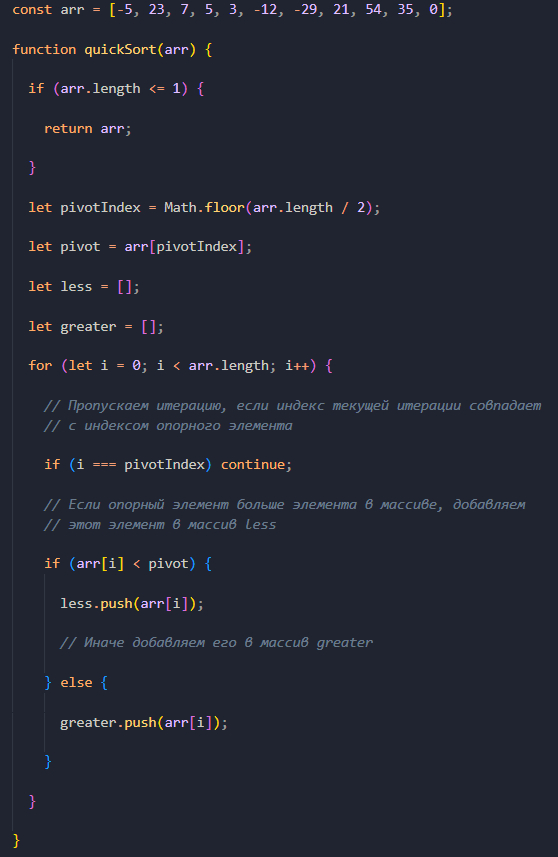
Затем у нас идут три условия. В первом условии мы сравниваем индекс текущей итерации цикла с индексом опорного элемента в массиве.
Если они совпадают, то текущую итерацию цикла мы завершаем с помощью ключевого слова continue, так как нам не нужно добавлять опорный элемент в один из наших подмассивов.
Далее во втором условии мы сравниваем элемент массива с опорным элементом. Если опорный элемент больше, то добавляем наш текущий элемент массива в массив less.
В противном же случае, добавляем текущий элемент массива в массив greater (третье условие).
В итоге, после завершения цикла for, у нас на выходе будет 2 массива: less с числами меньше опорного и greater с числами больше опорного или равными ему.
И дальше мы возвращаем массив, в который разворачиваем результат рекурсивного выполнения функции, принимающей в качестве аргумента массив less. Дальше вставляем наш опорный элемент pivot, а после снова разворачиваем результат выполнения функции для массива greater.
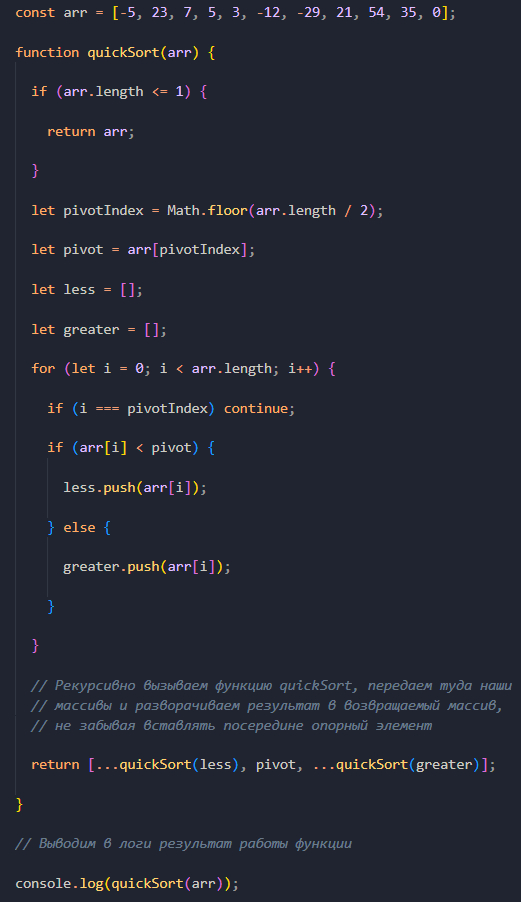
Когда функция доходит до базового случая, рекурсивный вызов функции заканчивается и все одиночные массивы соединяются в один большой отсортированный массив.
Выведем в консоль результат работы функции и убедимся в этом.
Быстрая сортировка в среднем и лучшем случае выполняется за Θ(n * log(n)) и Ω(n * log(n)) соответственно.
В худшем случае время выполнения алгоритма занимает О(n^2).
Более подробно про лучшее, среднее и худшее время выполнения алгоритма быстрой сортировки можно прочитать здесь.
Спасибо тем, кто дочитал, пишите ваше мнение, вопросы и предложения в комментариях. Не забудьте поставить плюсик этому посту, если он вам понравился :3

