Добро пожаловать в увлекательный мир программирования на языке Python! Независимо от того, начинающий вы или опытный программист, вы вооружитесь знаниями и навыками, необходимыми для успешного освоения языка. Python, известный своей простотой и универсальностью, завоевал огромную популярность среди разработчиков во всем мире. Благодаря удобному синтаксису и широкой библиотечной поддержке он идеально подходит для решения широкого спектра задач – от веб-разработки и анализа данных до программирования графических интерфейсов. Книга представляет собой комплексное руководство по изучению языка Python с нуля.
Типы данных делят на 2 группы: изменяемые и не изменяемые.
Изменяемые (mutable)
Списки (list): Упорядоченные коллекции, которые могут содержать элементы разных типов. Пример: [1, "apple", 3.14]. Списки часто используются для хранения и последовательного доступа к элементам
e = [1, 2, 3, 4, 5]
Словари (dict): Коллекции пар ключ-значение. Пример: {"name": "Alice", "age": 25}. Словари удобны для представления объектов с атрибутами. Ключом в словаре может быть значение с не изменяемым типом данных (int, float, str, tuple, bool, frozenset и т.д.)
g = {"name": "Alice", "age": 25}
Множества (set): Неупорядоченные коллекции уникальных элементов. Пример: {1, 2, 3}. Используются для удаления дубликатов и выполнения операций над множествами, таких как объединение, пересечение.
h = {1, 2, 3, 4, 5}
Байтовые массивы (bytearray): Это изменяемая последовательность целых чисел в диапазоне от 0 до 255. Они используются для работы с двоичными данными, например, при чтении файлов или сетевого взаимодействия. bytearray полезен, когда вам нужно изменять данные на уровне байтов.
ba = bytearray([50, 100, 150, 200])
Не изменяемые (immutable)
Целые числа (int): Как положительные, так и отрицательные. Например, 1, 100, -20.
a = 5
Вещественные числа (float): Числа с плавающей точкой (то есть с дробной частью). Примеры: 3.14, -0.001
b = 2.5
Комплексные числа (complex): Этот тип данных используется для представления комплексных чисел, которые включают в себя действительную и мнимую части. В Python комплексные числа могут быть созданы с помощью литерала j для мнимой части. Например, комплексное число 3 + 4j. Комплексные числа используются в научных и инженерных расчетах, где необходимо работать с числами, имеющими мнимую составляющую.
z = 3 + 4j
Длинные целые числа (long): В старых версиях Python (2.x и ранее) существовал отдельный тип данных long для представления очень больших целых чисел. Однако в Python 3 и выше этот тип был упразднен, и теперь все целые числа (int) могут быть любой длины. Таким образом, в современном Python отдельного типа данных long не существует — все большие целые числа автоматически становятся int.
a = 12345678901234567890L # Python 2.x
a = 12345678901234567890 # Python 3
Строки (str): Текст, заключенный в одинарные, двойные или тройные кавычки. Например: "hello", 'world'.
c = "Hello, Python!"
Булевы значения (bool): Имеют всего два значения: True и False. Они часто используются в условиях и логических выражениях.
d = True
Кортежи (tuple): Похожи на списки, но являются неизменяемыми. Пример: (1, "apple", 3.14). Используются, когда данные не должны изменяться после их создания. Если кортеж содержит изменяемые данные, то он становится изменяемым
f = (1, 2, 3)
Диапазон (range): Это неизменяемая последовательность чисел, обычно используемая в циклах for. range полезен для итерации через серии числовых значений.
for i in range(0, 10):
> > print(i)
NoneType: Этот тип данных имеет только одно возможное значение: None. Оно используется для обозначения отсутствия значения. Часто используется в логических операциях например if a is None:
a = None
Frozenset: Это неизменяемый аналог set. Так как frozenset неизменяем, он может использоваться в качестве ключа в словарях.
fs = frozenset([1, 2, 3])
Байты (bytes): Похожи на bytearray, но являются неизменяемыми. Они также представляют собой последовательности целых чисел от 0 до 255 и используются для работы с двоичными данными.
В общем, проект завершён и залит на гитхаб. Посмотрю, как повлияет на поиск работы. Дальше в туториале идёт добавление комментариев. Для моего сайта это неактуально, но в учебных целях займусь. Так, что дальше. Вчера закончилось время третьего спринта, сегодня начинаю изучать четвертый. Всем продуктивных выходных!
Всем привет) на тему двоичного поиска написано множество статей и гайдов, но в этой статье постараюсь подойти к задаче с позиции новичка и расписать максимально просто процесс решения этой задачи на языке программирования Python.
Инструкция к статье: Пожалуйста, если вы программист из Google, Билл Гейтс или Илон Маск, а также страдаете мегаломанией просьба не читать статью, в первых трех случаях она не принесет вам ничего нового, а в четвертом случае это не совсем удачный способ повышения ЧСВ)). Рассматриваются базовые конструкции, приведенный код тут не является "истиной в последней инстанции" как говорится Cujusvis hominis est errare. Поэтому если есть вариант решения пишите в комментарии! Буду рад комментариям от более опытных программистов, обычно их плюсую, спасибо Вам!)) закончим второй частью высказывания - nullius nisi insipientis in errore perseverare.
Рассмотрим кратко что и себя представляет двоичный поиск и зачем он нужен?
Двоичный поиск позволяет повысить производительность кода по сравнению с линейным кодом так как каждый элемент не перебирается а перебираются части списка где бы мог бы быть элемент. Стоит добавить что алгоритм подходит для отсортированного массива данных.
Какие знания используются для решения?
В процессе решения этой задачи применим знания в области циклов и списков.
(Небольшое отступление: https://t.me/python_scrypt - телеграмм канал по Python, задачи и вопросы с собесов а также обзор популярных библиотек и куча полезной инфы)
Приступим к решению задачи, договоримся что отступы в коде буду обозначать как " > > "
Будем разбирать на примере списка чисел от 1 до 10. Давайте попросим пользователя ввести массив чисел:
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
Этот код принимает строку символов, которую вводит пользователь, разделяет ее на отдельные числа с помощью метода split(), и затем с помощью map () применяет функцию int() к каждому элементу, чтобы преобразовать его в соответствующее целое число. После этого все эти числа помещаются в список listx.
Так как есть вероятность что пользователь введет неотсортированный список, а мы помним что нам нужен отсортированный список то выполним сортировку) как раз вспомним как ее сделать.
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
listx.sort() # выполняем сортировку
Далее, создаем копию списка (списки - изменяемый объект) и попросим пользователя ввести элемент который будем искать в списке.
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
listx.sort() # выполняем сортировку
list = listx # создаем копию списка b = int(input("Элемент: ")) # просим пользователя ввести значение для поиска
Дальше запускаем цикл, который будет выполняться пока значение длины списка больше либо равно 1
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
listx.sort() # выполняем сортировку
list = listx # создаем копию списка b = int(input("Элемент: ")) # просим пользователя ввести значение для поиска
while len(list)>=1: # len - получение длины списка list
В теле цикла пропишем 3 условия:
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
listx.sort() # выполняем сортировку
list = listx # создаем копию списка b = int(input("Элемент: ")) # просим пользователя ввести значение для поиска
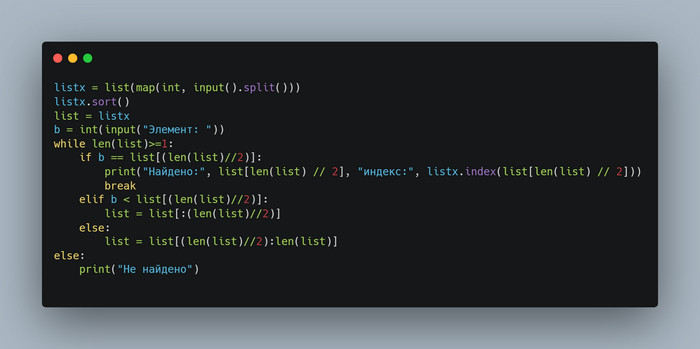
while len(list)>=1: # len - получение длины списка list > > if b == list[(len(list)//2)]: > > > > print("Найдено:", list[len(list) // 2], "индекс:", listx.index(list[len(list) // 2])) # если найден > > > > > >break # прекращение работы цикла > > elif b < list[(len(list)//2)]: # делим список на 2 части > > > > >list = list[:(len(list)//2)] # рассматриваем левую часть > > else: > > > >list = list[(len(list)//2):len(list)] # рассматриваем правую часть
Цикл находит медиану элемента в списке list. Он делает это путем разделения списка на две части, сравнивая элемент b с элементом в середине списка (если список имеет четное количество элементов, он использует среднее значение двух средних элементов). Затем он рекурсивно вызывает себя, если элемент меньше найденной медианы, он обрабатывает только первую половину списка, иначе он обрабатывает вторую половину списка. В конце он выводит медиану и ее индекс в списке.
Теперь представим что значения которое ввел пользователь нет в списке, выведем об этом сообщение. Это можно реализовать путем добавления конструкции else после выполнения цикла (если ни одно из условий в цикле не выполняется то срабатывает конструкция else).
listx = list(map(int, input().split())) # ввод списка чисел списка чисел 1 2 3 4 5 6 7 8 9 10
listx.sort() # выполняем сортировку
list = listx # создаем копию списка b = int(input("Элемент: ")) # просим пользователя ввести значение для поиска
while len(list)>=1: # len - получение длины списка list > > if b == list[(len(list)//2)]: > > > > print("Найдено:", list[len(list) // 2], "индекс:", listx.index(list[len(list) // 2])) # если найден > > > > > >break # прекращение работы цикла > > elif b < list[(len(list)//2)]: # делим список на 2 части > > > > >list = list[:(len(list)//2)] # рассматриваем левую часть > > else: > > > >list = list[(len(list)//2):len(list)] # рассматриваем правую часть else:
> > print("Не найдено") # сработает если в цикле не найдено ни одного значения
Все! готово! ниже прикреплю картинку кода.
Также можете посмотреть код в онлайн интерпретаторе - тык
Почти все браузеры, основанные на chromium, хранят закладки похожим образом. Меняются только директории, в которые эти браузеры установлены. Исключением является только Mozilla Firefox. При этом закладки хранятся в открытом виде, так что, любой желающий может получить к ним доступ. Не сказать, чтобы это была супер секретная информация. Но все же, стоило бы продумать этот момент. В данной статье мы рассмотрим код, который в автоматизированном режиме получает все закладки из распространенных браузеров с помощью Python.
Создадим файл browser_check.py. В нем, напишем код, который будет производить поиск браузеров по пути указанному в одном из словарей.
Импортируем необходимые библиотеки для работы скрипта и определим список, в который будем помещать словари с найденными браузерами:
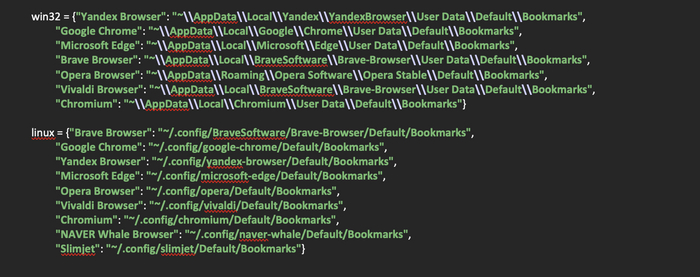
Следующим шагом будет создание двух словарей, в которые поместим пути к распространенным браузерам на операционных системах Windows и Linux, так как поиск браузеров будет производиться по путям, которые специфичны для каждой из операционных систем.
Создадим функцию browser_find(platform: dict) -> None, которая на входе будет получать словарь с путями к закладкам браузеров и проверять их существование. Если путь существует, в объявленный ранее список browser будет добавляться словарь с названием браузера и путем к его закладкам.
Следует обратить внимание на тот факт, что пути к закладкам браузеров указаны при установке их в директории по умолчанию. Если же пользователь поменял расположение директории с браузером, то он найден не будет.
Двигаемся далее и создадим функцию main, в которой будем определять платформу, на которой запущен скрипт. В принципе, если у вас MacOS, то нужно добавить еще один словарь с путями и условие, в котором определяется ваша система. Но, в данном случае детектируются только две операционные системы: Windows и Linux.
В зависимости от того, какая из систем установлена на компьютере с запущенным скриптом, забираем нужный словарь с путями к закладкам и передаем его в функцию browser_find, которую напишем в отдельном файле.
После этого проверяем, есть ли что-то в списке с браузерами. Если список пуст, выводим сообщение для пользователя, что браузеры не найдены. Если же список не пуст, итерируемся по нему в цикле, забираем словари и получаем название браузера, которое содержится в переменной key и путь к закладкам, содержащийся в переменной value.
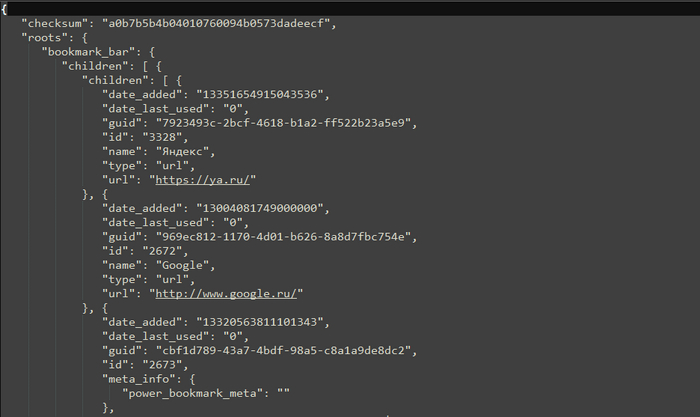
Передаем полученное значение в функцию по парсингу json. На самом деле, файл с закладками, это json-файл с достаточно большой структурой вложенности.
Часть структуры файла закладок
В зависимости от того, что вернет функция парсинга, а возвращает она или список со словарями, в которых содержаться полученные значения или False, двигаемся дальше. Если мы получаем список, то открываем файл с названием браузера на запись. Обратите внимание на то, что в данном случае файл открыт в режиме дозаписи, о чем свидетельствует параметр «a». Затем итерируемся по полученному списку, забираем из словарейОбратите внимание на ветку «roots», в которой и находятся все закладки. Так как закладки в браузере, это не просто последовательный набор названий и ссылок, то их группировка происходит по директориям создаваемым пользователем. Данные директории имеют название «children» и имеют тип «folder». Также, к примеру, на Панели закладок могут быть как директории с закладками, так и просто закладки для быстрого доступа. Тип закладок без папок «url».
Создадим файл bookmarks_find.py и приступим к написанию кода. Для начала импортируем библиотеки, которые понадобятся в данном скрипте.
import json
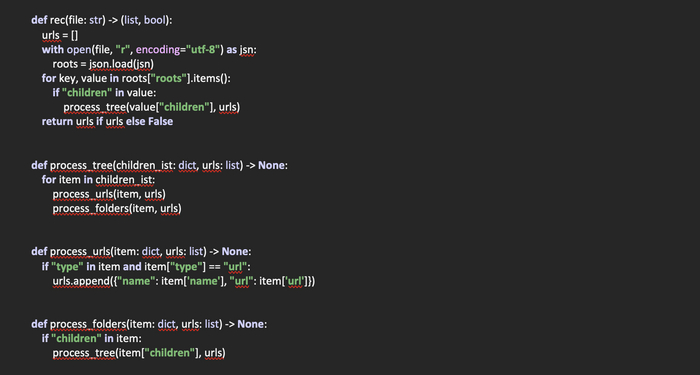
Создадим функцию rec(file: str) -> (list, bool), в которую передается путь к закладкам браузера. Возвращает же данная функция список со словарями, в которых содержится имя и url закладки. В случае же, если закладки найти не удалось, возвращается False.
Объявляем список urls, в который будем помещать найденные закладки в виде словарей. Откроем файл с закладками для чтения, поместим его содержимое в переменную roots.
Так как значение данной переменной будет являться словарем, проитерируемся по нему в цикле, указав ветку «roots» в качестве стартовой. Получим ключ и значение и проверим, есть ли в нем название «children». Если да, передаем полученную ветку в функцию process_tree, которую мы создадим чуть позже для обработки. Также передаем в эту функцию список urls. По сути, при передаче списка, если вспомнить его свойства, мы передаем указатель на оригинальный список, так как его копирования в данном случае не происходит. А значит, при его изменении в других функциях измениться и оригинальный словарь.
После того, как завершим итерацию по файлу, проверяем, пуст или нет список. Если список не пуст, возвращаем его из функции. Если пуст - возвращаем False.
Теперь создадим функцию process_tree(children_ist: dict, urls: list) -> None, которая получает на входе словарь из полученной директории и указатель на список, в котором будут храниться найденные ссылки в виде словарей.
Здесь все просто. Данная функция как переходник, в котором мы итерируемся по полученному словарю и передаем полученные значения в следующие функции для обработки.
Создадим функцию process_urls(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список. У данной функции предназначение – выявить ссылки в переданном словаре. Для этого проверяем, есть ли в переданном словаре ключ «type» и является ли его значение «url». Если да, забираем название ссылки и саму ссылку и добавляем в виде словаря в список urls.
И еще одна функция, которая будет необходима для проверки, не является ли полученный словарь директорией со ссылками «children». Создадим функцию process_folders(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список.
Здесь все тоже просто, проверяем, есть или нет «children» в переданном словаре. Если есть, передаем его рекурсивно в функцию process_tree для дальнейшей обработки.
Полный код скрипта:
import json
На этом вроде бы все. Основные скрипты и функции написаны, осталось только проверить, как это будет работать.
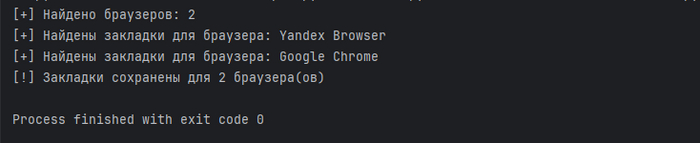
В процессе работы скрипт выведет несколько сообщений: о том, сколько было найдено браузеров, для какого из браузеров найдены закладки и для какого количества из найденных закладки сохранены.
Сообщения в терминале
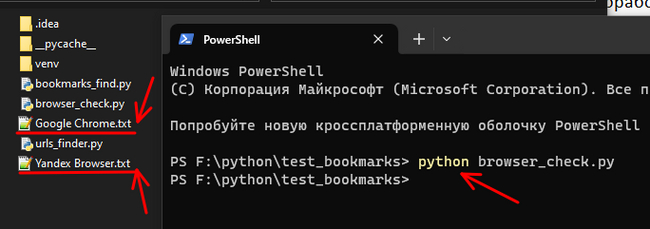
Если скрипт найдет браузеры в системе, в директории скрипта будут созданы файлы с названиями найденных браузеров, в которых содержатся закладки.
Файлы с найденными закладками
Как видно на скриншоте, у меня установлено два браузера. Давайте откроем один из файлов и посмотрим на часть его содержимого.
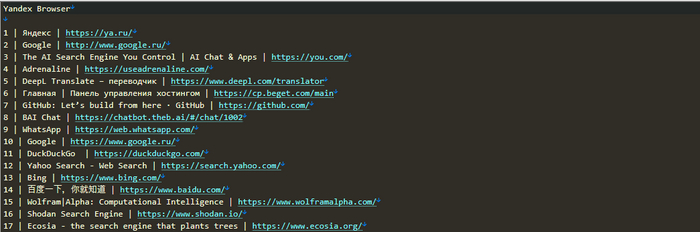
Содержимое файла с найденными закладками
Как видим, закладки найдены. За годы работы в данном браузере их накопилось чуть более 3000. Конечно же, показывать все я не буду, потому, только самое начало, для того, чтобы убедиться, что скрипт работает.
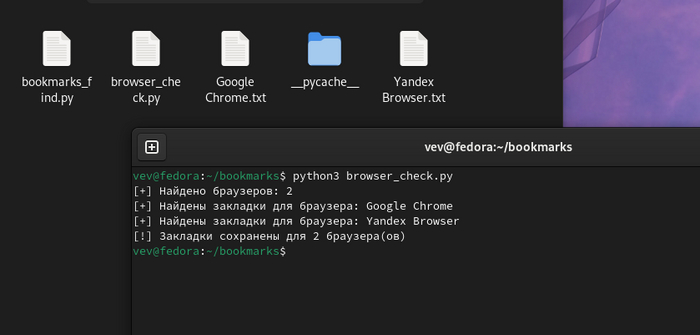
Скрипт работает как на Windows, так и на Linux. Вот скрин с работой скрипта в Fedora Workstation, в которой браузеры установлены по умолчанию, с помощью пакетов.
Работа скрипта в Fedora Workstation
Подведем итоги:
В данной статье мы научились рекурсивно парсить файл json, узнали, каким способом можно определить операционную систему, установленную на компьютере, а также сохранять данные из json в текстовый файл.
В перспективе, применений данному скрипту можно найти достаточно много. Все зависит только от вашей фантазии.