Новый подход к тренировке больших языковых моделей, ориентированный на повышение эффективности за счет приоритезации наиболее информативных токенов.
Порядок целевых токенов оказывает существенное влияние на сходимость обучения языковых моделей – от NanoGPT (0.09M параметров) и GPT-2-mini (2.67M параметров) для арифметических задач, до Qwen-2.5-1.5B-Instruct при классификации токсичного контента, и GPT-2-small (137M параметров) при генерации текста на WikiText-2, – демонстрируя, что даже незначительные архитектурные решения могут предсказывать будущие точки отказа в процессе оптимизации.
Исследование предлагает стратегию обучения, оптимизирующую последовательность предсказания токенов для улучшения производительности в различных задачах обработки естественного языка.
Оптимизация обучения больших языковых моделей (LLM) остается сложной задачей, особенно в контексте поддержания вычислительной эффективности при одновременном повышении производительности. В работе «Training LLMs Beyond Next Token Prediction -- Filling the Mutual Information Gap» предложен новый подход, основанный на приоритетном предсказании наиболее информативных токенов в процессе обучения. Данная стратегия позволяет оптимизировать последовательность предсказания токенов, что приводит к улучшению результатов в задачах арифметики, многометочной классификации текста и генерации естественного языка. Какие перспективы открывает данное направление для разработки более эффективных и интеллектуальных языковых моделей?
Предсказание Следующего Токена: Основа и Ограничения
Современные языковые модели, такие как GPT-2, семейства Llama и Qwen, базируются на предсказании следующего токена. Этот подход обучает модель вероятностному распределению символов в последовательности, учитывая контекст.
Несмотря на эффективность, данный метод может приводить к "смещению экспозиции". Модель обучается на идеальных данных, что ограничивает ее способность обрабатывать сложные или новые ситуации.
В процессе обучения модель не сталкивается с ошибками, что снижает ее устойчивость к неточностям во входных данных и ограничивает адаптацию к изменяющимся условиям. Это создает замкнутый круг, где модель совершенствуется в предсказании наиболее вероятных продолжений, но теряет способность к инновациям.
Хаос – не сбой, а язык природы.
Усиление Контекста: Максимизация Взаимной Информации
Стратегия максимизации взаимной информации (MI) между исходными и целевыми токенами улучшает контекстное понимание. В отличие от традиционных методов, этот подход направлен на выявление наиболее информативных элементов в контексте.
Приоритизация токенов посредством Max(MI(SS;tt)) позволяет модели концентрироваться на частях входной последовательности, которые вносят максимальный вклад в понимание и генерацию текста. Это особенно важно при неоднозначности или неполноте контекста.
Использование взаимной информации в качестве критерия приоритизации позволяет модели отфильтровывать шум и сосредотачиваться на релевантных сигналах, повышая точность и связность генерируемого текста. Такой подход применим в машинном переводе, суммаризации текста и генерации диалогов.
Применение и Валидация: За Гранью Беглости
Применение функции Max(MI(SS;tt)) демонстрирует улучшение производительности в различных задачах. Наблюдается повышение точности в многометочной классификации и сложных рассуждениях, таких как арифметические задачи. В задачах умножения двузначных чисел достигнут прирост точности до 28.5%.
Для повышения устойчивости используются методы расширения данных (Data Augmentation), дополненные алгоритмом TF-IDF. Техника переупорядочивания токенов (Token Reordering) способствует уточнению контекстной обработки информации.
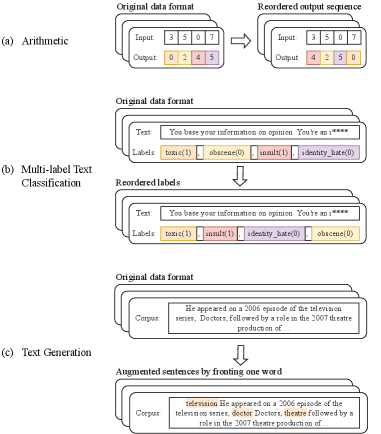
Исследование демонстрирует, что переупорядочивание целевой последовательности успешно применяется в различных задачах, таких как арифметические вычисления, где переставляются цифры числового ответа, многоместная классификация текста, определяющая порядок предсказаний меток, и генерация текста, где выбранный токен вставляется в начало каждого предложения. В арифметических задачах, таких как 35×07=0245, переупорядочивание цифр числового ответа является эффективным методом решения, в то время как в задачах многоместной классификации текста определяется порядок предсказаний меток, а в генерации текста - вставляется выбранный токен в начало каждого предложения. В ходе исследования было установлено, что переупорядочивание целевой последовательности применимо к арифметическим задачам, где переставляются цифры числового ответа, задачам многоместной классификации текста, где определяется порядок предсказаний меток, и задачам генерации текста, где выбранный токен вставляется в начало каждого предложения.
Стратегия позволяет смягчить проблему галлюцинаций, повышая фактическую корректность генерируемого текста. Сокращение неточностей в контенте является важным аспектом повышения надежности и доверия к модели.
Измерение Успеха: Perplexity и За Его Пределами
Традиционные метрики, такие как Perplexity, остаются ценными для оценки качества генерации текста, отражая способность модели предсказывать следующий токен. Однако, целостная оценка требует учета производительности по множеству задач и снижения нежелательных явлений, таких как галлюцинации.
Разработанная стратегия достигает средней точности 94.96% при решении арифметических задач и 78.64% по 9 задачам из GLUE benchmark. Это свидетельствует о значительном прогрессе в способности модели к обобщению и применению знаний.
Сочетание улучшенных метрик и результатов по задачам подтверждает эффективность максимизации взаимной информации и использования целевых методов аугментации данных. В частности, Max(MI(SS;tt)) превосходит Plain на 1.15% и Reverse на 2.04% в задачах многоклассовой классификации.
Каждый запуск – это маленький апокалипсис, и свидетельствами выживших остаются лишь цифры и графики.
Исследование демонстрирует, что последовательность обучения языковой модели имеет решающее значение. Авторы предлагают отойти от простого предсказания следующего токена, фокусируясь на тех, что несут наибольшую информационную нагрузку. Это напоминает о хрупкости любой системы, где нарушение баланса даже в незначительных элементах может привести к неожиданным последствиям. Ада Лавлейс некогда заметила: «Развитие науки — это не просто накопление знаний, а умение видеть связи между ними». Подобно этому, оптимизация последовательности предсказания токенов – это не просто технический прием, а попытка увидеть и укрепить внутренние связи в сложной экосистеме языковой модели, где каждый выбор архитектуры – это пророчество о будущих ошибках. Попытка управлять этой системой – это всегда компромисс, застывший во времени.
Что впереди?
Предложенная работа, стремясь оптимизировать последовательность предсказания токенов, лишь обнажает фундаментальную зависимость любой системы от порядка её формирования. Оптимизация предсказания «информационно-насыщенных» токенов – это не решение, а перестановка факторов в неизбежном приближении к состоянию полной взаимозависимости. Разделяя задачу на приоритетные компоненты, система лишь усложняет картину своих будущих сбоев, закладывая пророчество о том, какие именно точки отказа станут критическими.
Следующим шагом, вероятно, станет попытка моделирования не только вероятности предсказания токена, но и стоимости его ошибки – оценки ущерба от неверного решения в контексте всей системы. Однако, эта оптимизация лишь отодвинет неизбежное – всё связанное когда-нибудь упадёт синхронно, и цена ошибки будет определяться не вероятностью, а масштабом взаимосвязанных компонентов. Иллюзия контроля над сложностью будет лишь укрепляться.
Вместо поиска оптимальной последовательности обучения, возможно, стоит сосредоточиться на создании систем, способных к самовосстановлению после сбоев – не предотвращая их, а смягчая последствия. Потому что системы – это не инструменты, а экосистемы. Их нельзя построить, только вырастить, и в этой эволюции неизбежны мутации и вымирания.