

SQL: знакомство
20 постов
20 постов

20 постов
UPDATE — это команда, с помощью которой мы меняем данные, уже существующие в таблице.
Не добавляем новые строки (как INSERT), не удаляем (как DELETE), а правим то, что есть.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
Базовый синтаксис выглядит следующим образом:
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE condition;
UPDATE table_name → в какой таблице меняем данные.
SET → что именно меняем и на какие значения.
WHERE → условие, чтобы обновить только нужные строки.
Если забыть WHERE → обновятся все строки таблицы. Классический факап новичка.
Меняем телефон у клиента → UPDATE customers SET phone = '...' WHERE id = 5;
Уменьшаем остаток товара после покупки.
Обновляем статус заказа.
Проще говоря: везде, где данные живые и меняются со временем.
Можно обновлять сразу несколько строк:
UPDATE products
SET price = price * 0.9
WHERE category = 'clothes';
В этом запросе нет ограничений по количеству строк, если в таблице есть 10 строк с категорией = 'clothes', то скидка в 10% применится ко всем 10 строкам.
В UPDATE можно использовать JOIN при более сложной логике
Мы делаем обновления в таблице orders, но делаем их для тех покупателей, у которых есть признак ВИП. А признак ВИП хранится в таблице customers.
В этом запросе явно не указан JOIN, но с JOIN запрос выглядел бы вот так:
UPDATE orders o
SET amount = amount * 1.1
FROM orders o2
JOIN customers c ON o2.customer_id = c.id
Здесь больше строк, поэтому многие предпочитают первый вариант.
PostgreSQL, SQL Server → поддерживают UPDATE ... FROM.
MySQL → там другой синтаксис:
UPDATE orders o
JOIN customers c ON o.customer_id = c.id
SET o.amount = o.amount * 1.1
WHERE c.vip = true;
Т.е. в MySQL JOIN присутствует в явном виде.
RETURNING в PostgreSQL
UPDATE orders
SET status = 'done'
WHERE id = 101
RETURNING *;
Сразу получаешь обновлённые строки, без лишнего SELECT. В MySQL и SQL Server такого нет.
Deadlock при UPDATE
Транзакция А захватила строку 1 и ждёт строку 2.
Транзакция B захватила строку 2 и ждёт строку 1.
Обе ждут друг друга бесконечно.
База видит: «ну, так не пойдёт» → и убивает одну из транзакций, чтобы освободить дорогу.
При обычной блокировке ты просто ждёшь, пока другой закончит.
При deadlock оба ждут друг друга, и никто никогда не закончит — тупик.
В UPDATE можно использовать подзапросы:
UPDATE employees
SET salary = salary + 5000
WHERE department_id = (
SELECT id FROM departments WHERE name = 'IT'
);
Здесь UPDATE зависит от результата подзапроса.
UPDATE без SET
В некоторых СУБД (например, SQL Server) можно писать:
UPDATE table_name
SET column = column;
На вид — бесполезно. Но так можно снимать блокировки или триггерить AFTER UPDATE.
Можно использовать TOP и LIMIT при UPDATE
UPDATE TOP (10) users SET active = 0; -- для SQL Server
UPDATE users SET active = 0 LIMIT 10; -- для MySQL
А вот для PostgreSQL такого механизма нет - надо будет через CTE реализовывать.
UPDATE — мощный инструмент. Он нужен везде, где данные живут и меняются. Но:
всегда помни про WHERE,
учитывай блокировки,
и знай фишки СУБД (RETURNING, JOIN, LIMIT).
Напоминаю про свой канал На связи: SQL Присоединяйся для обсуждения вопросов по изучению SQL.
INSERT — это оператор для добавления новых строк в таблицу.
Классика выглядит так:
INSERT INTO customers (name, age, city)
VALUES ('Оля', 28, 'Москва');
Главные слова:
INSERT INTO — куда добавляем,
VALUES — что именно добавляем.

А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
При вставке значений в таблицу можно выделить одиночную вставку и массовую вставку.
Одиночная - это когда в запросе содержится вставка одной строки, а массовая - нужно вставить больше чем одну строку.
INSERT INTO products (name, price) VALUES ('Яблоки', 100);
INSERT INTO products (name, price) VALUES ('Груши', 120);
-- и так 1000 раз 😅
INSERT INTO products (name, price)
VALUES
('Яблоки', 100),
('Груши', 120),
('Бананы', 150);
Один INSERT на 1000 строк работает быстрее, чем 1000 отдельных запросов, потому что база открывает и закрывает транзакцию только один раз.
Транзакция — это логическая единица работы с базой данных, набор действий (обычно INSERT, UPDATE, DELETE и т. д.), которые выполняются как одно целое.
База гарантирует, что или все действия внутри транзакции будут выполнены, или не выполнится ни одно.
Например:
Перевод денег с карты на карту.
Снять деньги с карты А.
Зачислить деньги на карту Б.
Если выполнить только первый шаг, а второй не получится — деньги «пропадут».
Транзакция гарантирует, что либо оба шага выполнятся, либо оба отменятся.
Так вот, даже если мы явно в коде не прописываем начало и окончание транзакции, то наша база автоматически оборачивает наш запрос началом и окончанием транзакции
BEGIN;
INSERT INTO products (name, price) VALUES ('Яблоки', 100);
COMMIT;BEGIN;
INSERT INTO products (name, price) VALUES ('Груши', 120);
COMMIT;-- и так 1000 раз 😅
BEGIN;
INSERT INTO products (name, price)
VALUES
('Яблоки', 100),
('Груши', 120),
('Бананы', 150);
COMMIT;
Но при этом вставлять одним запросом млн строк - это плохо. Можно словить блокировку. Поэтому для большого объема вставки - лучше дробить на несколько маленьких частей.
Оптимальный размер батча — подбирается экспериментально. Обычно от 5k до 50k строк за один заход.
При вставке данных в таблицу у нас часто используется уникальный идентификатор строки, часто этот идентификатор является автоинкрементом, т.е. база сама записывает значение в это поле.
CREATE TABLE users (
id SERIAL, -- автоинкремент
name TEXT
);
INSERT INTO users (name) VALUES ('Оля'); -- id = 1
INSERT INTO users (name) VALUES ('Маша'); -- id = 2
Каждый INSERT добавляет новую запись, а автоинкремент гарантирует уникальный идентификатор для этой строки.
Без него нужно было бы самому считать, какой следующий номер ставить.
Автоинкремент экономит время и предотвращает ошибки.
Но автоинкремент не гарантирует, что значения в поле id будут "последовательными", он гарантирует, что значения в этом поле будут уникальными.
Получается, что при INSERT в поле с автоинкрементом могут быть "дырки".
Это получается, например, в следующих кейсах:
1. отмененная вставка:
- Сделали INSERT, база выделила id = 5.
- Транзакцию откатили (ROLLBACK).
- Id 5 пропал, следующие вставки идут с 6.
2. Удаление строк:
- Если удалить записи, то номера исчезнут, но новые не «подтянутся» к освободившимся.
3. Параллельная вставка:
- Две транзакции одновременно вставляют строки.
- Каждая получает свой id, даже если одна потом откатится → тоже появляются пропуски.
В PostgreSQL номера генерируются через объект SEQUENCE.
Если ты вручную добавил строку с id = 9999, а sequence «застрял» на 5000.
То, когда при следующих попытках осуществить вставку строки БД дойдет до значения 9999 - этот INSERT упадёт с ошибкой: «дубликат ключа». Потому что sequence не обновляется автоматически! Sequence не смотрит на максимальный id в таблице. Он просто отдаёт своё следующее число.
Решение может быть:
ALTER SEQUENCE … RESTART WITH <нужный номер>.
На вставку строк в таблицу может быть вызов триггера. Потому что вставка строки - это новая информация. А в зависимости от новой информации у нас могут быть разная логика подсчета того или иного показателя. Например, расчет бонусов для клиента зависит от суммы заказа. Поэтому при каждой вставке в таблицу заказов будет вызван триггер по расчету бонусов для клиента.
CREATE TRIGGER bonus
AFTER INSERT ON orders
FOR EACH ROW
EXECUTE FUNCTION bonus_cnt();
Каждая новая строка вызовет bonus_cnt().
Даже если ты вставляешь 1000 строк, триггер вызовется 1000 раз.
Есть еще такое понятие как UPSERT.
UPSERT = INSERT + UPDATE, т.е. «вставить новую запись, а если такая запись уже есть — обновить существующую».
Пример: у нас есть таблица users с колонкой id. Мы хотим добавить пользователя с id = 1.
Если пользователя нет → вставляем.
Если пользователь есть → обновляем его данные.
Но такой INSERT + UPDATE в каждой СУБД реализуется по разному.
Одна и та же логика «вставить или обновить» в коде не переносится напрямую между базами. То, что называется UPSERT в PostgreSQL, будет работать иначе в MySQL и совсем иначе в SQL Server.
INSERT ... ON CONFLICT (id) DO UPDATE ... -- Вставляет запись, если id ещё нет; иначе обновляет эту запись. PostgreSQL
INSERT ... ON DUPLICATE KEY UPDATE ... -- MySQL
MERGE ... -- SQL Server
По сути, UPSERT — это концепция, а не единый универсальный оператор.
На скорость INSERT влияет наличие индексов в таблице. Чем больше индексов, тем долше будет выполняться вставка. Каждая новая строка должна обновить все индексы. При массовых загрузках индексы иногда отключают, а потом создают заново
А еще, иногда база говорит: «Вставка прошла успешно», но на диск ещё ничего не записано.
PostgreSQL и MySQL (InnoDB) используют write-ahead log: запись сначала идёт в журнал, потом — на диск.
Если прямо в этот момент выключить сервер → можно потерять часть данных.
Решается настройкой fsync, commit и уровней надёжности транзакций.
INSERT — это не просто «добавить данные». Это про индексы, блокировки, автоинкременты, батчи и даже про то, как СУБД пишет на диск.
Обычно все знают самое базовое применение LIMIT - ограничение строк выдачи в запросе.
LIMIT 10 -> показать 10 строк
Но применение LIMIT не ограничивается только ограничением :-).
Есть интересные кейсы по использованию LIMIT в своих запросах.
Об этом чуть ниже.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!

И так, какие же кейсы есть с применением LIMIT
LIMIT + OFFSET
Многие помнят про LIMIT, но забывают про то, что можно еще применять сдвиг.
SELECT *
FROM users
ORDER BY id
LIMIT 10 OFFSET 20;
Этот запрос вернёт 10 строк, начиная с 21-й.
Такой прием применяется, например, в постраничной выдаче результатов запроса.
Но этот кейс имеет и минусы: OFFSET все равно просматривает первые 20 строк, чтобы добраться до нужных. При больших объемах OFFSET работает медленно.
LIMIT в UPDATE и DELETE
Да, да - в этих операторах тоже можно использовать LIMIT, не только в SELECT
DELETE FROM logs ORDER BY created_at ASC LIMIT 1000;
Так чистят таблицу порциями, чтобы не завалить базу огромным удалением.
LIMIT в подзапросах
Об этом часто помнят, т.к. подзапрос является запросом, а в запросах использование LIMIT - вполне привычное дело.
Найдем самый дорогой заказ:
SELECT *
FROM orders
WHERE id = (SELECT id FROM orders ORDER BY price DESC LIMIT 1);
Это иногда проще, чем возиться с MAX() и джойнами.
LIMIT vs FETCH … WITH TIES
В некоторых СУБД (например, SQL Server, Oracle) есть фича:
SELECT *
FROM products
ORDER BY price DESC
FETCH FIRST 3 ROWS WITH TIES;
Такой запрос вернёт не просто 3 строки, а все строки, у которых цена такая же, как у третьей записи.
(например, если на третьем месте несколько товаров с одинаковой ценой).
LIMIT показывает первые N строк после сортировки
А вот WITH TIES говорит: «Выдай все строки, которые наравне с последней по значению сортировки».
В других СУБД такой синтаксис можно реализовать через LIMIT + подзапрос с оконной функцией RANK()
LIMIT 0
Очень полезный трюк.
SELECT * FROM users LIMIT 0;
Вернёт пустую таблицу, но со всеми названиями и типами столбцов.
Это часто используют для генерации схемы в BI-инструментах или в тестах
LIMIT в CTE (PostgreSQL)
Можно ограничивать данные прямо на уровне общего табличного выражения (CTE), чтобы уменьшить нагрузку:
WITH top_orders AS (
SELECT * FROM orders ORDER BY price DESC LIMIT 100
)
SELECT * FROM top_orders WHERE customer_id = 42;
Так мы сначала берём только 100 дорогих заказов, а потом фильтруем по клиенту.
В итоге LIMIT — это не просто «дай 10 строк», а инструмент для оптимизации, постраничной навигации, аккуратных обновлений и даже для защиты от перегруза.
Подписывайся на мой ТГ канал На связи: SQL, чтобы узнавать/вспоминать еще больше нюансов SQL запросов.
ORDER BY — штука вроде бы простая («отсортируй строки»), но там есть много нюансов, про которые мы просто не помним или не пользуемся.
Вообще мы даже своими смартфонами не всегда (да, что уж - никогда) не пользуемся на полную мощность.
В своем канале На связи: SQL рассказываю про некоторые забытые нюансы языка SQL, особенности и необходимую теорию, чтобы любой начинающий мог свободно познакомиться с этим языком и применить его в дальнейшем для своих задач. Канал создан недавно, с 0 подписчиков, но уже активно наполняется контентом. Подписывайся!

Блок с ORDER BY предназначен для сортировки результата выборки.
По умолчанию сортировка ASC (по возрастанию). Можно явно писать:
ORDER BY age ASC -- от младших к старшим
ORDER BY age DESC -- от старших к младшим
2. Можно сортировать сразу по нескольким столбцам:
ORDER BY country, city
Сначала сортируются страны, внутри них — города.
3. Можно писать не имя, а номер колонки в SELECT:
SELECT name, age
FROM users
ORDER BY 2 DESC; -- сортируем по age
Но это считается «плохим тоном» — лучше явно указывать названия. Хотя мне очень нравится это использовать, особенно, когда в селекте не просто имя столбца, а вычисление.
4. NULL в ORDER BY требует особого внимание.
NULL в разных БД обрабатывается по-разному.
В PostgreSQL:
ASC → NULL идут в конце
DESC → NULL идут в начале
можно явно писать:
ORDER BY age ASC NULLS FIRST;
ORDER BY age DESC NULLS LAST;
В MySQL и SQL Server правила отличаются:
в MySQL NULL всегда считаются «меньше всего» (т.е. идут первыми в ASC).
в SQL Server можно управлять через ISNULL()/COALESCE().
В MySQL и SQL Server нельзя использовать NULLS FIRST или NULLS LAST при сортировке,
Для SQL Server используем:
ORDER BY ISNULL(age, 9999) ASC;
ORDER BY COALESCE(age, 9999) ASC;
Здесь NULL мы заменяем на большое число (9999), и оно уходит в конец сортировки по возрастанию.
А если хотим NULL в начало — ставим что-то маленькое, например -1.
Для MySQL есть поведение по умолчанию:
При ASC → NULL идут первые
При DESC → NULL идут последние
А если нужно наоборот, то делаем хитрость с IS NULL:
ORDER BY age IS NULL, age ASC;
Здесь age IS NULL вернёт 1 для NULL и 0 для обычных значений.
SQL сначала отсортирует по этому условию (0 → 1), а потом уже по age.
5. Можно сортировать не только по полям, но и по функциям.
ORDER BY LENGTH(name) DESC;
ORDER BY purchase_amount * discount;
6. Случайная сортировка - имеет место быть. Но очень "дорога" в использовании на больших объемах.
-- PostgreSQL / SQLite
ORDER BY RANDOM()-- MySQL
ORDER BY RAND()
Часто случайная сортировка используется при тестировании на небольших объемах.
- хотим показать пользователю случайный товар в магазине
- хотим проверить, как работает приложение, не завися от конкретного порядка записей
- рекомендательные системы: в выдачу добавляем случайный товар, чтобы не зацикливать пользователя только на "популярных" товарах.
- игры или викторины: рандомная выдача вопросов.
7. Есть еще такое понятие как COLLATION (сравнение строк).
ORDER BY учитывает локаль (collation). Поэтому, например, русские буквы могут сортироваться по-разному в разных СУБД:
А может идти перед а, или наоборот.
Можно явно указать сортировку:
ORDER BY name COLLATE "C" -- по байтовому значению
ORDER BY name COLLATE "ru_RU" -- по русскому алфавиту
Представь, что у тебя есть список имён:
['Елена', 'елена', 'Жанна', 'Анна']
Когда ты пишешь в SQL:
SELECT * FROM users ORDER BY name;
база должна решить:
считать ли «Елена» и «елена» одинаковыми?
что идёт раньше: «Ж» или «А»?
как сравнивать буквы с диакритикой: «é» vs «e»?
Вот именно на эти вопросы отвечает collation.
То есть COLLATION — это как правило сортировки в библиотеке: от него зависит, где именно окажется твоя книга.
То есть, ORDER BY — это не просто «отсортировать», а ещё и про то:
куда денутся NULL
как сортируются строки (с учётом локали)
можно ли сортировать по выражениям или случайно
В моем ТГ канале На связи: SQL я знакомлю новичков с языком SQL и хочу, чтобы те, кто желает познакомиться с анализом данных с легкостью шли в это направление. Присоединяйся!
Когда мы работаем с базой данных, почти всегда хотим не просто что-то выбрать, а применить несколько условий сразу. Например: выбрать всех клиентов старше 18 лет и с активной подпиской.
И здесь на помощь приходят два основных логических оператора: AND и OR.

AND — «и». Все условия должны быть выполнены одновременно.
Пример: выбрать из холодильника молоко и яйца, чтобы приготовить омлет:
SELECT *
FROM fridge
WHERE product = 'milk' AND product = 'eggs';
(Да, в реальности одной строки с молоком и яйцом не будет, но идея ясна: оба условия должны выполняться вместе.)
OR — «или». Достаточно, чтобы выполнено было хотя бы одно условие.
Пример: выбрать продукты, которые нужно купить или молоко, или яйца:
SELECT *
FROM shopping_list
WHERE product = 'milk' OR product = 'eggs';
Эти операторы обычно используют в блоке WHERE, чтобы фильтровать данные.
Также можно применять их в:
HAVING — фильтрация агрегатов после GROUP BY
JOIN ON — комбинирование условий соединения таблиц
Пример с HAVING:
SELECT category, COUNT(*)
FROM fridge
GROUP BY category
HAVING COUNT(*) > 5 AND AVG(expiry_date) < '2025-08-01';
Порядок выполнения важен
AND имеет более высокий приоритет, чем OR.
Если смешиваете их, всегда используйте скобки для точного порядка:
SELECT *
FROM fridge
WHERE (product = 'milk' OR product = 'eggs') AND expiry_date < '2025-08-01';
AND «сжимает» результат, OR «расширяет» результат
AND оставляет меньше строк, OR — больше
Частые ошибки
Забыли скобки и получили слишком большой или слишком маленький результат
Использовали AND там, где нужен OR (или наоборот)
Смешали NULL значения: NULL AND TRUE и NULL OR TRUE могут вести себя неожиданно
Представим, что мама проверяет холодильник:
У неё есть список продуктов, которые могут испортиться: молоко, яйца, йогурт
Она хочет приготовить что-то, если и молоко, и яйца в наличии → AND
Она хочет перекусить, если есть молоко или йогурт → OR
В SQL это выглядит так:
-- Для приготовления омлета
SELECT *
FROM fridge
WHERE product = 'milk' AND product = 'eggs';
-- Для перекуса
SELECT *
FROM fridge
WHERE product = 'milk' OR product = 'yogurt';
AND и OR — это простые, но мощные инструменты фильтрации. Правильное использование скобок и понимание приоритета операторов помогает избежать ошибок и выбирать точно те данные, которые нужны.
А в своем канале На связи: SQL я публикую информацию с особенностями и нюансами в языке SQL, разбираю аналитические запросы и подходы работы с данными. Канал создала недавно с нулем подписчиков, но там уже есть интересная информация для работы аналитиков. Подписывайся!
Каждый из нас ежедневно сталкивается с бытовыми вопросами. У вас огромный холодильник: продукты, напитки, соусы, остатки вчерашнего ужина. Каждый день нужно понять: что из этого пригодно к употреблению сегодня, что нужно использовать для обеда, а что отправить в мусор.

Вот тут и появляется WHERE. Это фильтр, который помогает выбрать именно нужные строки из таблицы — или продукты из холодильника.
А в своем канале На связи: SQL я публикую информацию с особенностями и нюансами в языке SQL, разбираю аналитические запросы и подходы работы с данными. Канал создала недавно с нулем подписчиков, но там уже есть интересная информация для работы аналитиков. Подписывайся!
Нам нужно выкинуть все продукты, у которых истек срок годности:
SELECT *
FROM fridge
WHERE expiry_date < CURRENT_DATE;
fridge — наша таблица с продуктами
expiry_date < CURRENT_DATE — условие: выбираем просроченные продукты
CURRENT_DATE - текущая дата
Сравнения: =, >, <, >=, <=
Логические связки: AND, OR, NOT
Проверки на вхождение: IN, BETWEEN, LIKE
Подзапросы: «проверить список покупок перед выбором»
Или, мы хотим приготовить что-то на десерт:
SELECT *
FROM fridge
WHERE category = 'dessert' AND expiry_date > CURRENT_DATE;
Условие AND expiry_date > CURRENT_DATE добавляем на случай, если мы не выкинули всю просрочку до этого.
В WHERE можно использовать подзапросы. Это когда нам нужна информация из другого источника, чтобы использовать ее в своем запросе. Например, нам надо понять что из рецепта отсутствует у нас в холодильнике.
SELECT *
FROM cooking_recipe
WHERE product NOT IN (SELECT product FROM fridge);
WHERE проверяет какие продукты отсутствуют в холодильнике.
Аналогично можно использовать EXISTS или NOT EXISTS
SELECT *
FROM fridge f
WHERE EXISTS (SELECT 1 FROM cooking_recipe s WHERE s.product = f.product);
EXISTS = есть продукт в списке
NOT EXISTS = нет продукта в списке
Эти конструкции позволяют сравнивать с набором значений.
SELECT *
FROM fridge
WHERE expiry_date <= ALL (SELECT expiry_date FROM fridge WHERE category = 'milk');
Все хорошие домохозяйки используют принцип ротации. Выбирают продукты, срок годности которых меньше всех в категории “молоко”.
Подзапрос (SELECT expiry_date FROM fridge WHERE category = 'milk') возвращает даты всех банок молока.
Условие expiry_date <= ALL (...) означает: выбрать только те банки, у которых дата годности меньше или равна каждой другой банке молока.
Практически это банка (или несколько, если даты совпадают), которая старше всех остальных.
То есть, результат будет одна или несколько банок с самой ранней датой годности.
SELECT *
FROM fridge
WHERE expiry_date <= ANY (SELECT expiry_date FROM fridge WHERE category = 'milk');
Условие expiry_date <= ANY (...) означает: выбрать все банки молока, у которых дата годности меньше или равна хотя бы одной другой банке молока.
Тут почти все банки проходят условие, кроме самой свежей (если она самая большая по сроку).
Результат может быть несколько банок, не обязательно только одна. Все, кто «моложе или равны хотя бы одной другой», будут выбраны.
Можно использовать CASE для сложной логики
SELECT *
FROM fridge
WHERE
CASE
WHEN product = 'milk' THEN shelf = 'top'
ELSE shelf = 'middle'
END;
Если я ищу молочные продукты в холодильнике, то должна их искать на самой верхней полке, иначе - на средней.
Ну а если тебе нужны слова поддержки и мотивации, то заглядывай в канал Сила слов. Там каждое утро приходит мотивационное сообщение для тебя, чтобы ты верил себе и в себя, продолжал или только начинал действовать.
Многие думают, что SQL читается сверху вниз — как написано, так и выполняется. Но это не так.
SQL-запрос устроен хитро: порядок написания ≠ порядок выполнения.
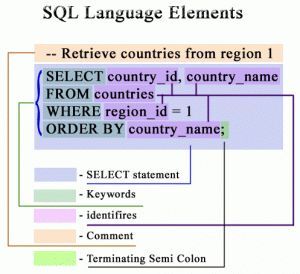
Классический скелет запроса выглядит так:
SELECT — какие поля выбрать
FROM — из какой таблицы
JOIN — если нужно соединение
WHERE — фильтрация строк до агрегации
GROUP BY — группировка
HAVING — фильтрация групп (после агрегации)
ORDER BY — сортировка
LIMIT — ограничение количества строк
SELECT — это конструктор. Ты как будто сначала берёшь детали, потом отбираешь нужные, потом собираешь по группам, и только потом смотришь итог.
Мы привыкли, что текст читается слева направо, сверху вниз. Но не везде так:
в арабском и иврите — читают справа налево,
в китайском — традиционно писали сверху вниз.
Это не ошибка, не странность, а особенность языка, которая исторически так сложилась.
SQL — тоже «язык», и у него есть свои правила: мы пишем запрос сверху вниз, начиная с SELECT
А выполняется сам запрос совсем в другом порядке.
Об этом уже есть пост в моем новом канале На связи: SQL. Это канал про нюансы SQL, практические задачки и многое другое, что связано с аналитикой. Его я создала недавно абсолютно с нуля. Так что, если интересно, то подписывайся. А вот и ссылка на пост про последовательность выполнения запросов.
Где ещё встречается разница между тем, как пишут и как «читают»:
Музыка 🎼
В нотах всё аккуратно записано: сверху вниз, слева направо. Но музыкант, читая ноты, должен сначала понять тональность, размер, темп, и только потом играть каждую ноту по порядку. То есть фактически исполняется не в том же порядке, как просто «прочитал глазами».
Рецепты в кулинарии 👩🍳
В рецепте шаги написаны линейно: 1, 2, 3. Но когда готовишь, иногда сначала ставишь воду кипятиться, пока режешь овощи. Т.е. порядок написанного ≠ фактический порядок действий.
Юридические документы 📑
Контракт читается сверху вниз, но при толковании юристы сначала смотрят на определения терминов, потом на условия, потом на исключения.
Программирование в целом 💻
В коде написано: «вызови функцию А, потом Б». Но компилятор или интерпретатор сначала обрабатывает импорт библиотек, парсит синтаксис, оптимизирует, и только потом «доходит» до исполнения.
В SQL — такая же история: пишем запрос сверху вниз, но база данных «читает» его по-своему. Про фактический порядок выполнения я написал подробно в своём канале На связи: SQL, так что если интересно — загляните 😉
Когда мы слышим слова таблица, то сразу идет ассоциация со строками и столбцами. Но в базе данных - это не просто строки и столбцы, это мини вселенная со своими правилами и требованиями.
В своем канале На связи: SQL я рассказываю об особенностях языка SQL. Разбираю аналитические запросы и подходы работы с данными. Канал создала недавно с нулем подписчиков, но там уже есть интересная информация для работы аналитиков. Подписывайся!
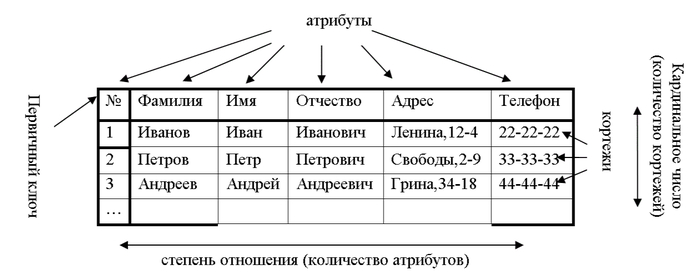
И для формирования таблиц в БД есть свои требования, нюансы и особенности.
Очень часто аналитики сталкиваются со следующими проблемами при работе с данными:
Иногда пытаются «запихнуть всё» в одну таблицу. Получается «широкая простыня» с сотнями колонок.
Такой подход приводит к тому, что становится неудобно работать, запросы тормозят, а половина столбцов вообще пустая.
В этом случае необходимо прибегать к нормализации данных — разносить данные по отдельным связанным таблицам.
Грубо говоря, нормализация - это способ организации данных. Что именно хранится, где именно хранится и как все, что хранится, связано между собой.
В таблице могут храниться одни и те же данные по 100 раз (например, имя клиента в каждом заказе).
Это приводит к сложности обновления — изменил телефон в одном месте, а в другом он остался старым; объем БД растет, что требует увеличения ресурсов для работы с данными.
В этом случае необходимо выносить повторяющиеся данные в отдельные таблицы и связывать ключами.
И это тоже про нормализацию данных.
Есть поле, но оно ничем не заполнено. И тогда аналитик задается вопросом: что это значит? Что данных просто нет (их никто не вносит), данные вносят, но они потерялись при загрузке в таблицу, либо эти данные необходимо воспринимать как равные нулю...
В этом случае необходимо сначала посмотреть требования к источнику данных, есть ли там обязательность их заполнения. Если данные обязательны к заполнению, то стоит рассмотреть ETL (Extract Transform Load - извлечение, преобразование и загрузка) процесс данных.
И от полученных результатов принимать решение как расценивать NULL данные.
Телефон хранят как INT, даты — как текст, деньги — как FLOAT.
Такой подход приводит к тому, что в телефоне «съедается» +7, даты не сортируются, а деньги теряют копейки.
И аналитик не может корректно обрабатывать данные, что приводит либо к ошибкам в результатах, либо к увеличению этапа обработки данных для выполнения какой-либо аналитики.
В этом случае: только правильное использование типов данных.
Нет ключей и индексов
Ключи нам нужны, чтобы однозначно идентифицировать данные и связывать таблицы между собой.
Есть первичный ключ (Primary Key) и внешний ключ (Foreign Key)
Первичный ключ - это уникальный идентификатор. Например есть два Ивановых Ивана Ивановича, но у них будут разные ID. Этот ID будет однозначно идентифицировать каждого из них.
Внешний ключ - это ссылка на другую таблицу. Например есть таблица заказов и в ней есть поле client_id. Это поле будет ссылаться на ID нашего Иванова Ивана Ивановича в таблице с персональными данными.
Индексы нам нужны для ускорения поиска.
Представь, у тебя есть огромная книга (миллионы строк в таблице). Если ты ищешь слово вручную — придётся листать страницу за страницей.
Но если есть алфавитный указатель (индекс) — ты сразу находишь нужное слово.
Примеры:
Поиск клиента по номеру телефона
Поиск заказов по дате
Поиск товаров по категории
Индексы ускоряют запросы в разы, но требуют памяти и времени на обновление (поэтому ими злоупотреблять тоже не стоит).
Если таблицу использовать как свалку — складывать туда и клиентов, и товары, и заказы — это как в одной кастрюле сварить борщ, компот и макароны.
Итог: никто не понимает, что с этим есть.
А в канале На связи: SQL уже первые посты про структуры запросов и JOIN ждут тебя.
Если тебе нужна поддержка и мотивация или просто сопутствующие слова для твоего развития, то приходи в канала Сила слов. Там каждое утро тебя ждет мотивационное и поддерживающее послание.
