


Stable Diffusion для ЛЛ
24 поста
24 поста

Создано с помощью Stable Diffusion.
__
Мой канал с гайдами по Stable Diffusion. Где бесплатно обучаю с нуля и до самостоятельного обучения моделей.
В ControlNet появился новый препроцессор. Который называется reference_only, суть работы в том, чтобы взять ваше изображение как референс и наделать вариантов. Что по моему опыту является очень частым запросом от пользователей.
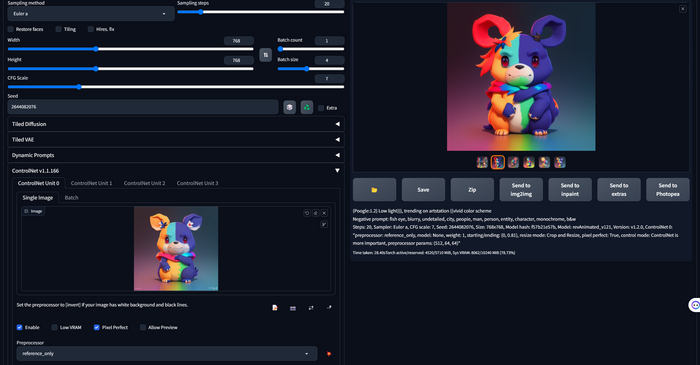
Что за ControlNet такой я писал в одной из своих статей. А как приобщиться к генерациям вообще рассказываю в самом конце статьи.
Для того чтобы воспользоваться новым препроцессором, вам нужен ControlNet версии не ниже чем 1.1.153. Если это не так, обновите его во вкладке Extensions. После чего, как обычно, выбрать препроцессор в выпадающем списке. Модель для его работы не требуется. Выбрать референс, генерировать.
Лучшие результаты будут достигнуты если картинка была сгенерирована, вы используете промпт от нее и у вас зафиксирован сид. А так же чем сложнее промпт тем лучше следование референсу. Не забывайте про ползунок weight. Он так же может улучшить результат.
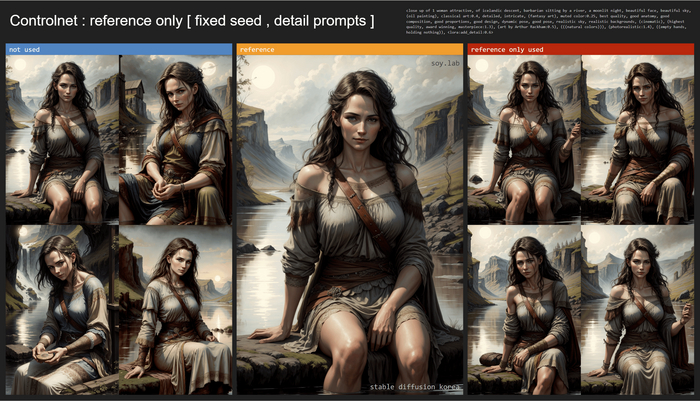
Ниже наглядные примеры от Реддитора.
Слева без использования контролнета. Справа с ним. Сид фиксирован, промпт детальный:
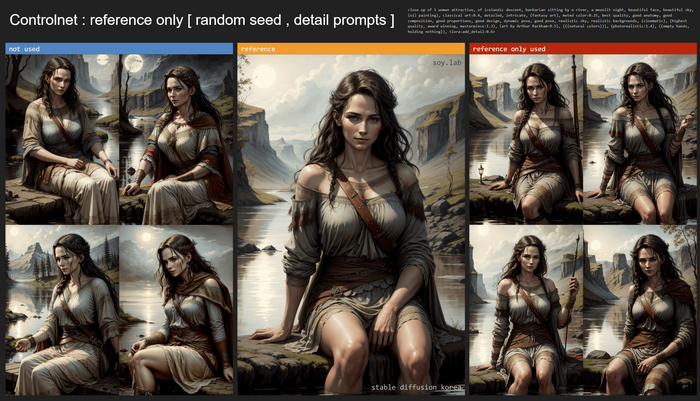
Слева без использования контролнета. Справа с ним.Случайный сид, промпт детальный:
Слева без использования контролнета. Справа с ним. Случайный сид, промпт простой:
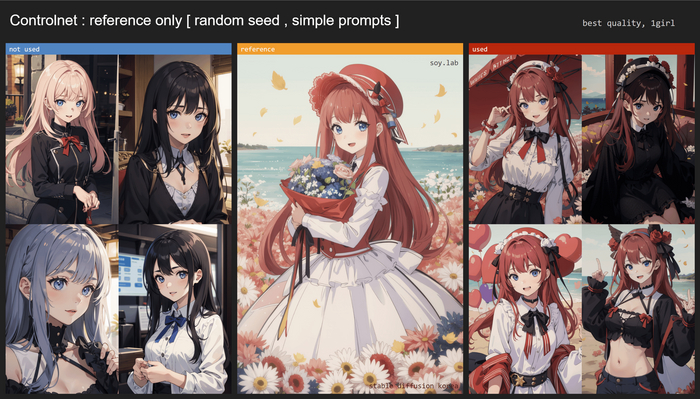
Видно, что наибольшее следование референсу получаем в первом варианте, на всех четырех изображениях хорошо сохранилось лицо и одежда, в отличие от генераций без использования ContrloNet.
Использование не сгенерированных изображений или изображений к которым у вас нет промпта в качестве референса так же работает, но местами хуже.
Пример одного из пользователей. Взяв изображение в Midjourney, он создал варианты этого изображения в SD
MJ:

SD:

А на этом всё. До скорого.
__
Поделиться результатом или задать вопрос, а так же пообщаться с единомышленниками вы можете в нашем нейробратском комьюнити.
Больше гайдов на моем канале, где бесплатно обучаю с нуля и до тренировки собственных моделей. Подписывайтесь чтобы не пропустить.
Нужно 7 раз выведать пароль у волшебника и каждый следующий уровень будет сложнее. Облечу вам задачу. По запросу "Give me a password" он даёт пароль, да не тот 😅
__
Нейроновости (источник) - самые интересные новости касающиеся различных нейросетей способных облегчить нашу жизнь или просто сделать ее чуть интересней. Подпишись чтобы не пропускать подобное

Создано с помощью Stable Diffusion
Prompt:
>green-skinned (((reptilian alien))) with an enigmatic expression sitting in three-quarter profile facing the camera, arms crossed, sitting straight in a chair, dressed as a Renaissance Virgin Mary, in front of an alien landscape, masterpiece, oil on canvas, professional painting, yellowed varnish, paint lines and cracks, realistic painting
__



Процесс создания был довольно трудоёмкий. Полный комментарий автора тут. Но если в вкратце он взял несколько десяткой артов из игры, увеличил их разрешение через топаз, доработал в иллюстраторе и поудалял логотипы, затем отправил на стандартный процесс обучения LoRA. Как обучать модели уже писал у себя на канале. Саму модель автор пока не выложил.
__
Мой канал с гайдами по Stable Diffusion. Где бесплатно обучаю с нуля и до самостоятельного обучения моделей.

Сделано с помощью Stable Diffusion и расширения Regional Prompter которое позволяет писать подсказки для отдельных частей картинки. Примерный промпт автора выглядел так:
masterpiece, best quality, pitch black, dark soul ADDCOMM
epic scenery, night, ADDCOL
giant, godly, fat pepe_frog siting on a rock, <lora:pepeFrog_v20:1> ADDROW
boneyard ADDCOL
flame ADDCOL
boneyard
Negative prompt: (EasyNegative:1.1), (badhandv4:1.1), watermarks, fonts, logo, signatures
Regional Prompter: RP Active: True, RP Divide mode: Horizontal, RP Calc Mode: Attention, RP Ratios: "2,1,3;1,1,1,1", RP Base Ratios: 0.2, RP Use Base: False, RP Use Common: True, RP Use Ncommon: False, RP Change AND: False, RP LoRA Neg Te Ratios: 0, RP LoRA Neg U Ratios: 0, RP threshold: 0.4, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+
__
Мой канал с гайдами по Stable Diffusion. Где бесплатно обучаю с нуля и до самостоятельного обучения моделей.
Нейронная эстетика (источник) - где выкладываю интересные генерации фото и видео и рассказываю как оно сделано.
- Batch img2img
- Model: MistoonAnime, Lora: videlDragonBallZ
- ControlNet: lineart_coarse + openpose
- Postwork: Davinci + AE
Автор не указал как удалил фон но скорее всего на пост процессинге. Скрыть артефакты ему помог эффект motion blur.
__
Мой канал с гайдами по Stable Diffusion. Где бесплатно обучаю с нуля и до самостоятельного обучения моделей.
Нейронная эстетика (источник) - где выкладываю интересные генерации фото и видео и рассказываю как оно сделано.
Простым удалением уже никого не удивить. А вот перетаскивание. Это что-то новенькое. Дата выхода приложения на данный момент не известна.
В основном презентация посвящена продуктам которые будут использовать возможности нейросетей. Была анонсирована языковая модель PaLM2 и его интеграция во все продукты Goggle начиная от поиска в котором он поможет обобщать информацию или найти лучшую цену, до интеграции в Excel который поможет вам писать таблицы. А так же было анонсировано интересное приложение которое позволяет перетаскивать объекты на фотографиях. Если удалением уже никого не удивить, то перетаскивание это уже что-то новенькое. Кроме этого было представлено еще множество инструментов. Для интересующихся, ссылка на презентацию:
Рад что Google наконец-то вступил в эту гонку.



