В прошлой части мы ознакомились с базовыми понятиями деревьев и обошли одно дерево рекурсией. В данной статье мы еще раз рассмотрим понятие рекурсии и посмотрим как небольшие во время итерации могут повлиять на результат. В данной части мы сфокусируемся на итерации, а в следующе мы уже будем использовать эти подходы для решения задач.
Обход деревьев часто ощущается как лабиринт
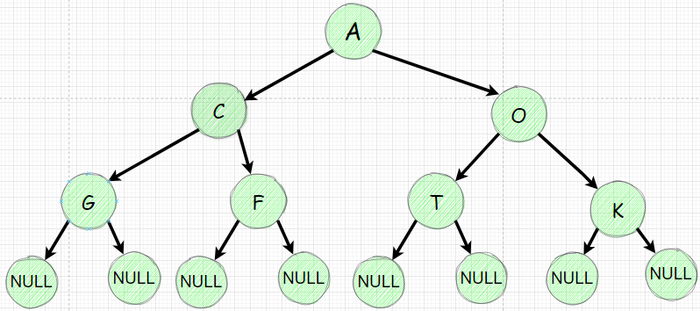
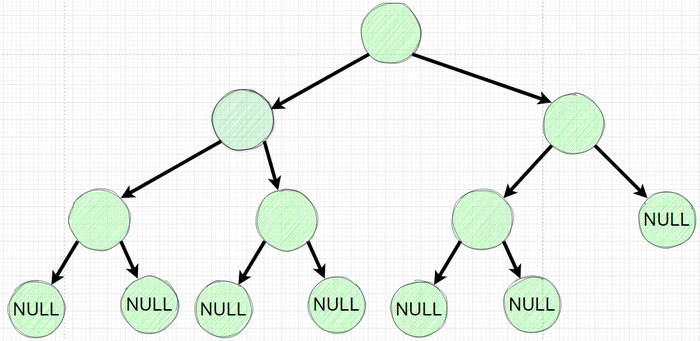
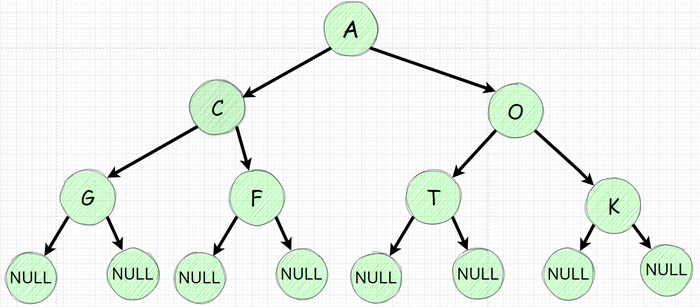
Давайте рассмотрим уже знакомое дерево:
Прямой обход дерева (Префиксный) - NLR
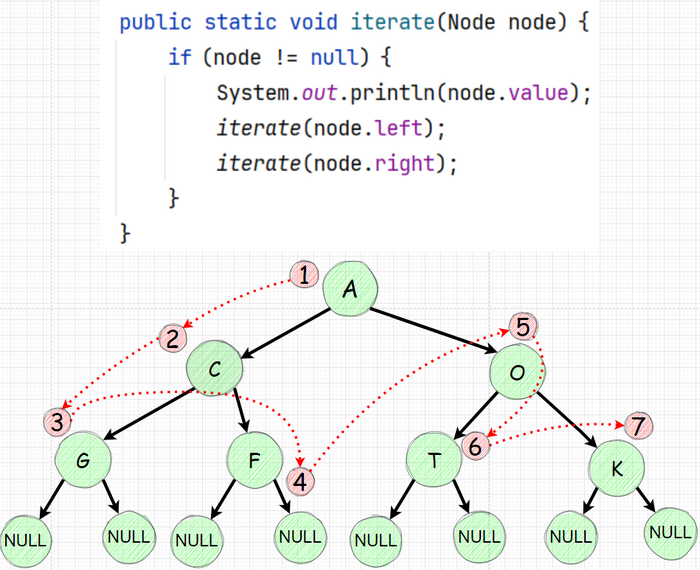
В прошло части мы уже итерировались по дереву рекурсивно. В нем мы сначала печатали значение узла (Node) затем посещаем левое поддерево (Left) и лишь потом правое поддерево (Right). Такой подход называется прямым или еще префиксным - NLR.
Распечатка значения и последующее движение влево вниз и уже затем вправо.
Центрированный обход дерева (Инфиксный) LNR
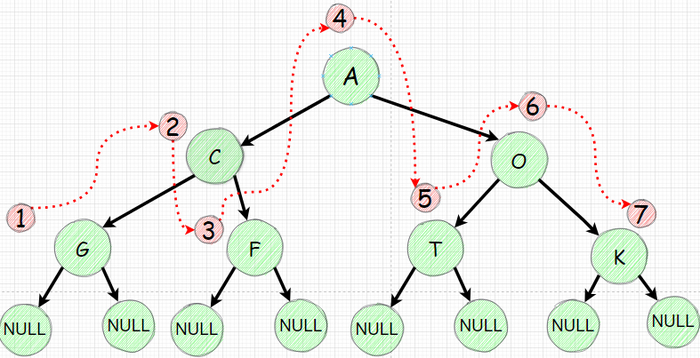
Теперь сделаем одно минимальное изменение - сначала мы пойдем в левое поддерево (Left) затем распечатаем значение узла (Node) и потом пойдем в правое поддерево (Right) - этот обход называют Инфиксным (от лат. in внутри fixus закрепленный) или центрированным - LNR. Понятие инфиксный прошло из математики. Если очень упрощать значит что N находится между L и R.
разница лишь в 1 линии но процес "обхода" меняется.
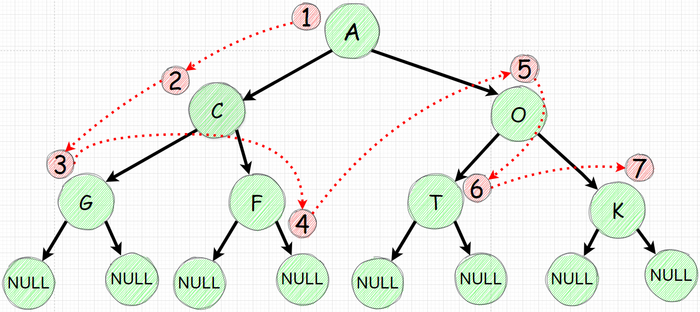
И так вроде рекурсия выполнила ровно такой же обход, но теперь процесс распечатки значения узла мы стали делать после того как уходим "влево". Теперь если задуматься то первая печать произойдет лишь когда мы дойдем до нижнего левого узла. Давайте изобразим как будет выглядеть "обход" а порядок печати значений узлов:
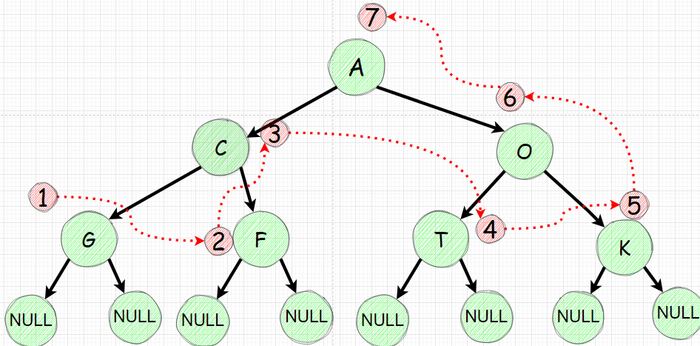
Обратный или Постфиксный обход. LRN
Думаю уже понятно что данный подход подразумевает печать значения узла (Node) после посещения левого (Left) поддерева и правого (Right) поддерева - LRN
Печатаем лишь после обхода левого и затем правого поддеревьев.
Порядок распечатки изображен ниже:
Минимальные изменения - большие последствия.
Изза минимальных изменений (меняя лишь порядок одной строчки) мы получили разные обходы дерева. Это позволит нам решать разные задачи в будущем.
Следующий этап.
В следующей статье мы рассмотрим какие задачи мы можем решать используя описанные подходы. Одна из главных целей цикла статей - помочь преодолеть страх задач про деревья во время собеседований. Думаю стоит повторить еще раз - как только вам прилетела задача на деревья во время собеса начинайте с того что напишите функцию обхода. Большинство алгоритмических задач решается именно через рекурсию (но не только через неё).
Деревья являются одним из самых пугающих вещей в разработке. Еще хуже дело обстоит, когда программист встречает задачу, связанную с деревьями, во время собеседования. В этой статье я постараюсь минимизировать боль, связанную с этой темой.
Деревья бывают разные. Мы рассмотрим двоичное сбалансированное.
В данной статье мы рассмотрим наиболее популярные — двоичные сбалансированные (красно-черные) деревья.
Пример бинарного дерева. У каждого листка может быть не более двух наследников.
Основные понятия.
Рассматривая бинарные деревья нужно знать следующие понятия:
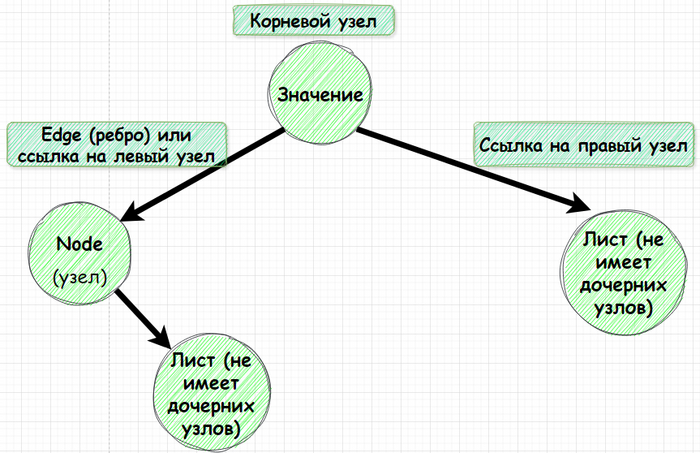
Node - он же узел. Это элемент дерева, содержащий какое-то значение, которое может быть любым, от примитива (например, числа) до объекта (например, пользователя).
Edge или ребро. Ссылка, соединяющая один узел с другим или указывающая на пустое значение (null).
Root Node. Верхний узел дерева, от которого начинается вся структура.
Leaf - Узел, не имеющий наследников, то есть находящийся в самом низу иерархии.
Высота дерева - Количество "уровней", от корня до самого нижнего узла.
Несбалансированные деревья могут выродиться в связный список.
Несбалансированные деревья — это деревья, у которых высота левой и правой веток может значительно отличаться. В худшем случае все узлы могут располагаться по одной стороне. В этом случае дерево деградирует до связного списка.
деградированное дерево вырожденное в связанный список.
Сбалансированные деревья.
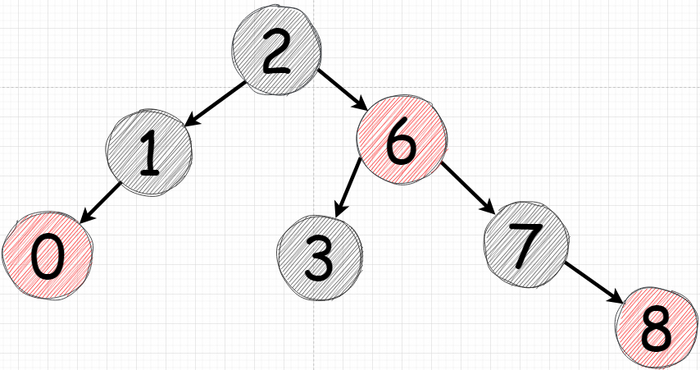
Сбалансированные (например красно-черные) при каждом добавлении нового узла проверяют, является ли дерево "несбалансированным". Если условие истино то дерево делает "разворот" свои узлов.
Пример красно черного сбалансированного дерева. Именно такое используется в TreeMap
Сбалансированные деревья никогда не вырождаются в связанные списки. В J ava джаве деревья представлены коллекцие TreeMap и TreeSet (который инкапсулирует TreeMap внутри себя).
Как могут быть представлены деревья на уровне кода.
Если мы не используем готовые решения вроде TreeMap то простейшее дерево может быть представлено в виде следующего класса:
Простейший узел. По большому счету это единственный важный момент.
Итого что мы имеем:
String data это то значение которое хранит узел. Это может быть любым объектом - в нашем случае просто строка.
Node left - ссылка на левого наследника.
Node right - ссылка на правого.
Используя Node класс создадим дерево
Поочередно инициализируем наше дерево с 7 узлами
Изобразим полученное дерево:
Итерация по дереву - один из самых важных навыков для решения задач.
Большинство (если не все) задач, связанных с деревьями требуют итерации или обхода узлов. Чаще всего, умея обходить дерево, вы решаете львиную часть проблемы. В данной статье мы рассмотрим лишь 1 вариант итерации, я напишу отдельные статьи чтобы рассмотреть другие подходы.
Используем рекурсию для итерации и распечатки всех элементов.
Каждый раз когда вам прилетела задача по деревьям, помните - скорее всего в основании решения будет рекурсия (это не всегда так, но довольно часто). Те у вас будет функция которая будет вызывать сама себя. Для распечатки дерева напишем рекурсию которая обходит все элементы начиная с левого наследника:
Код вроде простой но не стоит его недооценивать. Давайте проговорим этапы:
Распечатываем значение узла
Идем к левому наследнику и повторяем действие (те опять распечатываем и идем влево)
после того мы обошли все левые и уткнулись в null мы "возвращаемся" на уровень который находится наверху от нижнего левого и идем в правый наследник
зайдя в правый распечатывем и идем влево повторяя шаги 2-3.
Все это звучит странно проще будет изобразить:
Это лишь первая статья но в ней мы ознакомились с основными понятиями. Также мы обошли дерево, используя рекурсию. Это один из самых популярных подходов в решениии подобных задач. В следующей части мы рассмотрим альтернативные варианты работы с деревьями.
Собственно, название поста отображает его основную мысль) Есть желание сменить работу на Java-программиста, однако начитавшись постов и проанализировав HH возникают огромные сомнения по поводу нужности очередного стажера/джуна на рынке.
Коротко о бэкграунде: бакалавриат и магистратура по специальности "Автоматизированные системы управления тех.процессом", 5 лет опыта работы инженером-программистом АСУ ТП. Обязанности - разработка ПО для ПЛК(паскалеподобные SCL и ST) и SCADA(VBS, SQL и чуть-чуть C#), настройка ПК, ПНР.
Что делаю: купил курс на Я.Практикуме(да-да, очередной недопрограммист после курсов), когда понял, что у меня остается куча времени, т.к. курс разбит на 2-недельные спринты, а задания я прохожу от силы неделю, докупил еще JavaRush. Параллельно начал изучать Шилдта. В мыслях накидать свой петпроект для реальной задачи на работе - построение относительно простой системы отчетов. Само собой, после изучения Java Core - изучение Git, Maven, Spring и прокачка SQL.
Непосредственно вопрос: насколько реально найти с подобным "послужным" списком работу на должность Java Junior за 3-4 месяца? Город миллионник(не Москва и не Питер), на зп в целом пофиг, понимаю, что первые полгода-год - работа за еду)
Дополнительный вопрос: куда копать, куда не копать, на что следует обращать внимание?
Реактивщина стала поддерживаться Спрингом с 2017 года. Но через 6 лет многие так и не осознали, где её применять и зачем она нужна. А ведь для Спринга это стало целой новой эпохой.
Реактивнища это не изобретение Спринга.
Первое что нужно знать — реактивщина и реактивный подход не являются изобретением Спринга. Наоборот спринг как обычно поглотил очередную технологию, в данном случае Project Reactor
Реактивный дух времени.
Понятие реактивного подхода размыто но в общем подразумевает что приложение будет скорее событийно ориентировано. Давайте рассмотрим простой пример ниже, в котором сравним старый синхроный подход и рективный.
Синхронный блокирующий подход:
Предположим что на мнужно выполнить 3 задачи. В старом синхронном подходе мы получим код который будет запущенным одним потоком поочередно и блокирующе.
синхронный подход
Реактивный подход
Теперь перепишем ту же задачу используя реактивщину, встроенную в JDK еще с Java 9:
Создаем паблишер и отправляем ему 3 задачи.
Различия. Небольшая большая разница.
Как можно было понять что сам подход к написанию кода от «естественного» процедурного, где каждый этап движется сверху вниз теряется в реактивщине (хотя и в функциональности он тоже теряется). Реактивный код выглядит скорее как декларативный набор реакций на события и поэтому менее прозрачен и читаем. К сожалению, такой стиль написания кода усложняет процессы разработки, тестирования и поддержки кода.
Но почему реактивщина стала с каждым днем становится все более популярней?
Причин довольно много, но я упомяну лишь два наиболее важных (по моему мнению):
Эффективное использование ресурсов (это утверждение истинно только если вы используете неблокирующий код).
Отзывчивость системы (Responsive)
Реактивный + неблокирующий подходы = нефть, золото, греча и, конечно же, акции эппл.
Отгадайте, кто сожрет все потоковые ресурсы?
Если проанализировать среднестатистический цикл жизни потока то можно заметить что большую часть времени (иногда по 99% времени)
находится либо:
В состоянии ожидании доступа к локу те в состоянии ожидании монитора BLOCKED или WAITING
В "логическом ожидании" какого то ресурса как то ответа базы, сервиса или просто базы.
И это очень очень плохо. В текущих реалиях даже среднестатистический процессор обладает огромными мощностями. Большинство операций занимают нано и микросекунд, но ожидания и блокировки руинят всю производительность.
Решением является совместное использования реактивщины и неблокировщины. Первая организует процесс в котором пул потоков ожидает задачи под выполнение а неблокирующий подход не заставляет ждать потока в рамках одной из задач.
Отзывчивость системы. (Responsiveness)
Один из весомых плюсов реактивщины - возможность получения данных по мере их появления. А как следствие любые решения поверх реактивщины отзывчивы для пользователя и не висят тысячами лет пока все данные не подгрузятся.
Давайте уже, что нибудь попишем.
Как я уже упомянул есть несколько реактивных решений, но в рамках статьи мы напишем Спринговые классические решения.
Перед тем как начать. Если выше на путь реактивнищы - пути обратно нет. Все слои внутри приложений надо стараться писать именно в этом стиле. И конечно не забывать про неблокируйщий подход. Если следовать блокирующему то потоки будут стопорится именно у такой блокируюей воронки.
Что это значит на практике?
А на практике это значит что старые библиотеки вроде rest template (общение по http), jdbc template (связь с базой) должны быть выпилены и заменены не реактивные и неблокирующие:
Пример ниже не является самым сложным, но скорее показательным. Напишем простую локику:
К нам приходит http запрос
Мы перенаправляем запрос в базу
Как база дает первый ответ мы кидаем данные на фронт
Данные на фронте парсятся по мере появления (а не лишь когда все будут доступны)
Если говорить упрощенно то весь код по сути будет сводится к тому что мы будем прокладывать трубы в виде Flux или Mono объектов.
Стоит помнить что вся реактивная магия Спринга возможно лишь когда при его старте используется WebFlux'овый фреймворк. Старый вариант запуска Спринга с каким нибудь томкатом под капотом не сработает. Поэтому зависимости ниже обязательны:
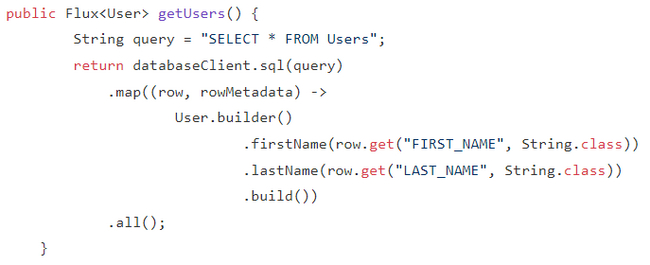
Начнем с базы, используем
Пробросим Flux используя DatabaseClient:
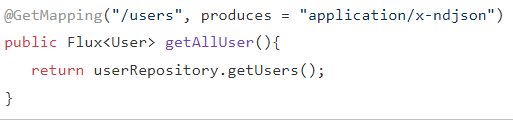
Теперь полученный Flux выставим на сторону фронта:
Наверно вы заметили что возвращаемый тип не application/json. Да тип x-ndjson. Если использовать стандартный application/json то данные которые будут улетать на фронт будут неполный и конвертировать их в целые объекты будет головной болью. Это недостаток потокового подхода (хотя по сути это 1 http запрос, просто растянутый). x-ndjson формат позволяет кидать на фронт кидать объекты
Читаем на фронте. Код неидеален, скорее служит в качестве простого примера.
Код выше делает следующее:
Делает http запрос
Ожидает ответа
Как только ответ прилетает начинает читать его по частям и писать в конcоль
Приведенный пример является довольно простым, возможности WebFlux гораздо богаче и позволяют манипулировать данными в асинхронном, реактивном подходе. Но код становится сложнее для написания, чтения и поддержки.
Еще раз про эффективный расход процессорных ресурсов.
Я еще раз хочу упомянуть что реактивные, неблокирующие решение написанные прямыми руками позволяют выжать максимум из предоставленных ресурсов. Особенно это актуально во времена микросервисов. Все чаще на проектах под небольшой микросервис могут выделить не более чем 1/0.5/0.1 CPU и я в общем поддерживаю такой подход.
Виртуальные потоки VS Реактивщина.
Эта тема заслуживает отдельного поста. И он будет следующим если эта статья зайдет. Дайте знать в комментах если интересно.
В данной статье мы разберем, что такое GraphQL, и построим приложение с использованием Java и Spring.
Атмосферный логотип GraphQL
GraphQL стал опенсорсным в 2015 году, однако за десять лет так и не достиг такой же популярности, как REST-архитектура (на графике ниже видно, что нет явной тенденции к большему росту). Нельзя прямо сравнивать GraphQL с REST, поскольку первый представляет собой язык запросов, а второй – архитектурный стиль. Тем не менее, оба имеют реализации в промышленной разработке.
GraphQL все еще остается аутсайдером.
GraphQL в двух словах это гибкий контракт.
GraphQL создает канал коммуникации, где клиент может указывать серверу, какие именно данные ему нужны. Благодаря такому подходу, имея всего лишь один гибкий канал, можно снизить нагрузку на потребление трафика и упростить процесс разработки.
Spring и GraphQL
Довольно ожидаемо что Spring поглотил стандарное решение GraphQL и, конечно же, добавил несколько новых аннотаций. Spring хлебом не корми - дай новых аннотаций наклепать. Давайте напишем своё первое - апи сотрудники.
Для работы со спрингом нужно добавить зависимости.
Для интеграции добавьте в зависимости org.springframework.boot:spring-boot-starter-graphql а также установите переменную в application.properties: spring.graphql.graphiql.enabled: true
Все начинается с GraphQL схемы.
При проектировке контракта, используемого внутри канала, нам необходимо предварительно задекларировать структуру данных. Наша схема будет выглядеть вот так:
Пример так себе, но для нашего примера сгодится.
Суть апи которое мы сделаем - предоставлять сотрудников. У каждого сотрудника есть ссылка на департамент, который в свою очередь имеет ссылку на локацию и руководителей этого отдела. Основной посыл такой - скорее всего многим потребителям нашего апи понадобятся данные о сотрудниках и их отделах. Но также некоторым из них все же могут пригодится все данные.
Составляем схему.
Делаем схему, которая будет соответствовать нашим классам. Слева я расположил знакомые нам Java классы, а справа схему которая будет сохранена в schema.graphqls файле и затем использована для построения соединения.
Язык graphql (справа) довольно интуитивен
Из структуры довольно понятно, что типы имеют либо примитивный тип - (строка, число) либо ссылки на другие объекты. Также в квадратных скобках отмечаются массивы данных.
Последний шаг - декларация запроса. В нашем случае allEmployees.
Создадим метод который будет возвращать данные - он должен быть помечен аннотацией @QueryMapping. Также зарегистрируем его в schema файле:
Возвращаемый тип и название метода должны совпадать.
На этом все. Мы закончили разработку. Пишем первые запросы.
Довольно просто получилось интегрировать GraphQL, осталось научиться им пользоваться. Для этого мы воспользуемся встроенной веб интерфейсом который поставляется из коробки. После старта приложения откройте: http://localhost:8080/graphiql?path=/graphql
Вот какую красоту мы увидим.
Что это такое? Более детально:
Слева у нас есть конструктор который помогает кликами создавать запрос
По центру мы готовим сам контракт для запроса - его можно править в ручную
Справа результат работы апи для выбранного контракта
В примере выше мы выбрали лишь два поля которые нужно вернуть для каждого сотрудника - имя и айдишник. Давайте добавим туда и департамент с локациями:
Лишь измения в контракте дали нам новый результат. На бэкэнде мы не сделали изменений.
Как можно заметить, добавив необходимые поля, мы изменили контракт. Теперь данные о сотрудниках, департаментах и их локациях возвращаются с бэкенда.
Это не все возможности GraphQL.
Данная статья не включает все возможности GraphQL такие как:
Мутации - возможность делать гибкие запросы на изменение данных
Подписка - возможность подписываться на изменения
Более гибкие возможности работы с GraphQL - например возможность читать данные из контекста GraphQL
Генерация документации
DataLoaders - возможность борьбы с N+1 проблемой при работе с базой данных
Моё скромное мнение.
По моему технология недооценена на рынке и достойна куда большего внимания. Текущая имплементация далека от идеала но и относительно проста. Проблема снижения нагрузки и создания универсального апи которое можно динамически менять без изменений со стороны сервера - встречается часто, особенно в больших компаниях (а чаще в больших компания java и используется). Поэтому я всем советую поиграться с технологией и применять в нужных случаях.
Среди множества способов и решений для анализа виртуальной машины Java есть одно хорошее решение — Flight Recorder. Благодаря этой утилите работающая Java-машина может записывать все происходящее внутри.
Достоинства Flight Recorder
Если сравнивать Flight Recorder с другими похожими решениями то можно отметить
Минимальную нагрузку на само приложение (пишут, что она составляет около 1% производительности).
Наличие большого количества метрик и возможность интегрировать свои кастомные метрики.
Простоту интеграции и поддержки.
Отсутствие необходимости перезагрузки приложения. Утилита работает с "горячей виртуальной машиной"
Возможность запускать аналитику на фиксированное количество секунд/минут.
Запуск Flight Recorder.
Предположим, вы уже создали свое приложение и готовы запустить его с помощью JAR. Если вы хотите при старте приложения запустить процесс записи Flight Recorder, то достаточно выполнить следующую команду
В данном случае, в течение 10 секунд после старта Flight Recorder будет записывать все происходящее в виртуальной машине.
Используем JCMD для динамического подключения записи.
Как альтернативу можно использовать утилиту входящую в jdk - JCMD которая позволит подключиться уже к рабочей JVM.
Чтобы узнать, какие виртуальные машины работают в данный момент, достаточно просто написать JCMD и получить что-то вроде:
Слева находятся номера процессов которые можно использовать для подключения.
Как только мы определили, к какому процессу (42800) нужно подключиться, вводим команду для записи отчета на 30 секунд. Файл с записанной аналитикой будет назван myreport.fjr. Итоговая команда будет следующей:
JCMD 42800 JFR.start durati filename=myreport.jfr
Анализируем отчет
Самый просто способ прочитать myreport.jfr - установить программу JMC (Java Mission Control). Скачать её можно вот тут.
После запуска программы можно выбрать существущий myreport.jfr либо подключиться к рабочей виртуальной машине и создать его внутри программы.
Анализируем File I/O - работу с файловой системой.
На вкладке "OUTLINE" необходимо выбрать "File I/O", и тогда можно получить аналитику работы программы с файловой системой. Я намеренно написал код, который создавал файлы размером 20 МБ. Вот что получилось в итоге:
Выглядит довольно точно. Где то 6 файлов было записано каждый по 20 мб.
Socket IO - работа с сетью.
Чтобы просмотреть работу и трафик, необходимо выбрать "Socket I/O". В моем случае, взаимодействия с сетью было крайне мало. Вот результат:
Картина совпала - по сети передавались лишь байты данных. Это примерно ничего.
Аналитика памяти - Ключевая вещь для анализа работы виртуальной машины.
Чтобы оценить затраты памяти, необходимо выбрать "Memory" внутри вкладки "Outline":
Как можно заметить, в памяти было выделено до 80мб, но затем собрано сборщиком мусора. Судя по всему, утечек нет. Но для хорошей аналитики утечек минуты работы профайлера недостаточно.
Аналитика Сборщикам Мусора.
Тут несколько вариантов. Есть Grabage Collectons, GC Configuration, GC Summary. Давайте рассмотрим первый и последний:
Итак, на вкладке видна детализированная аналитика времени работы сборщика мусора. Также можно просмотреть общую статистику:
Суммарное время сборщика сборщика мусора составило 56 мс, и при этом было сделано 13 остановок.
Аналитика потоков. Thread Dumps
Также важной частью отчета является информация о состоянии потоков. Благодаря этим данным можно выявить взаимные блокировки и подобные проблемы. Вкладка "Thread Dumps":
Анализ событий.
Flight Recorder также позволяет записывать происходящие события внутри JVM (и даже создавать свои!). Затем все эти процессы можно удобно просмотреть в Event Browser:
В качестве заключения.
Flight Recorder очень удобная в использовании утилита для аналитики виртуальной машины, которая делает внутренние процессы даже сложных Java программ значительно более читаемыми. Меня лично радует сам факт разивития подобных утилит. Кому интересна Java а также мир разработки приглашаю в мой телеграм канал.
Спасибо за внимание, надеюсь вы узнали что то новое.
❓Вы когда-нибудь ощущали разочарование, работая с чужим кодом? Сегодня трудности сопровождения исходного кода представляют важную проблему разработки программного обеспечения, приводящую к дорогостоящим срывам сроков и ошибкам. Подключайтесь к ее решению. Данное практическое руководство познакомит вас с 10 простыми рекомендациями, помогающими писать программное обеспечение, которое легко поддерживать и адаптировать. Эти тезисы сформулированы на основании анализа сотен реальных систем.
Написанная консультантами компании Software Improvement Group (SIG), книга содержит ясные и краткие советы по применению рекомендаций на практике. Примеры для этого издания написаны на языке Java, но существует аналогичная книга с примерами на языке C#.
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Java - это язык строгой типизации. Но это далеко не всегда дает гарантию безопасности во время выполнения программы (т.е. в Runtime).
В отличие от интерпретируемых языков, строгая типизация в Java позволяет избегать миллиарда ошибок, проверяя типы на момент компиляции. Вы не можете назначить строку целому числу (про приведение типов речи не идет). В статье мы рассмотрим наиболее частые ошибки, которые компилятор не может отловить.
1. Null Pointer Exception - топ-1 проблема в Java.
К сожалению, в Java до сих пор нет null-safe типов. А это значит, что любой объект потенциально может быть не инициализирован и указывать на null. Рассмотрим очевидный случай:"
К сожалению компилятор такое допускает
Решением данной проблемы будет введение null-safe типов, которые будут позволять объекту быть null только если это явно указано.
2.Удаление из коллекции во время итерирования.
Классическая ошибка при работе с коллекциями - удаление записей из коллекции без использования итератора. Рассмотрим пример ниже:
Итерируемся и удаляем одновременно.
При попытке запуска такого кода в рантайме мы получим:
Итератор жалуется что кто то модифицировал коллекцию пока он по ней ходил.
Если присмотреться поглубже, можно разглядеть, что внутри итератора это вызывает ошибку при попытке обратиться к следующему элементу:
3. Немодифицируемые коллекции в Java реализуют интерфейсы, предназначенные для модифицируемых коллекций. Аналогичная ситуация существует и для коллекций фиксированного размера.
На мой взгляд, это представляет собой определенный недостаток в дизайне Java. В языке присутствует понятный интерфейс Collection, который устанавливает требования для всех коллекций, включая возможность удаления, добавления и других модификаций данных. Однако существуют реализации, такие как:
Все эти реализации реализованы через интерфейсы, предполагающие наличие функциональности для модификации данных, но на практике они этого не делают. Об этом становится известно только во время выполнения программы. По вопросу модификаций коллекций, Дуг Ли (Doug Lea) высказывал следующее(см. первый параграф).
Кратко говоря, он не стал разделять существующие коллекции на обычные и немодифицируемые, так как это привело бы к увеличению числа интерфейсов и итераторов: "Now we're up to twenty or so interfaces and five iterators." Создание минимум 20 новых интерфейсов и 5 новых итераторов. Более того это все равно не помогло избежать всех потенциальных Runtime исключений.
Я не могу судить человека, кто написал java.util.concurrent. Но я знаю, что в том же Kotlin'e были созданных Mutable/Immutable коллекции, которые позволяют избежать подобных проблем. Мне не важно, добавит ли Java 25 или 2500 новых классов и надеюсь, что в будущем будут добавлены интерфейсы и реализации, предназначенные исключительно для немодифицируемых коллекций без методов типа get/remove/add и так далее. Все текущие недоразумения могут быть отмечены как устаревшие (deprecated).
4. Перезапуск ранее запущенного потока.
В случае работы с многопоточностью можно допустить ряд ошибок, которые не будут отловлены на моменте компиляции. Например, попытка "переиспользовать" один и тот же поток, запустив его дважды:
Запущенный ранее поток запустить еще раз не выйдет.
5.Некорректная работа с монитором.
Также при работе с монитором нужно соблюдать ряд правил. Я не буду вдаваться в подробности, просто приведу пример неправильной попытки работы с локом:
6.Бесконечная рекурсия.
Компилятор не может отличить рекурсию, которая будет работать с условием прерывания, или без. Поэтому бесконечная рекурсия вполне может быть скомпилирована:
Большинство всех показанных выше проблем отлавливаются утилитами которые анализируют код на ошибки вроде SonarQube или ему подобных, об этом я писал в этой статье.