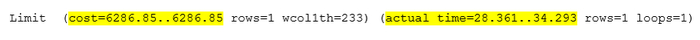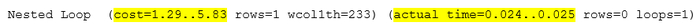Надо жизнь сначала переделывать. Переделав - можно начинать.
Наиболее эффективные подходы заключаются в замене IN на более оптимальные конструкции и использовании специальных техник работы с данными.
ANY(ARRAY[]) вместо IN
Замена IN (...) на = ANY(ARRAY[...]).
Оператор ANY может остановить проверку при первом совпадении.
Когда метод эффективен
Когда список значений очень большой.
JOIN с виртуальной таблицей
Преобразование списка значений в виртуальную таблицу с помощью VALUES и соединение с основной таблицей.
Когда метод эффективен
Когда список значений можно представить как набор строк.
EXISTS вместо IN для подзапросов
Проверка существования записи с помощью EXISTS.
Запрос прекращает работу, как только найдет первое совпадение.
Когда метод эффективен
Особенно эффективен для коррелированных подзапросов и сценариев с NOT IN (лучше использовать NOT EXISTS)
Материализованные представления
Предварительный расчет и сохранение результатов "тяжелого" запроса, например, с DISTINCT.
Когда метод эффективен
Когда данные изменяются редко, а актуальность в реальном времени не критична.
Нормализация схемы данных
Вынесение часто запрашиваемых полей (например, make, vehicle_year) в отдельные справочные таблицы.
Когда метод эффективен
Когда одни и те же значения (DISTINCT ...) выбираются из таблицы миллионы раз .
💡 Рекомендации по применению методов
Помимо замены оператора, важно рассмотреть более фундаментальные оптимизации.
Правильные индексы: Необходимо убедится, что на столбцах, которые участвуют в условиях IN, ANY или JOIN, созданы индексы (чаще всего BTREE). Без индекса даже переписанный запрос будет выполняться медленно .
Анализ плана запроса.
Нормализация данных: Если часто делается запросы вида SELECT DISTINCT column_name к очень большой таблице, это может указывать на недостатки в структуре базы данных. Вынесение возможных значений атрибута (например, марок автомобилей) в отдельную справочную таблицу — кардинальное, но очень эффективное решение .
⚠️ Чего следует избегать
NOT IN с подзапросами: Для сценариев исключения (NOT IN) PostgreSQL может строить неоптимальные планы с подзапросами (SubPlan). Вместо NOT IN практически всегда лучше использовать NOT EXISTS или LEFT JOIN ... WHERE ... IS NULL, которые приводят к более эффективному плану с Hash Anti Join .
DISTINCT без необходимости: Если нужно получить только уникальные значения, а не все строки, использование DISTINCT может создать дополнительную нагрузку. Иногда эту задачу можно решить на уровне приложения или с помощью других методов SQL .
Оптимизация запросов с LIMIT 1 в PostgreSQL фокусируется на том, чтобы СУБД нашла нужную строку максимально быстро, не перебирая все данные.
Ключевые моменты:
правильные индексы
анализ плана выполнения
избегание лишних операций.
Создание подходящих индексов
Создать индекс по колонкам из WHERE и ORDER BY. Позволяет найти строку за несколько шагов.
Эффект
Кардинальное ускорение (в тысячи раз), устранение полного сканирования таблицы.
Анализ плана выполнения
Использовать EXPLAIN (ANALYZE, BUFFERS) для просмотра плана запроса. Показывает, используется ли индекс.
Эффект
Точно определяет "узкое место" в запросе, позволяет оценить стоимость операций.
Использование ORDER BY с индексом
Всегда использовать ORDER BY с LIMIT для предсказуемого результата. Упорядочивание должно совпадать с индексом.
Эффект
Гарантирует корректность результата и позволяет использовать индекс для сортировки.
Устранение лишних операций
Убрать ненужные DISTINCT, сложные вычисления в WHERE, избыточные JOIN. Снижает объем работы до применения LIMIT.
Эффект
Сокращает общее время выполнения, особенно если лишняя операция требовала сортировки.
Увеличение work_mem
Увеличить параметр work_mem, если в плане есть Sort с дисковыми операциями (Disk: writes temp).
Эффект
Ускоряет операции сортировки и хеширования, выполняемые в памяти.
💡 Рекомендации по созданию индексов
Для LIMIT 1 особенно важны индексы, которые позволяют сразу найти единственную запись.
Типичные сценарии:
Простой поиск: Для запроса SELECT * FROM users WHERE email = 'test@example.com' LIMIT 1; индекс по колонке email: CREATE INDEX CONCURRENTLY idx_users_email ON users(email);.
Поиск с сортировкой: Для запроса SELECT * FROM logs WHERE user_id = 123 ORDER BY created_at DESC LIMIT 1; (последняя запись пользователя) оптимален составной индекс: CREATE INDEX CONCURRENTLY idx_logs_user_id_created_at ON logs(user_id, created_at DESC);. Так PostgreSQL быстро найдет все записи пользователя в обратном порядке и возьмет первую.
🔍 Анализ план запроса
После создания индекса используйте EXPLAIN (ANALYZE, BUFFERS) для проверки , необходимо убедиться, что в плане появился узел Index Scan или Index Only Scan, а не Seq Scan (последовательное сканирование таблицы). Обратить внимание на стоимость операции и количество прочитанных данных.
🚫 Частые ошибки
LIMIT без ORDER BY: Без явного указания порядка PostgreSQL возвращает строки в удобном для него порядке, который может быть непредсказуемым. Всегда нужно использовать ORDER BY с LIMIT для гарантированного результата.
Слишком сложные условия в WHERE: Вычисления наподобие WHERE extract(month from created_at) = 12 часто не позволяют использовать индекс. Переписать условие так, чтобы колонка была "чистой": WHERE created_at >= '2025-12-01' AND created_at < '2026-01-01'.
OFFSET с большими значениями: LIMIT 1 OFFSET 1000000 заставляет СУБД перебрать и отбросить все миллион строк. Для постраничной навигации использовать условие WHERE id > last_seen_id ORDER BY id LIMIT n.
P.S.
Настройка work_mem может помочь, если в плане выполнения видна сортировка на диске, но начинать всегда стоит с проектирования индексов и анализа запросов.
Доброго всем времени суток Есть сервак под Win 2022. Без доступа в интернет. На сервере поднят RDP, установлен офис и т.д.
Есть куча юзеров (около 50) которые подключаются к серваку по RDP и работают (создают, редактируют, копируют, удаляют) там с файлами офиса.
Нужно: а) какую-нибудь программу, для записи действий каждого пользователя. Родной журнал событий показывает только параметры сессий. То есть время подключения\отключения и т.д. Но не показывает какие действия и с какими НЕсистемными файлами производил пользователь. А нужно, именно знать с какими конкретно документами, что, сколько раз, когда (по дате и времени) делал каждый пользователь. б) поскольку число файлов плавно перевалило за тысячу, понадобилось что-то вроде СУБД для хранения, разграничения доступа и номинального редактирования офисных документов. Доступа к интернету - нет, поэтому никакие онлайн или облачные решения, тут не годятся.
Прошу совета опытных и знающих. Заранее всем благодарен за подсказки и помощь.
Продолжение анализа производительности для той же СУБД .
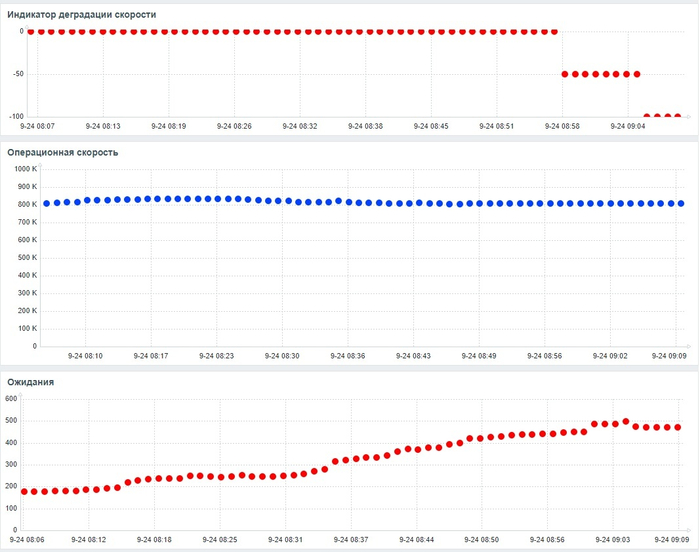
Инцидент производительности СУБД
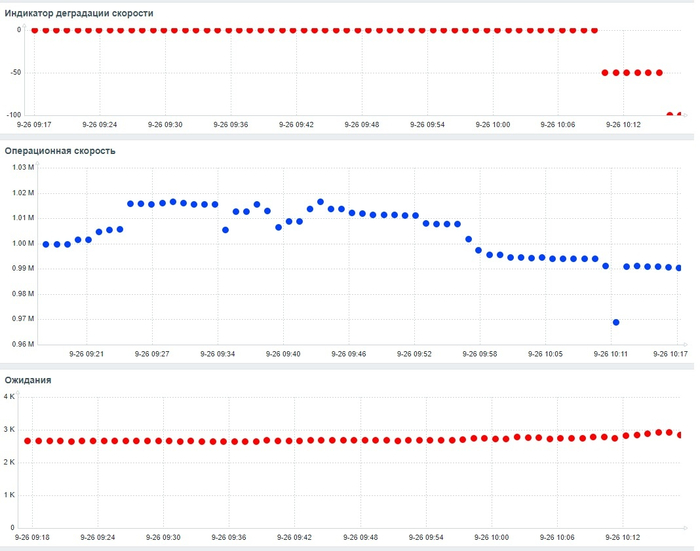
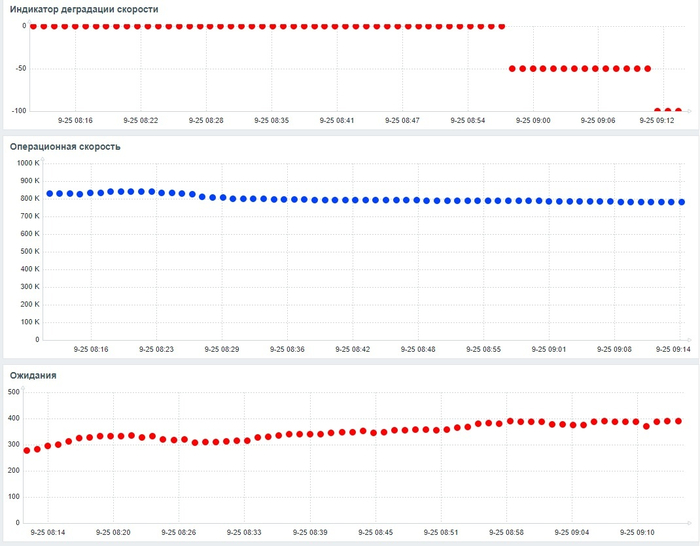
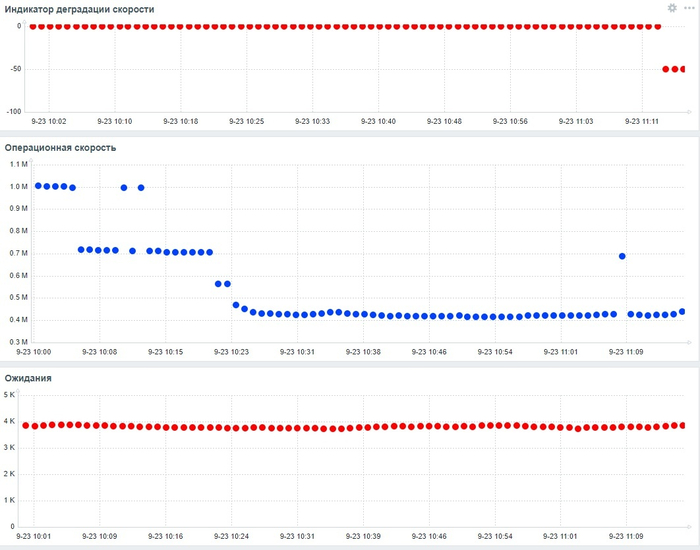
Дашборд Zabbix
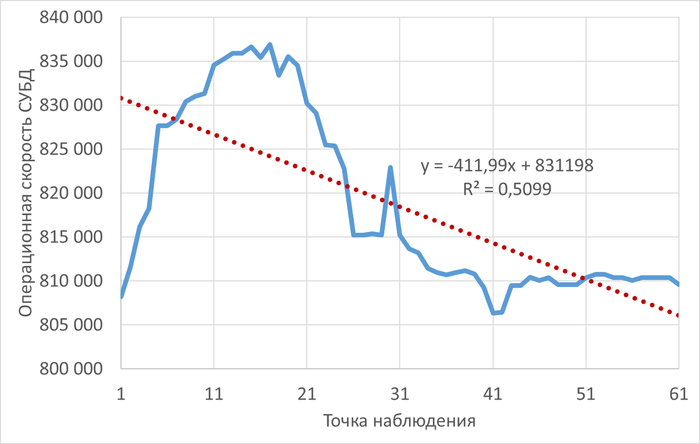
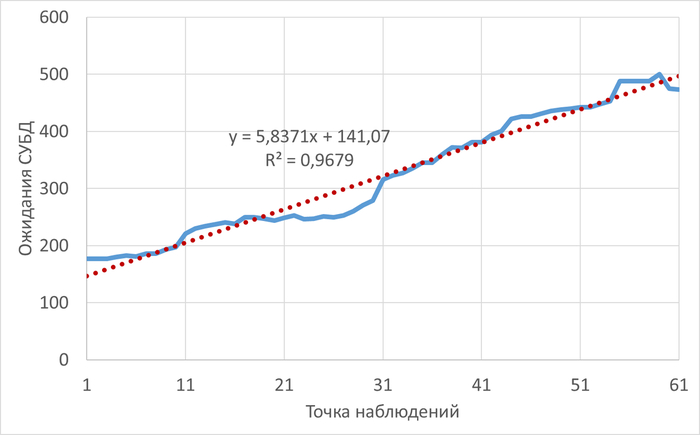
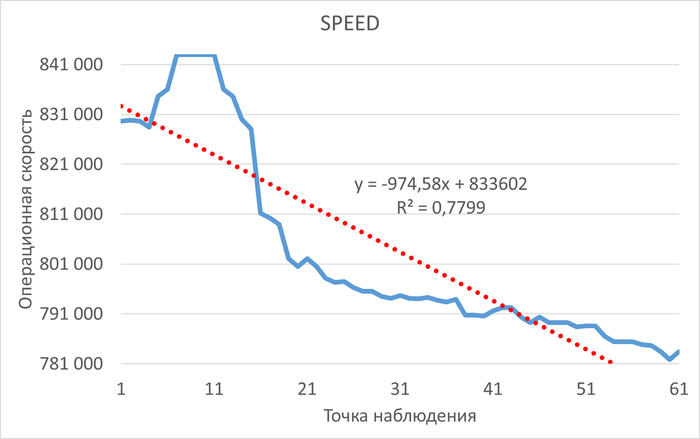
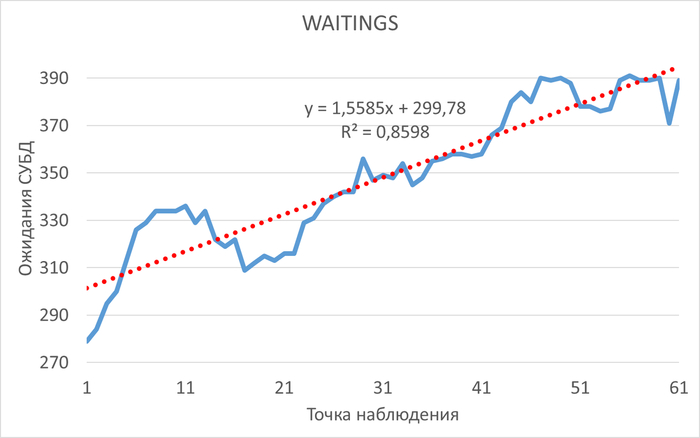
Операционная скорость и ожидания СУБД
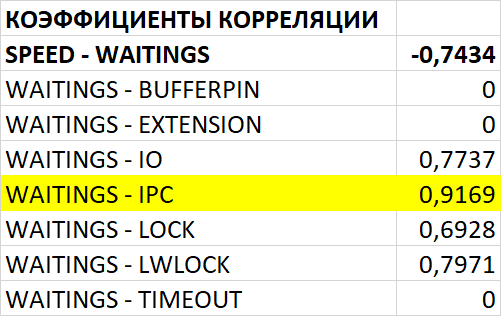
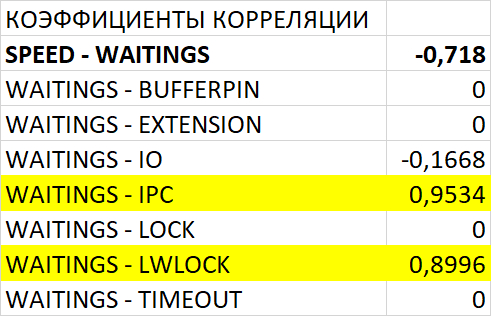
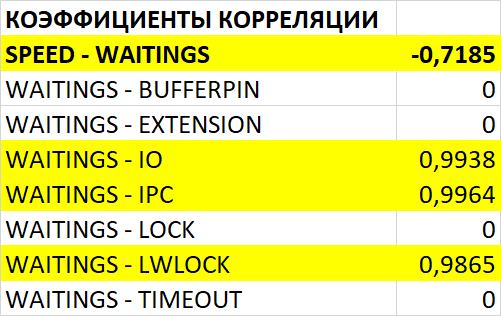
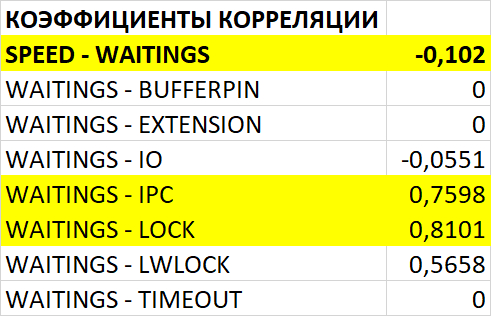
Корреляция и ожидания СУБД
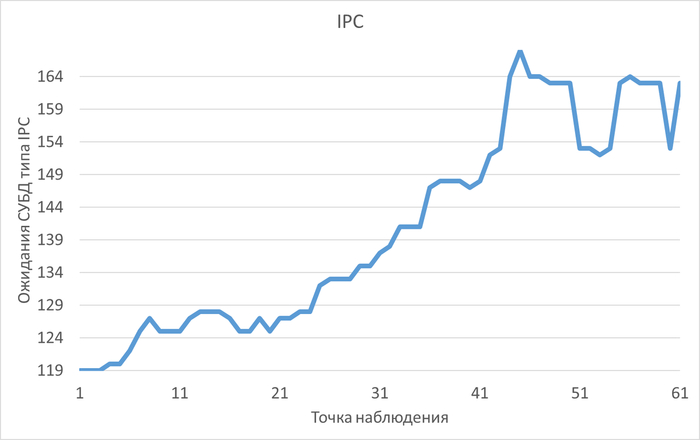
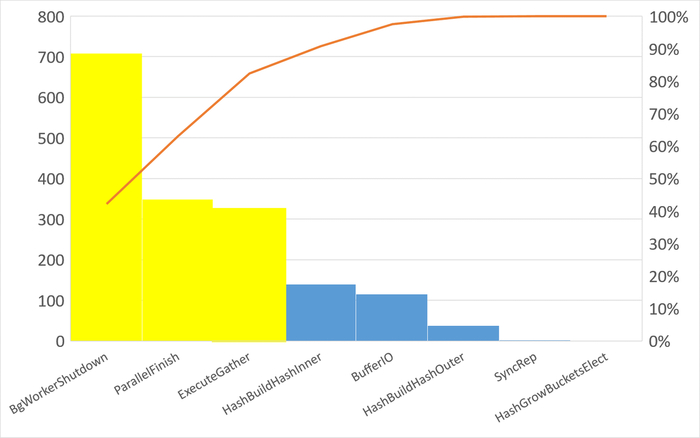
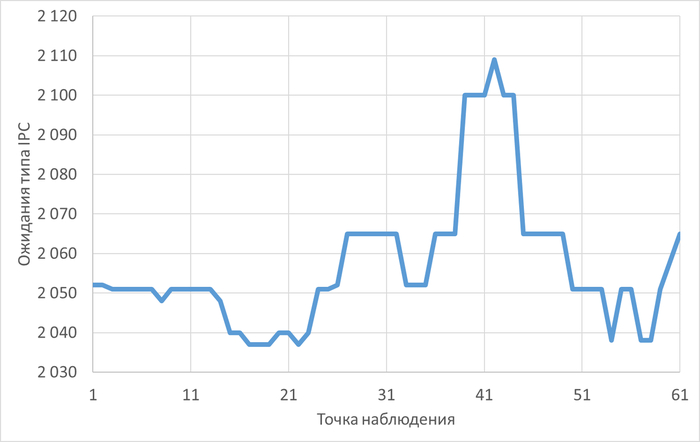
Ожидания типа IPC
80% ожиданий:
BgWorkerShutdown
ParallelFinish
ExecuteGather
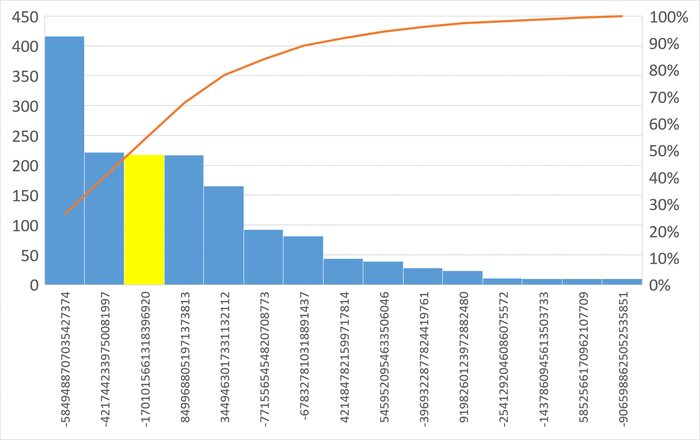
Ожидания типа IPC по SQL-запросам
Следующий SQL-запрос для оптимизации : -1701015661318396920
Текст запроса содержит параметр, поэтому для анализа возможных вариантов оптимизации придется воспользоваться планом выполнения запроса, полученному из отчетов pgpro_pwr:
pgpro_pwr_queryid: e864c744b5bda408
plan_id: b8b72054c691886a
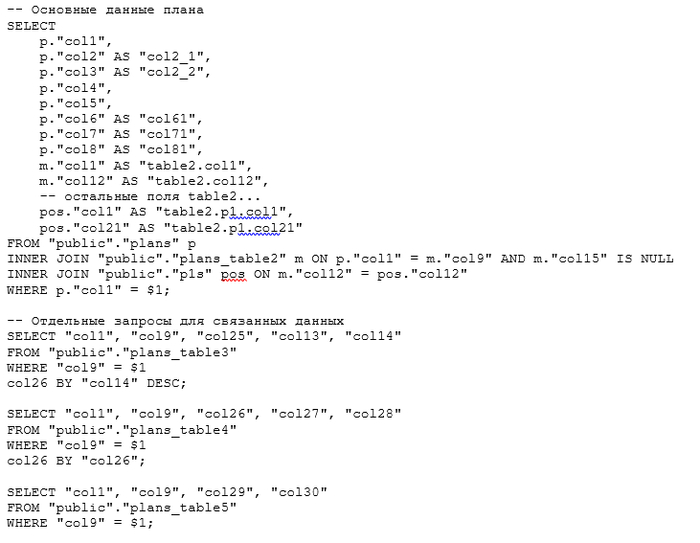
План выполнения запроса
Оптимизация SQL-запроса
1. Оптимизация структуры запроса
Основная проблема - "декартово произведение" из-за нескольких LEFT JOIN.
2. Добавление недостающих индексов
3. Оптимизация текущего запроса
4. Настройка PostgreSQL
Возможный план оптимизации
Добавление индекса для plans_table4 - это самое слабое место в текущем плане
Разделить запрос на несколько - это даст наибольший прирост производительности
Использование агрегацию через JSON, если нужны все данные в одной строке
Проанализировать причины инцидента производительности СУБД . Выявить и оптимизировать SQL-запросы влияющие на снижение производительности СУБД.
Инцидент производительности СУБД
Дашборд Zabbix
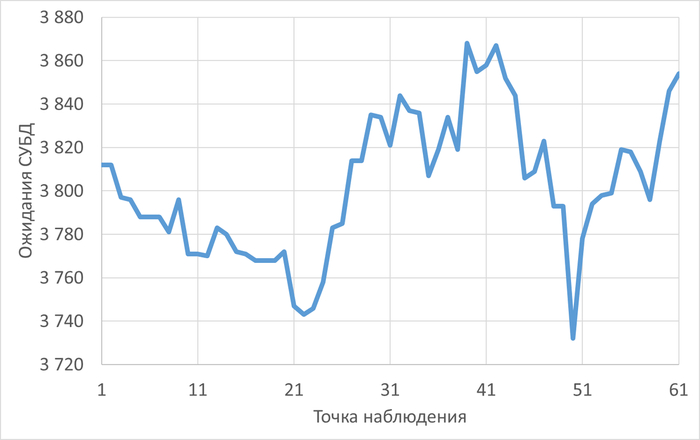
Операционная скорость и ожидания СУБД
Корреляция ожиданий СУБД
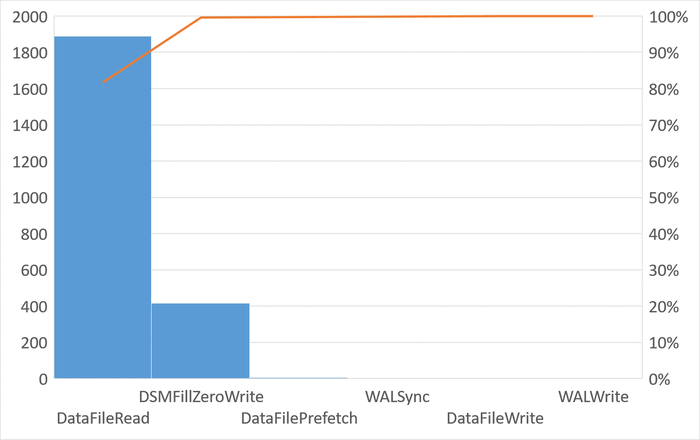
Ожидания типа IO
80% ожиданий DataFileRead
Ожидания типа IO по SQL-запросам
Ожидания типа IPC
80% ожиданий:
BgWorkerShutdown
ParallelFinish
ExecuteGather
Ожидания типа IPC по SQL-запросам
SQL-запросы с количеством ожиданий типа IPC >= 10
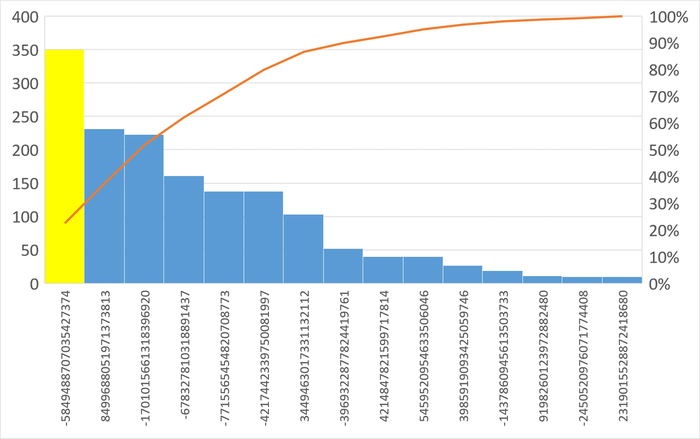
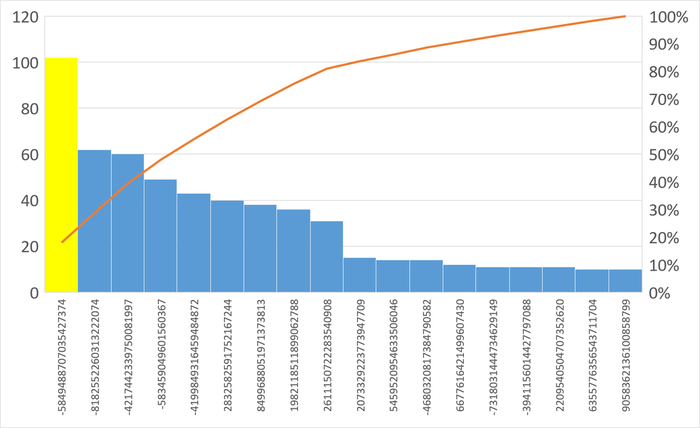
Наибольшее количество ожиданий типа IPC по SQL c queryid = -5849488707035427374
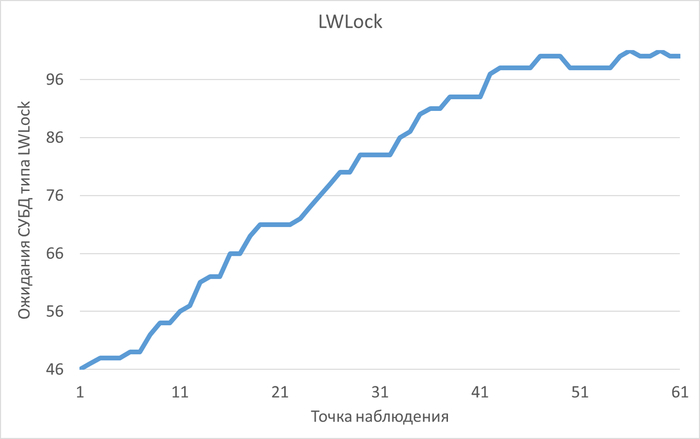
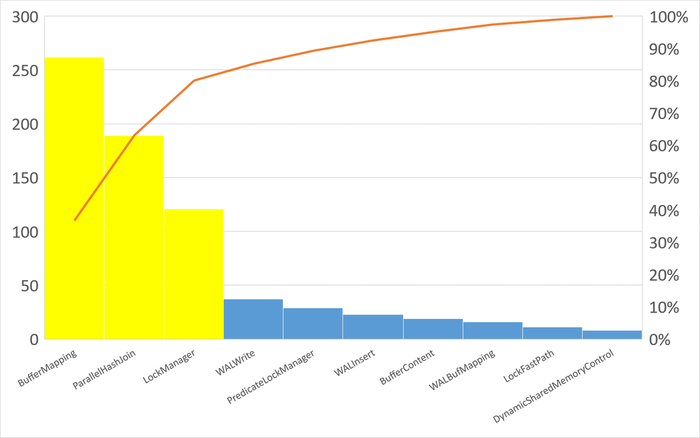
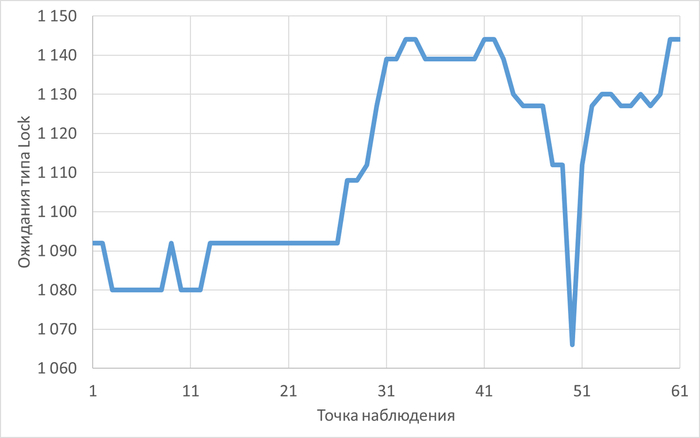
Ожидания типа LWLock
80% ожиданий:
BufferMapping
ParallelHashJoin
LockManager
Ожидания типа LWLock по SQL-запросам
SQL-запросы с количеством ожиданий типа LWLock >= 10
Наибольшее количество ожиданий типа IPC по SQL c queryid = -5849488707035427374
SQL-запрос для оптимизации: -5849488707035427374
План выполнения запроса
Оптимизация SQL-запроса
1. Добавить индексы
-- Для фильтрации table1
CREATE INDEX CONCURRENTLY col1x_succession_plan_filter
ON "table1" ("col2")
WHERE "col8" IS NULL AND "col9" IS NULL;
-- Для соединения с col7
CREATE INDEX CONCURRENTLY col1x
ON "col7" ("table1col1", "col8", "col4");
-- Для связи с table2
CREATE INDEX CONCURRENTLY col1x
ON "table1" ("table2col1");
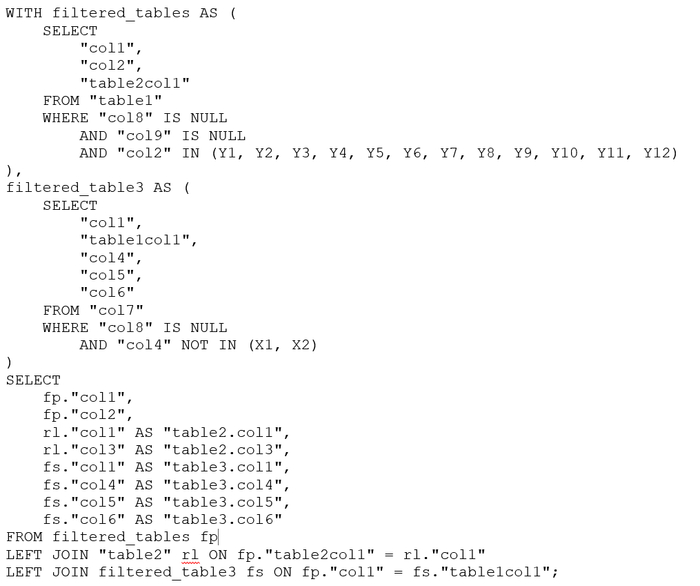
2. Переписать запрос с использованием CTE
3. Оптимизация работы с IN
CREATE TEMP TABLE temp_tables (col2 BIGINT);
INSERT INTO temp_tables VALUES (Y1), (Y2), ...; -- все значения
-- Затем в основном запросе:
WITH filtered_tables AS (
SELECT ...
FROM "table1" sp
JOIN temp_tables pt ON sp."col2" = pt.col2
WHERE ...
)
Результат
Применение комплекса PG_HAZEL "Орешник" позволило резко сократить время на анализ причин снижения производительности СУБД и быстро определить ключевые возможности для оптимизации проблемных SQL-запросов.
Если есть инструмент - любая проблема может быть решена.
Задача
Проанализировать причины инцидента производительности СУБД . Выявить и оптимизировать SQL-запросы влияющие на снижение производительности СУБД.
Инцидент производительности СУБД
Дашборд Zabbix
Операционная скорость и ожидания СУБД
Корреляция типов ожиданий СУБД
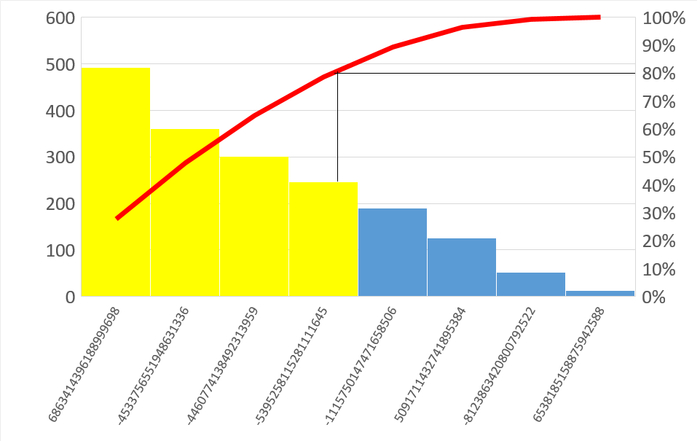
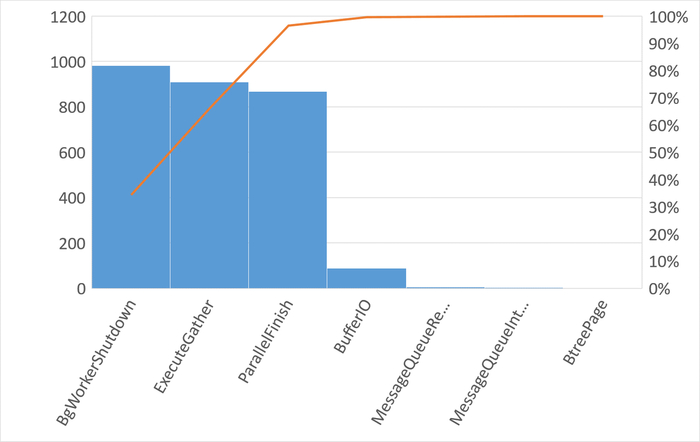
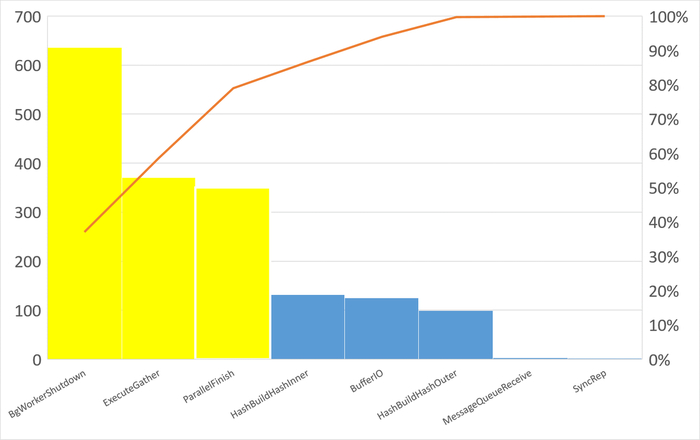
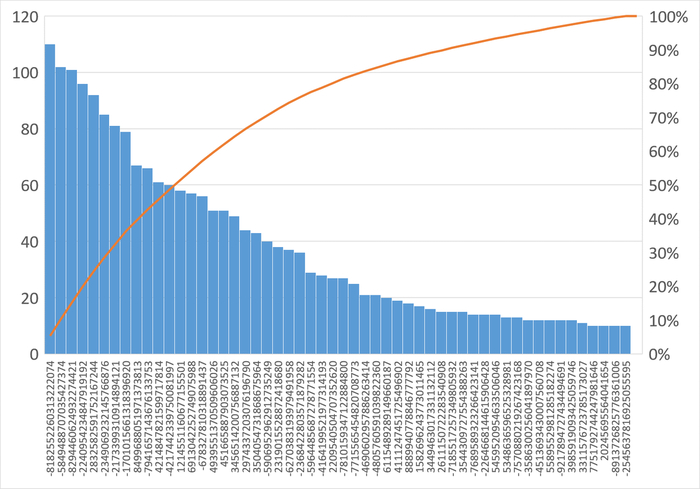
Диаграмма Парето по типу ожидания IPC
80% событий ожиданий :
BgWorkerShutdown: Ожидание завершения фонового рабочего процесса.
ExecuteGather: Ожидание активности дочернего процесса при выполнении узла плана Gather.
ParallelFinish: Ожидание завершения вычислений параллельными рабочими процессами.
Диаграмма Парето SQL-запросов по типу ожидания IPC
80% событий ожидания IPС по SQL-запросам:
6863414396188999698
-4533756551948631336
106835746851505948
-5395258115281111645
-4460774138492313959
-4665732847868082957
-7678244758353921905
Результат анализа ожиданий на уровне SQL-запросов:
Наибольшее количество ожиданий IPC по запросу 6863414396188999698
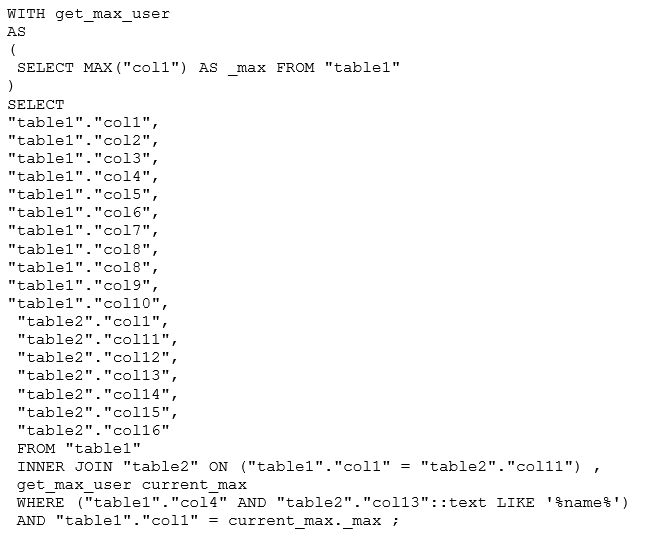
Текст запроса 6863414396188999698
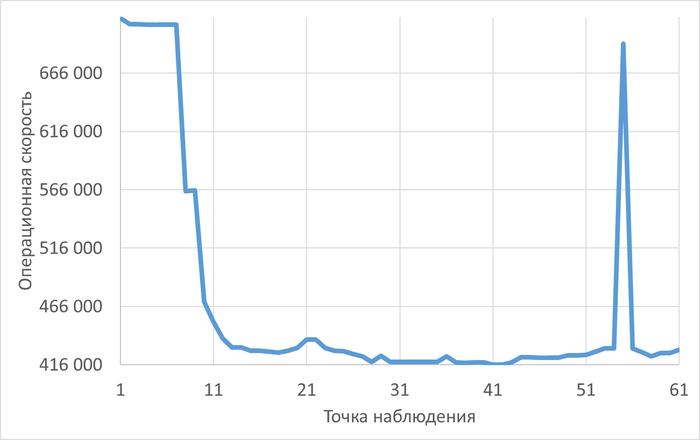
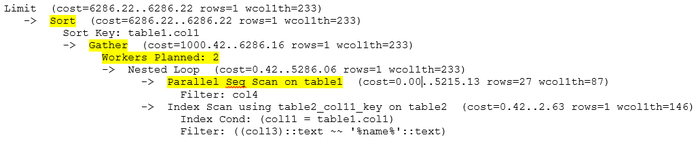
План выполнения запроса 6863414396188999698
Проблемные узлы плана выполнения:
Sort
Gather
Workers Planned: 2
Parallel Seq Scan
Оптимизация SQL-запроса
Измененный текст запроса
План выполнения измененного запроса
Сравнение стоимости и времени выполнения оригинального и измененного запроса
Оригинальный SQL-запрос
Измененный SQL-запрос
Результат
Применение комплекса PG_HAZEL "Орешник" позволило резко сократить время на анализ причин снижения производительности СУБД и быстро определить ключевые возможности для оптимизации проблемных SQL-запросов.