Как правильно оценивать модель?

Подобрали датасет, написали код, получили первые результаты работы нейронки после обучения.
Но модель нужно тестить со всех сторон.
Не получится продать ИИ заказчику или сдать своему руководителю без нормальной отчетности.
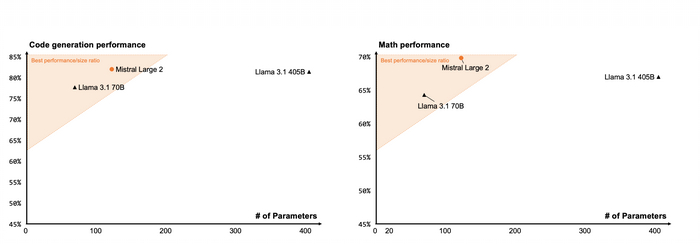
Всего есть 7 важных метрик, по которым модель оценивается.
Accuracy: Процент правильных предсказаний относительно общего числа предсказаний.
Полнота (Recall): Доля истинных положительных предсказаний относительно фактического числа положительных случаев.
Точность (Precision): Доля истинных положительных предсказаний среди всех положительных предсказаний.
F1-мера: Гармоническое среднее точности и полноты, полезное для неравномерно распределённых классов.
ROC-AUC: Площадь под кривой ROC; показывает, как модель различает положительные и отрицательные классы.
Mean Absolute Error (MAE) и Mean Squared Error (MSE) для регрессионных задач.
Идеальных моделей не бывает, поэтому метрики нужно догонять в зависимости от задачи.
Помимо учета метрик, нужно уметь: и оптимизировать модель через настройку гиперпараметров (о ней в статье на Хабре), и уменьшать предвзятость ИИ через кросс-валидацию или попросту разбиение тренировочных данных, и убирать эффект переобучения через регуляризацию.
Идеальный анализ качества модели, кстати, не обходится без графиков.
Но иногда всех вышеприведенных методов недостаточно.
Например, при ковариационном сдвиге распределение входных данных каждого слоя нейронки в меняется процессе обучения, из-за чего сети становится сложнее обучать.
Чтобы пофиксить проблему используется батч-нормализация, где среднее значение приближается к нулю, а стандартное к единицу через преобразование входных данных каждого слоя.
Чтобы пофиксить чрезмерную зависимость работы модели от отдельных нейронов применяют дропаут, который рандомно будет выключать некоторые узлы в сети на каждом этапе обучения.
Но главное – это не просто знать методы, а уметь анализировать.