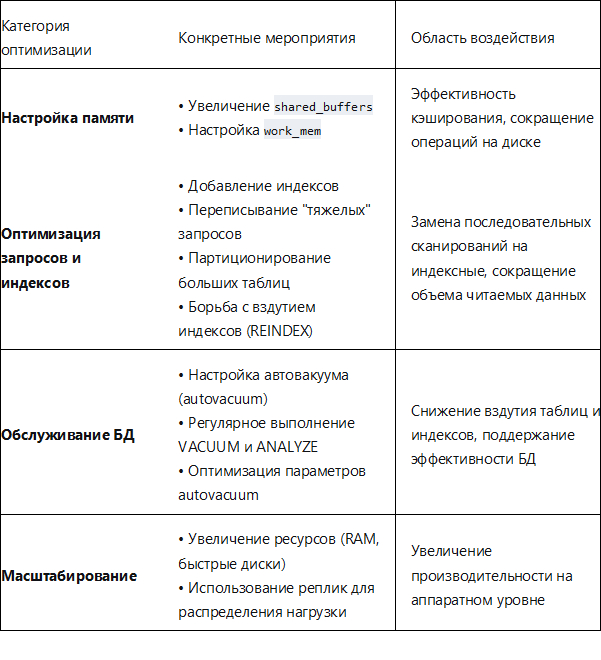
Начало работ по теме
Задача
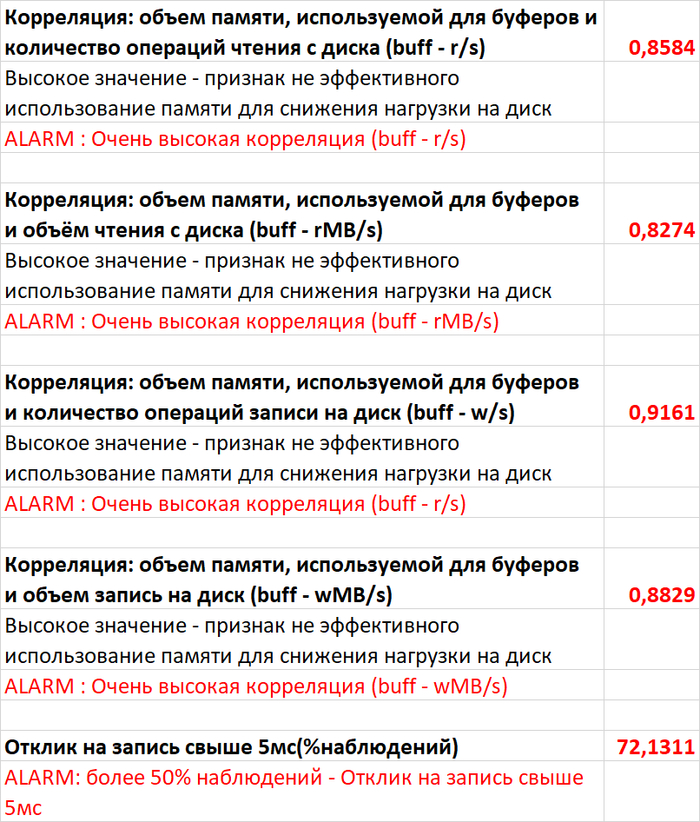
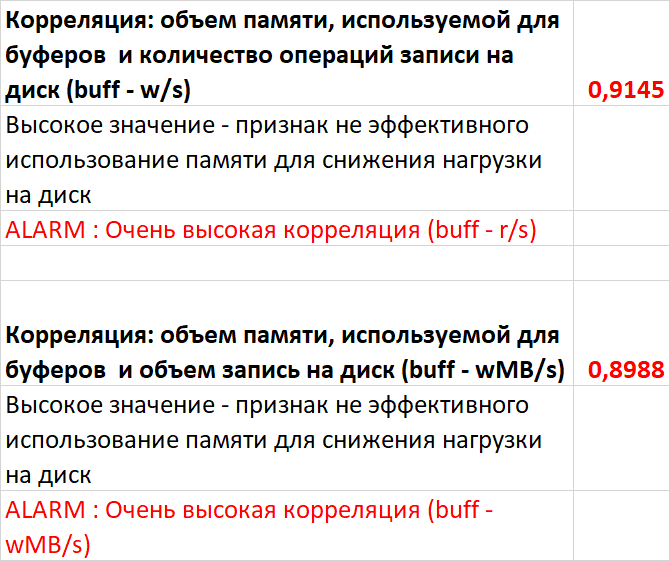
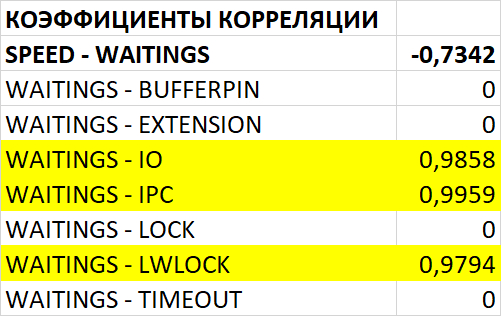
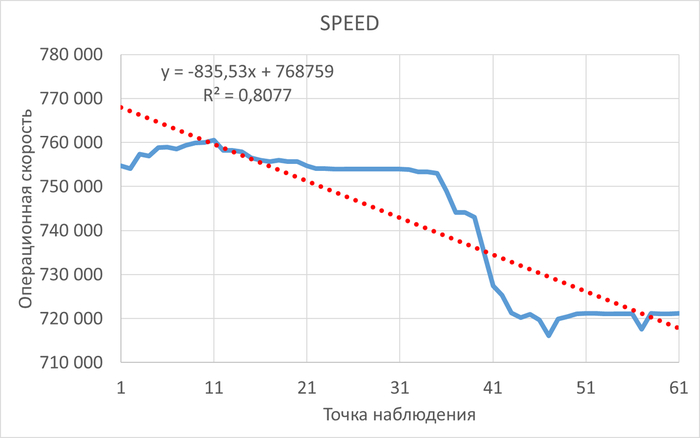
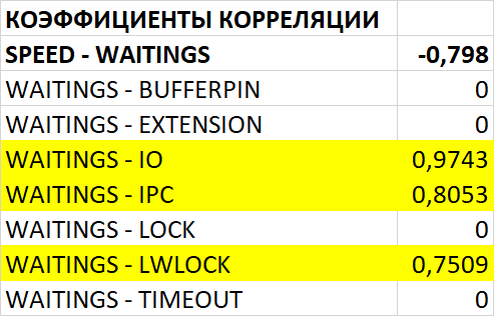
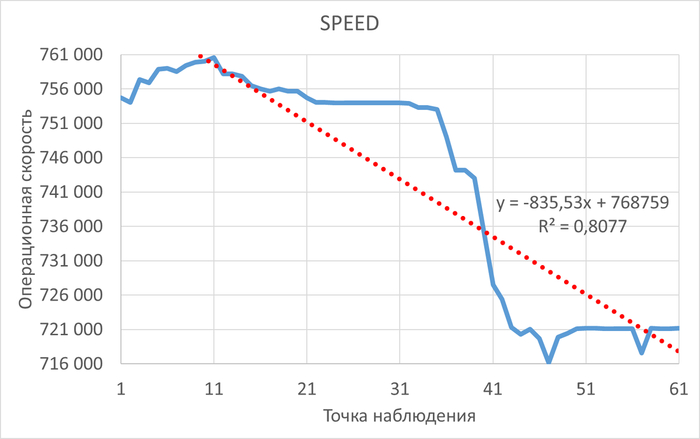
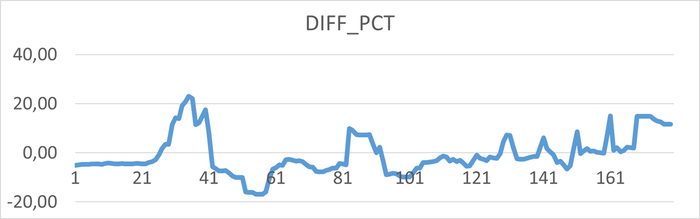
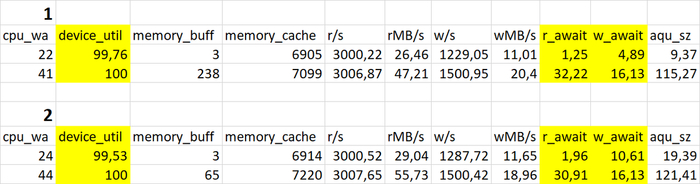
Провести сравнительный анализ метрик оценки производительности СУБД и результатов корреляционного анализа ожиданий СУБД в период штатной работы СУБД и при снижении производительности СУБД.
Используя семантический анализ выявить аномалии SQL запросов.
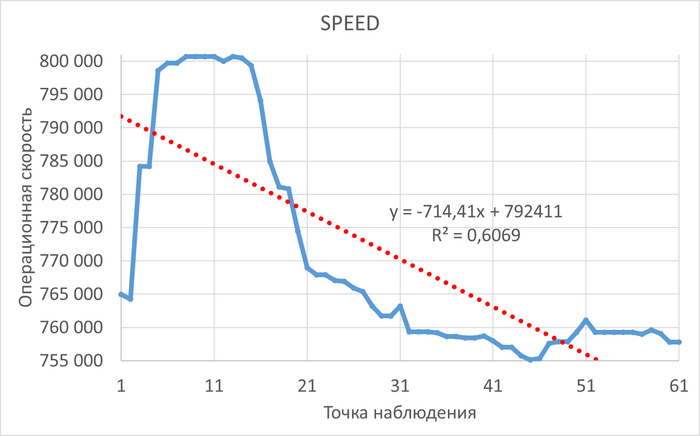
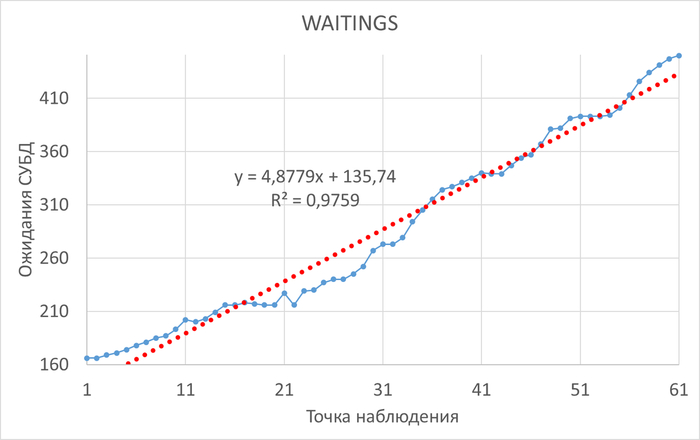
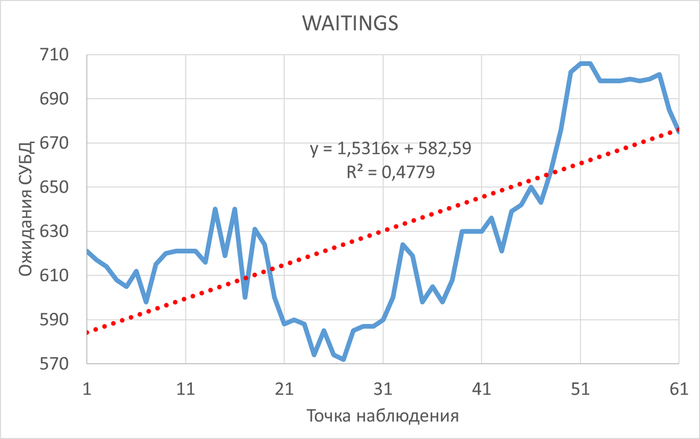
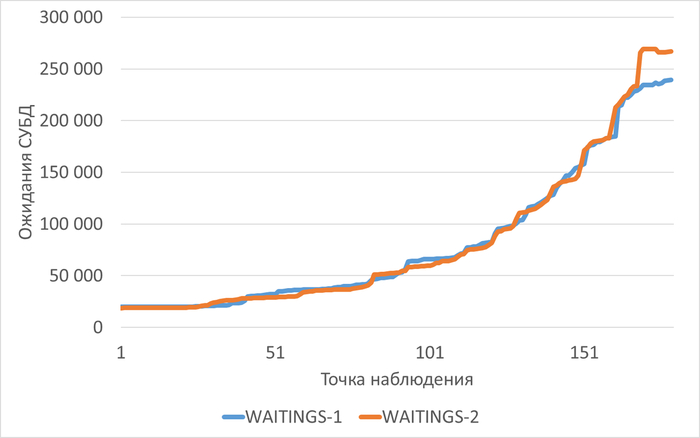
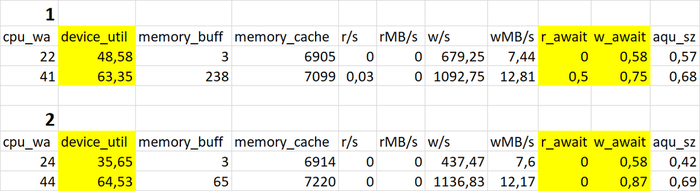
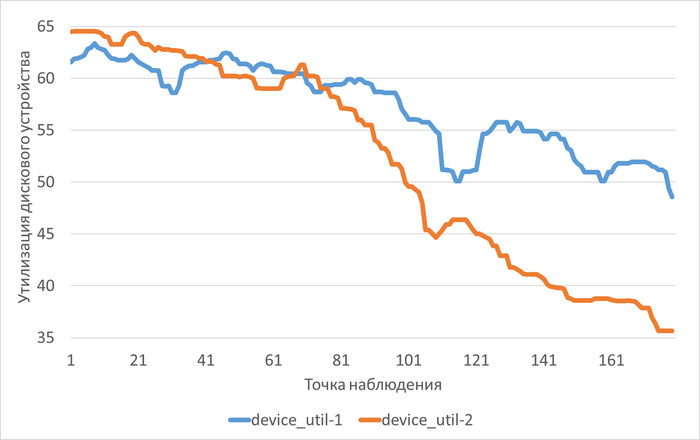
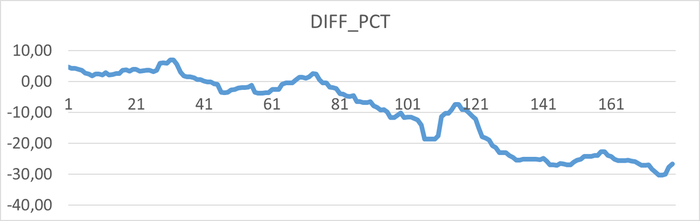
Период штатной производительности СУБД(1)
Инцидент снижения производительности СУБД(2)
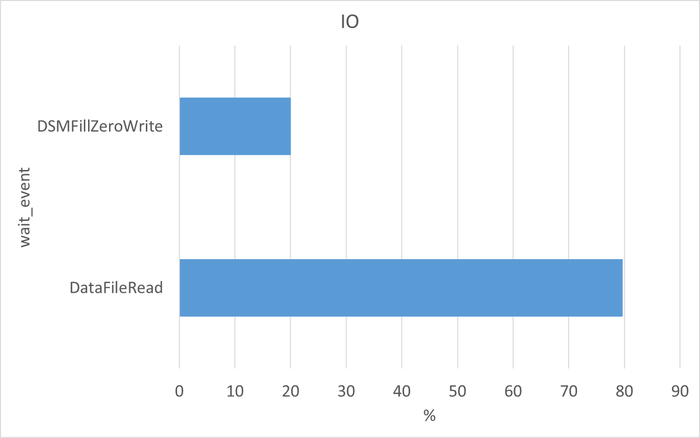
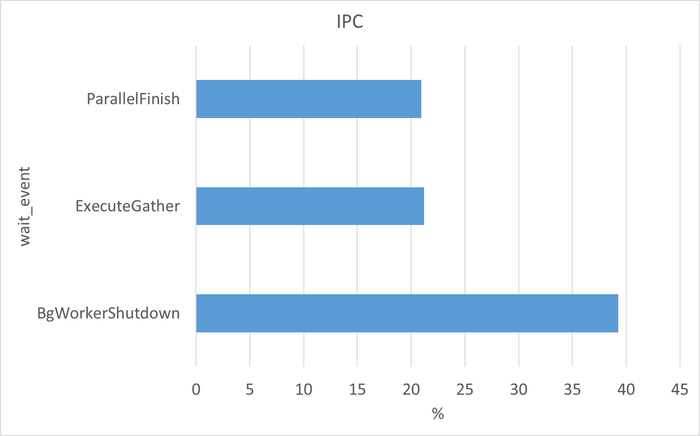
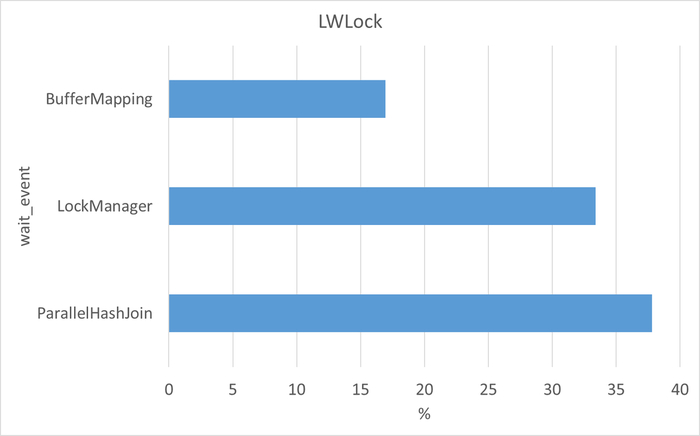
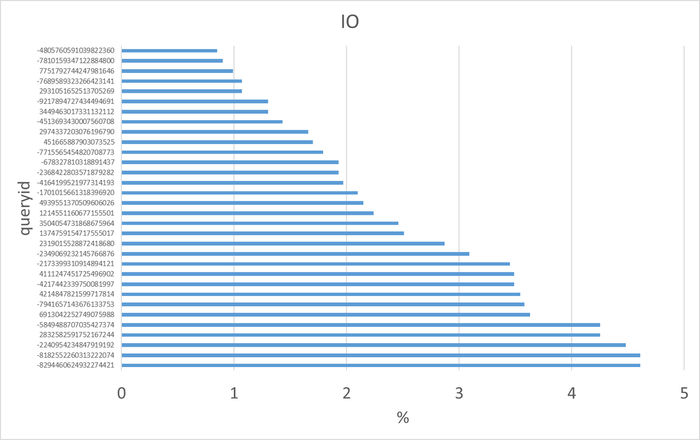
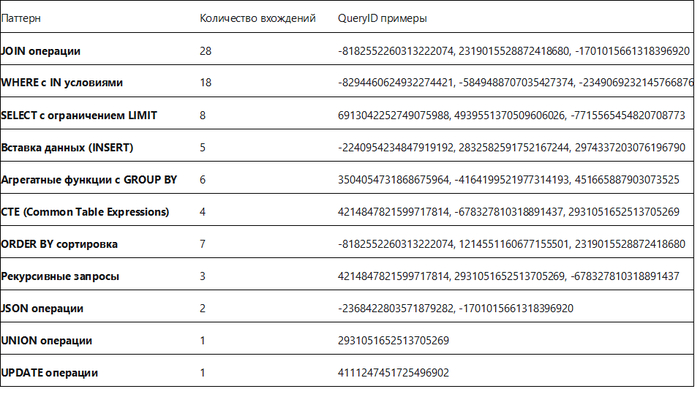
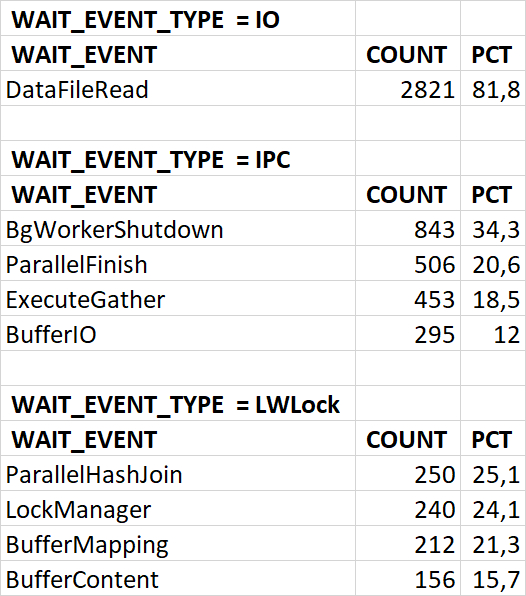
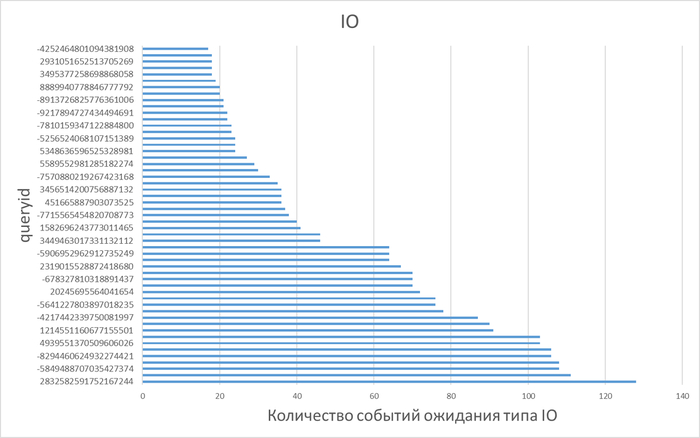
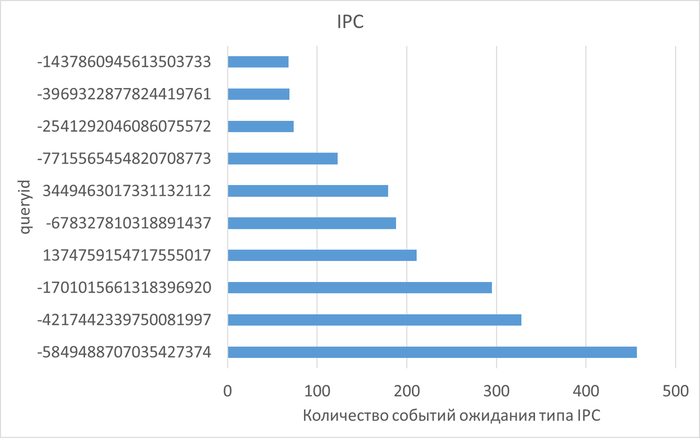
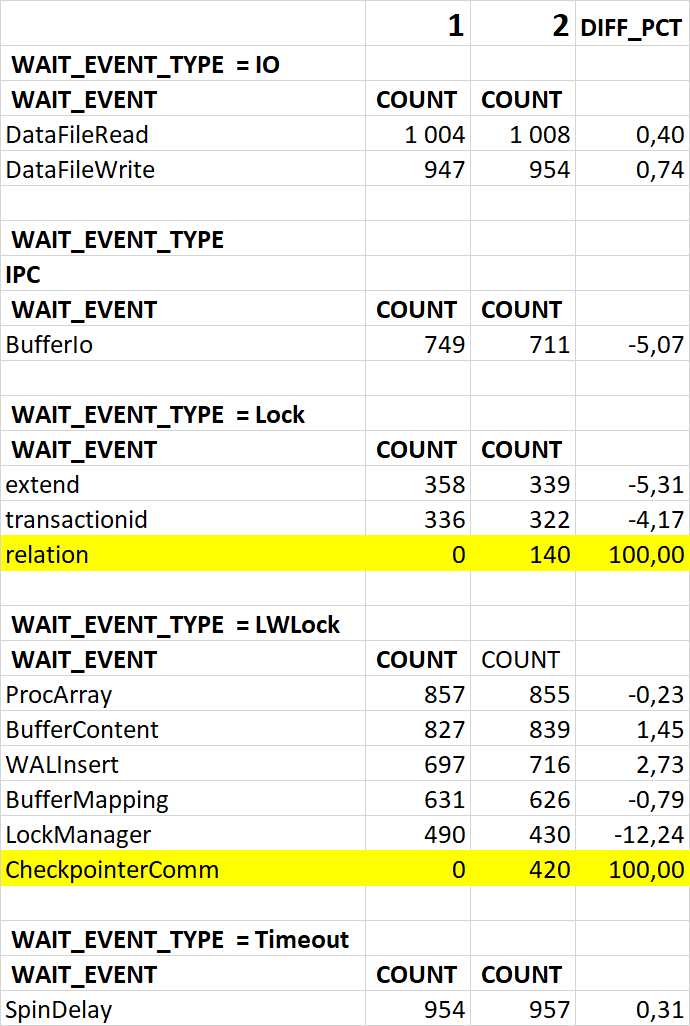
Диаграмма Парето по wait_event
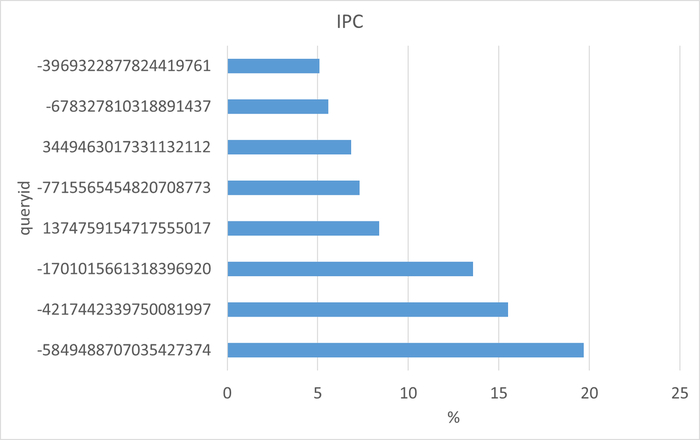
Семантический анализ SQL запросов по типу ожидания IPC между периодами штатной производительности (1) и снижением производительности (2)
Общие паттерны
Паттерн 1: SELECT с LEFT OUTER JOIN и сложной фильтрацией
SELECT main_table.*, joined_tables.*
LEFT OUTER JOIN table1 ON ...
LEFT OUTER JOIN table2 ON ... AND (conditions)
WHERE (main_table.deleteDateTime IS NULL AND main_table.field IN (...))
Пример: Запросы к successionPlan с джойнами riskLeaving и successor
Паттерн 2: CTE с оконными функциями и рекурсивной структурой
WITH cte1 AS (SELECT ..., row_number() OVER (PARTITION BY ...) FROM ...),
cte2 AS (SELECT ... FROM cte1 JOIN multiple_tables ON complex_conditions)
SELECT array_agg(...) FROM cte2 WHERE ... OR level = (SELECT max(level) FROM cte2)
Пример: Запрос с CTE orgUnitIds и responsible
Паттерн 3: Комплексный SELECT с цепочкой JOIN
SELECT main_table.*, multiple_joined_tables.*
INNER JOIN table1 ON ... AND (condition)
LEFT OUTER JOIN table3 ON ...
LEFT OUTER JOIN table4 ON ...
LEFT OUTER JOIN table5 ON ...
WHERE main_table.uuid = $1
Пример: Запрос к plans с джойнами plans_meta, positions, plans_statuses и др.
Паттерн 4: Простой SELECT из VIEW
SELECT * FROM view_name WHERE view_name.foreign_key IN (...)
Пример: Запрос к employeeManagerView
Паттерн 5: SELECT с фильтрацией и сортировкой
WHERE field1 = $1 AND field2 != $2
Пример: Запрос к таблице rating
Паттерн 6: SELECT с INNER JOIN по атрибутам
SELECT main_table.*, joined_tables.*
INNER JOIN table2 ON ... AND table2.key = $1 AND table2.value = $2
Пример: Запрос к tasks с джойнами plans_tasks и tasks_attributes
Паттерны для периода деградации производительности
Паттерн 7: UPDATE с множественными полями
SET field1=$1, field2=$2, ..., fieldN=$N
WHERE primary_key1 = $M AND primary_key2 = $K
Пример: UPDATE запрос к auditLog
SELECT count(*) AS count FROM table WHERE foreign_key = $1
Пример: Подсчёт записей в plans_meetings
Паттерн 9: SELECT с IN для одного параметра
SELECT fields FROM table WHERE foreign_key IN ($1)
Пример: Запрос к excludeSendEmailToNotificationSettings
Итог по ожиданию типа IPC:
SELECT с LEFT OUTER JOIN ✅ ✅
CTE с оконными функциями ✅ ✅
Комплексный SELECT с JOIN ✅ ✅
SELECT с сортировкой и LIMIT ✅ ✅
SELECT с INNER JOIN по атрибутам ✅ ✅
UPDATE с множественными полями❌ ✅
SELECT с IN для одного параметра ❌ ✅
Период штатной производительности содержит 6 уникальных паттернов, период деградации производительности содержит все 9 паттернов.
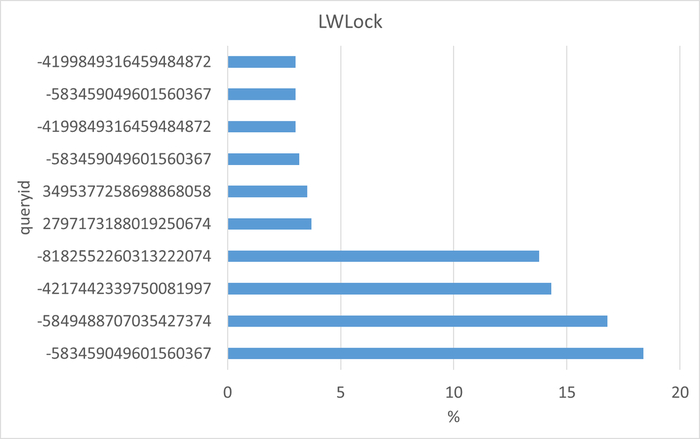
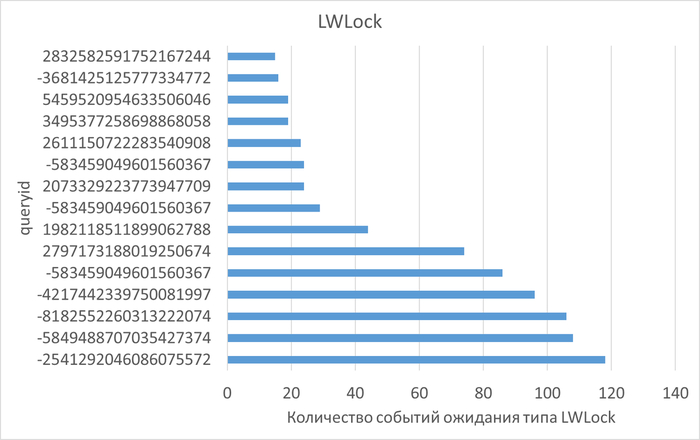
Семантический анализ SQL запросов по типу ожидания LWLock между периодами штатной производительности (1) и снижением производительности (2)
Общие паттерны
Паттерн 1: Установка временной зоны
Частота: Повторяется многократно в обоих файлах
Паттерн 2: SELECT successionPlan с LEFT OUTER JOIN
SELECT "SuccessionPlan".*, "riskLeaving".*, "successors".*
LEFT OUTER JOIN "riskLeaving" ON ...
LEFT OUTER JOIN "successor" ON ... AND (deleteDateTime IS NULL)
WHERE ("SuccessionPlan"."deleteDateTime" IS NULL
AND "SuccessionPlan"."positionId" IN (...)
AND "SuccessionPlan"."archiveDate" IS NULL)
Особенности: Одинаковая структура с разными значениями positionId
Паттерн 5: INSERT с множественными значениями
INSERT INTO "table" (field1, field2, ...)
Примеры: INSERT INTO "request", INSERT INTO "outbox_v1"
Паттерн 6: SELECT из outbox_v1 с пагинацией
SELECT "id", "stream", "subject", "payload", "options"
Встречается только в период штатной производительности(1)
Паттерн 3: SELECT improvementPlan с агрегацией
SELECT ip.*, array_agg(g.id) as goals, array[]::json[] as ...
FROM "improvementPlan" ip
LEFT JOIN "improvementPlanGoal" g ON ...
Паттерн 4: UPDATE с RETURNING
UPDATE "table" SET ... WHERE ... RETURNING fields
Пример: UPDATE "offerApprovalStatusHistory"
Паттерн 7: Системный мониторинговый запрос
SELECT current_database(), s1.relname AS table, seq_scan, idx_scan, ...
FROM pg_stat_user_tables s1
JOIN pg_class c ON s1.relid = c.oid
WHERE NOT EXISTS (SELECT ... FROM pg_locks WHERE ...)
Встречается только в период деградации производительности (2)
Паттерн 8: UPDATE auditLog с множественными полями
SET field1=$1, field2=$2, ..., fieldN=$N
WHERE primary_key_conditions
Паттерн 9: SELECT improvementPlanGoalToCourse с цепочкой JOIN
SELECT "ImprovementPlanGoalToCourse".*, joined_tables.*
FROM "improvementPlanGoalToCourse"
LEFT OUTER JOIN "courseSession" ON ...
LEFT OUTER JOIN "participation_results" ON ...
INNER JOIN "improvementPlanGoal" AS "goal" ON ...
LEFT OUTER JOIN "improvementPlan" AS "goal->improvementPlan" ON ...
WHERE "deleteDateTime" IS NULL AND id > ...
Паттерн 10: SELECT task с пагинацией
SELECT "Task".*, "module"."title", "process"."title"
LEFT OUTER JOIN "module" ON ...
LEFT OUTER JOIN "processes" ON ...
WHERE "Task"."targetEmpCodeId" = ...
Паттерн 11: SELECT user с подзапросом
JOIN "empCodeToUser" AS eCTU ON ...
JOIN "empCode" AS eC ON ...
JOIN "empCodeToPosition" eCTP ON eCTP.id = (
SELECT id FROM "empCodeToPosition" AS subECTP
ORDER BY subECTP.id DESC LIMIT 1
WHERE u."isEnabled" AND NOW() < u."endDateTime" AND ...
Паттерн 12: SELECT plans_tasks с цепочкой INNER JOIN
SELECT "PlansTasksModel".*, multiple_joined_tables.*
FROM "plans_tasks" AS "PlansTasksModel"
INNER JOIN "tasks" AS "task" ON ...
INNER JOIN "tasks_meta" AS "task->meta" ON ...
INNER JOIN "tasks_attributes" AS "task->filter" ON ...
LEFT OUTER JOIN "tasks_attributes" AS "task->attributes" ON ...
LEFT OUTER JOIN "tasks_statuses" AS "statuses" ON ...
WHERE "PlansTasksModel"."plan_uuid" = ...
Паттерн 13: UPDATE с массовыми параметрами
UPDATE "user" SET ... WHERE id IN ($1, $2, ..., $1002)
Особенности: Очень большое количество параметров (1002)
Паттерн 14: INSERT с RETURNING
INSERT INTO "table" (...) VALUES (...) RETURNING fields
Пример: INSERT INTO "auditLog" ... RETURNING ...
Итог по ожиданию типа LWLock:
SELECT successionPlan ✅ ✅
SELECT improvementPlan с агрегацией ✅ ❌
INSERT с множественными значениями ✅ ✅
SELECT outbox_v1 с пагинацией ✅ ✅
SELECT improvementPlanGoalToCourse ❌ ✅
SELECT task с пагинацией ❌ ✅
SELECT user с подзапросом ❌ ✅
UPDATE с массовыми параметрами ❌ ✅
Период штатной производительности содержит 7 уникальных паттернов, период деградации производительности содержит 11 паттернов.