PG_HAZEL : Часть 3 - характерные события ожиданий типа LWLock при инциденте производительности высоконагруженной СУБД
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Иногда легкие блокировки имеют не легкие последствия .
Начало
Задача
Проанализировать состояние ОС и характерные ожидания СУБД при инциденте производительности для высоконагруженной СУБД.
Количество ядер CPU : 192
Размер RAM: 1TB
Версия PostgreSQL: 15.13
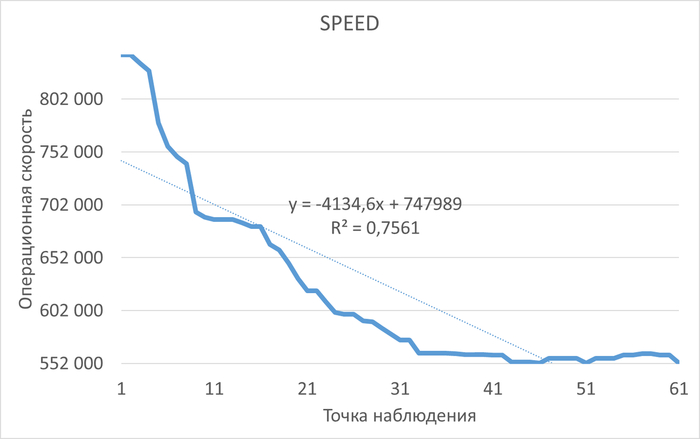
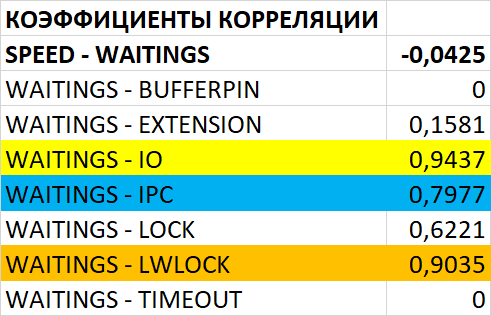
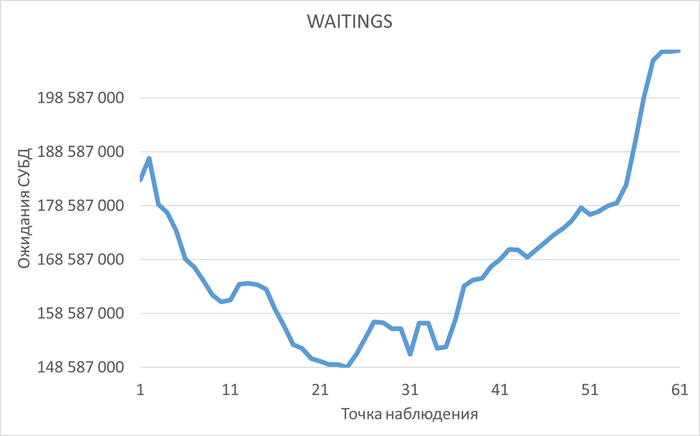
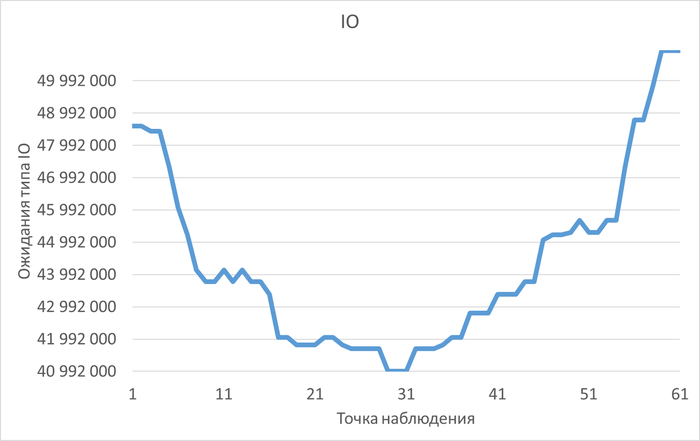
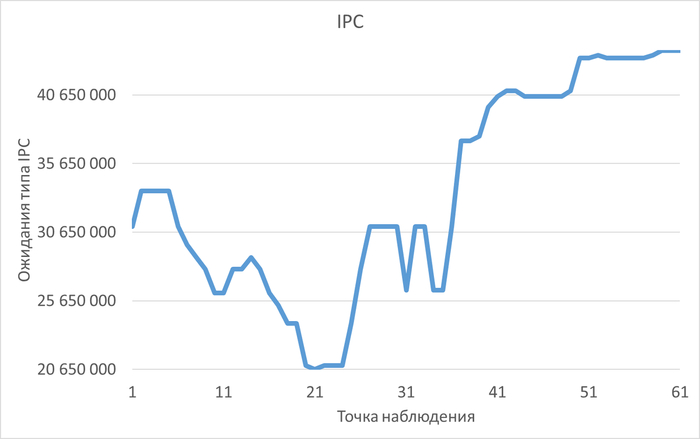
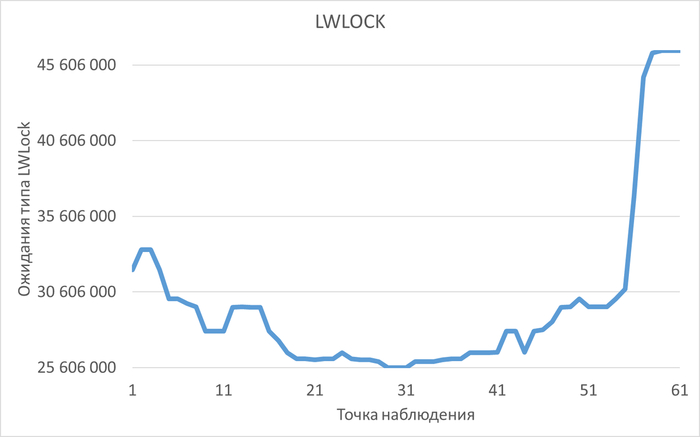
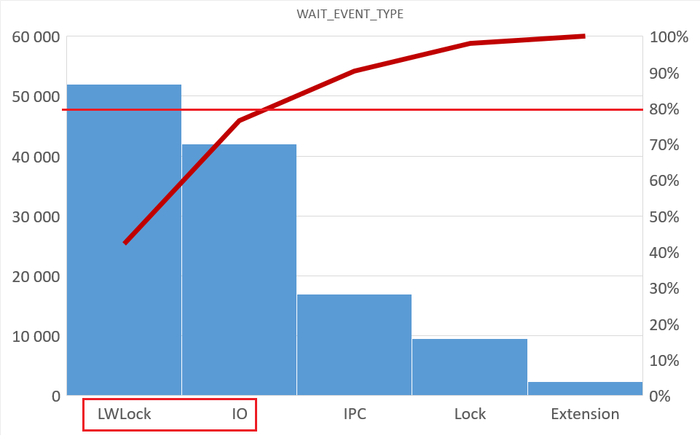
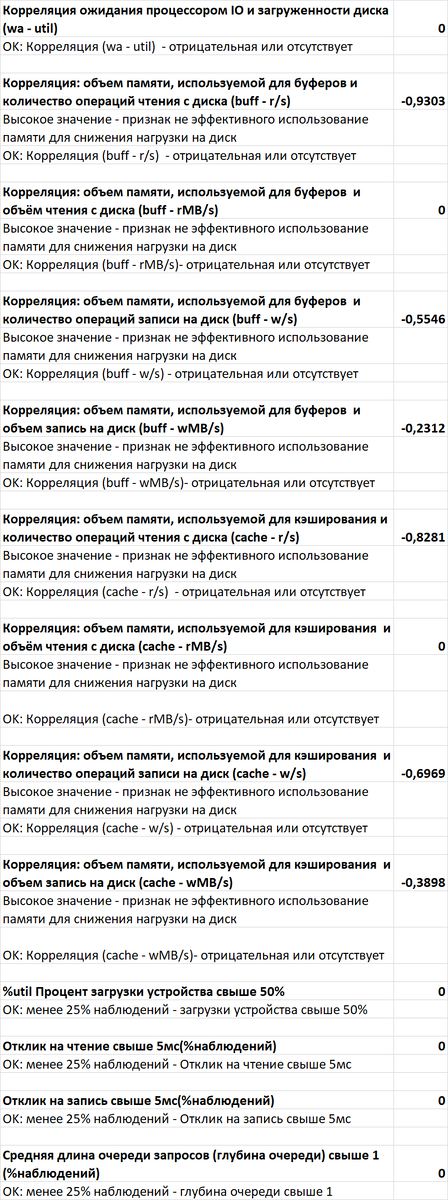
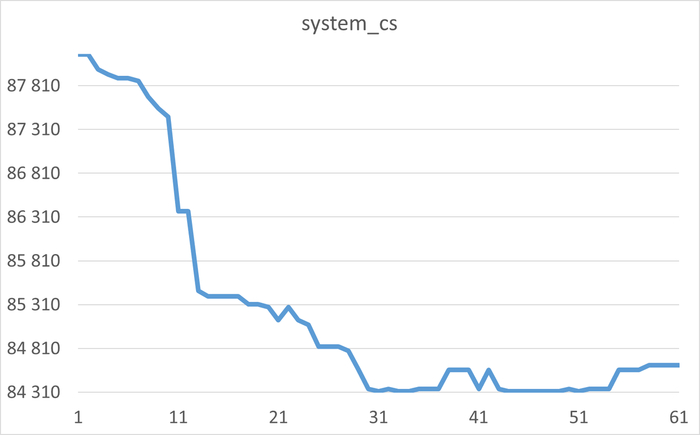
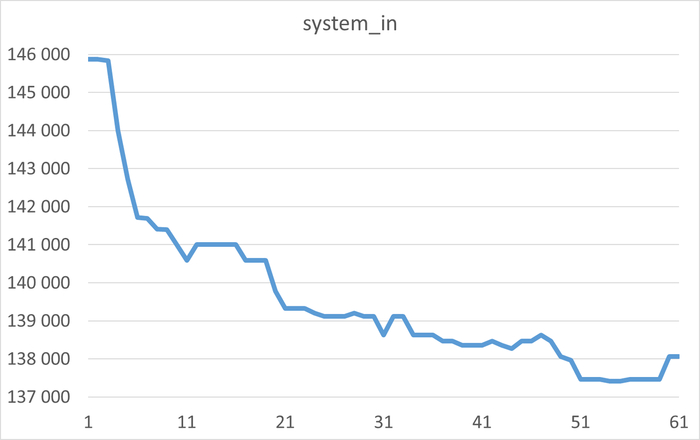
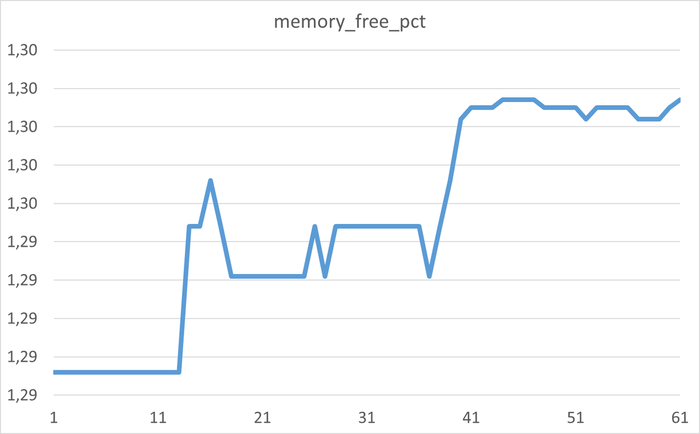
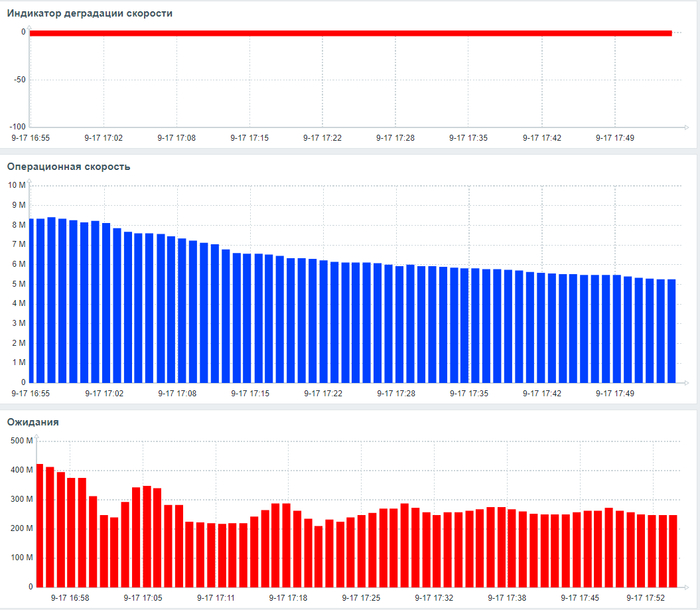
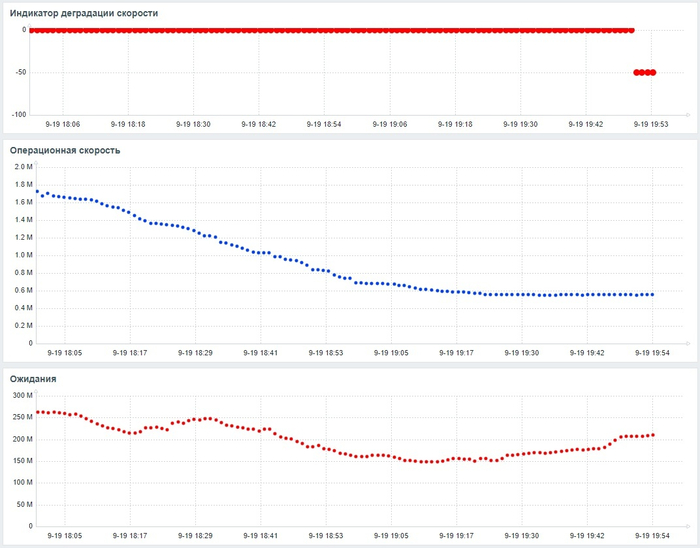
Инцидент производительности СУБД
Дашборд Zabbix
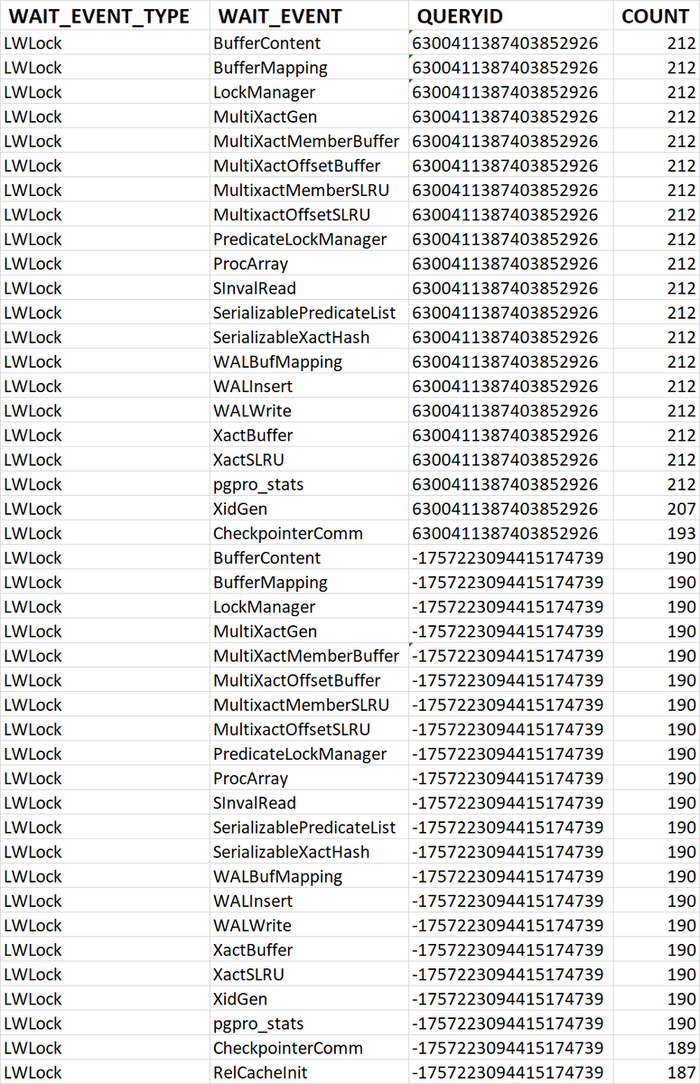
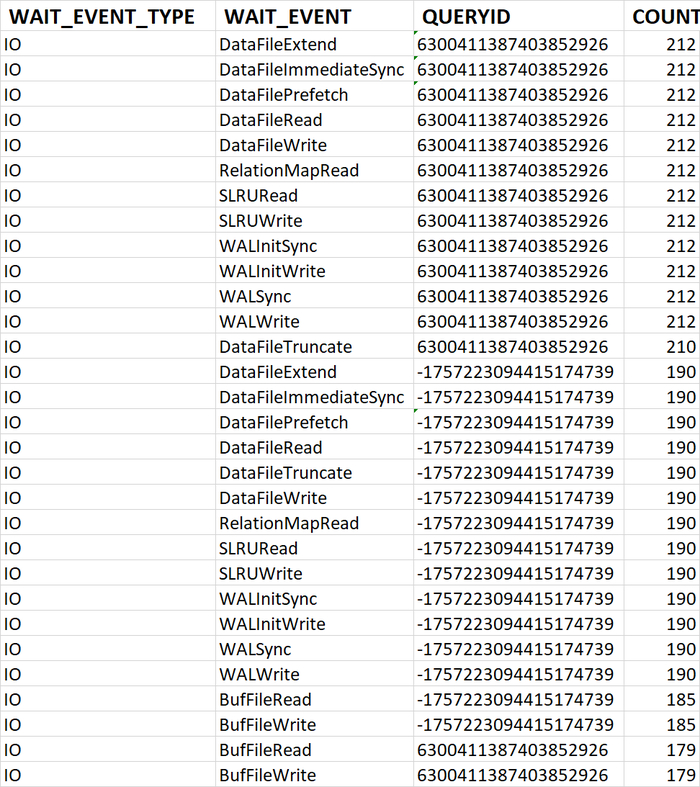
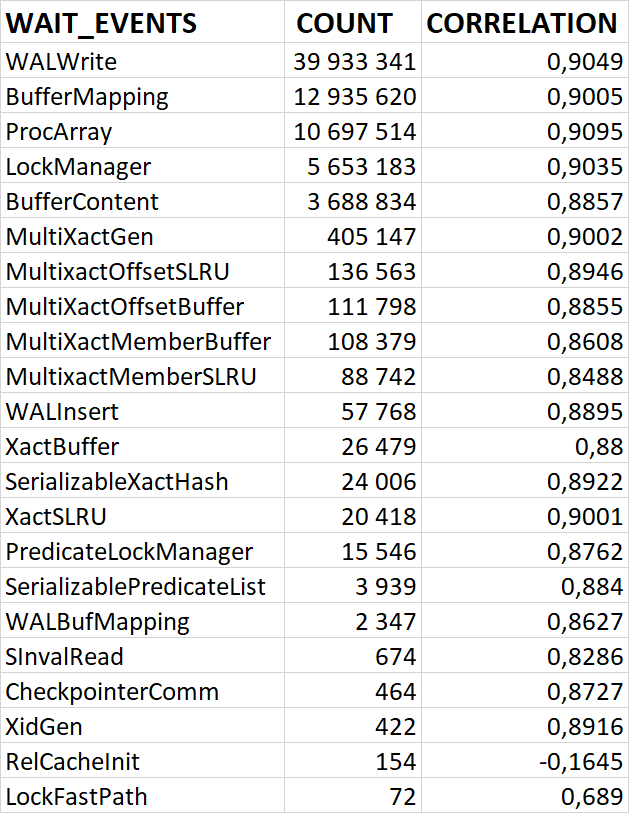
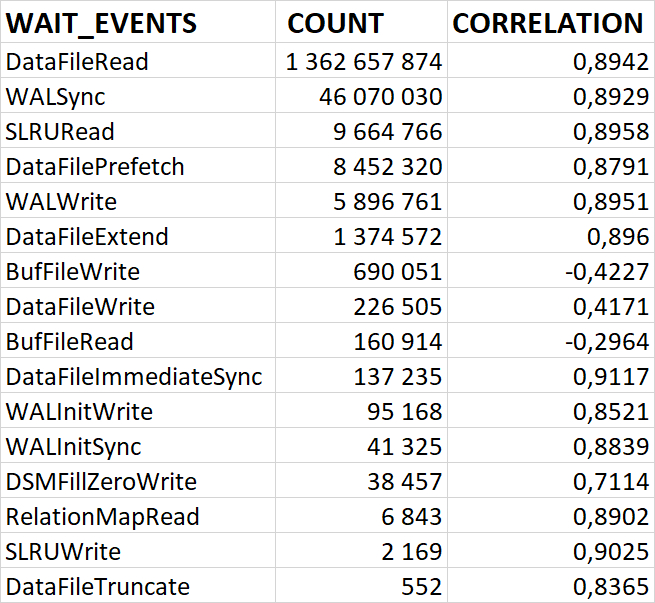
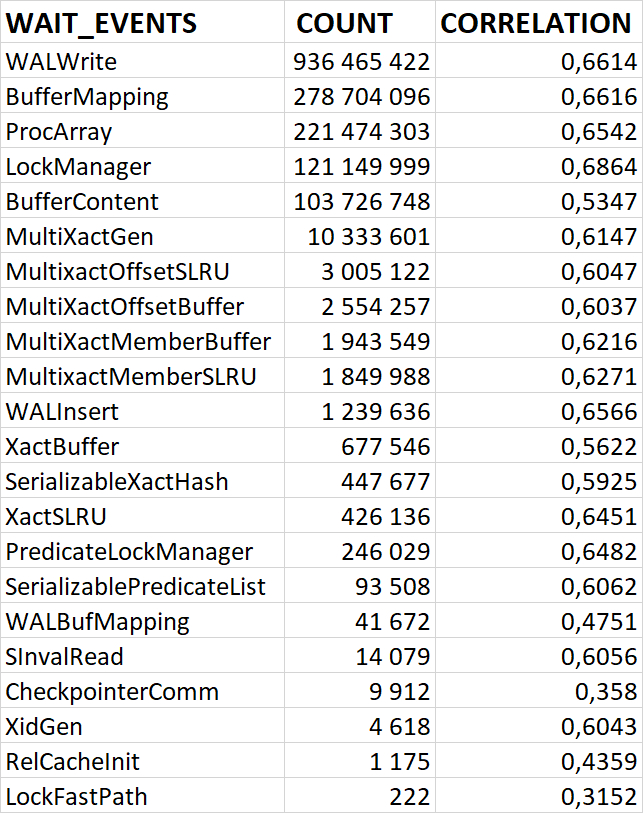
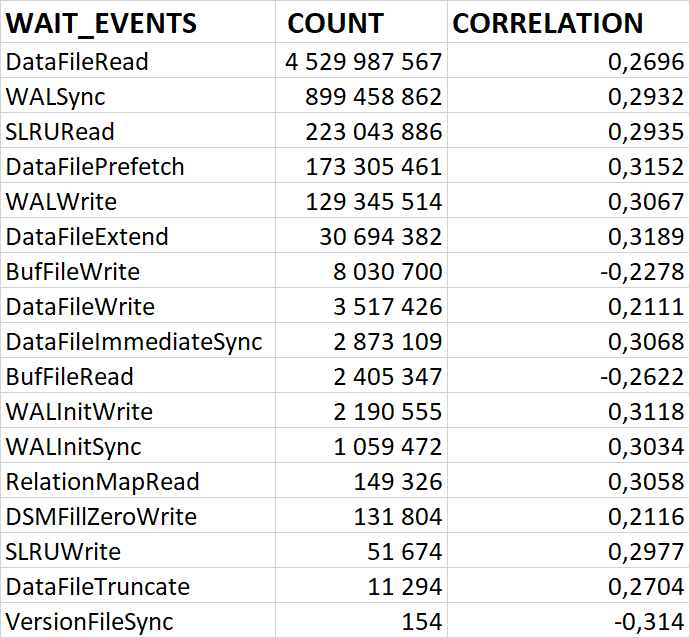
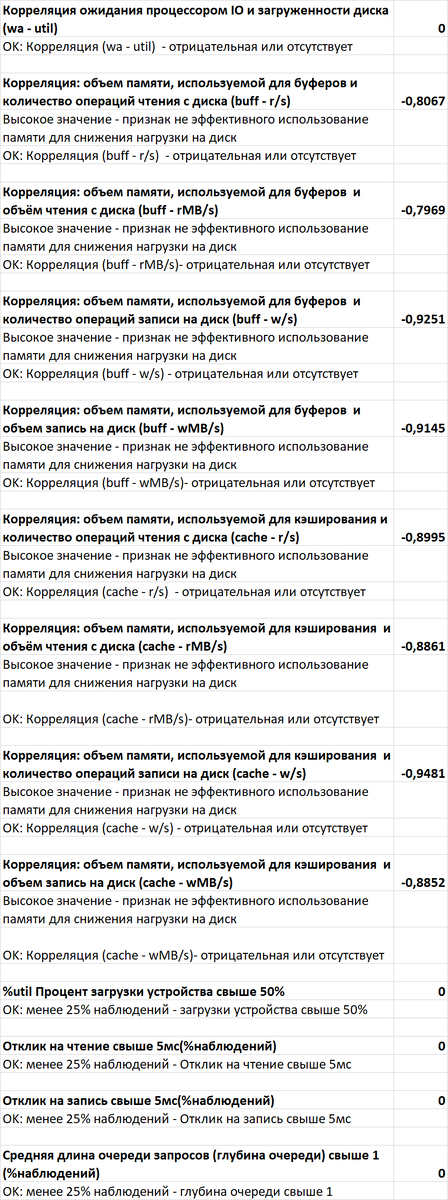
80% ожиданий СУБД вызваны ожиданиями типа LWLock и IO.
Характерные события ожидания типа LWLock
BufferContent: Ожидание при обращении к странице данных в памяти.
BufferMapping: Ожидание при связывании блока данных с буфером в пуле буферов.
CheckpointerComm: Ожидание при управлении запросами fsync.
DynamicSharedMemoryControl: Ожидание при чтении или изменении информации о выделении динамической общей памяти.
LockFastPath: Ожидание при чтении или изменении информации процесса о блокировках по быстрому пути.
LockManager: Ожидание при чтении или изменении информации о «тяжёлых» блокировках.
MultiXactGen: Ожидание при чтении или изменении общего состояния мультитранзакций.
MultiXactMemberBuffer: Ожидание ввода/вывода с SLRU-буфером данных о членах мультитранзакций.
MultixactMemberSLRU: Ожидание при обращении к SLRU-кешу данных о членах мультитранзакций.
MultiXactOffsetBuffer: Ожидание ввода/вывода с SLRU-буфером данных о смещениях мультитранзакций.
MultixactOffsetSLRU: Ожидание при обращении к SLRU-кешу данных о смещениях мультитранзакций.
PredicateLockManager: Ожидание при обращении к информации о предикатных блокировках, используемой сериализуемыми транзакциями.
ProcArray: Ожидание при обращении к общим структурам данных в рамках процесса (например, при получении снимка или чтении идентификатора транзакции в сеансе).
RelCacheInit: Ожидание при чтении или изменении файла инициализации кеша отношения (pg_internal.init).
SerializablePredicateList: Ожидание при обращении к списку предикатных блокировок, удерживаемых сериализуемыми транзакциями.
SerializableXactHash: Ожидание при чтении или изменении информации о сериализуемых транзакциях.
SInvalRead: Ожидание при получении сообщений из общей очереди сообщений аннулирования.
WALBufMapping: Ожидание при замене страницы в буферах WAL.
WALInsert: Ожидание при добавлении записей WAL в буфер в памяти.
WALWrite: Ожидание при записи буферов WAL на диск.
XactBuffer: Ожидание ввода/вывода с SLRU-буфером данных о состоянии транзакций.
XactSLRU: Ожидание при обращении к SLRU-кешу данных о состоянии транзакций.
XidGen: Ожидание при выделении нового идентификатора транзакции.