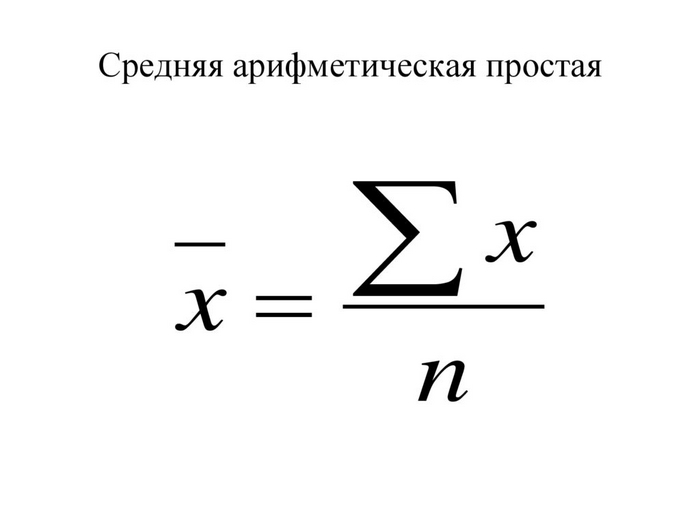Часть 3 - Сценарий нагрузочного тестирования "Heavyweight"
Нужно выбирать
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "Heavyweight"
Тестовый запрос состоит только из выражений SELECT с использованием JOIN ,ORDER BY и математических функций.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
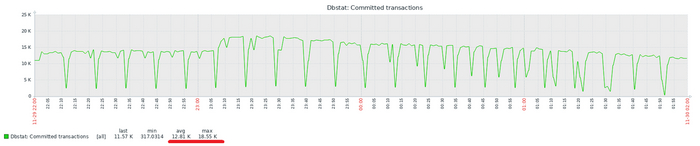
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
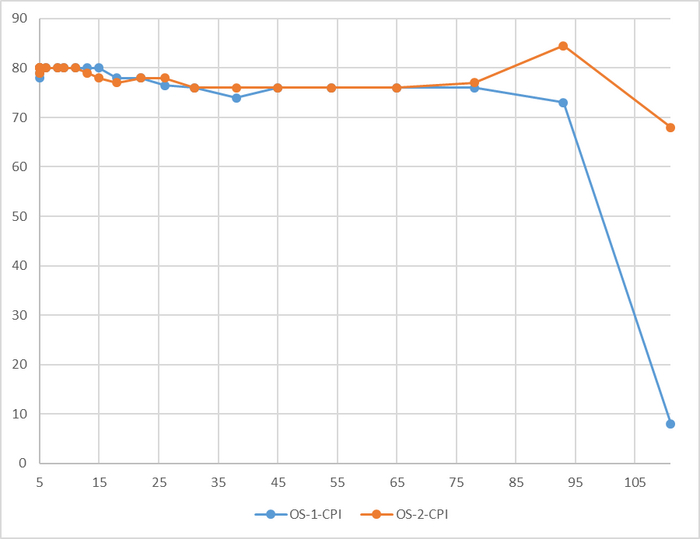
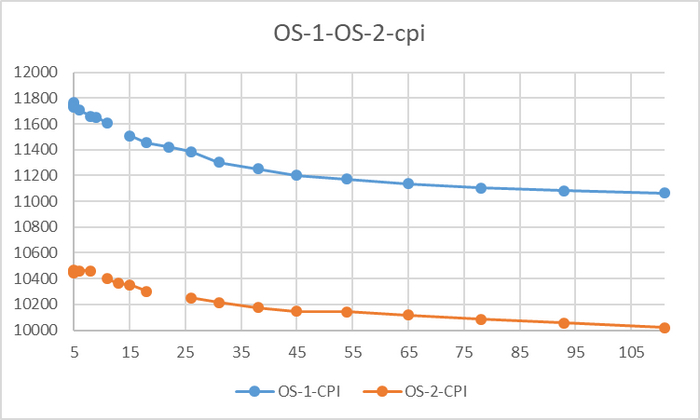
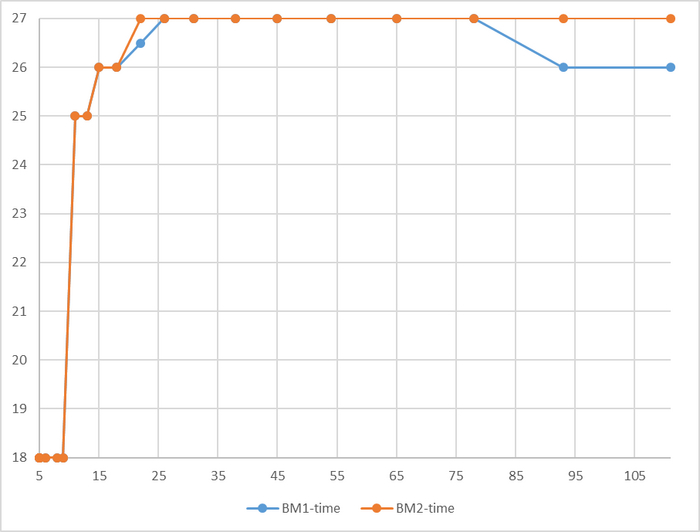
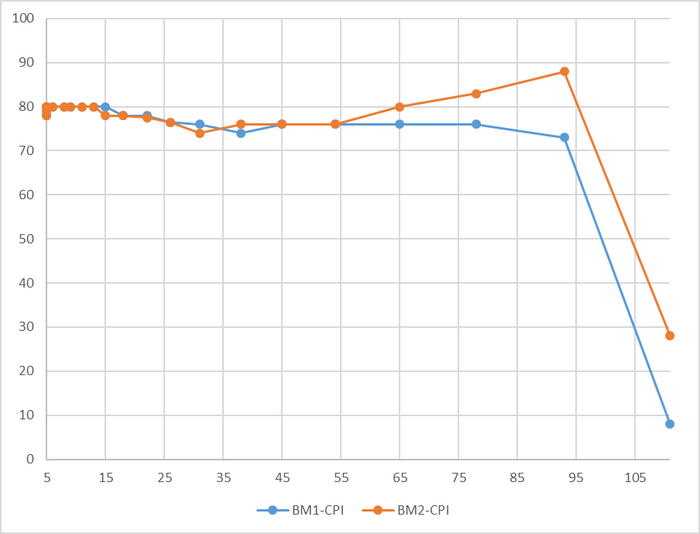
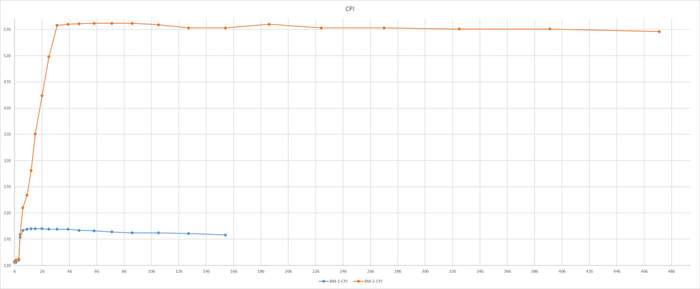
Производительность СУБД
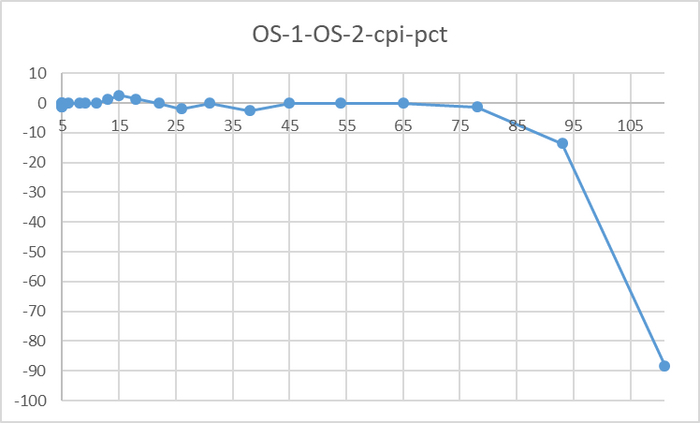
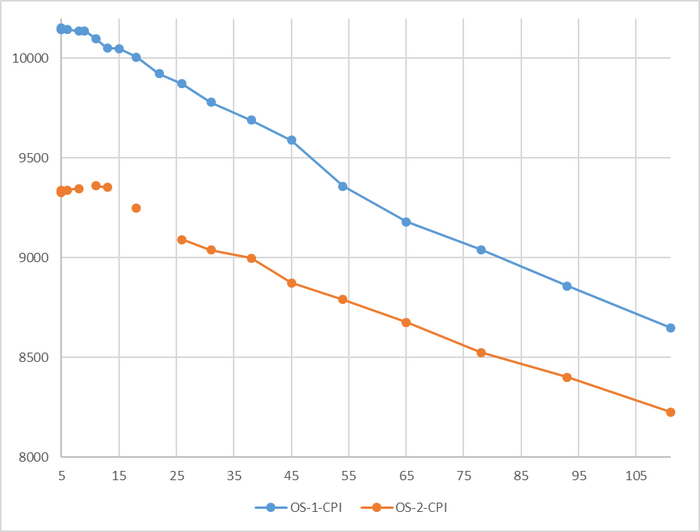
До 78 соединений - разница в производительности не более 3%
Резкий рост относительной разницы производительности после 76 соединений
До 78 соединений - разница в производительности практически отсутствует.
При высокой нагрузке - OS-2 существенно производительнее.
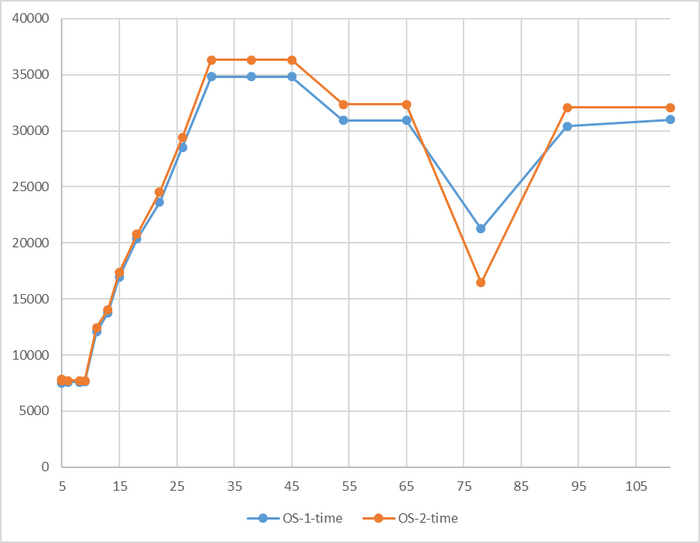
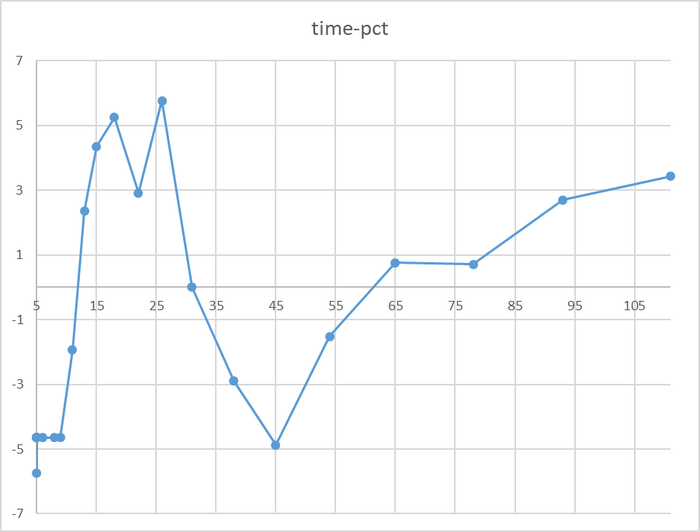
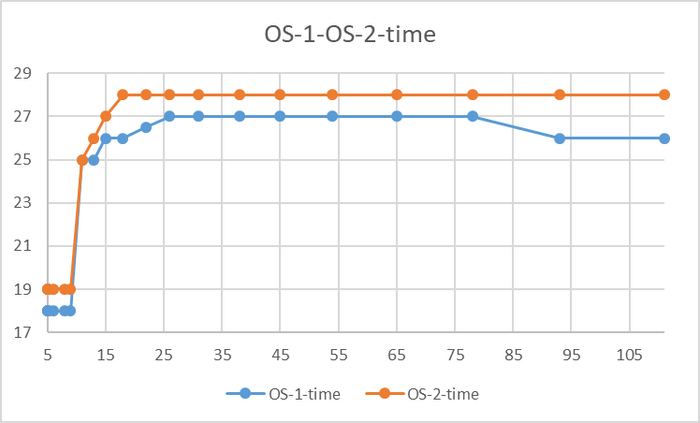
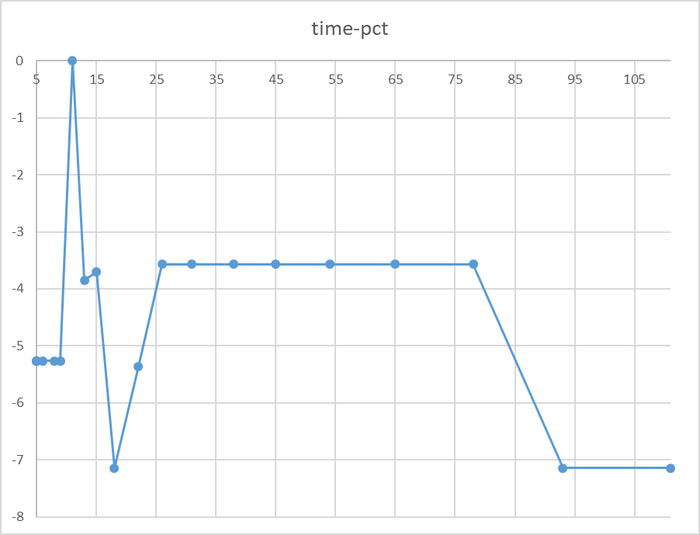
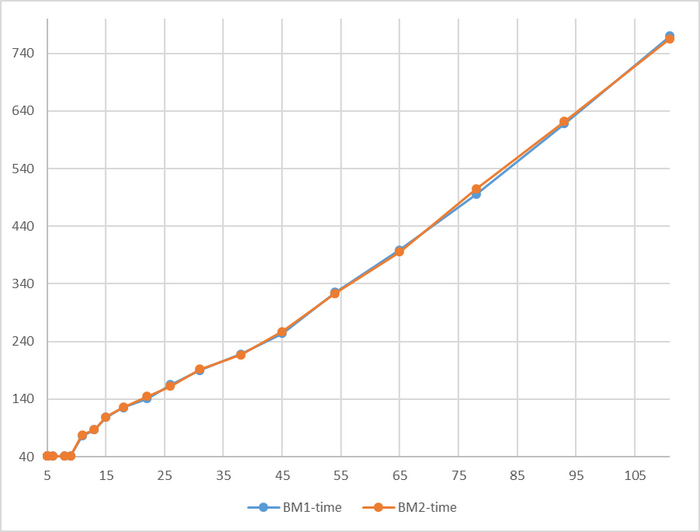
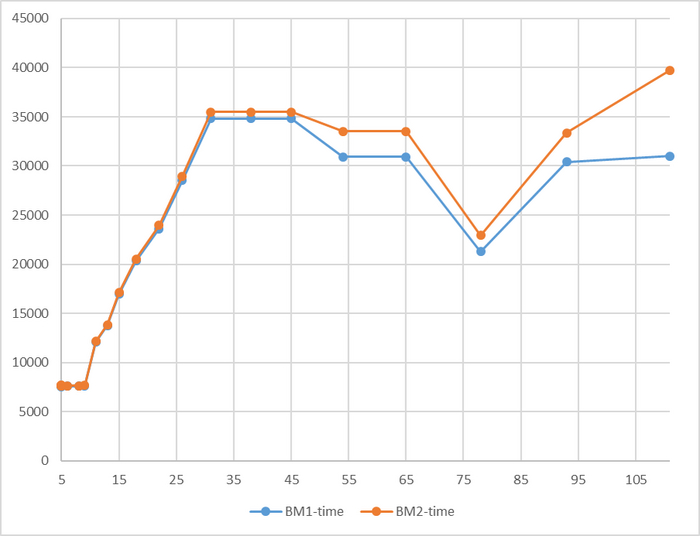
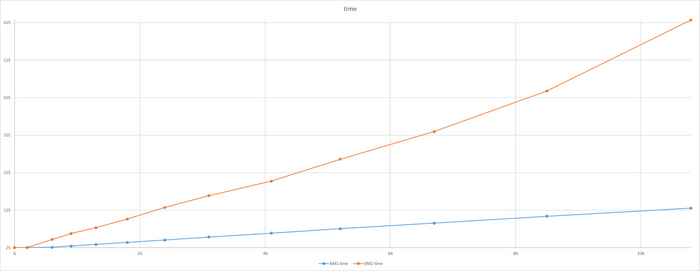
Время выполнения тестового запроса
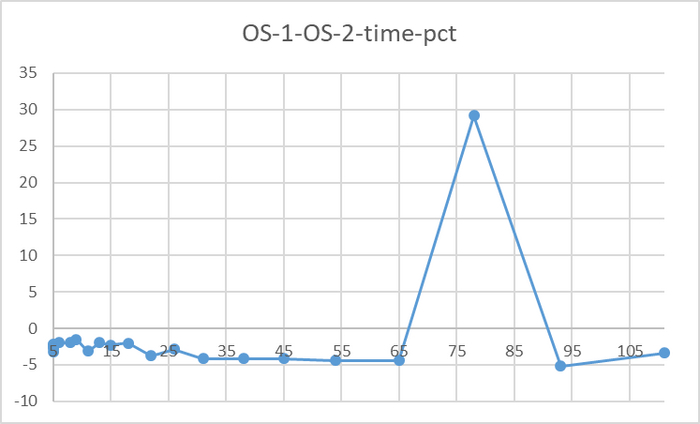
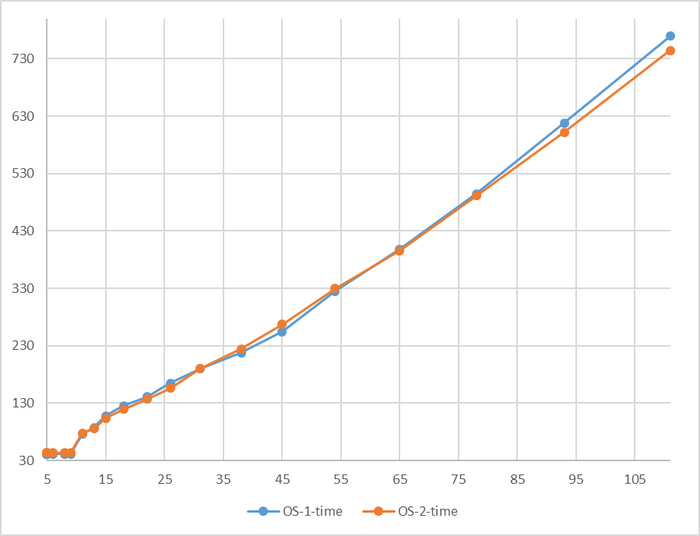
Явная аномалия в районе 78 соединений
Имеется аномалия значений
За исключением аномалии при 78 соединений, относительная разница времени выполнения не превышает 5%.
Итог
Для сценария "Heavyweight", при нагрузке свыше 78 сессий - производительность СУБД развернутой на ОС Linux версии OS-2 превосходит производительность СУБД развернутой на ОС Linux версии OS-1 более чем на 10%.
P.S. Аномальное значение при 78 сессиях нуждается в повторном эксперименте.
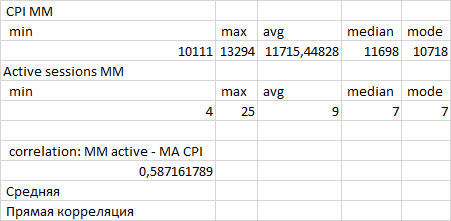
Прямая корреляция между количество активных сессий и производительностью СУБД . Или другими словами - чем выше нагрузка на СУБД , тем выше производительность.
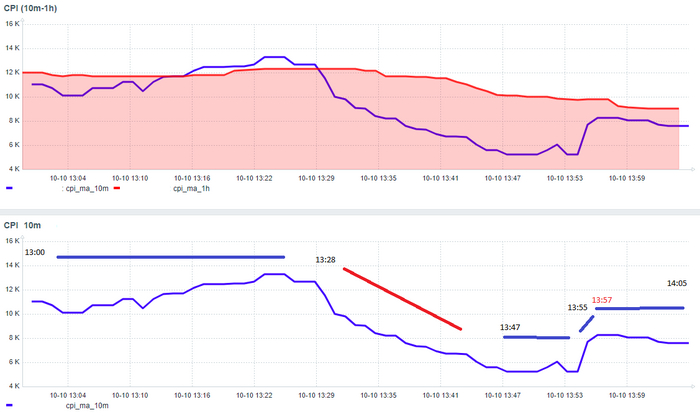
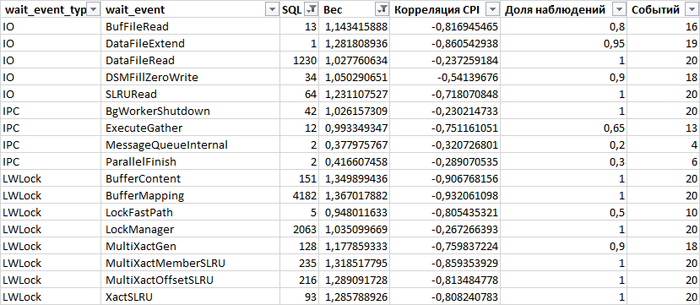
Статистические показатели ожиданий СУБД - корреляция ожиданий и производительности СУБД
Рис.2. Корреляционный анализ ожиданий и производительности 13:00-13:28
Количество пользовательских запросов по которым имеются события ожидания СУБД - минимально.
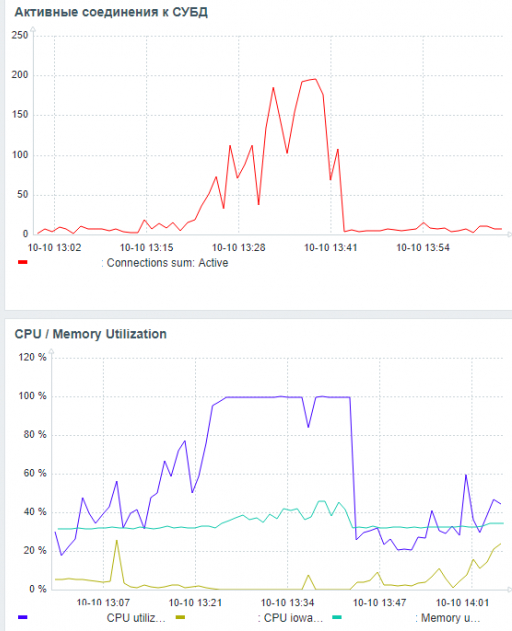
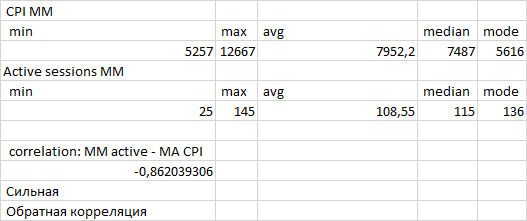
Сильная обратная корреляция - чем выше нагрузка на СУБД тем ниже производительность. Явный признак инцидента производительности СУБД
Статистические показатели ожиданий СУБД - корреляция ожиданий и производительности СУБД
Рис.4. Корреляционный анализ ожиданий и производительности СУБД нисходящего тренда 13:28 - 13:47
Как видно из таблицы - количество ожиданий кардинально увеличилось. Явный признак - имеются серьезные проблемы с производительностью СУБД.
2.Определение наиболее значимой причины деградации производительности СУБД
Из Рис.4 видно, что наибольшая обратная корреляция между событиями ожидания и снижением производительности СУБД имеется для события LWLock / BufferMapping
Рис.5. Ожидание LWLock / BufferMapping
Как видно - количество ожиданий менее чем за 20 минут - весьма существенно.
Итак, первый результат
Первой( но конечно не единственной) причиной деградации производительности СУБД в период 13:28 - 13:47 является - большое количество ожиданий LWLock / BufferMapping при выполнении пользовательских запросов.
Чуть подробнее об ожидании BufferMapping
Ожидание при связывании блока данных с буфером в пуле буферов.
This event occurs when a session is waiting to associate a data block with a buffer in the shared buffer pool.
Context
The shared buffer pool is an PostgreSQL memory area that holds all pages that are or were being used by processes. When a process needs a page, it reads the page into the shared buffer pool. The shared_buffers parameter sets the shared buffer size and reserves a memory area to store the table and index pages. If you change this parameter, make sure to restart the database. For more information, see Shared Buffer Area.
The buffer_mapping wait event occurs in the following scenarios:
A process searches the buffer table for a page and acquires a shared buffer mapping lock.
A process loads a page into the buffer pool and acquires an exclusive buffer mapping lock.
A process removes a page from the pool and acquires an exclusive buffer mapping lock.
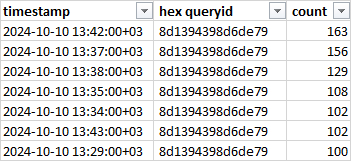
3. Определение запросов с максимальным количество ожиданий
Рис.6. Запросы с ожиданием LWLock / BufferMapping c количество более 100.
Далее, дело техники, используя утилиту pgpro_pwr по queryid, находим проблемный запрос за период 13:30 - 13:50(снимки pgpro_pwr формируются каждые 10 минут).
Запрос передается разработчикам , для анализа .
Дальнейшие события ожидания анализируются схожим образом. Если отсортировать таблицу Рис.4. по количеству пользовательских запросов(более 100) , то можно и нужно сформировать список проблемных запросов для передачи группе разработки на оптимизацию и доработку.
Рис.7. Список ожиданий отсортированный по количеству пользовательских запросов.
Итог
Статистический анализ производительности СУБД позволяет подтвердить наличие деградации производительности не дожидаясь деградации на уровне приложения.
Корреляционный анализ ожиданий и производительности СУБД позволяет быстрее определить корневую причину снижения производительности СУБД и определить список проблемных пользовательских запросов.
P.S.
В настоящее время ведутся работы по разработке и тестированию новой версии инструментария по мониторингу и анализу производительности СУБД PostgreSQL - "Орешник".
Методология статистического анализа производительности СУБД PostgreSQL будет довольно существенно дополнена и доработана.
Часть 2 - Сценарий нагрузочного тестирования "OLTP"
Выбирай сердцем
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "OLTP"
Тестовый запрос состоит только из выражений SELECT - UPDATE.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
Производительность СУБД
Разница производительности от 5-9%
Относительная разница производительности OS-1 и OS-2
Время выполнения тестового запроса
Разница времени выполнения тестового запроса от -5% до 7%
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "OLTP", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 на 5-9% .
Часть 1 - сценарий нагрузочного тестирования "Select only"
Какой Linux выбрать ?
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "Select only"
Тестовые запрос состоит только из выражения SELECT.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
Производительность СУБД
Разница производительности от 10 до 13%
Относительная разница производительности OS-1 и OS-2
Время выполнения тестового запроса
Разница времени выполнения тестового запроса до 7%
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "Select only", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 не менее чем на 10% .
Статья не о сравнении ОС, задача статьи - тестирование методологии сравнения производительности СУБД.
Задача
Имеется 2 виртуальных машины с развернутой СУБД PostgreSQL.
Версия СУБД - одинаковая.
ОС - одинаковая. Гипервизор - один.
Различие - системный диск HDD vs. SSD.
Необходимо количественно определить влияние расположения файлов ОС на производительность СУБД. Т.е. определить разницу в накладных расходах для создания серверного процесса для нового соединения .
Реализация эксперимента - сценарии нагрузки
Для оценки производительности и среднего времени выполнения тестового запроса используются 3 сценария нагрузки:
Select only (условный сценарий WEB): нагрузка в виде запроса .
TPC-B (условный сценарий OLTP): Нагрузка в виде транзакции состоящей из UPDATE-SELECT
Heavyweight (условный сценарий DSS): Нагрузка в виде тяжелого запроса SELECT..JOIN..ORDER BY + вычислительная нагрузка
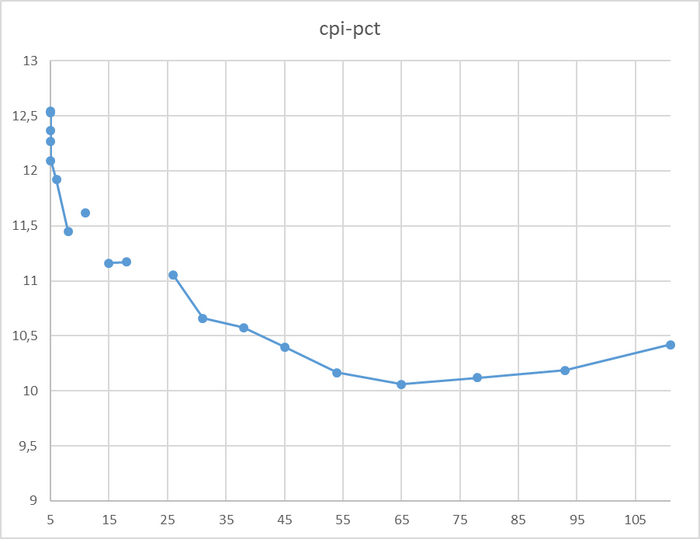
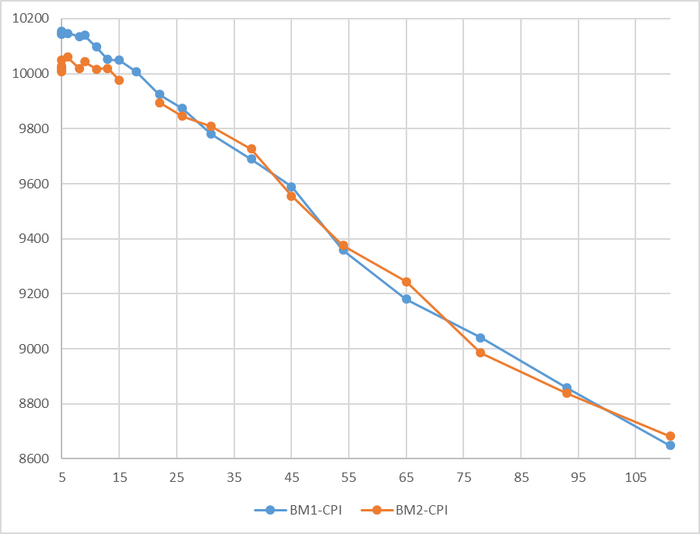
Индекс производительности СУБД(CPI) : операционная скорость
Время выполнения тестового запроса: скользящая медиана с периодом 1 час.
В реальной эксплуатации - применимо с существенными ограничениями.
Проблема
Имеется 2 виртуальные машины в облачном хранилище - версия СУБД одинаковая, гипервизор один , других ВМ в гипервизоре - нет.
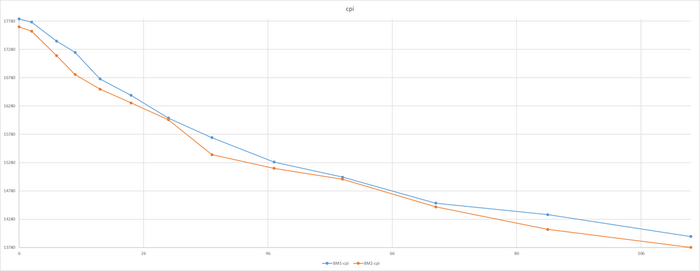
Производительность СУБД
Разница в производительности СУБД не превышает 2.5%
Среднее время выполнения тестового запроса
Разница непрерывно растет и достигает 80%
В результате - производительность СУБД практически не отличается , а среднее время выполнения тестового запроса отличается кардинально. Как такое возможно ?
Причина
Использование при расчета значение mean_exec_time среднего арифметического .
Среднее арифметическое не всегда является идеальным показателем. Например, если ваши данные содержат очень высокие или низкие значения, они могут сильно исказить среднее. В таких случаях рассмотрите использование других статистических мер.
Для иллюстрации проблемы был проведен простой эксперимент
Серия запусков тестового запроса с фиксацией времени выполнения и искусственным выбросом(замедление выполнения) .
Результаты
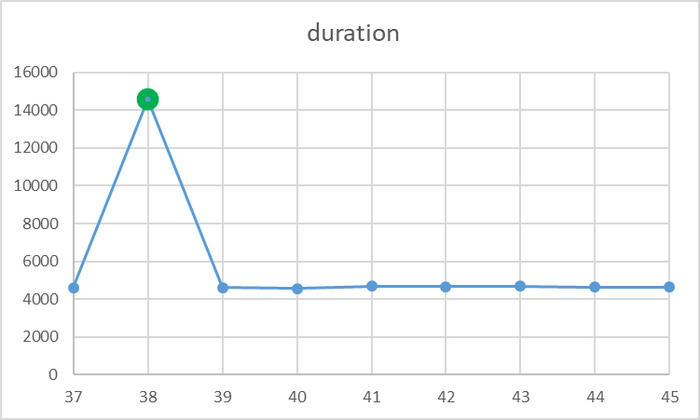
Всего 1(один) выброс
id duration
37 4602
38 14581
39 4610
40 4569
41 4685
42 4666
43 4680
44 4621
45 4637
mean_exec_time = 5651.6708999
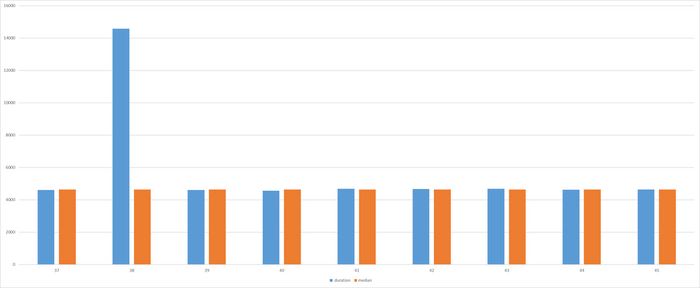
Достаточно всего одного выброса , что бы значение метрики весьма существенно изменилось .
Решение проблемы
Использование в качестве среднего значение - медианы
Медиана — это значение, которое делит упорядоченный набор данных на две равные части. Другими словами, половина значений в наборе данных меньше медианы, а другая половина — больше. Медиана является центральным значением в наборе данных.
В данном эксперименте медиана = 4637 . Данное значение вполне соответствует значению подсказываемому здравым смыслом при анализе результатов наблюдений.
Единичный выброс не влияет на значение медианы
Итог
Разница между значением длительности выполнения тестового запроса и mean_exec_time для штатной работы СУБД составляет от 17 до 19%.
Разница между значением длительности выполнения тестового запроса и медианой для штатной работы СУБД составляет от -1.5 до 1%.
Какое значение использовать для усреднения показателей - очевидно.
В дальнейшем, при анализе производительности, метрика mean_exec_time ( представления типа pg_stat_statments/pgpro_stats) исключается из показателей производительности СУБД.
При проведении анализа производительности СУБД нет задачи оценить стабильность работы( облачная инфраструктура в принципе нестабильна и подвержена существенным влияниям внешних факторов), есть задача оценить производительность СУБД.
Для тестирования использовался именно этот сценарий .
Конфигурация виртуальных машин
ВМ-1
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
CPU = 8
RAM = 15
OC = RED 7.3
ВМ-2
Postgres Pro (enterprise certified) 14.11.3 on x86_64-pc-linux-gnu, compiled by gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516, 64-bit
CPU = 24
RAM = 189
ОС = Astra Linux (Smolensk) 1.6
Итоги теста по сценарию TPC-B
Производительность ВМ-1 существенно выше ВМ-2
Т.е. по итогам данного теста получается - СУБД развёрнутая по шаблону ВМ-1 будет существенно производительнее ?
Что будет , если архитектор примет решение о выборе версии СУБД и запланирует ресурсы инфраструктуры на основании только данного теста ?
Решение проблемы
Одного теста для анализа производительности СУБД и ВМ - недостаточно.
Как было указано в документации:
Однако вы можете легко протестировать и другие сценарии, написав собственные скрипты транзакций.
Что и было сделано.
Для продолжения тестов, был подготовлен сценарий требующий серьезных вычислительных ресурсов - SELECT ... JOIN
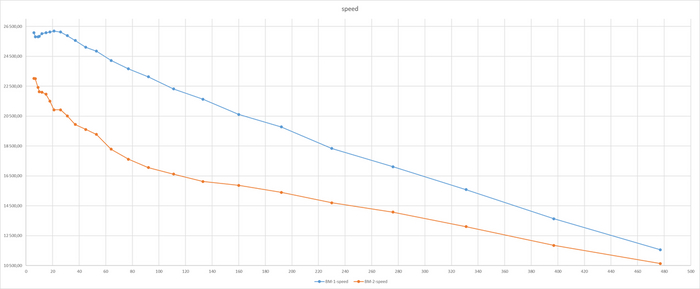
Результат тестирования тяжелого запроса
ВМ-2 СУЩЕСТВЕННО производительнее чем ВМ-1
Все встало на свои места.
ВМ-1 даже не хватило ресурсов при количестве одновременных запросов свыше 160. При этом производительности ВМ-2 существенно выше производительности ВМ-1.
Итог
Нельзя принимать архитектурных решений на основании результатов одного только сценария нагрузочного тестирования
2. Для оценки производительности архитектурного решения по конкретной СУБД необходим комплекс разных сценариев нагрузочного тестирования.
Как минимум:
-Select only: оценка скорости чтения данных из СУБД
-Standard: оценка производительности СУБД в условиях конкуренции за блокировки.
-Heavyweight: оценка производительности СУБД при выполнении тяжелых вычислительных и ресурсоемких операций.
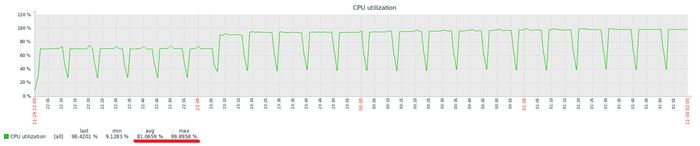
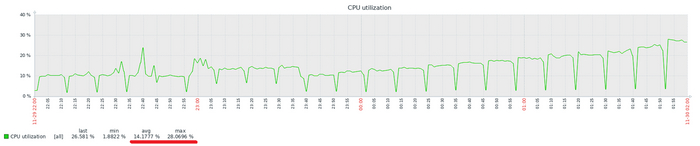
Мониторить утилизацию CPU отдельно — не имеет смысла. Мониторить надо производительность СУБД, в первую очередь.
Рост утилизации CPU — не инцидент. Снижение производительности СУБД и рост утилизации CPU — инцидент.
Высокая утилизация CPU и рост производительности СУБД — показывает эффективное использование предоставленных ресурсов. Низкая утилизация CPU и низкая производительность СУБД в рабочее время — зря потраченные средства.