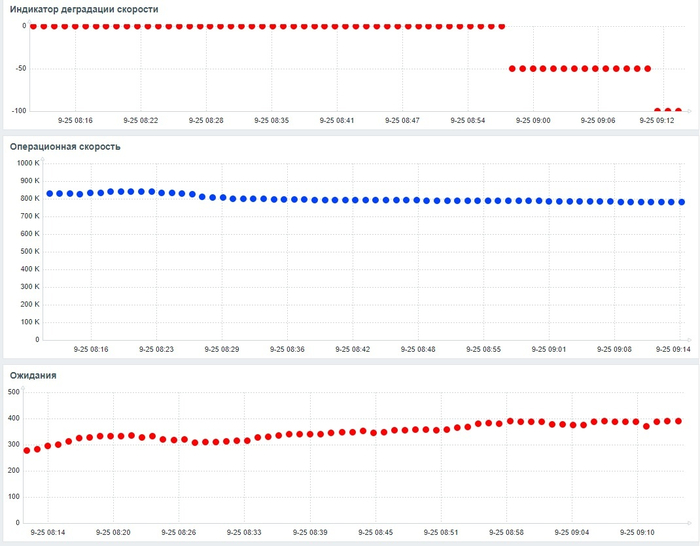
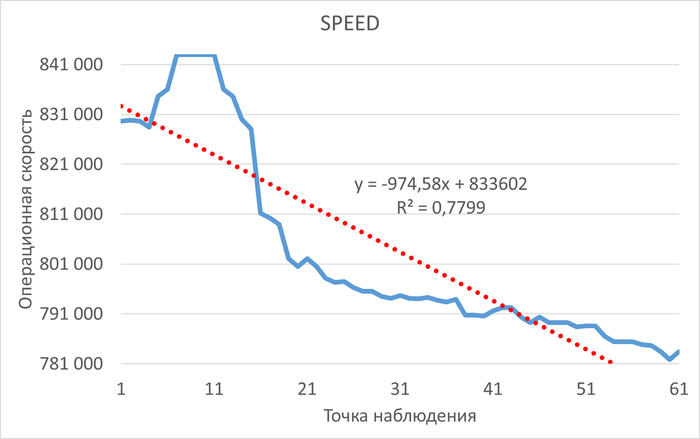
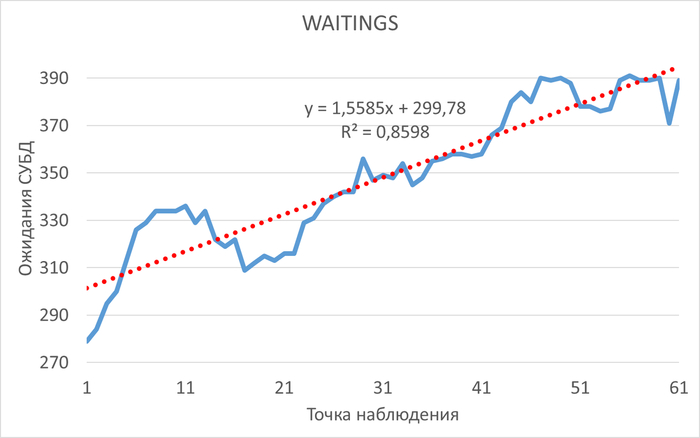
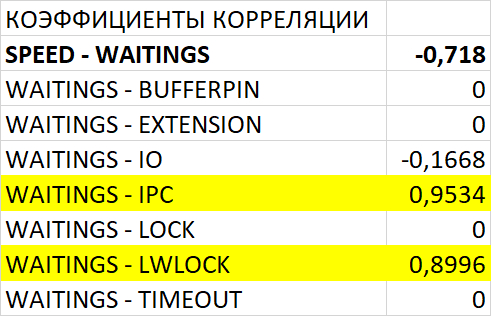
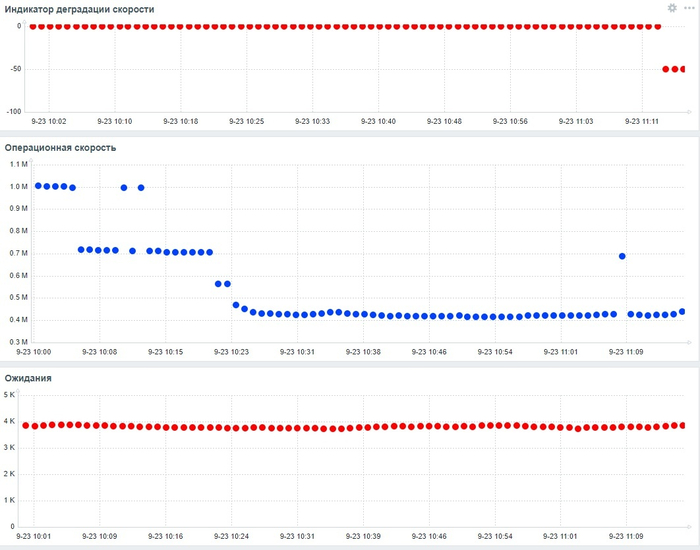
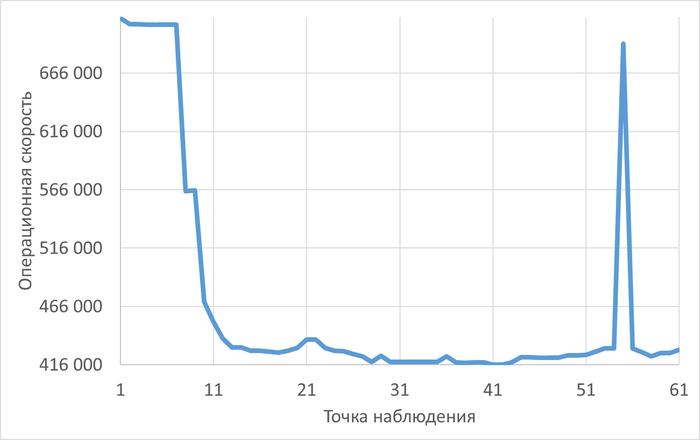
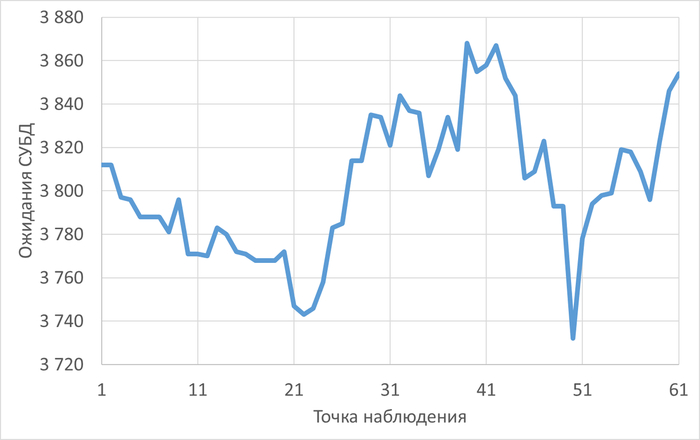
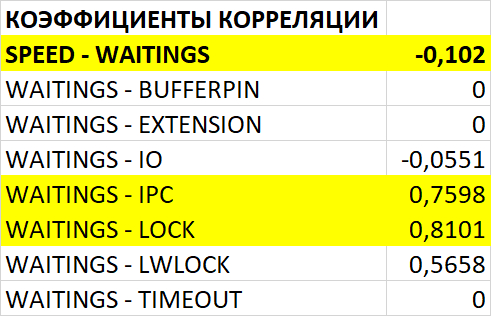
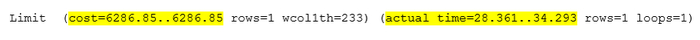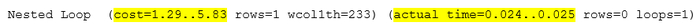Оптимизация SQL-запросов PostgreSQL : IN с большим количеством значений
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Надо жизнь сначала переделывать. Переделав - можно начинать.
Наиболее эффективные подходы заключаются в замене IN на более оптимальные конструкции и использовании специальных техник работы с данными.
ANY(ARRAY[]) вместо IN
Замена IN (...) на = ANY(ARRAY[...]).
Оператор ANY может остановить проверку при первом совпадении.
Когда метод эффективен
Когда список значений очень большой.
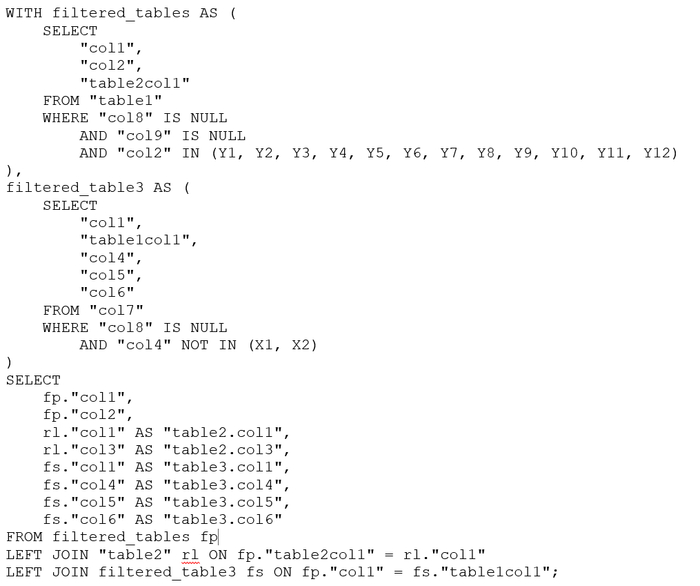
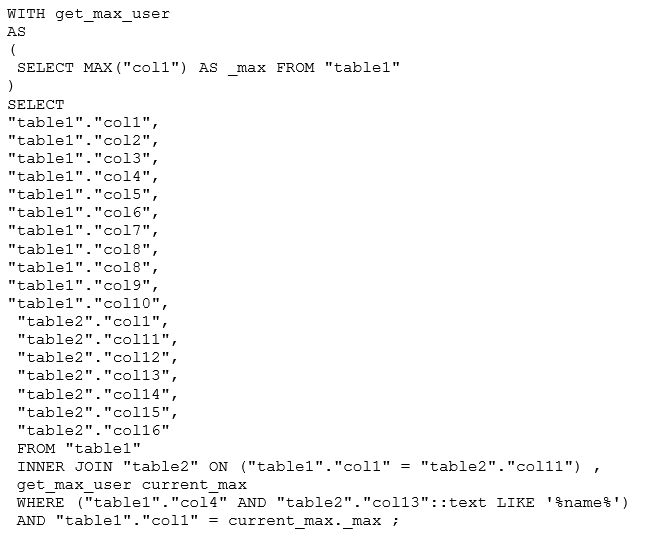
JOIN с виртуальной таблицей
Преобразование списка значений в виртуальную таблицу с помощью VALUES и соединение с основной таблицей.
Когда метод эффективен
Когда список значений можно представить как набор строк.
EXISTS вместо IN для подзапросов
Проверка существования записи с помощью EXISTS.
Запрос прекращает работу, как только найдет первое совпадение.
Когда метод эффективен
Особенно эффективен для коррелированных подзапросов и сценариев с NOT IN (лучше использовать NOT EXISTS)
Материализованные представления
Предварительный расчет и сохранение результатов "тяжелого" запроса, например, с DISTINCT.
Когда метод эффективен
Когда данные изменяются редко, а актуальность в реальном времени не критична.
Нормализация схемы данных
Вынесение часто запрашиваемых полей (например, make, vehicle_year) в отдельные справочные таблицы.
Когда метод эффективен
Когда одни и те же значения (DISTINCT ...) выбираются из таблицы миллионы раз .
💡 Рекомендации по применению методов
Помимо замены оператора, важно рассмотреть более фундаментальные оптимизации.
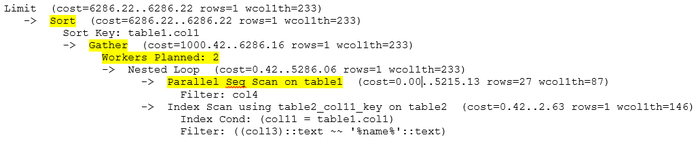
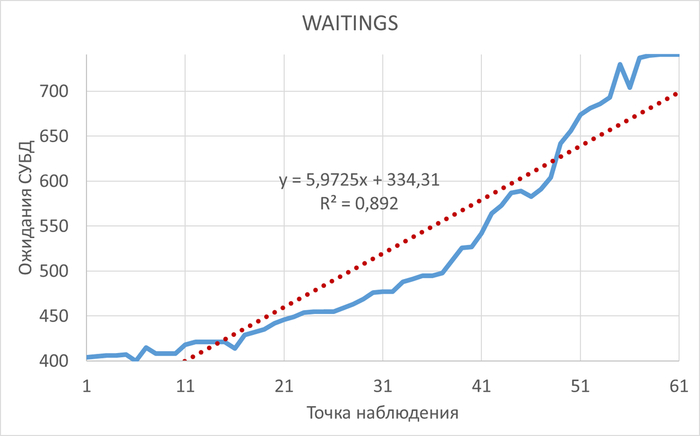
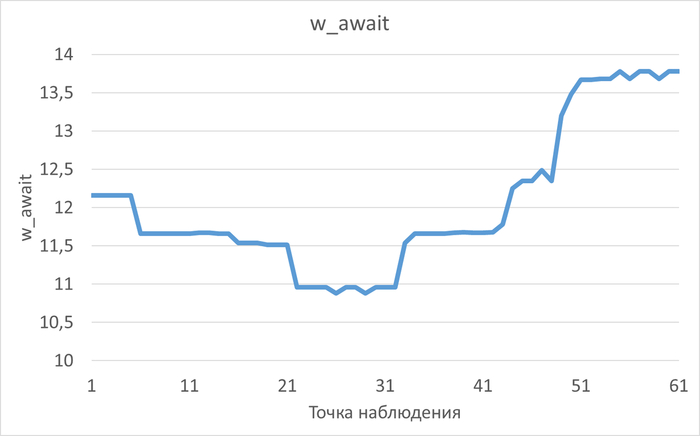
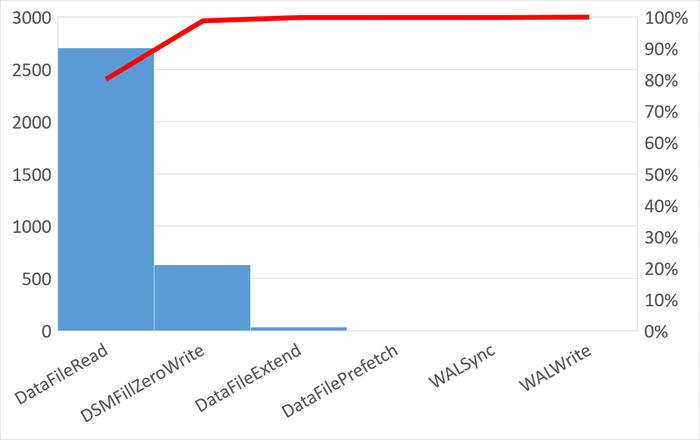
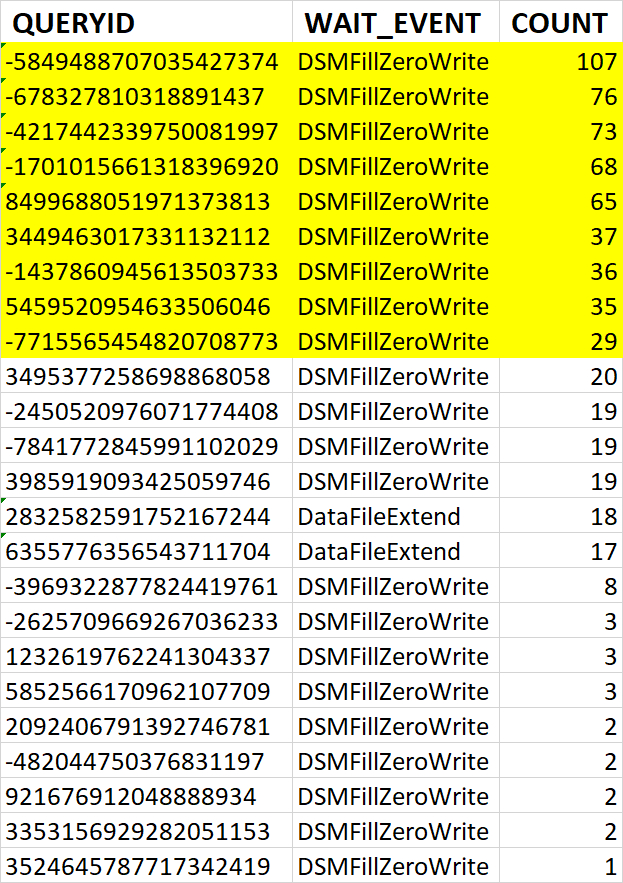
Правильные индексы: Необходимо убедится, что на столбцах, которые участвуют в условиях IN, ANY или JOIN, созданы индексы (чаще всего BTREE). Без индекса даже переписанный запрос будет выполняться медленно .
Анализ плана запроса.
Нормализация данных: Если часто делается запросы вида SELECT DISTINCT column_name к очень большой таблице, это может указывать на недостатки в структуре базы данных. Вынесение возможных значений атрибута (например, марок автомобилей) в отдельную справочную таблицу — кардинальное, но очень эффективное решение .
⚠️ Чего следует избегать
NOT IN с подзапросами: Для сценариев исключения (NOT IN) PostgreSQL может строить неоптимальные планы с подзапросами (SubPlan). Вместо NOT IN практически всегда лучше использовать NOT EXISTS или LEFT JOIN ... WHERE ... IS NULL, которые приводят к более эффективному плану с Hash Anti Join .
DISTINCT без необходимости: Если нужно получить только уникальные значения, а не все строки, использование DISTINCT может создать дополнительную нагрузку. Иногда эту задачу можно решить на уровне приложения или с помощью других методов SQL .