



Уважаемый Масалович А. легенда СВР КГБ. Гений своего времени - перевоплощения не побоюсь сказать А.Э
Уникальный продукт, уникальный купец)))
Уникальный продукт, уникальный купец)))

Он стартовал 6 октября 2019 года и состоит из 13 эпизодов.
Но сейчас ни об этом. Хотел обратить Ваше внимание и обсудить с Вами, одну из самых неоднозначных по моему скромному мнению, персону - Белую Розу или Мистера Чжана.

Что может быть лучше психически больного человека в рамках триллера, правильно два психически больных персонажа, которые ко всему прочему решили схлестнуться в игре на выживание. Должен признать, что данный персонаж заставил заиграть совершенно новыми красками последние сезоны сериала Мистер Робот. Собственно формула успеха уже была проверенна временем. Тому прямым доказательством является личность главного героя сериала, Эллиота Алдерсона, которого сыграл молодой актер Рами Малек. Стоит отметить, что реальный возраст актера, на данный момент 38 лет. Думаю, что для большинства это окажется сюрпризом, ведь в кадре актеру с трудом можно дать 28-29 лет, а то и вообще 25.

Опять же вернемся к Белой Розе, которую или которого, практически никто не смог обойти стороной, без определенных последствий для себя. Встреча с данным персонажем постоянно так или иначе оборачивается катастрофой, в которой либо наносится физический вред здоровью, либо психологический и тут попробуй разберись, какой из этих факторов страшнее.
Белая Роза — хакер, таинственный лидер организации «Тёмная Армия». Он — женщина — трансгендер родом из Китая, одержим идеей управления временем. Когда они встречаются с Эллиотом Алдерсоном, он дает Эллиоту три минуты, чтобы обсудить атаку на Корпорацию Зла(E-Corp). Мотивы Белой Розы не поддаются объяснению, и когда Эллиот спрашивает, почему тот помогает Нахрен Общество, он не отвечает на вопрос, потому что Эллиот превысил лимит выделенных ему трёх минут.
На публике Белая Роза появляется как мужчина, Министр Чжэн из Министерства Государственной Безопасности Китая. В качестве него он принимает агентов ФБР, расследующих взлом электронных резервов Корпорации Зла.
В финальной сцене 9 серии 1 сезона Белая Роза появляется в доме Филиппа Прайса, где обсуждает с ним новости о последнем взломе. В этой сцене он одет в деловой костюм и ведет себя как серьезный мужчина, владелец бизнеса. Примечательно, что у него на запястье часы с минутным таймером, которые издают сигналы во время разговора. Белая Роза поддерживает образ мужчины при общении с Прайсом; во время одного из разговоров по телефону, когда они обсуждают новый проект Корпорации Зла связанный с электронной валютой (E-Coin), он использует мужской голос в образе женщины. Во 2 серии 2 сезона мы узнаем, что Белая Роза живёт в экстравагантно украшенном доме местоположение которого неизвестно.
Во время приема ФБР в доме Белой Розы в Китае, агент Доминик Ди Пьеро, в поисках уборной случайно находит комнату обставленную часами. В этот момент входит Белая Роза и объясняет ей, что хранит так много часов вокруг себя как постоянное напоминание о смертности, о скоротечности жизни. Далее Белая Роза приводит Ди Пьеро в другую комнату, и утверждает, что это спальня его сестры. Он показывает ей традиционные, искусно пошитые китайские платья, при этом продолжая вести диалог о смертности и индивидуальности. На следующий день Ди Пьеро вспоминает об этом в разговоре с коллегой, и упоминает, что у Белой Розы нет сестёр.
Своё скромное повествование о данном персонаже, хотел бы подытожить его же словами, которые нахожу весьма глубокими по смыслу :
«— У каждого хакера есть пристрастие. Вы взламываете людей, я взламываю время.» — Белая Роза.

В общей сложности $315 тыс. заработали участники хакерских соревнований Pwn2Own 2019, проходивших 6-7 ноября в Токио. В ходе соревнований участниками было обнаружено 18 ранее неизвестных уязвимостей, о которых производители затронутых продуктов были сразу же уведомлены. На исправление проблем производителям отведен срок в 90 дней.
Организатором Pwn2Own является Trend Micro Zero Day Initiative (ZDI), а призовой фонд составил $750 тыс. Наибольшую сумму по итогам двух дней ($195 тыс.) выиграла хорошо известная по прошлым соревнованиям команда Fluoroacetate в составе двух человек – Амата Камы (Amat Cama) и Ричарда Чжу (Richard Zhu). По итогам двух дней Pwn2Own Fluoroacetate стала чемпионом уже третий раз подряд.
В первый день соревнований участники Pwn2Own заработали $195 тыс. за эксплуатацию уязвимостей в смарт-телевизорах, маршрутизаторах и смартфонах. Для взлома им было предоставлено 17 различных устройств, в том числе «умный» дисплей Portal и шлем виртуальной реальности Oculus Quest от Facebook. Оба эти устройства участвовали в Pwn2Own впервые.
Участники соревнований осуществили 10 попыток взлома, и большинство из них оказались успешными. Команде Fluoroacetate удалось взломать смарт-телевизоры Sony X800G и Samsung Q60, «умную» аудиоколонку Amazon Echo и смартфон Xiaomi Mi9, а также похитить изображение с Samsung Galaxy S10 через NFC.
Команда Flashback взломала «умные» маршрутизаторы NETGEAR Nighthawk Smart WiFi Router (R6700) и TP-Link AC1750 Smart WiFi Router. Команда F-Secure Labs попыталась взломать маршрутизатор TP-Link и смартфон Xiaomi Mi9, однако попытки оказались успешными только частично.
Во второй день соревнований участники Fluoroacetate смогли выполнить произвольный код на Samsung Galaxy S10, за что получили $50 тыс. Команды Flashback и F-Secure Labs взломали маршрутизатор TP-Link AC1750, получив $20 тыс. каждая. Во второй день F-Secure Labs все-таки удалось взломать Xiaomi Mi9 и заработать $30 тыс.
Инженеры Google неожиданно выпустили Chrome 78.0.3904.87 для Windows, Mac и Linux, где исправлена уязвимость нулевого дня, уже находящаяся под атаками. Проблема получила идентификатор CVE-2019-13720 и представляет собой use-aster-free баг в аудиокомпоненте браузера.
Уязвимость обнаружили специалисты «Лаборатории Касперского», которые уже опубликовали детальный анализ проблемы. Эксперты пишут, что баг используется для установки малвари на компьютеры жертв.
Полная версия: https://xakep.ru/2019/11/01/chrome-0day/Как обновить Google Chrome: https://support.google.com/chrome/answer/95414

https://xakep.ru/2019/10/08/muhstik/
..........
При этом Фремель не ограничился и простой публикацией ключей. Он также выпустил инструмент для дешифровки пострадавшей информации, доступный для скачивания через MEGA. Подробную инструкцию по его использованию можно найти на форуме Bleeping Computer.
https://www.bleepingcomputer.com/forums/t/705604/muhstik-qna...
https://mega.nz/#!O9Jg3QYZ!5Gj8VrBXl4ebp_MaPDPE7JpzqdUaeUa5m...
Делюсь тем что считаю ИМХО интересным, прошу не нужно меня обсуждать и давать мне советы, иначе вы быстро подружитесь с моим игнор листом.
Михаил Коробов и Константин Лопухин (Scrapinghub) «Как собрать датасет из интернета»
Часть 1
Анализ данных предполагает, в первую очередь, наличие этих данных. Первая часть доклада рассказывает о том, что делать, если у вас не имеется готового/стандартного датасета, либо он не соответствует тому, каким должен быть. Наиболее очевидный вариант — скачать данные из интернета. Это можно сделать множеством способов, начиная с сохранения html-страницы и заканчивая Event loop (моделью событийного цикла). Последний основан на параллелизме в JavaScript, что позволяет значительно повысить производительность. В парсинге event loop реализуется с помощью технологии AJAX, утилит вроде Scrapy или любого асинхронного фреймворка.
Извлечение данных из html связано с обходом дерева, который может осуществляться с применением различных техник и технологий. В докладе рассматриваются три «языка» обхода дерева: CSS-селекторы, XPath и DSL. Первые два состоят в довольно тесном родстве и выигрывают за счет своей универсальности и широкой сфере применения. DSL (предметно-ориентированный язык, domain-specific language) для парсинга существует довольно много, и хороши они, в первую очередь, тем, что удобство работы с ним осуществляется благодаря поддержке IDE и валидации со стороны языка программирования.
Для тренировки написания пауков компанией ScrapingHub создан учебный сайт toscrape.com, на примере которого рассматривается парсинг книжного сайта. С помощью chrome-расширения SelectorGadget, которое позволяет генерировать CSS-селекторы, выделяя элементы на странице, можно облегчить написание скрапера.
import scrapy
class BookSpider(scrapy.Spider):
name = 'books'
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
for href in response.css('.product_pod a::attr(href)').extract():
url = response.urljoin(href)
print(url)
Пример без scrapy:
import json
from urllib.parse import urljoin
import requests
from parsel import Selector
index = requests.get('http://books.toscrape.com/')
books = []
for href in Selector(index.text).css('.product_pod a::attr(href)').extract():
url = urljoin(index.url, href)
book_page = requests.get(url)
sel = Selector(book_page.text)
books.append({
'title': sel.css('h1::text').extract_first(),
'price': sel.css('.product_main .price_color::text')extract_first(),
'image': sel.css('#product_gallery img::attr(src)').extract_first()
})
with open('books.json', 'w') as fp:
json.dump(books, fp)
Некоторые сайты сами помогают парсингу с помощью специальных тегов и атрибутов html. Легкость парсинга улучшает SEO сайта, так как при этом обеспечивается большая легкость поиска сайта в сети.
Часть 2
О скорости скачивания страниц, распределении на процессы и способах их координации. При больших объемах выборки данных важно оптимизировать скорость и частоту запросов таким образом, чтобы не положить сайт и не быть заблокированным за бомбардировку автоматическими запросами. Это может быть реализовано путем разбиения на несколько процессов: например, разделив между ними url-ы, чтобы в рамках одного процесса осуществлялся парсинг одного сайта. Еще один вариант — общая очередь, куда помещаются запросы и достаются по мере необходимости.
Какие существуют варианты хранения полученных данных? Можно извлекать информацию сразу, либо сохранять HTML-страницы для последующей обработки в исходном (около 100КБ) или сжатом (15 КБ) размере. Порядок обхода сайта для извлечения данных зависит от его объема и структуры. Большинство современных сайтов представляют собой весьма сложные конфигурации большого числа страниц со ссылками друг на друга, напоминающие паутину. Две стандартные стратегии обхода: в глубину и в ширину. Плюсы и минусы обхода в глубину:
небольшой размер очереди запросов
удобен для краулера одного сайта
может не подойти для обхода всех ссылок (т.к. глубина может быть очень боьлшой или бесконечной)
Особенности в ширину:
подходит для обхода всех ссылок на сайте
большой размер очереди
реальная глубина — 2-4
возможные проблемы глубины в графе ссылок
Вторая часть доклада посвящена примерам ресурсов, предоставляющих готовые датасеты, собранные со всего интернета. В базе данных Common Crawl, например, хранится около 300 ТБ информации, которая обновляется каждый месяц. Сервис Web Data Commons извлекает из Common Crawl структурированные данные.
Дмитрий Сергеев (ZeptoLab) «Написание пауков, или что делать, когда тебя вычисляют по IP»
Как вести себя, если при сборе данных сервер блокирует ваши автоматические запросы, выдавая ошибки 403, 404, 503 и так далее? Во-первых, нужно запастись терпением и пожертвовать частотой отправки запросов. Ни один уважающий себя сервер не потерпит бесцеремонной продолжительной бомбардировки автоматическими запросами. Докладчик столкнулся с этим лично, проводя на досуге исследование популярности мемов на одном из популярных информационных ресурсов. Будучи заблокированным по IP, он написал письмо в техподдержку с просьбой разбанить его, на что получил автоматический ответ о разблокировке. Подумав, что, если ему отвечает автомат, то и просить о разблокировке можно автоматически, он написал бота, который при каждом бане отправлял поддержке письмо с текущим IP и слезной просьбой о разбане. Автоматы переписывались всю ночь, в течение которой докладчик выяснил, что время ожидания разбана растет экспоненциально.
Постепенно он учился быть похожим на человека не нарушая трех законов робототехники имитируя браузер: ставя временны′е заглушки перед запросами (при заполнении форм, кликах на кнопки, переходе по страницам, параллельных запросах и т.д.):
time.sleep(3)
генерируя случайные юзер-агенты:
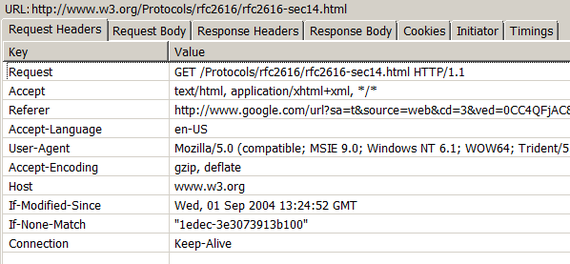
и используя Tor для многоуровневой переадресации:
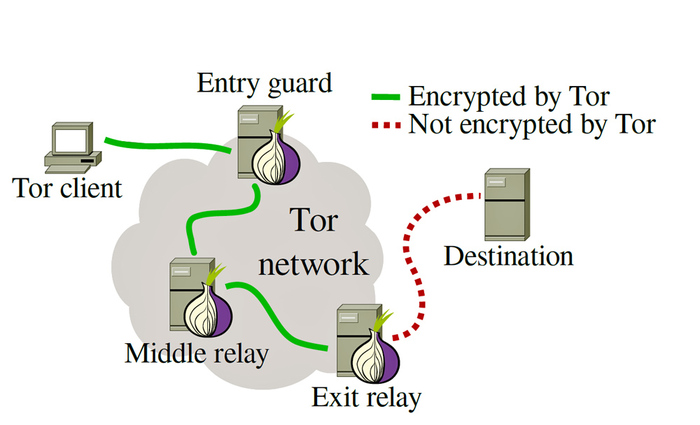
Комбинация этих методов позволяет достичь желаемого объема полученной информации без потери времени на баны и ожидание разблокировки.
Пример
Пример кода, который использует генератор хэдеров и тор для определения текущего IP-адреса:
import os
import socket
import requests
import time
import socks
import stem.process
from stem import Signal
from stem.control import Controller
from user_agent import generate_user_agent
current_time = lambda: int(round(time.time()))
class Network:
def switch_ip(self):
self.controller.signal(Signal.NEWNYM)
print("Switching IP. Waiting.")
t = current_time()
time.sleep(self.controller.get_newnym_wait())
print("{0}s gone".format(current_time() - t))
def print_bootstrap_lines(self, line):
print(line)
def init_tor(self, password='supersafe', log_handler=None):
self.tor_process = None
self.controller = None
try:
self.tor_process = stem.process.launch_tor_with_config(
tor_cmd=self.tor_path,
config=self.tor_config,
init_msg_handler=log_handler
)
self.controller = Controller.from_port(port=self.SOCKS_PORT + 1)
self.controller.authenticate(password)
except:
if self.tor_process is not None:
self.tor_process.terminate()
if self.controller is not None:
self.controller.close()
raise RuntimeError('Failed to initialize Tor')
socket.socket = self.proxySocket
def kill_tor(self):
print('Killing Tor process')
if self.tor_process is not None:
self.tor_process.kill()
if self.controller is not None:
self.controller.close()
def __init__(self):
# путь к директории файлов браузера Tor. В данном случае, директория для OS X
TOR_DIR = '/Applications/TorBrowser.app/Contents/Resources/TorBrowser/Tor/'
PASS_HASH = '16:DEBBA657C88BA8D060A5FDD014BD42DB7B5B736C0C248422F37C46B930'
IP_ADDRESS = '127.0.0.1'
self.SOCKS_PORT = 9150
self.tor_config = {
'SocksPort': str(self.SOCKS_PORT),
'ControlPort': str(self.SOCKS_PORT + 1),
'HashedControlPassword': PASS_HASH,
'GeoIPFile': os.path.join(TOR_DIR, 'geoip'),
'GeoIPv6File': os.path.join(TOR_DIR, 'geoip6')
}
self.tor_path = os.path.join(TOR_DIR, 'tor')
# Setup proxy
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, IP_ADDRESS, self.SOCKS_PORT)
self.nonProxySocket = socket.socket
self.proxySocket = socks.socksocket
def main():
try:
network = Network()
network.init_tor('supersafe', network.print_bootstrap_lines)
url = 'http://checkip.amazonaws.com/'
headers = {'User-Agent': generate_user_agent()}
req = requests.get(url, headers=headers)
print(req.content)
network.switch_ip()
req = requests.get(url, headers=headers)
print(req.content)
finally:
network.kill_tor()
if __name__ == "__main__":
main()
P.S. извинения мои за то что спамлю в ленту по сути и вот почему
К сожалению, Ваш пост «Всё о парсинге сайтов на Python» удален. Причина: запрещено размещение поста, единственным содержанием которого является ссылка
А сейчас наверное из за игнора БМа пост удалят? нет?
Делюсь тем что считаю ИМХО интересным, прошу не нужно меня обсуждать и давать мне советы, иначе вы быстро подружитесь с моим игнор листом.
Михаил Коробов и Константин Лопухин (Scrapinghub) «Как собрать датасет из интернета»
Часть 1
Анализ данных предполагает, в первую очередь, наличие этих данных. Первая часть доклада рассказывает о том, что делать, если у вас не имеется готового/стандартного датасета, либо он не соответствует тому, каким должен быть. Наиболее очевидный вариант — скачать данные из интернета. Это можно сделать множеством способов, начиная с сохранения html-страницы и заканчивая Event loop (моделью событийного цикла). Последний основан на параллелизме в JavaScript, что позволяет значительно повысить производительность. В парсинге event loop реализуется с помощью технологии AJAX, утилит вроде Scrapy или любого асинхронного фреймворка.
Извлечение данных из html связано с обходом дерева, который может осуществляться с применением различных техник и технологий. В докладе рассматриваются три «языка» обхода дерева: CSS-селекторы, XPath и DSL. Первые два состоят в довольно тесном родстве и выигрывают за счет своей универсальности и широкой сфере применения. DSL (предметно-ориентированный язык, domain-specific language) для парсинга существует довольно много, и хороши они, в первую очередь, тем, что удобство работы с ним осуществляется благодаря поддержке IDE и валидации со стороны языка программирования.
Для тренировки написания пауков компанией ScrapingHub создан учебный сайт toscrape.com, на примере которого рассматривается парсинг книжного сайта. С помощью chrome-расширения SelectorGadget, которое позволяет генерировать CSS-селекторы, выделяя элементы на странице, можно облегчить написание скрапера.
Чтобы пользователи могли запретить Google Analytics собирать информацию о себе при посещении веб-сайтов, мы создали расширение для браузера, блокирующее скрипты Google Analytics (ga.js, analytics.js, dc.js).
https://chrome.google.com/webstore/detail/google-analytics-o...

P.S. Чтобы большой брат не следил за нами!

