В профессиональном сообществе Active Directory часто рассматривается как наиболее проблемный элемент с точки зрения информационной безопасности. Многие администраторы и ИБ-специалисты скептически относятся к надежности этой службы, а некоторые эксперты рекомендуют минимизировать ее использование. Однако практика показывает, что Active Directory может функционировать как защищенная и устойчивая система, если организация готова отойти от устаревших подходов к администрированию и инвестировать ресурсы в современное проектирование архитектуры, а не полагаться исключительно на наложенные средства защиты.
В данном материале детально разбираются принципы построения безопасной инфраструктуры, классификация векторов атак и методы «закаливания» (hardening) среды. Важно понимать, что безопасность AD - это не разовое действие, а непрерывный процесс управления конфигурациями и правами доступа.
Многогранность экосистемы Active Directory
Когда специалисты говорят о «небезопасной AD», они чаще всего подразумевают Active Directory Domain Services (ADDS) - классическую службу каталогов, базирующуюся на протоколе Kerberos и групповых политиках. Нередко уязвимости привносит и служба сертификации (ADCS), реализующая инфраструктуру открытых ключей (PKI), ошибки в настройке которой могут стать критическими для безопасности периметра. Однако семейство Windows Server включает ряд других служб, понимание которых необходимо для комплексной защиты.
Первый важный компонент - Active Directory Rights Management Service (ADRMS). Это инструмент криптографической защиты цифрового контента (документов, электронной почты). Хотя в локальных инсталляциях он используется редко, именно он стал технологическим фундаментом для облачного решения Microsoft Purview Information Protection. Влияние ADRMS на безопасность инфраструктуры минимально, за исключением специфических сценариев социальной инженерии.
Второй компонент - Active Directory Lightweight Directory Services (ADLDS), ранее известный как ADAM. Это LDAP-совместимая служба, использующая механизмы репликации ADDS, но лишенная функций членства компьютеров, поддержки Kerberos и групповых политик. ADLDS обладает гибко настраиваемой схемой и может существенно повысить уровень безопасности. Например, она позволяет создавать изолированные метакаталоги для сервисов в демилитаризованной зоне (DMZ), исключая необходимость прямых запросов к производственной AD из недоверенных сегментов сети.
Третий компонент - Active Directory Federation Services (ADFS). Это провайдер идентификации, поддерживающий современные протоколы SAML и OpenID Connect. Грамотно настроенная ферма ADFS усиливает безопасность при интеграции с веб-приложениями. Однако ошибки в конфигурации ADFS, особенно при публикации внешних приложений или интеграции с Entra ID, создают критические бреши в защите.
Фундаментальные проблемы безопасности и архитектурные ограничения
Сложившаяся репутация Active Directory как уязвимой системы обусловлена историческим контекстом. Многие архитектурные решения Microsoft, заложенные десятилетия назад, диктовали определенный путь развития, где приоритет отдавался обратной совместимости и удобству пользователей в ущерб безопасности.
При проектировании защищенной среды необходимо учитывать неизменные характеристики Active Directory:
Управление правами. Принципалы (пользователи, группы) внутри AD могут обладать правами на модификацию самой директории. Это создает технологическую базу для эскалации привилегий.
Роль контроллера домена (DC). Каждый контроллер обладает собственной машинной идентичностью, но не имеет изолированной базы данных безопасности. Компрометация одного DC равносильна компрометации всего домена.
Сложность репликации. Механизм синхронизации копий базы данных между контроллерами открывает сотни векторов атак - от DoS-атак на службу репликации до внедрения вредоносных объектов, которые распространяются по всему лесу.
DNS и саморегистрация. Интегрированный DNS допускает саморегистрацию узлов без строгой проверки, что делает возможным спуфинг имен и атаки «человек посередине» (MitM).
Устаревшая криптография. Поддержка протоколов NTLM и Kerberos RC4, оставшаяся со времен миграции с NT-доменов, делает возможными такие атаки, как overpass-the-hash.
Векторы атак: классификация угроз
Злоумышленники редко используют сложные эксплойты нулевого дня для взлома AD. Чаще всего они эксплуатируют штатный функционал системы. База знаний MITRE ATT&CK классифицирует тактики атакующих, основываясь на трех базовых функциях Active Directory:
Функция поиска (Lookup). Предоставление информации по протоколу LDAP. Используется злоумышленниками на этапе разведки (Reconnaissance) для построения карты сети, поиска привилегированных групп и уязвимых целей.
Функция аутентификации. Механизмы проверки подлинности (Kerberos/NTLM) становятся мишенью для кражи учетных данных (Credential Access) и горизонтального перемещения внутри сети (Lateral Movement).
Функция конфигурации. Групповые политики и скрипты входа используются для выполнения вредоносного кода (Execution) и закрепления присутствия в системе (Persistence).
Ключевая проблема заключается в том, что Active Directory не является системой управления идентификацией (IDM) или управления доступом (IAM) в современном понимании этих терминов. Попытки возложить на нее несвойственные функции без дополнительных средств контроля приводят к снижению уровня защищенности.
Принципы современного дизайна инфраструктуры
Требования к ИТ-инфраструктуре кардинально изменились по сравнению с концом 1990-х годов. Если раньше ключевым фактором была автономность локальных офисов при нестабильных каналах связи, то сегодня приоритеты сместились в сторону облачных интеграций и мобильности.
Современный дизайн Active Directory должен учитывать гибридные сценарии работы. Большинство входов в систему теперь происходит через облачные провайдеры (например, Entra ID), которые синхронизируются с наземной AD. Это снижает зависимость от локальных контроллеров, но повышает требования к мониторингу каналов синхронизации.
Улучшение качества каналов связи позволяет упростить топологию лесов. Консолидация ресурсов и отказ от сложной структуры сайтов не только упрощает администрирование, но и сокращает поверхность атаки.
Топология доменов и стратегии восстановления
Существует прямая корреляция между сложностью сетевой топологии и уровнем безопасности. Многодоменные леса Active Directory представляют собой значительный риск. Каждый дополнительный домен увеличивает число потенциальных точек входа для атакующего. В модели безопасности AD компрометация одного домена в лесу фактически означает компрометацию всего леса, так как границы безопасности проходят по границе леса, а не домена.
Особенно остро проблема многодоменной структуры проявляется в сценариях аварийного восстановления (Disaster Recovery). При атаке вируса-шифровальщика восстановление однодоменного леса сводится к восстановлению одного контроллера из бэкапа. В многодоменной среде требуется сложная, синхронизированная процедура восстановления всех доменов, описанная в 50-страничных руководствах Microsoft. Малейшая ошибка в последовательности действий может привести к полной неработоспособности инфраструктуры.
Следует отказаться от практики создания отдельных доменов для филиалов или департаментов. Сегментация должна выполняться на уровне организационных единиц (OU) с делегированием прав. Использование отдельных лесов оправдано только в специфических случаях: для создания зон повышенной безопасности (Red Forest) или изоляции небезопасных сред (например, DMZ).
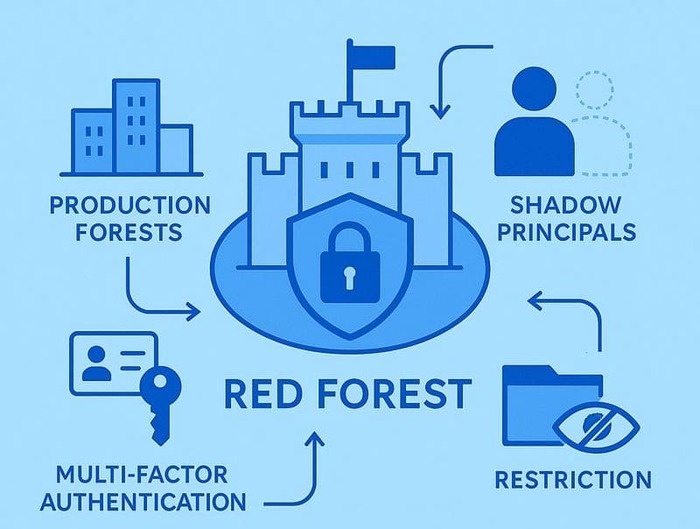
Концепция Red Forest (ESAE) для защиты привилегий
Для защиты критически важных административных учетных данных наиболее эффективной считается архитектура Red Forest (или ESAE - Enhanced Security Admin Environment). Это выделенный, изолированный лес Active Directory, предназначенный исключительно для управления производственными лесами.
В этой модели административные учетные записи хранятся в защищенном лесу, которому доверяют рабочие леса (отношение одностороннего доверия). Это исключает возможность кражи привилегированных паролей на скомпрометированных рабочих станциях. Для доступа в Red Forest обязательно использование строгой многофакторной аутентификации (смарт-карты, аппаратные токены).
Важным аспектом является использование «теневых принципалов» (shadow principals) для назначения прав, что позволяет управлять доступом без создания постоянных учетных записей в целевых доменах. Также необходимо жестко ограничить права группы Authenticated Users внутри Red Forest, запретив чтение каталога, чтобы предотвратить разведку со стороны потенциального инсайдера или злоумышленника, преодолевшего периметр.
Ограничение видимости и противодействие разведке
Стандартные настройки Active Directory предоставляют любому аутентифицированному пользователю избыточные права на чтение информации в каталоге. Это позволяет атакующим легко собирать данные о структуре сети, списке администраторов и сервисных учетных записях.
Основным источником этой проблемы является группа Pre-Windows 2000 Compatible Access. В современных средах членство группы Authenticated Users в этой группе является атавизмом. Рекомендуется провести аудит и удалить из неё всех пользователей, оставив (при необходимости) только конкретные сервисные аккаунты, использующие устаревшее ПО.
Дальнейшее усиление безопасности (Hardening) подразумевает ограничение видимости критических атрибутов. Рядовые сотрудники не должны иметь возможность просматривать состав групп администраторов, свойства объектов в привилегированных OU или служебные разделы конфигурации. Для проверки текущего состояния безопасности и выявления скрытых векторов атак рекомендуется использовать специализированные инструменты аудита, такие как Purple Knight или PingCastle.
Заключение
Обеспечение безопасности Active Directory требует системного подхода, выходящего за рамки простой установки обновлений. Ключ к защите лежит в плоскости архитектуры: упрощение топологии, переход к однодоменным лесам, внедрение модели административного эшелонирования (Tiering) и изоляция привилегий. Отказ от настроек по умолчанию в пользу принципа минимальных привилегий и ограничение видимости данных превращают AD из уязвимого места в надежный фундамент корпоративной ИТ-инфраструктуры.