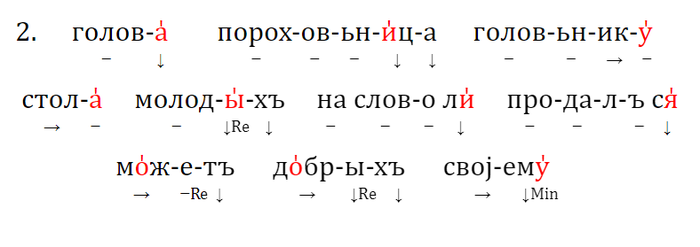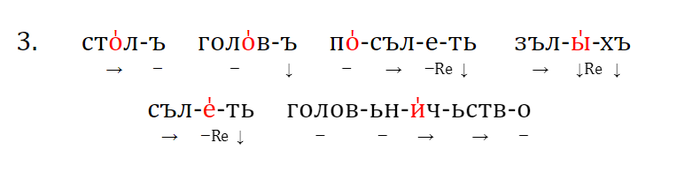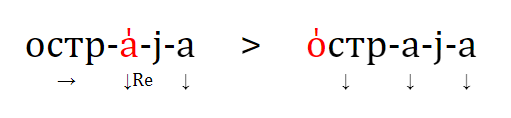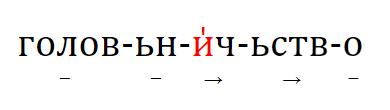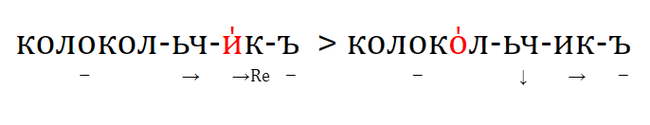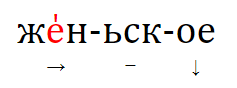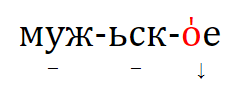В конце 2018 года группа российских лингвистов завершила многолетний проект по филогении индоевропейской языковой семьи. После нескольких туров рецензирования статья с описанием результатов была принята к публикации к 2020 году в Diachronica, который является ведущим мировым журналом по сравнительно-историческому языкознанию.
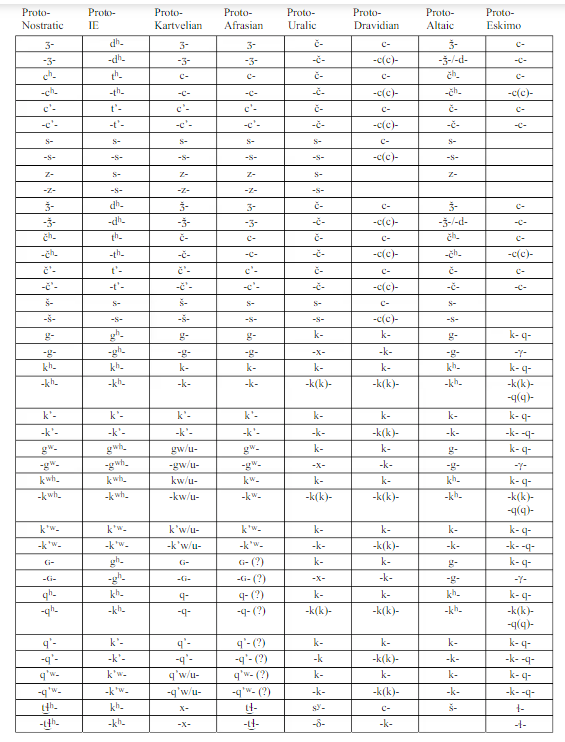
Ключевое: сравнительно-историческое языкознание = (лингвистическая) компаративистика; когнаты = родственные слова; девербативы = отглагольные существительные.
Лингвистика сейчас переживает бурную цифровизацию (с эволюцией нейросетей этот процесс будет развиваться всё дальше), и сравнительно-историческое языкознание — не исключение. В компаративистике цифровизация касается нескольких аспектов: в частности, это алгоритмы автоматического определения когнатов между словарями сравниваемых языков и алгоритмы выяснения степени родства между сравниваемыми языками, т. е. построение генеалогического дерева.
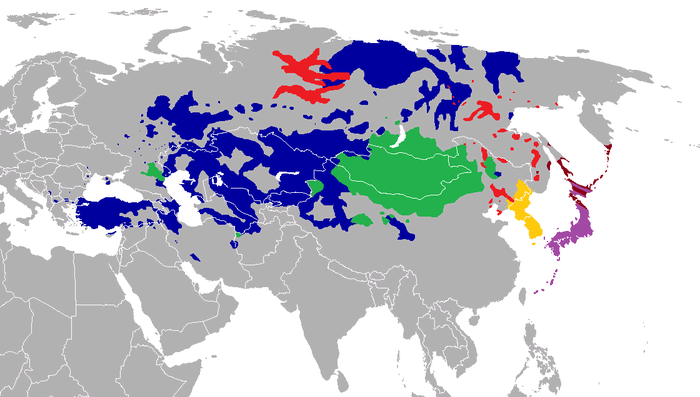
Карта современных индоевропейских языков. На сегодняшний день индоевропейская семья занимает первое место по площади распространения и количеству носителей:
Что касается формализованных генеалогических связей между языками, первые важнейшие шаги в этом направлении были сделаны американским лингвистом Моррисом Сводешем в середине XX в. В силу некоторых методологических изъянов та пионерская версия лексикостатистики не нашла большой популярности среди лингвистов. Начиная с 80‑х годов наш выдающий лингвист Сергей Анатольевич Старостин развивал идеи Сводеша и преодолел, по крайней мере, часть теоретических проблем (Starostin 2007). К сожалению, Старостин публиковался преимущественно на русском, поэтому не оказал в полной мере того влияния на мировую компаративистику, которое мог бы оказать. В начале XXI в. группа Дона Ринджа выступила с обновленной концепцией построения лингвистических деревьев (Ringe, Warnow & Taylor 2002): на довольно качественном лингвистическом датасете методом наибольшей совместимости они предложили некоторую древесную классификацию индоевропейских языков. Но опять же из-за довольно существенных методологических изъянов (специально подобранный датасет и кольцевая логика построения дерева) концепциях Ринджа не нашла большого количества сторонников.
Матаппарат лингвиста С. А. Старостина из публикации «Сравнительно-историческое языкознание и лексикостатистика (1989)»:
Мощное «второе дыхание» лингвистическая филогения получила в начале 10‑х гг. XXI в., когда этой областью стали заниматься люди с биологическим образованием и биологическим образом мышления, поскольку используемые техники и алгоритмы более-менее напрямую заимствованы из биологии (генетики). С одной стороны, это крайне полезно и продуктивно — посмотреть, как мыслят и работают представители более точной науки. С другой стороны, отсутствие понимания лингвистической специфики у этих авторов привело к серьезным ляпам и явно ошибочным выводам, по крайней мере, в некоторых знаковых публикациях последних десяти лет, в первую очередь это статьи группы Расселла Грея и Квентина Аткинсона, выходившие в ведущих журналах вроде Nature и Science. Далее началось своего рода состязание между биоинформатиками, кто сможет предложить более заковыристую и зубодробительную модель для описания языковой эволюции, где ценность имеет математический аппарат, а не лингвистические данные и не итоговый филогенетический результат (который в иных статьях оказывался самым диким), например, Blanchard et al. 2011. Со стороны это может выглядеть как дискредитация формального подхода, и сегодня это подталкивает многих компаративистов, особенно старшего поколения, вообще к отрицанию лексикостатистики и всех подобных приемов классификации языков.
В этой связи следует сформулировать принципиальную разницу между сравнительно-историческим языкознанием и генетикой — разницу, которую представители смежных наук обычно плохо осознают:
1. в генетике собрано и накоплено очень много качественных данных, а актуальная задача заключается в разработке всё более сложных алгоритмов анализа, чтобы вычленить полезный сигнал.
2. в лингвистике же остро стоит проблема с нехваткой качественных входных данных (поскольку мало кто хочет тратить время на сбор и обработку первичного материала), а вопросы матаппарата явно отходят на второй план.
Однако не всё так плохо, потому что сначала московская группа, а теперь и всё большее число коллег за рубежом активно пропагандируют важность качества лингвистических данных, подаваемых на вход модели. Возможно, через несколько лет это станет базовым принципом языковой филогении.
Итак, основная деятельность связана с разработкой принципов сбора лингвистического материала, изобретением техник и приемов последующей обработки этого материала и, наконец, применением существующих компьютерных алгоритмов к лингвистическому материалу для получения генеалогического дерева.
Все эти новшества, разумеется, следует тестировать на языковых группах с уже известной структурой: автоматизированно строится дерево, сравнивается насколько оно (не) противоречит мнению традиционных экспертов и далее делается вывод, насколько адекватными оказались теоретические идеи. Как показывает практика, разработки московской группы демонстрируют очень хорошие практические результаты. Тестирование на языковых группах с заранее известной филогенией показывает, что формальные деревья совпадают с традиционной классификацией.
Что касается индоевропейских языков, то у них нет никакой устоявшейся генеалогической классификации, поэтому в орбиту основных интересов московской группы индоевропейская семья не входит. Однако, поскольку лингвисты накопили очень много нового в том, что касается языкового филогенетического анализа, а индоевропейские языки — интересная для публики тема, то решили, что могли бы применить эти знания и умения и к этой языковой семье. И можно сказать, что результаты получились очень удачными.
Фантазия художника на тему неолитических земледельцев. Быт праиндоевропейцев мог выглядеть так:
Работа над проектом шла следующим образом. Первым делом собрали 110-словные сводешевские списки для основных древних и многих современных языков индоевропейской семьи. Несмотря на кажущуюся легкость, это совсем не простая задача: на составление одного списка у квалифицированного лингвиста может уйти две-три недели.
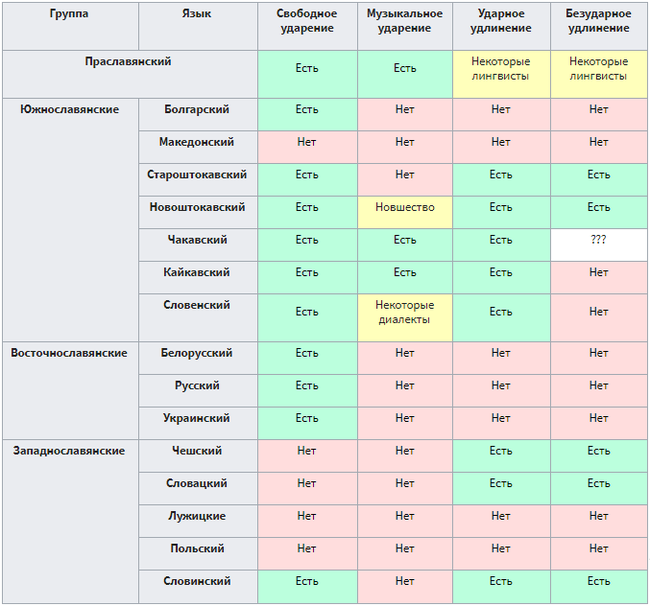
Далее применили прием поэтапной реконструкции. Как известно, в индоевропейской семье абсолютно консенсусно выделяется ряд неглубоких групп, таких как славянская, германская, албанская и т. п. Если у группы хорошо зафиксирован древний язык, который (пусть и с натяжкой) может рассматриваться как праязык данной группы, то брали сводешевский список для этого древнего языка: например, для всей индийской группы это ведийский санскрит. А если такого языка не обнаруживается, то на основании синхронных списков реконструировали сводешевский список для праязыка данной группы. Так реконструировали 110‑словные списки для праславянского, прабалтийского, прагерманского, праиранского, прабриттского.
Использования именно небольшого числа прасписков вместо большого числа синхронных списков имеет два сильных преимущества.
1. С математической точки зрения, чем больше таксонов (языков) исследуются, тем больше требуется признаков (сводешевских слов) для построения правдоподобного дерева. Скажем, для 30 таксонов может быть достаточным 100‑словник, а для 30-100 таксонов уже лучше использовать 200-словник. При этом, чем дальше мы отдаляемся от сводешевского 100‑словника, тем менее стабильные и менее семантически ясные концепты будут попадаться, т. е. для какого-либо языка составить 200‑словник — это задача не в два, а в несколько раз более сложная, чем сбор 100‑словника. В конечном итоге всё упирается в квалифицированные человеко-часы, которых, разумеется, не хватает.
2. Чем дальше списки отстоят от корня дерева (от праязыка), тем больше в них накапливается гомопластичных (параллельных) эволюционных событий. А чем больше входных списков, тем больше в них будет ошибок в силу человеческого фактора. Всё это добавляет шум в датасет и усложняет модель.
Конечно, у метода ступенчатой реконструкции есть своя оборотная сторона: реконструируя прасписки, можно банально ошибиться и взять в прасписок совсем не то слово, которое в данном языке выражало данный сводешевский концепт. Однако, оценивается вероятность ошибиться в конкретных концептах как не слишком высокая и не считается, что этот риск перевешивает две проблемы синхронных списков, описанные выше. Дело в том, что, во-первых, реконструкция списков для довольно неглубоких групп, их хронологический возраст обычно составляет 2000-2500 лет (скажем, славянской группе около 2000 лет, германская группа глубже, но не принципиально глубже). Во-вторых, что важнее, мы используем строгую методологию семантической (ономасиологической) реконструкции, недавно разработанную группой российских лингвистов. В этой методологии сформулированы пять критериев, позволяющих выбрать для того или иного сводешевского концепта наиболее вероятную праоснову. Эти критерии таковы:
1. топология дерева. Стремление к сокращению чисел эволюционных событий на дереве.
2. внешняя этимология, подсказывающая исходную семантику при сравнении нескольких лексических кандидатов.
3. морфологическая производность. Морфологически прозрачное производное имеет больше шансов оказаться инновацией, чем непроизводная основа.
4. типология семантических сдвигов. Переход между некоторыми значениями обычен в обоих направлениях (например, ‘трава’ ↔ ‘зелёный’), а в некоторых парах переход возможен только в одну сторону (например, ‘светить’ → ‘луна’).
5. исключение ареального эффекта. Если лексическая изоглосса захватывает соседние языки, она может быть результатом контактов.
В итоге в датасете оказалось 13 списков, представляющих все известные группы индоевропейской семьи (астериском [ * ] помечены реконструированные прасписки):
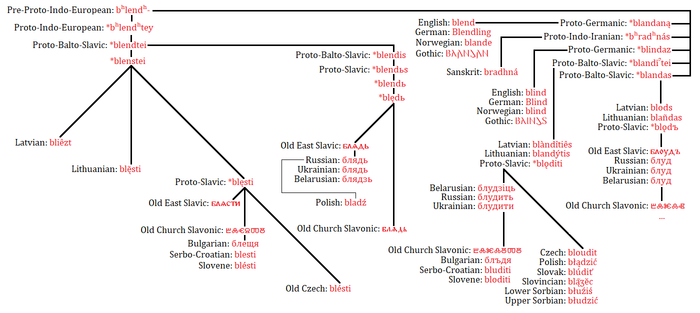
Разметив формы с этимологически родственными корнями между списками, получается традиционная лексикостатистическая матрица с корневыми когнациями (т. е. когда основы из разных языков, имеющие этимологически общий корень, помечаются как родственные друг другу). Например, в этой матрице прагерманское *wend-a-z 'ветер' = праславянскому. *wētr-o-s 'ветер', а санскритское agni 'огонь' = латинскому ignis 'огонь'. Назовем эту матрицу Этап-1.
На основе этой матрицы строятся деревья, причем не одним методом (как обычно делают), а тремя разными методами: метод ближайших соседей (специально модифицированный для лингвистических исследований), байесовский метод и метод максимальной парсимонии. Особенности этих методов — отдельная объемная тема, в которую сейчас нет нужды углубляться. Нам важно, что каждый из этих методов имеет свои сильные и слабые стороны, поэтому используются все три, а потом три полученных дерева объединяются в одно консенсусное дерево, которое и рассматривается как результат Этапа-1.
Однако нас не очень интересует топология, полученная из корневых когнаций, потому что понимается, что входные лексические данные можно улучшить и таким образом усилить филогенетический сигнал.
График DensiTree, суммирующий байесовские деревья, полученные на Этапе-3:
На Этапе-2 убирается из лексической матрицы так называемый деривационный дрейф, т. е. случаи, когда подразумеваются в разных языках параллельные морфологические образования. Например, германское *we‑nd‑a‑z и праславянское *wē-tr-o-s имеют общий корень (индоевропейский h₂weh₁- 'веять'), но это девербативы с разными суффиксами (прагерманский *‑nd‑ и праславянский *-tr-), и интуитивно хочется считать, что появление славянского новообразования *wē-tr-o-s — это отдельное эволюционное событие на лексикостатистическом дереве. С другой стороны, не всякая разница в морфологическом оформлении говорит о параллельных новообразованиях, например, совсем не хочется считать древнегреческое kard‑í‑aː 'сердце' и прагерманское *hert-ô 'сердце' не связанными друг с другом производными (исторически это результат различной адаптации праиндоевропейской атематической парадигмы). Пока предложены два критерия деривационного дрейфа (критериев может быть больше, эта тема нуждается в дополнительной разработке):
1. если две основы из сопоставляемых языков имеют общий корень, но различаются аффиксальной структурой, и есть свидетельства в пользу того, что хотя бы одна из основ подверглась частеречному изменению (например, существительное ↔ глагол), эти основы, скорее всего, демонстрируют гомопластичное развитие. Пример с прагерманское *we‑nd‑a‑z и праславянское *wē-tr-o-s как раз иллюстрирует этот критерий (мы имеем тут разные аффиксы и частеречный переход глагол → существительное).
2. если две основы из сравниваемых языков имеют общий корень, но модифицированы с помощью разных аффиксов, и есть свидетельства в пользу того, что эти основы были образованы от более простой основы, семантика которой сильно отличалась от значений сопоставляемых основ, такие две основы скорее всего представляют собой гомопластичное развитие. Например, в латинском, балтийском и кельтском обозначения 'человека' образованы от индоевропейского термина 'земля' (т. е. 'человек' как 'земной, землянин'), но с разными суффиксами: *‑on в латинском и в прабалтийском (*hom‑in-, *žm‑un-) и *‑yo- в пракельтском (*gdon‑yo-). Латинская и балтийская формы, с одной стороны, и кельтская форма, с другой стороны, представляют собой скорее всего два различных лексикостатистических события, будучи результатом параллельного словообразования по частотной семантической модели.
Применяя эти два критерия к лексической матрице, мы размечаем основы с деривационным дрейфом как неродственные друг другу. Таким образом получаем матрицу, где прагерманское *we‑nd‑a‑z ≠ праславянскому *wē-tr-o-s (по-прежнему санскритское agni = латинскому ignis). Назовем эту матрицу Этап-2.
На Этапе-2 также строятся три дерева и суммируются в виде консенсусного дерева. В принципе, такое дерево уже является полноценным научным результатом, но всё же филогенетический сигнал можно усиливать и дальше.
Поэтому приступаем к Этапу-3, на котором производим гомопластичную оптимизацию матрицы. Эта процедура заключается в том, что, если в матрице есть когнаты, которые противоречат древесной структуре (полученной на Этапе-2), то во многих (далеко не всех) случаях можно с большой степенью вероятности предположить, что эти формы представляют собой параллельное (т. е. гомопластичное) развитие. Например, индоевропейская основа для значения 'огонь' вполне надежно восстанавливается как péh₂-wr̥, она сохраняется в обоих аутлайерах (анатолийском и тохарском) и в ряде узкоиндоевропейских групп: в греческой, армянской, германской, италийской. В балто-славяно-индо-иранской кладе эта основа вытесняется основой *ng-n-i- (откуда русск. огонь, др.‑инд. agni- и пр.). Загадочным образом ignis значит 'огонь' и в латыни, хотя италийская группа сохраняет старое обозначение 'огня': умбрское pir. Какова была изначальная семантика основы *ng‑n‑i-, мы не знаем, но, поскольку ни одна из классификаций не объединяет латынь в отдельную кладу с балто-славяно-индо-иранским и тем более в обход умбрского, то с большой вероятностью лат. ignis 'огонь' — это параллельное семантическое развитие, независимое от *ng‑n‑i- 'огонь' в балто-славяно-индо-иранской кладе. На основе этих рассуждений в датасете Этапа-3 помечается латинское ignis 'огонь' как форма не родственная балто-славяно-индо-иранскому *ng‑n‑i- 'огонь', это и есть гомопластичная оптимизация. Таким образом, имея консенсусное дерево (Этап-2) и очистив матрицу от явных гомопластичных событий, получается уже итоговая для исследования матрица, на основе которой опять строится консенсусное дерево. Это Этап-3 и финал работы.
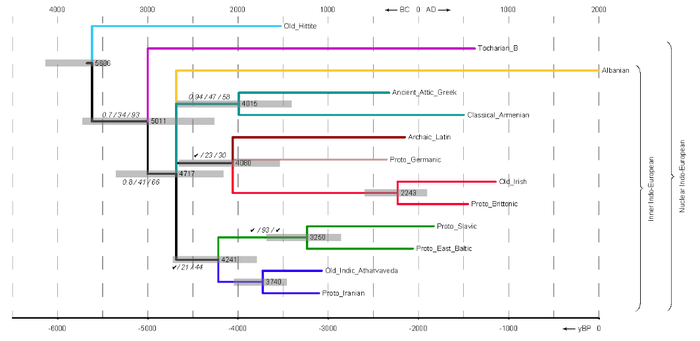
Строгое консенсусное дерево индоевропейской семьи на основе набора данных Этапа-3 (wind ≠ ветер, agni ≠ ignis). Дерево суммирует три дерева, полученных индивидуальными методами. Даты получены с помощью анализа Bayesian MCMC: серые линейки показывают временной интервал с 95% вероятностью времени расхождения; справа от каждого узла указывается среднее время расхождения. Нижняя шкала — годы до настоящего времени (yBP). Значения статистической поддержки указаны курсивом рядом с ветвями в следующей последовательности: Bayesian MCMC / StarlingNJ / MP («✓» означает, что P ≥ 0,95, не указано для узлов с P ≥ 0,95 во всех методах). Традиционные группы обозначены цветом:
А что в итоге? Итоговое дерево не содержит никаких несуразиц с точки зрения классической индоевропеистики, как в плане топологии дерева, так и в плане датировок, например, первое разделение на анатолийскую и не-анатолийскую ветви помечается в промежутке 4139–3450 до н. э. (средняя дата 3686 до н. э.) — точно так же и современные индоевропеисты предполагают, что распад произошел в первой половине 4‑го тысячелетия до н. э.
По всей видимости, за всю историю индоевропейских штудий это первый раз, когда, используя формальные биологические классификационные методы без каких-либо предварительных ограничений на топологию и вообще без какого-либо насилия над материалом и матаппаратом, были получены дерево и датировки, не противоречащие традиционным взглядам индоевропеистов.
Главная находка — это одномоментное разделение узкоиндоевропейского узла на четыре ветви в промежутке 3400–2200 до н. э.: (1) греко-армянскую, (2) албанскую, (3) итало-германо-кельтскую, (4) балто-славяно-индо-иранскую. Такой быстрый распад очень хорошо согласуется с тем фактом, что за последние 150 лет (первое дерево индоевропейских языков было опубликовано Шлейхером в 1861 г.) индоевропеисты пришли более-менее к консенсусу о первых аутлайерах (анатолийский, тохарский) и о молодых кладах вроде балто-славянской или индо-иранской. А вот какие ветвления происходят в середине дерева, нет понимания до такой степени, что подавляющее большинство традиционных индоевропеистов вообще отказывается мыслить индоевропейскую семью в древесном виде и предпочитает не касаться этой темы (если вы откроете современные учебники по индоевропеистике, то вряд ли вы там увидите филогенетические картинки). Это значит, что нет никаких мощных пучков изоглосс, способных помочь внутренней классификации, и в свете этого мультифуркация на четыре ветви представляется наиболее правдоподобным сценарием.
Полученные датировки промежуточных узлов удивительно хорошо соответствуют радиоуглеродным датам некоторых археологических культур, которые традиционно связываются с расселением индоевропейцев (поиск прародины или промежуточных прародин индоевропейцев ни в коем случае не входили в задачи, но хочется отметить, что и тут результаты не вступают в противоречие с взглядами индоевропеистов):
1. Возникновение афанасьевской культуры: 2800 до н. э. // Отделение тохарского: 3727–2262 до н. э. (средняя дата 3011 до н. э.).
2. Закат синташтинской культуры: 1800 до н. э. // Распад индоиранской клады: 2044–1458 до н. э. (средняя дата 1740 до н. э.).
3. Закат культуры шнуровой керамики: 2300-2000 до н. э. // Бинарный распад балто-славяно-индо-иранской клады: 2723–1790 до н. э. (средняя дата 2241 до н. э.).
4. Закат культуры колоколовидных кубков: 2100 до н. э. // Троичный распад итало-германо-кельтской клады: 2655–1537 до н.э. (средняя дата 2080 до н.э.).
Современная аэросъемка Аркаима (синташтинская культура):
Под конец стоит упомянуть такой частный аспект исследования. Помимо 13 индоевропейских списков в датасет был опционально добавлен прасамодийский список. Самодийская группа — это одна из двух ветвей уральской семьи. Прауральский язык, видимо, является ближайшим родственником праиндоевропейского. Сегодня далеко не все ученые признают обоснованными вообще какие-либо внешние связи индоевропейского, но тем не менее индо-уральская гипотеза постепенно завоевывает признание и, наверное, в ближайшем будущем станет мейнстримом (например, не так давно московская группа обосновала индоевропейско-уральское родство со статистической точки зрения). Продублирование всех подсчетов и деревьев с самодийским и без самодийского, и оказалось, что различий в топологии и хронологии фактически нет: самодийский оказывается аутгруппом (первым отделившимся таксоном) и не меняет индоевропейское дерево. Это должно указывать на то, что лексические схождения между самодийским (уральским) и индоевропейским не стохастические случайные созвучия, а могут представлять собой древний индо-уральский лексический фонд, независимо изменяющийся в обеих ветвях по предполагаемой эволюционной модели. Так что в принципе это является еще одним косвенным свидетельством в пользу индоевропейско-уральского родства.