


Программист - швейцарский нож
Парсер - инструмент для анализа/разбора текстовой информации.
Парсер - инструмент для анализа/разбора текстовой информации.

В общем история наверное уже не впервой встречается В общем искал игрулю PUBG, глупо конечно искать ее за дешево, но мне стало интересно где и как купить дешевле, так как в нашей стране у всех имеется желание получить на халяву или сэкономить.
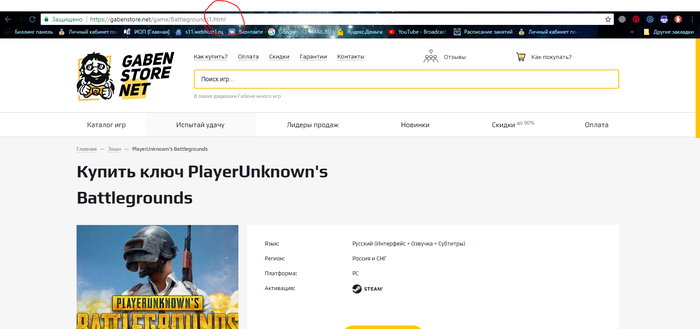
Зашел на сайт Gabenstore, приобрел и приобрел stickman а не пубг. Не особо обратил внимание на сайт, ведь ранее посмотрел всякие обзоры на Youtube, конечно перед тем как оплатить, я уже заранее приготовился к худшему, собственно ожидания сбылись.
Попал на фейк, после того нагуглил настоящий сайт gabestore.
1) .html линк (просто парень взял стянул оригинальный сайт, на всех нормальных на линк работает ЧПУ) даже ssl сертификат настроил, что якобы повышает доверие к сайту когда видишь надпись защищено.
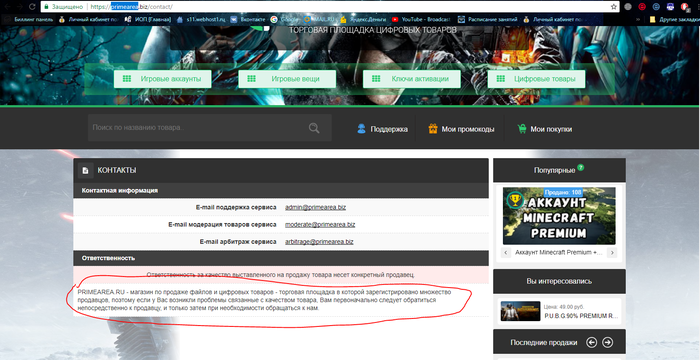
2) Линк кнопки купить ведет на ресурс primearea biz, где производится оплата, сам ресурс является чем то вроде plati ru, барахолкой игр, ключей, аккаунтов.

3) Ну а сама площадка вообще не несет никакой ответственности за беспредел продавцов и ведь торгуют и покупают.
До Aliexpress этим барахолкам далеко, а бесплатный сыр бывает только в мышеловке.
Будьте бдительны!
Написал тут вторую версию парсера, плюс ещё очень удобное приложение для компьютера. Благодаря этому я уже могу поздравить @Zanco, @timofey9, @BesAng, @NeoGalaxy, @228332, @AnnaDmitrievna, @Zicker, @vaha39, @Enaisha, @gunnner, @Renaljalja, @m1kk, @orientman, @todausss, @morr1son, @Katazza, @Dotsenko.ms, @iMarti, @Kuchkin, ведь у всех у них сегодня день рождения! Юху! Никакая ручная сортировка не применялась, эти ники программа выдала сама.
@Midzukawa, вот оно:

Во-первых, новая версия скрипта для браузера, его нужно вставить из ссылки.
Во-вторых, программа для компьютера
Нужно самому нажимать на кнопку "показать все комментарии", до тех пор, пока все не раскроются, и запустить скрипт. Затем к Вам скачается файл с результатами. В программе нажать кнопку "загрузить файл с комментами" и выбрать загруженный файл.
Сортировка
Выберите нужные опции, а затем кнопку "сортировать".
-"показывать только непонятные": показывать комменты, дата рождения авторов которых неизвестна
-"показывать только понятные": показывать комменты, дата рождения авторов которых известна
-"показывать только за дату": показывать комменты, дата рождения авторов которых является датой в поле ниже. Год не имеет значения.
Изменение
При выборе коммента в списке слева, можно воспользоваться меню "коммент" справа внизу. Вам доступен номер коммента (то, что идёт в ссылке после слов #comment), пользователь, оставивший его, и дата его рождения, если известна. При нажатии на кнопку "показать коммент" Вы можете увидеть текст коммента. При нажатии на кнопку "задать дату" сохраняется дата рождения этого пользователя, указанная в поле выше, но ровно до закрытия программы.
Недавно @Midzukawa опубликовал этот пост, а под ним этот комментарий:
!!! ATTENTION !!!
В связи с огромным количеством людей, ищем модераторов для сортировки пользователей по датам и вообще помощи, боюсь, вдвоем нам будет тяжко.
Поднимите повыше, чтобы все видели, пожалуйста!
!!! ATTENTION !!!
Итак, уважаемый @Midzukawa, готов представить тебе мой парсер, написанный на коленке за 5 минут. Что он делает:
1. Имитирует нажатие "показать все комментарии" до тех пор, пока все из них не будет показаны
2. Распознаёт даты, в том числе названия месяцев
3. Выводит всё в файл
4. В случае ошибки выделяет этот коммент среди остальных в файле. Вот так:

Итак, как его использовать:
1. Открыть, внимание, пост с новой версии Пикабу!
2. Открыть консоль (если у Вас Google Chrome, то нажать F12)
3. В консоли открыть вкладку "Console"
4. Вставить такой код:
var comments = document.getElementsByClassName("comment__content");
var more = document.getElementsByClassName("comments__more-button");
while(more[0].style.display != "none"){
more[0].click();
await new Promise(resolve => setTimeout(resolve, 2000));
}
var textToSave = "---PIKALOGGER[1]---\r\n";
for(var i = 0; i < comments.length - 1; i++){
var comm = comments[i].innerText.replace(/[^a-zA-Zа-яА-Я0-9 .:!?]/g, "");
textToSave = textToSave.concat(comm);
var numon = comments[i].innerText.replace(/[^0-9.]/g, "");
var dates = numon.split(".", 2);
var month = dates[1];
if(comm.toLowerCase().includes("январ") && (month == "" || month == undefined)){
month = "01";
} else if(comm.toLowerCase().includes("феврал") && (month == "" || month == undefined)){
month = "02";
} else if(comm.toLowerCase().includes("март") && (month == "" || month == undefined)){
month = "03";
} else if(comm.toLowerCase().includes("апрел") && (month == "" || month == undefined)){
month = "04";
} else if(comm.toLowerCase().includes("ма") && (month == "" || month == undefined)){
month = "05";
} else if(comm.toLowerCase().includes("июн") && (month == "" || month == undefined)){
month = "06";
} else if(comm.toLowerCase().includes("июл") && (month == "" || month == undefined)){
month = "07";
} else if(comm.toLowerCase().includes("август") && (month == "" || month == undefined)){
month = "08";
} else if(comm.toLowerCase().includes("сентябр") && (month == "" || month == undefined)){
month = "09";
} else if(comm.toLowerCase().includes("октябр") && (month == "" || month == undefined)){
month = "10";
} else if(comm.toLowerCase().includes("ноябр") && (month == "" || month == undefined)){
month = "11";
} else if(comm.toLowerCase().includes("декабр") && (month == "" || month == undefined)){
month = "12";
}
var possibleDate = "=========================================================================================================================Возможная дата: ???";
if(dates[0] != undefined && dates[0] != "" && month != undefined && month != ""){
var possibleDate = "====================================================================================Возможная дата: ".concat(dates[0]).concat(".").concat(month);
}
textToSave = textToSave.concat("\r\n").concat(possibleDate).concat("\r\n---NEWCOMMENT---\r\n");
}
var textToSaveblob = new Blob([textToSave], {type:"text/plain"});
var textToSaveurl = window.URL.createObjectURL(textToSaveblob);
var downlink = document.createElement("a");
downlink.download = "Pikabu-comments-parsed.txt";
downlink.href = textToSaveurl;
document.body.appendChild(downlink);
downlink.click();
5. Нажать Enter
6. Чуть подождать
7. К вам скачался файл с результатами
8. ???
9. PROFIT
Ну и да, я родился девятого августа)
Добрый день!
Возникла следующая ситуация.
Компания работает на 15 тендерных площадках.
На каждой из них нужно оплачивать
а) участие на самой площадке -абонентка
б) деньги за участие в конкретных тендерах
В компании работают по этому направлению 5 человек.
Менеджер заходит на сайт, в личный кабинет, видит остаток денег на счете и понимает, что на его тендер денег для участия хватит.
Второй менеджер заходит через полчаса на этот же сайт по другому запросу и так же считает, что денег ему хватит.
После списания денег по заявке первого менеджера, выясняется, что на втрого денег не хватает и он в пролете
Вопрос: можно ли написать парсер/сборщик информации или типа того, который бы с определенной периодичностью заходил по логиину/паролю (разному для каждого сайта) в личные кабинеты, брал там эти данные ( в разных местах лежат) и сливать в таблицу?
И примерный ценник на это.
Всем спасибо за информацию.
Пиво и девочки прилагаются


Всем Доброго дня.
Знающие подскажите, как имея 2 сайта вытащить из них информацию.
Но на сайтах эта информация "скрыта" в виде визуальных элементов, значение появляется при наведении на предмет курсором.
По какому запросу мне можно найти человека который помог бы с этим вопросом?
Комент для минусов внутри.
Наконец дошли руки написать обещанный пост про парсер сайтов. Главное условие для нашего парсера, чтобы сайт был открытый и не требовал авторизации (в принципе 98% интернет магазинов).
Для примера работы я буду использовать этот сайт, ни в коем случае не реклама. Сам парсер я взял у команды Lofblog (ссылка на оригинал) это не реклама, урок был написан еще в апреле 2014, но почему то не нашел своей славы. На него я наткнулся после нескольких часов блужданию по интернету в поисках бесплатного и хорошего способа парсинга сайт.
Так а теперь приступим к самому парсеру, сначала я выложу его код (для тех кто хоть немного понимает справятся без моих коментариев), а потом начну пояснять все потихоньку.
function getconten() {
for(var j=1;j<=68;j++){
getPageContent(1+10*(j-1),"https://cleanshop.ru/catalog/spbd/?start="+j)
}}
function getPageContent(startRow,url) {
var sheet = SpreadsheetApp.getActiveSheet();
var range = sheet.getRange("A2:I5000");
var cell = range.getCell(startRow,1);
var response = UrlFetchApp.fetch(url);
var textResp=response.getContentText();
var start,end,name;
for (var i=1;i<=10;i++){
//фото
start = textResp.indexOf('<table class="good_img">',end)+24;
start = textResp.indexOf('src="',start)+5;
end = textResp.indexOf('"',start);
name = textResp.substring(start,end);
cell.setValue(name);
cell=cell.offset(0,1);
// цена
start = textResp.indexOf('</td></tr><tr><th>',end)+18;
end = textResp.indexOf('</th></tr></table>',start);
name = textResp.substring(start,end);
cell.setValue(name);
cell=cell.offset(0,1);
//название
start= textResp.indexOf('<div class="good_text">',end)+23;
start= textResp.indexOf('class="good_title">',start)+19;
end=textResp.indexOf('</a>',start);
name =textResp.substring(start,end);
cell.setValue(name);
cell=cell.offset(0,1);
//код
start = textResp.indexOf('Код: ',end)+5;
end = textResp.indexOf(' | ',start);
name = textResp.substring(start,end);
cell.setValue(name);
cell=cell.offset(0,1);
// описание
start = textResp.indexOf('<p>',end)+3;
end = textResp.indexOf('</p>',start);
name = textResp.substring(start,end);
cell.setValue(name);
cell=cell.offset(0,1);
cell=cell.offset(1,-5);}}
Шаг 1: Создаем документ на Google тут или тут;
Шаг 2: Кликаем в меню по пункту "Инструменты" затем на "Редактор скриптов", у нас откроется новая вкладка.
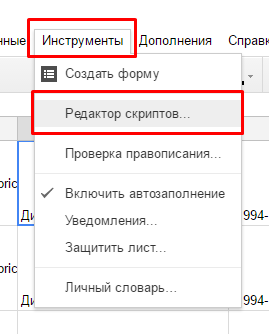
Шаг 3: В открытое окно вставляем наш скрипт.
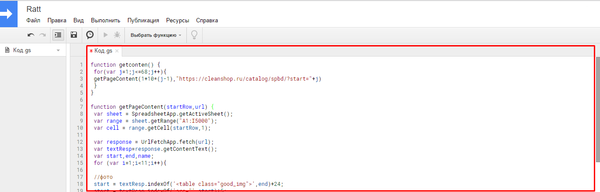
Шаг 4: Запуск скрипта для начала нужно выбрать функцию getcontent. затем нажать кнопку запуска (серая стрелка, станет черной после выбора функции).
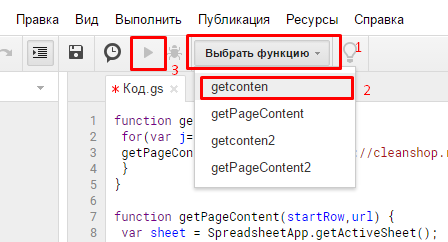
После этого в документе мы увидим подобное:

Теперь основные комментарии к коду:
Мы имеем 2 функции getconten и getPageContent , из getconten мы передаем нужные данные и запускаем функцию для getPageContent для парсинга страницы которую мы передали из getconten.
Функция getconten: здесь мы имеем цикл равный количество страниц в данном разделе. За каждый проход цикла мы отправляем ссылку на страницу и кол-во уже обработанных товаров.
И так какую же ссылку нам вставить для нашего сайта? Большинство сайтов имеет подобную структуру сайт.ру/раздел/?страниц=1 под словом страница может скрываться любое слово в нашем случае start, чаще page. Иногда на первой странице сайта этой переменной нет, нужно просто перейти например на вторую. Для лучше понимая рекомендую прочитать прочитать про GET запросы тут или в google.

Формула 1+10*(j-1) - нужна для того чтобы записи шли дальше,а не перезаписывались в документе, где 10 это количество записей (!внимание! количество записей по умолчанию, для частоты лучше зайти на нужную страницу с другого браузера или с приватной вкладки тогда вы уведите страницу именно так, как видит ее ваш скрипт).
Функция getPageContent: здесь творится основная магия. Я думаю здесь стоит пояснить только основные моменты, более подробнее почитать про каждую из функций можно в гугле если заинтересует.
sheet.getRange("A1:I5000") - здесь мы выбираем диапазон ячеек, с которыми мы будем работать, рекомендую ставить большой разбег.
for (var i=1;i<=10;i++) - параметры цикла, где 10 см.формулу выше (!Внимание! цифры должны совпадать с формулой вышей).
Основные параметры мы настроили, теперь приступаем к настройке парсинга.
Дальнейшие действия подразумевают, что вы имеет базовые понятия HTML и исходный текст страницы, если же нет настоятельно рекомендую сначала прочитать про эти вещи.
И так разбор полета пошел:
Чтобы вставить в ячейку некоторый текст со страницы нам нужно знать его начальное положение (start) и конечное (end). Для этого мы находим уникальную строку для элемента которые мы хотим спарсить, в случае с изображением товара это строка <table class="good_img"> она уникальная, ее имеет только товары при этом она имеется у каждого товара, но отталкиваясь от этой строки мы захватим слишком много, по этому находим точку еще ближе к нужной информации и уже от ее оставляем как start. Незабываем приплюсовывать количество всех символов в строке.
start = textResp.indexOf('<table class="good_img">',end)+24;
start = textResp.indexOf('src="',start)+5;
С концом еще проще здесь как правило закрывающийся тег или же кавычки.
end = textResp.indexOf('"',start);
Далее функцией substring извлекаем нужные данные зная где они начинаются и где заканчиваются.
name = textResp.substring(start,end);
Тут просто присваиваем значению в ячейку.
cell.setValue(name);
И перешагиваем на новый столбец, оставаясь на этой же строке .offset(Строка,Столбец).
cell=cell.offset(0,1);
Незабываем в конце перепрыгнуть на новую строку и вернуться на нулевой столбец.
cell=cell.offset(1,-5);- где 5 количество столбцов на которое мы ушли или проще говоря сколько данных у товаров мы спарсили.
Теперь поговорим о его достоинствах и недостатков более подробно:
Он бесплатный, но имеет ограничений на кол-во использования обращения к сайту, вроде 12000 раз за 24 часа, для обхода вроде как надо покупать специальную лицензию ну или просто зайти с другого аккаунта.
Он полностью универсальный, да его функционал позволяет спарсить почти все тоже самое что и большая часть платных парсеров.
Не требует установки какого то софта.
Из недостатков это наличие неких базовых знаний и наличие логики, ну и немножко опыта. Я не пользовался другими парсерами, но мне кажется там почти такой же входной парог.
Парсер достаточно костальный, но именно по этому бесплатный, т.е его придется адаптировать под каждую задачу по этому имеет смысл использовать только если товаров большое количество.
Нельзя парсить на закрытах сайтах где требуется авторизация или же данные которые динамически подгружаются на странице.
Если мой урок не очень понятен, то советую посмотреть видео там очень доходчиво объясняют. Это мой первый пост в стиле уроков, по этому совсем сильно не бить. Надеюсь кому то этот способ сэкономит время и возможно даже деньги с учетом того, что цена за наполнения карточки товара начинается от 10р.
Так же хочу написать пост про то как с пользой использовать формулы в EXCEL для решение больших задач, если тема с excel вам интересна и у вас есть некоторые рутинные задачи пишите их в комментариях постараюсь оптимизировать с excel.
С библиотекой Jsoup я разобрался, но вот в чем проблема:
Возьмём к примеру заглавную страницу Пикабу. При сохрании в Document попадает только часть ленты. Насколько я понял, когда я руками дохожу до определённой границы, срабатывает скрипт и подгружаются следующие элементы ленты.
Каким образом мне спарсить всю информацию, например, за конкретную дату. Я конечно могу залогиниться и ручками сохранить дохреналион страниц, а потом их обработать, но это не вариант.





