


Сообщество программирование и разработка
адрес .dev
Программирование и все что с ним связанно

адрес .dev
Программирование и все что с ним связанно
Некоторые ресурсы при копировании текста с сайта вставляют в буфер обмена ссылку на себя. Например, такое поведение будет при копировании первого абзаца со страницы КонсультантПлюс.
Как это технически работает?
В JS можно на событие copy навесить свой обработчик, который что-то модифицирует. Есть более современное Clipboard API.
Этот функционал позволяет осуществить атаку на целостность данных через манипуляцию с содержимым буфера обмена. Результат - страничка, где написано
echo "not evil"
Теперь скопируйте этот фрагмент и вставьте в терминал. Поздравляю, вас хакнули. В терминал вставился другой текст
echo "evil"
Не копируйте команды сразу в терминал. Лучше перепечатать (так ещё и запомнится лучше) или идти по пути сайт — блокнот — анализ глазками. Копировать без переноса строки тоже не поможет — наглый js может вставить в буффер символ переноса строки. В итоге безопасное
pip install -U pytest
Может сделать с вами что-то злобное. Не всегда об этом можно узнать. Команды в терминале, которые начинаются с пробела, в истории команд не сохраняются. Если вывод команды достаточно длинный (установка пакета для python является хорошим примером), то вы даже не увидите настоящую введенную команду.
А ещё так можно модифицировать ваш .bashrc, сделав любой alias.
В телеграм-канале разбираем разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командную разработку.
Есть такой вид атаки на отказ в обслуживании (DoS, Denial of Service) — forkbomb. Запускается процесс, который бесконечно порождает сам себя, пожирая все ресурсы системы. Прав суперпользователя не требуется, любой пользователь может создавать процессы.
Cкрипт атаки выглядит так. Функция порождает две версии себя, связанные конвейером. Правая функция уходит в фоновый режим с помощью знака амперсанд &.
forkbomb()
{
forkbomb | forkbomb&
}
Скрипт можно переписать в непонятный однострочник, изменив название на символ двоеточия:
:(){ :|:& }; :
Такой набор символов эквивалентен скрипту выше. При этом он компактен, и его могут запихнуть вам в качестве шуточного ответа на вопрос. Спасибо ещё, что не патч Бармина.
В видео также рассматриваются линуксовые команды команды
1. lscpu
2. nproc
3. uptime
4. top
5. free
6. переменные $$ $PPID
7. настройка числа PID в /proc/sys/kernel/pid_max
8. ctrl-L для очистки терминала
9. разделение экрана в терминале terminator
10. буфер выделения и вставка по нажатию на колёсико мышки
11. pkill
И разбираются флаги такой docker команды
docker run --it --rm --cpus="0.5" --memory=4G --pids-limit=1000 --name=forkbomb ubuntu bash
Плюс применяются команды docker ps / stats / exec.
Хотите почувствовать себя капитаном тонущего корабля? Теперь ресурсы системы принадлежат не вам, а паразитному процессу forkbomb. Приятного просмотра!
Починить атакованную систему можно только перезагрузкой. Ну, если атакующий скрипт вам не дописали в .bashrc. Тогда только recovery mode в grub.
В телеграм-канале разбираем разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командную разработку.
Сегодня продолжим изучать наш идеальный скрипт из предыдущего видео (видео прошлой части). Разберёмся с непонятными конструкциями в bash [] и [[]] и обсудим, когда можно не ставить кавычки вокруг переменных. Ниже видео с разбором, а кому удобнее текстовый вариант — добро пожаловать ниже.
Давайте разбираться. Двойные квадратные скобки в современном bash - это ключевое слово, такое же, как for. Проверить это можно с помощью команды type. Одинарные квадратные скобки - это встроенная команда, такая же, как test. Что из этого следует? Да фиг знает, по факту. Просто интересно. А вот внутри одинарных и двойных квадратных скобок можно использовать разные конструкции.
Для сравнения [[ и [ нашёл для вас очень наглядную таблицу
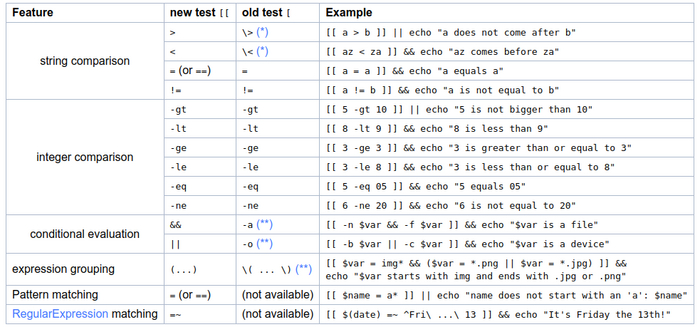
Источник: https://mywiki.wooledge.org/BashFAQ/031
Например, знак меньше для одинарных скобок нужно экранировать, как и скобки. Для двойных скобок работают привычные программисту логические операции, регулярные выражения и прочие приятные штуки. Глобально, нет причин сейчас использовать одинарные квадратные скобки. Разве что ради переносимости.
Но про переносимость куда мы говорим? Действительно, двойные квадратные скобки появились не сразу. В разделе 7.1 книги Advanced Bash-Scripting Guide (версия на русском) написано, что конструкция появилась в bash версии 2.02. Кстати, это очень большая и вкусная книжка по bash, рекомендую её, если вы зачем-то решили стать в баше экспертом. Там под тысячу страниц, материал не для слабых духом. Есть и на русском, и на английском.
Так когда появились двойные скобки? Проверим changelog баша, там можно найти первое упоминание конструкции [[]] в версии 2.02. А потом можно найти релиз, и это 1998 год. 1998, Карл. Надеюсь, все обновились с тех пор.
В man bash можно найти описание [[]], лучше посмотрите в видео этот фрагмент.
Соберём на коленке пример демонстрации важности двойных кавычек.
a="hello world"
if [[ $a == "hello world" ]]
then
echo "success"
fi
# в видео показан однострочник ниже
if [[ $a == "hello world" ]]; then echo "success"; fi
И всё хорошо, внутри [[]] действительно можно не применять кавычки, bash всё сделает корректно. Но потом модифицируем пример
# так неправильно!
if [[ $a == "hello world" ]]; then echo "success"; touch $a; fi
И вот этот код уже ломается. Вместо создания одного файла "hello world" создаются два отдельных файла. Потому что в touch надо кавычками защищать переменную
# так нормально, но тяжело объяснить, где нужны кавычки
if [[ $a == "hello world" ]]; then echo "success"; touch "$a"; fi
А теперь объясните джуну, где надо ставить кавычки, а где не надо. Самое простое правило - кавычки должны быть везде. Великий и ужасный Гудвин, ой, то есть баш, очень неустойчив к разного рода ошибкам. По опыту жить проще с ядрёным стайл-гайдом, по которому чисто визуально можно выявить ошибку. Есть переменная? Должны быть кавычки.
# так безопаснее всего
if [[ "$a" == "hello world" ]]; then echo "success"; touch "$a"; fi
Давайте попробуем сконструировать выражение для оценки времени выполнения. Как корретно измерять время выполнения я планирую снять отдельное видео. Пока не будем вдаваться в детали и попробуем собрать нужную конструкцию
Утилита time выдаёт временные характеристики работы программы. Сейчас нас интересует блок real, где указано общее время работы программы согласно системному таймеру, то есть время от запуска команды до её завершения
time echo $( i=0; while [[ $i -lt 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Если заменить двойные квадратные скобки на одинарные, по неведомой мне причине скорость выполнения драматически падает. Нет ни одной адекватной причины использовать одинарные квадратные скобки уже лет десять как.
Вернёмся к замене -lt на треугольный знак меньше. Попробуем
# ОШИБОЧНОЕ 2 итерации вместо 1кк
time echo $( i=0; while [[ $i < 1000000 ]]; do i=$(( $i+1 )) ; done; echo $i )
Вау! Отработало мгновенно. Но неправильно. Обратите внимание на вывод - прошло только 2 итерации. Потому что два больше миллиона, если смотреть на них как на строки. Строковое сравнение идёт посимвольно, и два больше 1 - истина, дальше смотреть не требуется.
По факту, нужно использовать арифметическое выполнение
time echo $( i=0; while (( $i < 1000000 )); do i=$(( $i+1 )) ; done; echo $i )
А теперь ещё раз. Как вы думаете, в большом скрипте легко обнаружить такую ошибку? Это отладочный ад. Поэтому используйте -lt и аналогичные конструкции в баше, чтобы сэкономить себе время
Подытожим: всегда используйте двойные квадратные скобки в if и while, всегда защищайте ваши переменные двойными кавычками, даже если в отдельных конструкциях баш делает это за вас. Пишите поддерживаемый код, и да пребудет с вами баш.
Заходите в наш канал DevFm в телеграмм, где выходят годные материалы для middle плюс python разработчика. Если хотите разобраться с азами Linux, то добро пожаловать в наш бесплатный курс cli-for-dev на степике. Буду рад, если вы поддержите нас позитивными оценками и обратной связью по курсу.
UPD я улудшил Скрипт для массового выборочного конвертирования форматов файлов в Ubuntu, например, heic в jpg, вторая серия
В общем, у меня айфон и убунта. Не самое удобное сочетание, но, если ты однажды перешел на Линукс, значит - у тебя уже изначально предрасположенность к танцам с бубном вокруг компьютера. С помощью Warpinator'а перекидывание файлами с ноутбука на телефон и обратно наладилось, а после того, как в пыльном углу образовался nas-сервер из старого ноутбука - процесс стал непринужденным. Однако, выяснился ньюанс - фотки на гейфоне пишутся почему-то в странненьком формате .heic, а весь остальной мир предпочитает жпг. Причем, он выяснился, когда мне надо было заслать в налоговую два-три десятка фотогорафий документов. И онлайн-конвертеры почему-то адекватно при этом не работали. В общем. ВЫЗОВ ПРИНЯТ. За неадекватное для поставленной задачи время (чет типа полдня) было порождено решение в виде баш-скрипта:
#!/bin/bash
IFS=$'\n'
read -r -d '' -a array < <( xclip -selection clipboard -out && printf '\0' )
for element in "${array[@]}"
do
strlen=${#element} #дляна имени файла с расширением
pathlen=`expr $strlen - 4` #длина имени без последних 4 символов heic
path=`expr substr $element 1 $pathlen` #имя файла без расширения (первые "все - 4" символы)
jpg=$path"jpg" #прилепить новое расширение
heif-convert "$element" "$jpg" #тут можно вкорячить любой конвертер
done
Соответственно, для работы баш-скрипта нужны пакеты xclip и libheif-examples. Теперь - что вообще происходит: xclip - консольная утилита для работы с буфером обмена. heif-convert - команда из пакета libheif-examples, которая конветртирует файл из имя.хейф в имя.жпг. После того, как все пакеты установлены и вся лабуда скопипащена в файл скрипта с расширением .sh, который помечен, как исполнимый, делается следующее: в тунаре (кстати, не знаю, будет ли работать в наутилусе) выделяются подопытные файлы, копируются в буфер обмена. Далее, хоткеем или консолью запускается скрипт. Далее, оно делает копии скопированных в буфер файлов в новом формате с теми же именами в той же папке. Подробно: после копирования из тунара файлов в буфере оказывается кучка строк типа такого:
/home/username/123/IMG_0144.HEIC
/home/username/123/IMG_0145.HEIC
/home/username/123/IMG_0146.HEIC
первые 2 строки после бин-баш - чтение содержимого буфера обена в массив переменных, где каждая переменная - полное имя файла. Затем - перебор элементов массива (полных имен файлов), замена расширения на конце и впихивание "исходного_имени_и_расширения" и "конечного_имени_и_расширения" в непосредственно команду конвертера. Больше всего гемора было с поиском рабочего решения по чтению буфера в массив. Из плюсов получившегося поделия - с учетом распространенности в линухе консольных конвертеров файлов с синтаксисом типа КОНВЕРТЕР "ИЗ_ЭТОГО" "В_ЭТО", этот скрипт непринужденно может быть перепилен под любой подобный конвертер. Удобно же. Вроде.
Недавно в сообществе GNU/Linux появился пост с программой для Shell-а от PetRiot. В комментариях началось обсуждение целесообразности самой программы, но этот вопрос мне не интересен в полной мере, а вот качество самого кода хотелось бы улучшить. Поэтому я решил проанализировать код скрипта и дать пару советов как можно улучшить и сократить код. Надеюсь данный разбор будет полезен как для автора скрипта, так и для остальных читателей.
Начнем с первой строчки:
#!/bin/sh
Shell(sh) - самый старый интерпретатор командной строки, увы у него отсутствует множество возможностей, поэтому лучше использовать /bin/bash.
Данный код работает и в sh, но в дальнейшем мы будем использовать bash:
#!/bin/bash
Далее идет создание(запись названия файлов в переменные) временных файлов:
f_out=.get_ip_ranges
f_tmp=.ips
О том, что эти файлы временные, нам говорит то, что в конце их удаляют:
rm $f_out
rm $f_tmp
Тут сразу бы хотелось отметить несколько вещей:
1) создание временных файлов не всегда хорошо само по себе
2) названия могут конфликтовать с другими файлами, так мы можем случайно затереть важный файл с таким же названием
3) удаление временных файлов в конце кода. В случае ошибки удаление может не сработать(для данного случая маловероятно, но мы же стремимся к хорошему коду)
Первый пункт слишком спорный, поэтому я его проигнорирую.
Но всегда можно обсудить вопрос целесообразности временных файлов, в комментариях к посту.
Для решения второго пункта, я бы посоветовал использовать команду mktemp:
f_out="$(mktemp)"
f_tmp="$(mktemp)"
Теперь временные файлы однозначно уникальные, но нужно обеспечить их удаление в конце работы программы(в конце работы программы != в конце кода программы).
Для решения 3 пункта, используем команду trap:
trap "rm -f $f_out $f_tmp" EXIT
Команда trap запустит посланный ей код сразу после завершения программы, тем самым мы можем быть уверенны что файлы будут удалены. Также мы добавили параметр -f команде rm, который нужен для игнорирования ошибок и убирает вопросы о удалении.
Перед тем как перейти к следующей части, хотелось бы добавить ещё одну важную деталь в скрипт - проверку входных параметров.
Автор забыл упомянуть, что для запуска скрипта нужно обязательно послать один аргумент - название сайта. Если этого не сделать, то работа программы будет не очевидна. Добавим в начало проверку:
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
Если первый аргумент пустой, то выписывается текст ошибки на stderr и программа завершается. В дальнейшем данное решение можно улучшить, создав функцию для ошибок.
Теперь начало кода выглядит так:
#!/bin/bash
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
Идем дальше:
dig $1 A | grep "^$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
dig $1 A | grep "^$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" > $f_out
dig $1 A | grep "^www.$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
dig $1 A | grep "^www.$1" | grep -o -E "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" >> $f_out
Тут начинаются любимые всеми регексы. Увы читабильность кода плохая, поэтому попробуем это исправить:
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" > $f_out
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" >> $f_out
Мы создали переменную o_re где находится повторяющая часть ip_re регекса и саму переменную ip_re.
Теперь код короче, но можно сократить ещё:
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
Используя команду tee мы выписали результат команды в командную строку и одновременно в файл $f_out.
Исправив с учетом этого остальную часть кода и получим:
#!/bin/bash
if [ -z "$1" ]; then
echo "Error: missing argument" 1>&2 ; exit 1
fi
f_out="$(mktemp)"
f_tmp="$(mktemp)"
trap "rm -f $f_out $f_tmp" EXIT
echo "*********************************************"
echo "Get A records from DNS:"
# Octet regex
o_re="(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"
# IP regex
ip_re="$o_re\.$o_re\.$o_re\.$o_re"
dig $1 A | grep "^$1" | grep -o -E "$ip_re" | tee "$f_out"
dig $1 A | grep "^www.$1" | grep -o -E "$ip_re" | tee -a "$f_out"
echo "*********************************************"
echo "Get NS records from DNS:"
dig $1 NS | grep "^$1" | awk {'print $NF}' | while read nsserv
do
nsname=${nsserv:0:${#nsserv}-1}
echo "=================================="
echo "NS: $nsname"
dig @$nsname $1 A | grep "^$1" | grep -o -E "$ip_re" | tee -a $f_out
done
echo "*********************************************"
echo "Resolve ip range from whois service:"
sort -h $f_out | uniq > $f_tmp
rm $f_out
cat $f_tmp | while read ip
do
echo "Get ip range for $ip"
whois $ip | grep -E -i "inetnum|route|netrange|cidr" >> $f_out
done
echo "*********************************************"
echo "Result"
echo "*********************************************"
sort $f_out | uniq | while read range
do
echo "${range:16}"
done
Так код выглядит уже лучше. Для дальнейших исправлений надо углубиться в работу программы, поэтому это будет в следующей части разбора.
Спасибо за внимание, надеюсь данный пост окажется для вас полезным.
P.s. прошу прощение за орфографические ошибки, мне бы точно не помешал разбор моего текста с орфографической точки зрения :)
Начало цифрового рукоблудия тут: Скрипт для массового выборочного конвертирования форматов файлов в Ubuntu, например, heic в jpg
Спасибо @Dristofor, который навеял мне мысль про более изящное решение.
В thunar можно добавлять кастомные пункты в контекстное меню (Правка - Особые действия), после чего путь к файлам, имена выделенных файлов и что там надо передаются в качестве параметров в программу обработчик. А еще есть комплект программ ImageMagick, где есть консольная команда convert, которая всякие форматы изображений конвертирует друг в друга с синтаксисом типа convert SOURCE RESULT. То есть, по итогу, задача - выцепить из параметров скрипта имена конвертируемых файлов без расширений, и с полным путем конвертировать их в файлы с теми же именами в новом формате. Причем, не перепиливая скрипт под новый формат каждый раз.
Реализация:
#!/bin/bash
#convertany.sh [result_format] [path] [filename1 filename2...]
#для использхования с imagemagick
i=1
for counter in "$@" #цикл с перебором параметров запуска скрипта
do
if [ ! $i -eq 1 ] && [ ! $i -eq 2 ] #дурацкое решение, ниже объясню
then
source="$2""/""${counter}"; #вылепить полное имя файла из 2-го параметра и имени файла
result="${source%.*}"".""${1}" #поменять расширение в полном имени на параметр 1
convert "$source" "$result" #конвертировать, собсна
fi
i=$((i+1));
done
Что все это значит:
Скрипт вызывается с параметрами: 1-желаемое расширение, в формат которого конверируется файл; 2- путь к конвертиируемым файлам; начиная с 3-го параметра - имена файлов в обрабатываемой папке. Все параметры прогоняются через цикл, в котором игнорируются 1 и 2 параметры, а из коротких имен файлов лепятся длинные имена с новым и старым расширением, которые подставляются в команду конвертера imagemagick. Почему-то условный переход на сравнение $counter $1 и $2 у меня не заработал, так что я засунул костыль ввиде счетчика, извинити. Изначально я хотел просто запрашивать пачку длинных имен файлов, но потом узнал, что длина командной строки в линухе ограничена 4кб, и выбрал вариант покороче.
Далее, скрипт у нас, конечно, помечен, как исполнимый, imagemagick установлен. Ковыряем настройки Особых действий в Thunar:
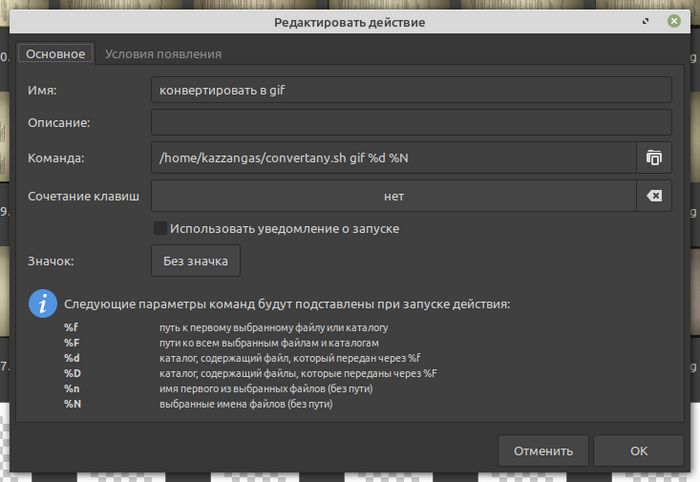
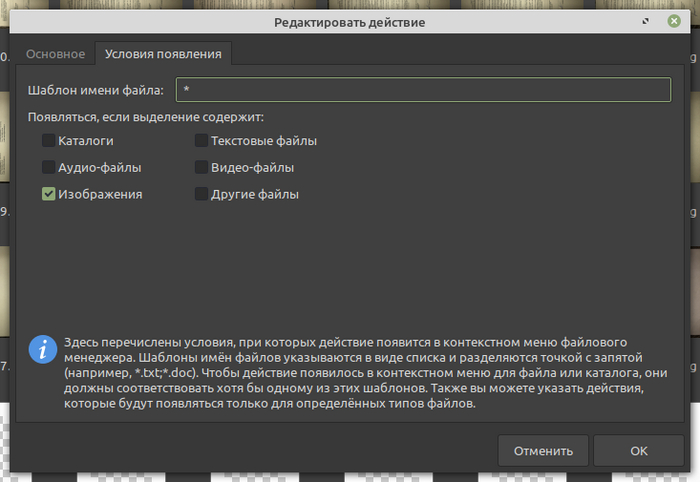
Соответственно, после имя_скрипта.sh и перед %d%N вписываем то расширение, для получения которого мы все это теребим. После заполнения всего этого в настройках, выбираем пачку файлов картинок (причем, можно разного формата), тыкаем в контекстном меню на свежевылупившийся пункт, получаем новые гифки или что там заказывали.
Ньюанс. Во-первых, ранние версии imagemagick (у меня 6-я) не умеют обрабатывать, например, .heic; что оно ест, можно узнать командой "convert -help". Далее, как я понимаю, в поздних версиях вместо convert пишут magick, соответственно, команду в скрипте надо поменять. Ну и, в моем случае, для обработки .heic`ов, нужен сторонний конвертер heif-convert из пакета libheif-examples; вписывается вместо "convert", работает с тем же синтаксисом, в настройках Особых действи тунара надо указать шаблон имени файла *.heic и Появляться, если содержит Другие файлы.
Как оно лепится к наутилусу, я без понятия, но - почти уверен - не сильно сложнее.






