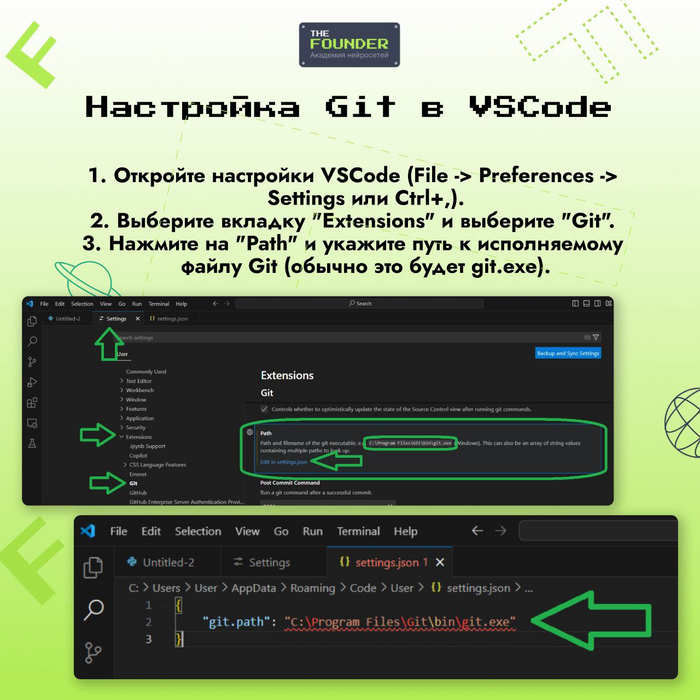
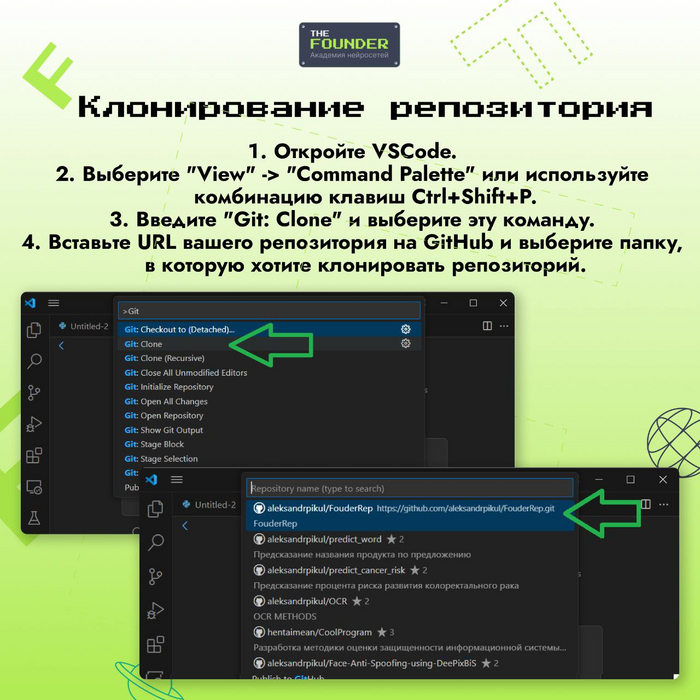
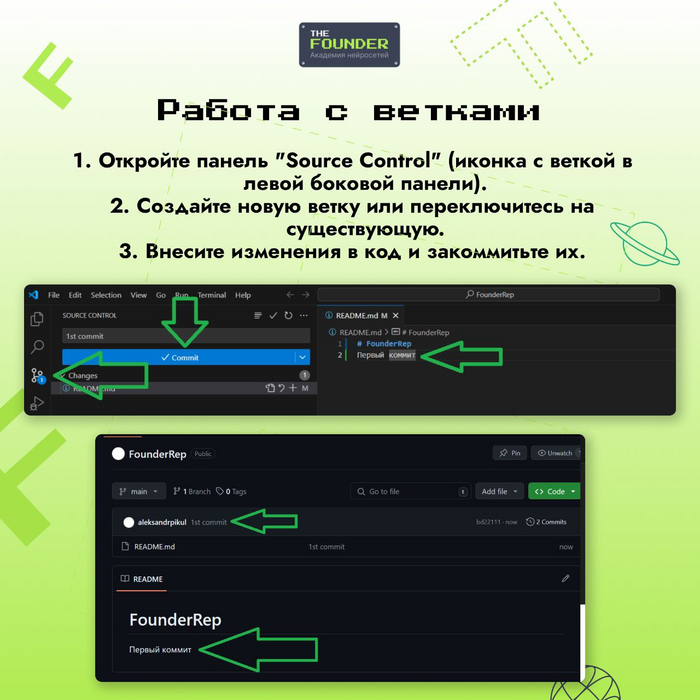
Когда речь о заходит об игре, в которую можно играть бесконечно, то первым делом вспоминается Sims 3 и Sims 4. Типичный симулятор жизни, который постоянно модернизируется как разработчиками, так и самими игроками в помощью модов.
Но что, если попробовать создать игру в жанре action-adventure с элементами survival horror и стелс-экшена, сюжет которой будет адаптироваться под каждого игрока? И, по сути, быть бесконечным? Возможно ли такое?
В теории, да, но создание такой игры потребует максимально слаженной работы между дизайнерами, разработчиками и специалистами по ML. Для начала, нужно определить основные компоненты, которые сделают игру адаптивной и бесконечной.
Технически, игра должна иметь систему, способную анализировать действия игрока и принимать решения о том, какие события и персонажи будут включены в сюжет. Для этого могут использоваться алгоритмы кластеризации для анализа стилей игры, алгоритмы рекомендаций для выбора событий и персонажей, и алгоритмы управления поведением для создания реалистичных реакций на действия игрока.
Кроме того, игра должна иметь динамическую систему генерации контента, которая может создавать новые задания, уровни и персонажей в реальном времени. И здесь среди первых выступают алгоритмы процедурной генерации контента, потому что они могут создавать разнообразные игровые элементы на основе определенных параметров и правил.
Вроде бы всё понятно, но…
С какими проблемами столкнется команда?
Именно об этом и стоит думать в первую очередь. Проблемы могут быть разные, но вот, к чему точно нужно быть готовым:
Сложность в адаптивности. Нужно создать систему, чтобы каждый игрок чувствовал, что игра адаптирована под него. Например, чтобы события в игре менялись в зависимости от того, как он играет. Это сложно, потому что нужно придумать способ, как игра "понимает" игрока и реагирует на его действия.
Вообще такие подходы развиваются в геймдеве, но вряд ли это экономически выгодно для компаний…
Создание такой игры может быть дорогостоящим и затратным процессом. Компании могут оказаться не готовыми к финансовым рискам, связанным с разработкой инновационных игровых концепций, особенно если нет гарантии коммерческого успеха.
Управление контентом. Игра должна быть интересной и разнообразной для каждого игрока. Но создание большого количества уровней, персонажей и сюжетов требует много работы. Команда должна будет постоянно добавлять новый контент, чтобы игроки не скучали.
В этом плане на первый план выходит процедурная генерация контента. Вопрос в том, как это должно работать, чтобы сам контент получился интересным и логичным…
Процедурная генерация контента — это крутая штука, которая позволяет создавать игровой контент с помощью алгоритмов и компьютерных программ, а не вручную. Это означает, что уровни, миры, персонажи и другие элементы игры могут быть созданы динамически во время игры, а не заранее.
Когда вы играете в игру с процедурной генерацией контента, вы никогда не знаете, что вас ждет.
Разработчики должны создать сложные алгоритмы и системы, чтобы гарантировать, что сгенерированный контент будет интересным и логичным. Они должны учитывать различные аспекты игры, такие как структура уровней, характеристики персонажей и задачи игрока.
А это сложно и неоправданно дорого, потому что всегда найдутся те, кому не понравится ничего.
Да и тестирование такой игры будет сложнее. Потому что каждый игрок может испытать разный игровой опыт. Команда должна будет тестировать игру нереальное количество раз, чтобы убедиться, что все работает правильно для всех игроков.
Возможно ли это? Да, только если у вас в команде очень много людей.
Количество сотрудников, необходимых для тестирования игры за два месяца, зависит от масштаба проекта, его сложности и доступных ресурсов. В среднем, для тестирования игр такого уровня сложности требуется команда из нескольких десятков человек, включая тестировщиков, QA-инженеров, разработчиков и дизайнеров уровней. Кроме того, могут потребоваться менеджеры проекта, аналитики и другие специалисты для координации и анализа работы.
Важно также учитывать, что время, необходимое для тестирования, зависит от объема контента в игре, количества возможных путей прохождения и степени автоматизации тестирования. Чем больше игра и чем больше в ней вариативности, тем больше времени и ресурсов потребуется для тестирования.
Но что, если она бесконечная? Тогда это большая проблема.
Не будем забывать и о том, что игра должна работать на всех устройствах и не тормозить. Потянут ли её домашние компьютеры пользователей, у которых нет доступа к GPU серверам? Вряд ли.
И, наконец, чтобы игра могла адаптироваться к каждому игроку, нужно обучить модели понимать, как играют люди. А это потребует очень высокий порог знаний в области ML и примерно столько же времени, как и создание самой игры.
Но главный вопрос: оправдает ли такая игра всех усилий, что были вложены в её разработку?
Сложно сказать. В конечном итоге, оценка оправданности игры будет зависеть от конкретных результатов ее выхода на рынок, отзывов пользователей и финансовых показателей.