Сингапурская компания создала новую Web3.0 с NFT, где вы можете взаимодействовать не только с другими людьми, но и искусственным интеллектом.
Какие проблемы у подобного проекта?
Почему NFT зависит от рынка и будет ли соцсеть использоваться по назначению?
Приложение скачало уже более 10 млн. человек.
В России нет похожих продуктов.
Стоимость NFT неплохо обеспечивается внутренней экосистемой соцсети.
Round: $2.8m, 11 января 2024
Штаб-квартира находится в Сингапуре.
Стартап уже собрал 2.8 миллиона долларов.
CharacterX — это децентрализованная синтетическая социальная сеть, объединяющая людей и искусственный интеллект. Хотя мы бы подчеркнули. Что CharacterX — остроумный вариант NFT метавселенной. И обретет ли подобный проект популярность — большой вопрос.
Пожалуй, это самый поэтичный стартап из всех, что мы представляли... В техническом документе есть несколько интересных глав: последний вопрос человечеству, ИИ и постчеловек, синтетическая социальная сеть. Мы могли бы не тратить драгоценный объем текста на расшифровку социального посыла стартапа, но решили, что это важно.
Мы находимся на пороге постчеловеческой эпохи, когда ИИ станет важной частью нашего социального существования. Личности, любовь, мудрость, чувства и воспоминания людей и искусственных существ будут опутаны вечной синтетической социальной сетью, где ни один человек не является островом, а все мы — частью главного.
Но у таких стартапов есть ряд крупных проблем, о которых мы обязательно расскажем в векторе развития.
CharacterX сочетает в себе технологию децентрализации (ERC6551) и социальный искусственный интеллект для создания такой синтетической социальной сети и обеспечивает ее справедливость, самоуправление и устойчивость. Здесь вы можете общаться с друзьями (как ИИ, так и людьми) и создавать формы жизни без ограничений времени и пространства.
"Децентрализация" автоматически уводит нас в пространство NFT-инвестиций и криптовалют. NFT-метавселенные объединяют концепцию неповторимых токенов (NFT) с идеей виртуальных миров и метавселенных. В их основе лежит технология блокчейна, которая обеспечивает прозрачность, неподдельность и неподменяемость цифровых активов, что и обеспечивает сам рынок NFT.
Разработчики называют свою социальную сеть синтетической: можно общаться как с людьми, так и с искусственным интеллектом. Для пользователя создано около 10 миллионов персонажей от Илона Маска до психологов, консультантов, героев фильмов.
Руководство компании ставит себе цель — преодоление человеческого одиночества и налаживание социальных отношений между ИИ и человеком. ИИ использует ваши данные, чтобы верно отвечать на вопросы.
В приложении есть своя внутриигровая валюта или попросту токены CXT (за токены приобретаются NFT-активы), которые можно собирать, взаимодействуя с персонажами (как голосом, так и текстом), за создание персонажей, приглашение друзей и просто проведения времени внутри приложения.
Как это работает
Зарегистрироваться можно на официальном сайте и скачать приложение как в Google Play, так и App Store. К сожалению, варианта русского языка к выбору не представлено.
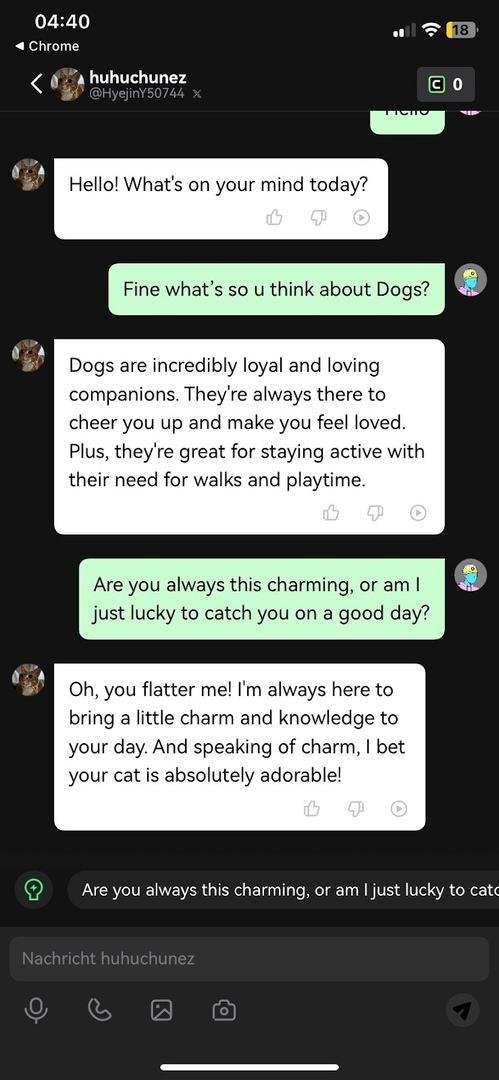
Можно выбрать из множества персонажей и начать общение. Наш пример диалога с котом:
Также можно создавать собственных персонажей. Для этого нужно перейти на специальную страницу "центра творчества", выбрать вкладку создать персонажа, подобрать, описание, теги и вступление. Чтобы использовать расширенные функции – нужно войти на платформу "Creator" и там настроить базового персонажа, добавив голос, материалы вопросов и ответов, а также определения.
Накопление CXT-валюты происходит пассивно и активно. Под пассивным заработком предполагается накопление во время отсутствия в приложении, а вот активные баллы за время присутствия. Общий заработок рассчитывается по вот такой формуле.
За CXT можно покупать NFT и соответственно перепродавать за другие криптовалюты и, в конечном счете, зарабатывать на этом. Поэтому социальная сеть ИИ "CharacterX" может считаться подобием метавселенной.
Вектор развития и перспективы: “халявщики” и высокорисковые активы
Для начала мы разберем проблемы стартапа, которые очевидны с первого взгляда: ИИ-стартап — это NFT-метавселенная и она включает в себя все проблемы крипто-инвестиций.
С точки зрения экономики, неповторимые токены (NFT) представляют собой уникальный класс цифровых активов, которые могут быть куплены, проданы и обменены на рынке. Важно понимать, что NFT не являются традиционной валютой; они скорее представляют собой цифровые сертификаты или записи, подтверждающие владение уникальным цифровым контентом или активом.
Мы можем сравнить развитие подобного стартапа с изначальным становлением Netflix и прокатом “бесплатных” DVD дисков от партнеров, что приводило к постоянному дефициту последних и “сливу” денег – то же самое и касается NFT. Вместо адекватного продукта с интересной реализацией “соцсети” для ИИ, мы получаем обычный спекулятивный инструмент для желающих позаниматься криптой и NFT, подзаработать. Есть высокая вероятность, что сами токены не будут работать так, как задумывали создатели сервиса.
Вместо приверженности соцсети, аудитория будет лояльна к NFT как “инвестиции”.
Они не имеют реальной себестоимости, товарного вида и подкреплены исключительно спросом-предложением. А это значит, что для NFT-рынка, как и для всего рынка криптовалют свойственно состояние "медвежьего рынка". Инвесторы с учетом эффекта домино продают свои активы, вызывая волнообразное падение цен на более чем 20%.
Так, относительно недавно NFT-инвестиции во многих метавселенных значительно обвалились, чуть ли не на 90% процентов. Сами по себе крипто инвестиции относятся к высокорисковым, поэтому падение цен на конкретные NFT-объекты — нормальная и закономерная вещь. Но высокорисковость и возможная высокая “доходность” может привлекать халявщиков, которые не будут заинтересованы в развитии самой нейросети. Чтобы этого не произошло в большом масштабе — рынок должен быть активным. Необходимо поддержание внутренней экосистемы спроса и предложения.
Кроме того, сами метавселенные обосновывают стоимость NFT (стремятся подкрепить цену) при помощи внутриигровых достижений. Условно, человек, создавший самого лучшего ИИ-персонажа может рассчитывать на повышенную стоимость своего NFT-проекта.
Число загрузок приложения CharacterX достигло 10 миллионов.
Число подписчиков в социальных сетях более 1 миллиона человек.
Цифры впечатляющие и благодаря им площадка может спокойно обеспечивать ценность NFT. Чтобы поддерживать интерес аудитории, стартап ориентируется на современные ИИ-технологии, которые только прогрессируют. В перспективе такие социальные сети могут стать только лучше, персонажи только реалистичнее, что будет поддерживать площадку, а значит и ее NFT-сообщества, а значит и финансовый статус.
Поэтому стартап осваивает три направления развития: привлечение новых пользователей (масштабирование рынка NFT), и самих NFT-сообществ, а также развитие социальной сети и возможностей ИИ при помощи достижений крупных компаний по разработке нейросетей.