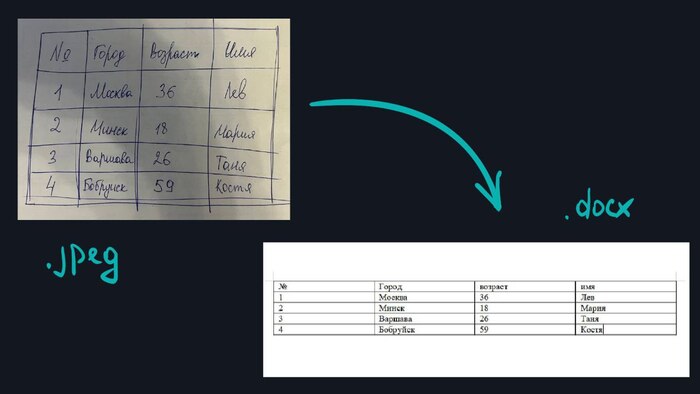
TesseractOCR

TesseractOCR — это движок оптического распознавания символов (OCR) с открытым исходным кодом. Он может быть полезен при распознавании документов, но требует значительных усилий для достижения приемлемого результата.
Основные недостатки:
- для качественного распознавания требуется тонкая настройка под каждый тип документа. Вам придется потратить много времени на подбор параметров.
- чтобы добиться высокой точности на специфических документах, нужно вручную разметить сотни, а лучше тысячи сканов и дообучить модель.
- не распознает рукописный текст.
- качество распознавания значительно падает, если в документе присутствует текст на нескольких языках.
В отличие от TesseractOCR, Vision LLM требуют минимальной настройки (температуры) для начала работы. Вам не нужно тратить время на дообучение.
Для сервиса Извлечение текста из изображений и PDF я добавил возможность использовать TesseractOCR. Можете проверить, какой вариант лучше подойдет для ваших задач (Vision LLM 🏆).
TesseractOCR можно использовать на слабом железе и в ситуациях, когда вам надо распознать несложный текст, или вы собираетесь распознавать свои очень специфичные документы.
Репозиторий гитхаб с простейшим примером использования TesseractOCR в Docker контейнере: https://github.com/Butakov-Andrey/ocr_example
Подробнее про реальное применение ИИ: https://t.me/optifyhub