Сейчас декабрь, все закрывают квартал/год, делают бюджет на следующий год, но а я в поиске работы. Нет, начала поиск я не в декабре, а в октябре. Из результатов за 2 месяца - один оффер, но я отказалась от него. Не из-за содержания работы, а из-за процесса оформления - он вызвал сомнения.
И пока я продолжала поиск, я начала анализировать, что вообще происходит вокруг. Почему раньше всё работало одним способом, а теперь - совсем иначе.
Сейчас из каждого утюга слышу, что работу найти сложно, что на поиск работы надо закладывать 6 месяцев и т.д. и т.п. Ну ОК, подумала я, и вот в октябре начала искать, отрыла резюме на hh.ru для всех желающих, стала повторять теорию, нарешивать задачки и т.д.
Просматриваю вакансии, отбираю в избранное, потом анализирую, что и как там может быть. И наблюдаю за своим резюме. В итоге:
- просмотров резюме - кот наплакал,
- на отклики, релевантные моему опыту - отказы
- предложения только с релокацией в другую страну
Смотрю я статистику своего резюме: последний раз искала работу через HH в 2021 году, просмотров резюме по 10 в день. А сейчас дай бог 3 в неделю.
Резюме у меня одно, я его обновляю и дополняю по мере изменения моего опыта.
Читаю информацию про текущее положение на рынке, везде слышу, что рынок работодателя, что вакансий мало, резюме много. А дальше, очень часто натыкаюсь на то, что все разом говорят - надо делать резюме под конкретную вакансию
Причиной всего этого - автоматизация процессов. Первый скрининг резюме проводит не HR, а AI-агент, настроенный под конкретные триггерные слова.
Раньше мы писали резюме для людей.
Теперь - сначала для алгоритмов
Эпоха универсальных резюме закончилась.
Не потому, что специалисты стали хуже.
А потому что требования стали более структурированными, а инструменты поиска - более автоматизированными.
И теперь у меня вместо одного резюме - 4 резюме, с нотками особенностей под конкретные направления.
Опыт один и тот же.
Но фокус - разный.
И именно фокус видят алгоритмы.
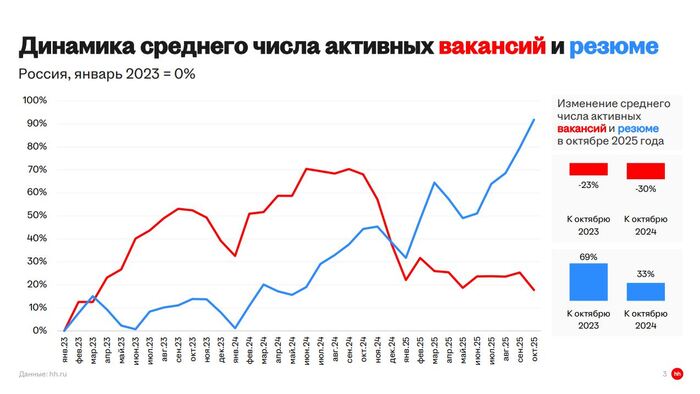
И вот в этой статистике, которую вещает HH.ru - ссылка на презентацию здесь
Говорится о динамики среднего числа вакансий и резюме
Сопоставление вакансий идет к количеству резюме - не к количеству кандидатов.
Если даже возьмем меня, то у меня 4 резюме (планируется еще одно), т.е. количество резюме (в моем случае надо разделить на 4). А если это применить ко всем резюме, то может быть и картина то изменится. И не будем мы использовать слово рынок работодателя - а может быть другой рынок. Например рынок AI-ассистентов
Со стороны соискателей, тоже идет автоматизация. Соискатели в ручную откликаются на 100 вакансий из идеи - а что-то да и сработает. Либо также настраивают автоотклик, автообновление. Все это приводит к тому, что на одну вакансию HR-ы получают 400-3000 откликов, что руками нереально разобрать.
Поэтому компании:
- ставят автоскоринг
- ранжируют по ключевым словам
- убирают резюме, которые хоть чуть-чуть не совпадают
- сортируют по «свежести обновления»
И это не плохо и не хорошо — это новая норма.
Но к ней нужно адаптироваться.
Искать работу в конце 2025 года — это уже не про то, чтобы быть «идеальным кандидатом».
Это про то, чтобы быть заметным в мире, где первые фильтры проходят не люди, а алгоритмы.
Ну а я в своем канале про SQL буду продолжать делиться полезной информацией, интересными задачками и продолжать вдохновлять людей для изучения аналитики.
Если тебе интересно, подписывайся На связи: SQL
Этот канал я веду с нуля.